
LISTA DE FUNCIONES
Capacidades de procesamiento de texto
- Análisis de contenido en colección de documentos ANSI o RTF (varios mb cada uno) y variables alfanuméricas cortas (hasta de 255 caracteres).
- Diccionario moderado de creación de lemas y prefijos (inglés, francés, italiano, alemán y español; contactar para otros idiomas).
- Capacidad para incorporar el pre-procesamiento de texto externo EXE o DLL (incluye muestra de prefijos en inglés y transformación n-grams)
- Exclusión opcional de pronombres, conjunciones, etc., mediante el uso de listas de exclusión definidas por el usuario (o listas de alto).
- Categorización de palabras o frases usando diccionarios existentes o los definidos por el usuario.
- Categorización de palabras con base en operadores booleanos (Y, O, NO) y reglas de proximidad (CERCA, DESPUÉS, ANTES).
- Substitución de palabras y frases y puntuación usando comodines y ponderación.
- Análisis de frecuencia de palabras clave, frases, categorías o conceptos derivados o códigos definidos por el usuario e ingresados manualmente dentro de un texto.
- Desarrollo interactivo y mantenimiento sencillo de diccionarios jerárquicos, taxonomías, o esquemas de categorización.
- ¡Editor en arrastrar y soltar para sencilla asignación de palabras y frases en categorías!
- Capacidad para restringir el análisis a porciones específicas de un texto o para excluir comentarios y anotaciones.
- Capacidad para ejecutar un análisis de muestra aleatoria de casos.
- Corrector de ortografía integrado con asistencia técnica para más de 10 idiomas tales como inglés, francés, español, etc.
- Tesauro integrado para apoyar en la creación de taxonomías y esquemas comprensivos de categorización (inglés, francés, español, italiano, portugués y alemán).
- Potente filtro de casos en cualquier campo alfanumérico o numérico y en ocurrencia de códigos (con los operadores booleanos Y, O y NO).
- Imprime tablas en calidad presentación.
- Importa archivos de texto ANSI y Unicode, MS Word, WordPerfect, RTF y HTML, PDF.
- Exporta cualquier tabla a Excel, SPSS, ASCII, archivos de valores separados por coma o tabuladores, o archivos HTML.
-
Flexible herramienta para destacar palabras clave (el editor de texto puede presentar todas las categorías usando colores diferentes).
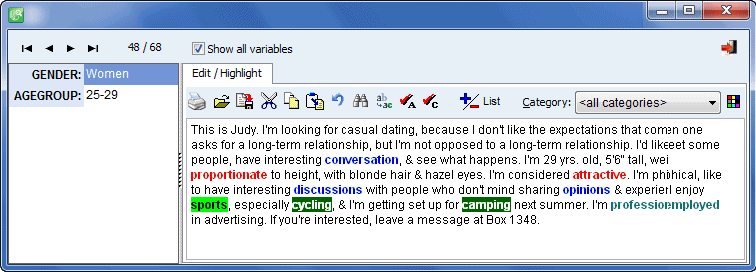
Análisis de una variable en la frecuencia de palabras clave
- Análisis de una variable en frecuencia de palabras (conteo de categoría o palabra y registro de ocurrencia).
- Matriz de co-ocurrencia de palabra x palabra.
- Matriz de datos de palabra x caso.
- Escalamiento multidimensional integrado con mapas 2D y 3D.
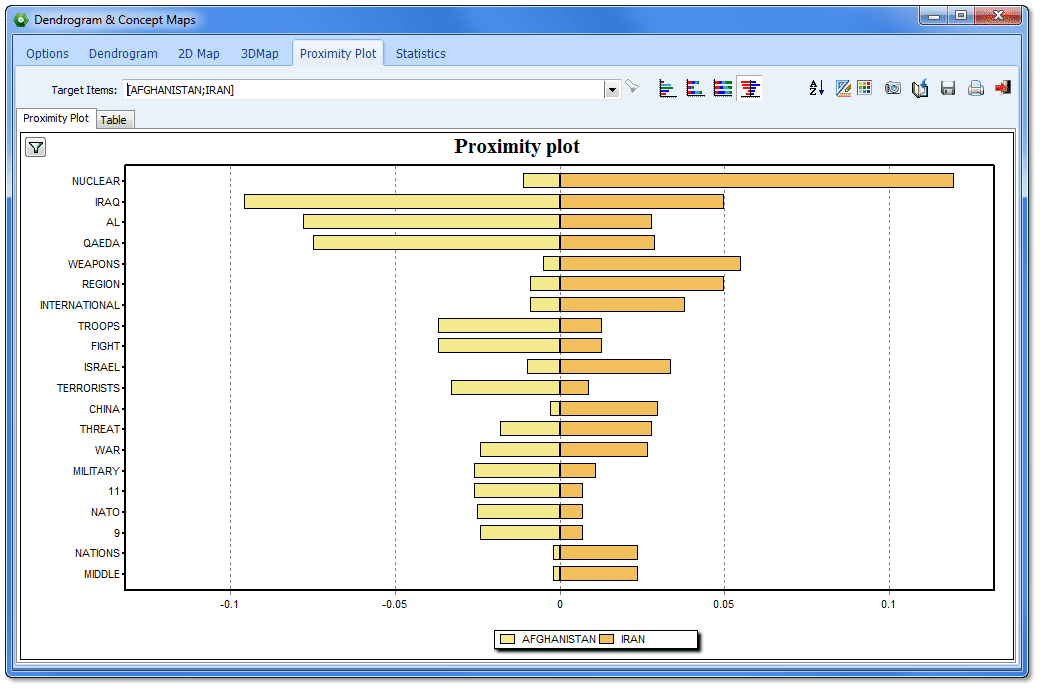
- Gráfica de proximidad.
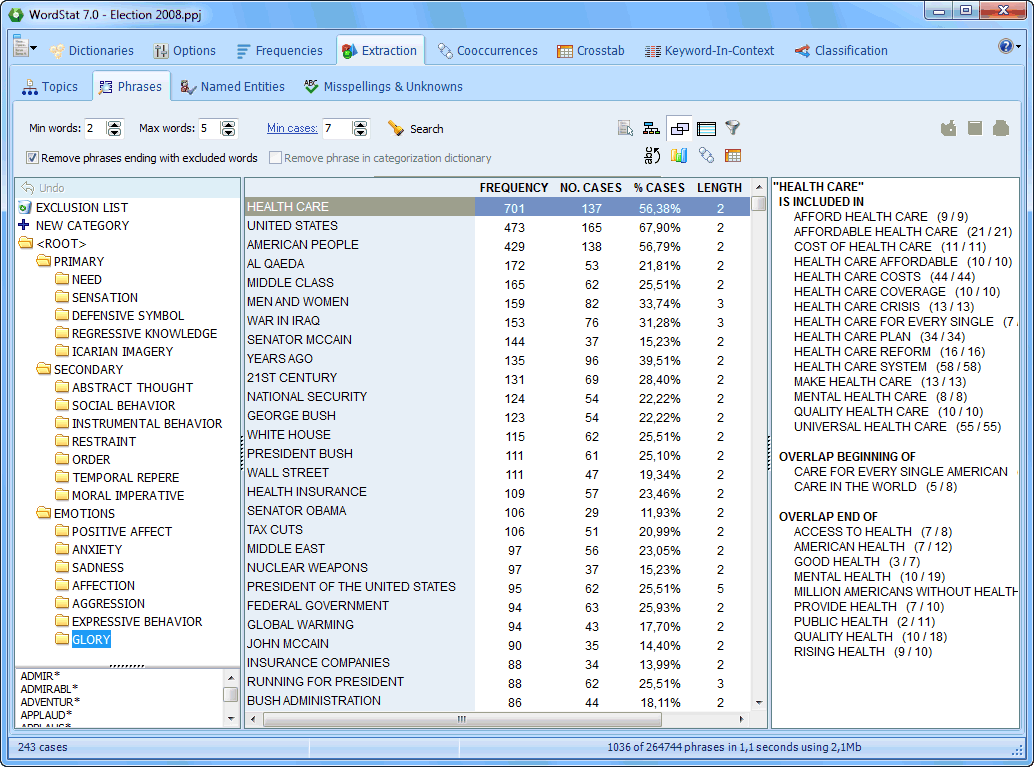
Función de extracción
- Buscador de vocabulario extrae términos técnicos, nombres de compañías y productos así como errores ortográficos comunes.
- Buscador de frases permite identificar fácilmente frases y expresiones recurrentes.
Creación de norma y comparación
- Capacidad para crear archivos norma basados en análisis de frecuencia de palabras o categorías de contenido.
- Comparación de frecuencias obtenidas de archivos de norma previamente guardados.
Función de recuperación de palabra clave
- Una poderosa función de recuperación de palabras clave permite la identificación de unidades de texto (documentos, párrafos u oraciones) conteniendo una palabra clave o una combinación de palabras clave con un óptimo filtrado de casos.
- Capacidad para adjuntar códigos QDA Miner a segmentos recuperados.
- Pueden exportarse los segmentos recuperados al disco en formato tabular (Excel o archivos de texto delimitados) o como reportes de texto (formato RTF).
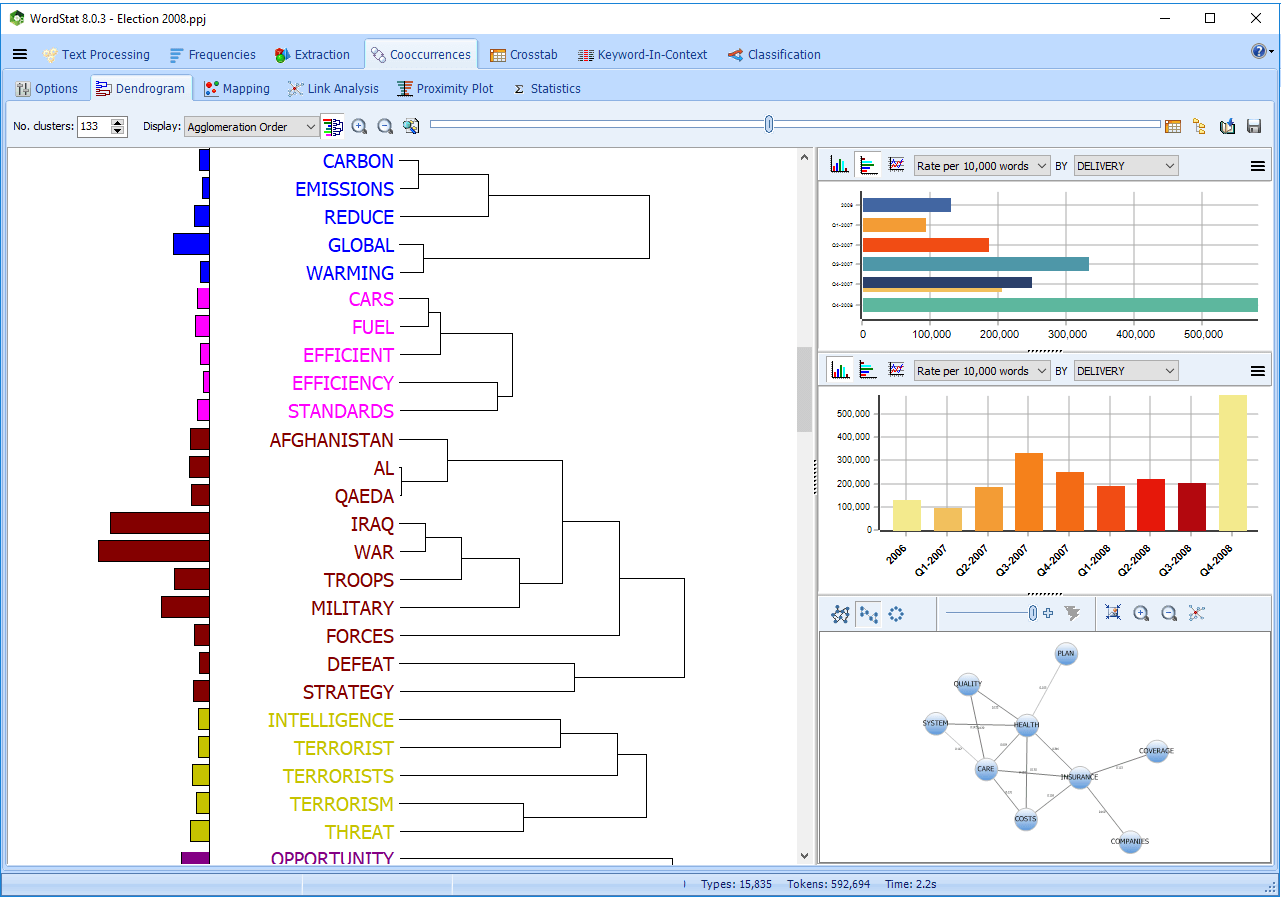
Análisis de co-ocurrencia de palabras clave
- Clasificación integrada y presentación de dendrograma de co-ocurrencia de palabra clave.
- Análisis de proximidad de primer y segundo orden.
- Gráfico de proximidad para fácilmente identificar todas las palabras clave que co-ocurren con una palabra clave objetivo.
- Escalamiento multidimensional en 2D y 3D de la frecuencia conjunta o co-ocurrencia de palabras o categorías.
- Criterios flexibles de co-ocurrencia de palabra clave (dentro de un caso, una oración, un párrafo, una ventana de n palabras, un segmento definido por el usuario) así como métodos de clasificación (proximidad de primer y segundo orden, elección de medidas de similitud).
- Fácil recuperación de texto desde el dendrograma o gráfico de proximidad.
Análisis de caso o de similitud de documento
- Se puede usar clasificación jerárquica, escalamiento multidimensional y gráficos de proximidad para explorar la similitud entre documentos o casos.
Respuestás múltiples y comparaciones
- Puede ejecutar análisis de frecuencia de una variable y tablas cruzadas de información guardada en varios campos alfanuméricos (variables de cadena o memos)
- Comparación de ocurrencia de palabra clave entre diferentes campos.
- Computa medidas de acuerdo entre codificadores (porcentaje de acuerdo, Cohen’s Kappa, Scott’s Pi, Krippendorff’s R y r-bar, marginal libre) con base en códigos manualmente ingresado en diferentes variables.
Comparación de dos variables variables entre subgrupos
- Comparación de dos variables entre cualquier campo textual y cualquier variable ordinal o nominal (tales como sexo de los participantes, subgrupos específicos, años de publicación, etc.).
- Selección entre 11 diferentes medidas de asociación para evaluar la relación entre ocurrencia de palabras y variables nominales u ordinales (Chi-cuadrada, razón de verosimilitud, Tau-a, Tau-b, Tau-c, D simétrica de Somers, Dxy y Dyx asimétricas de Somers, Gamma, R de Person, Rho de Spearman).
- Computación estadística de cualquier frecuencia absoluta o relativa.
- Capacidad para ordenar la matriz en orden alfabético de palabras, frecuencia u ocurrencia de palabras, estadísticas obtenidas o por su probabilidad.
- Visualmente comparar elementos entre subgrupos mediante gráficas de barra y gráficas de líneas.
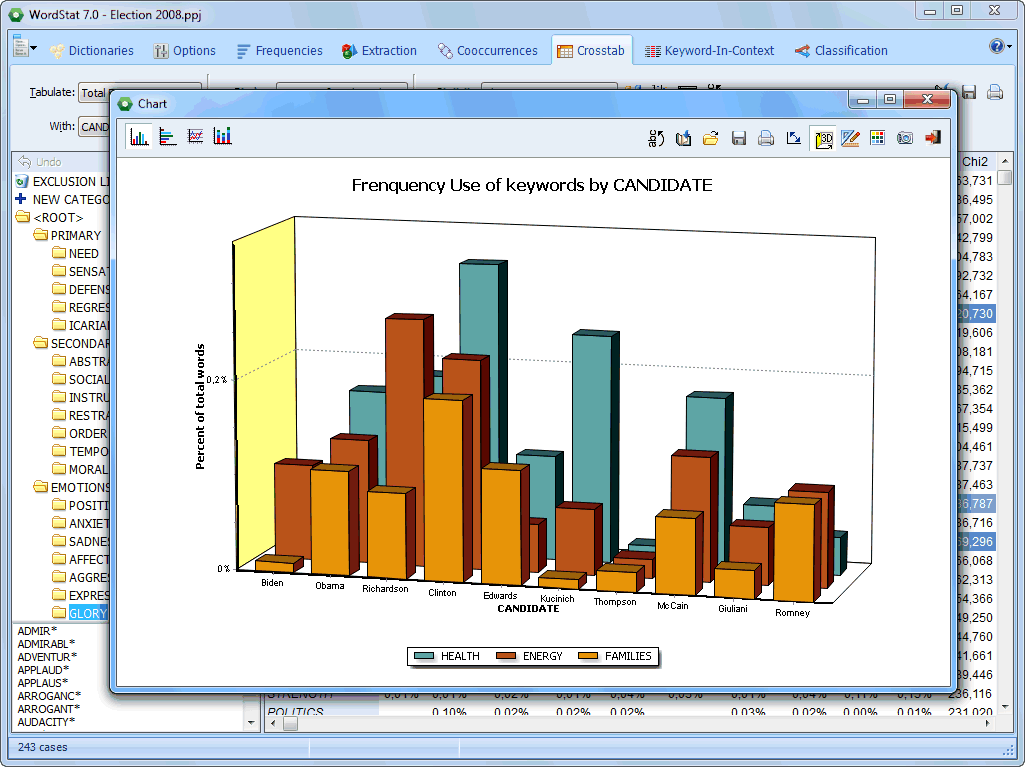
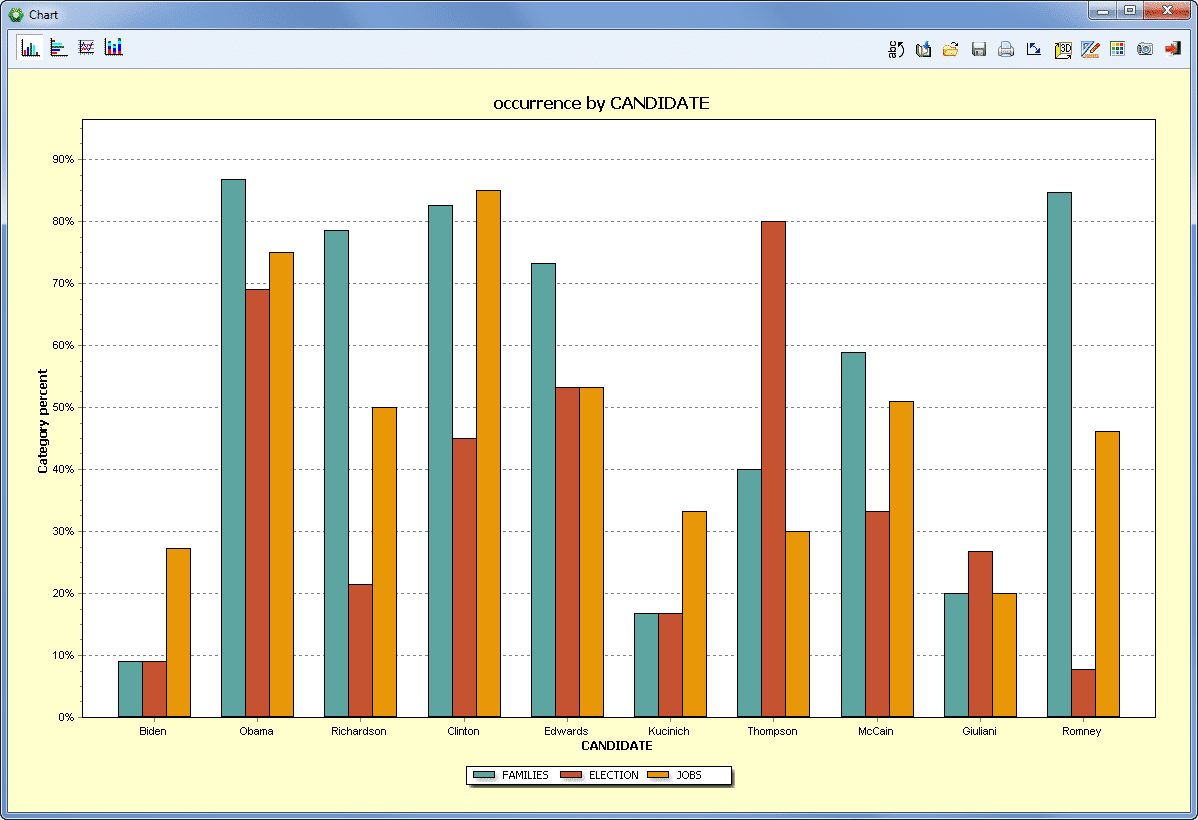
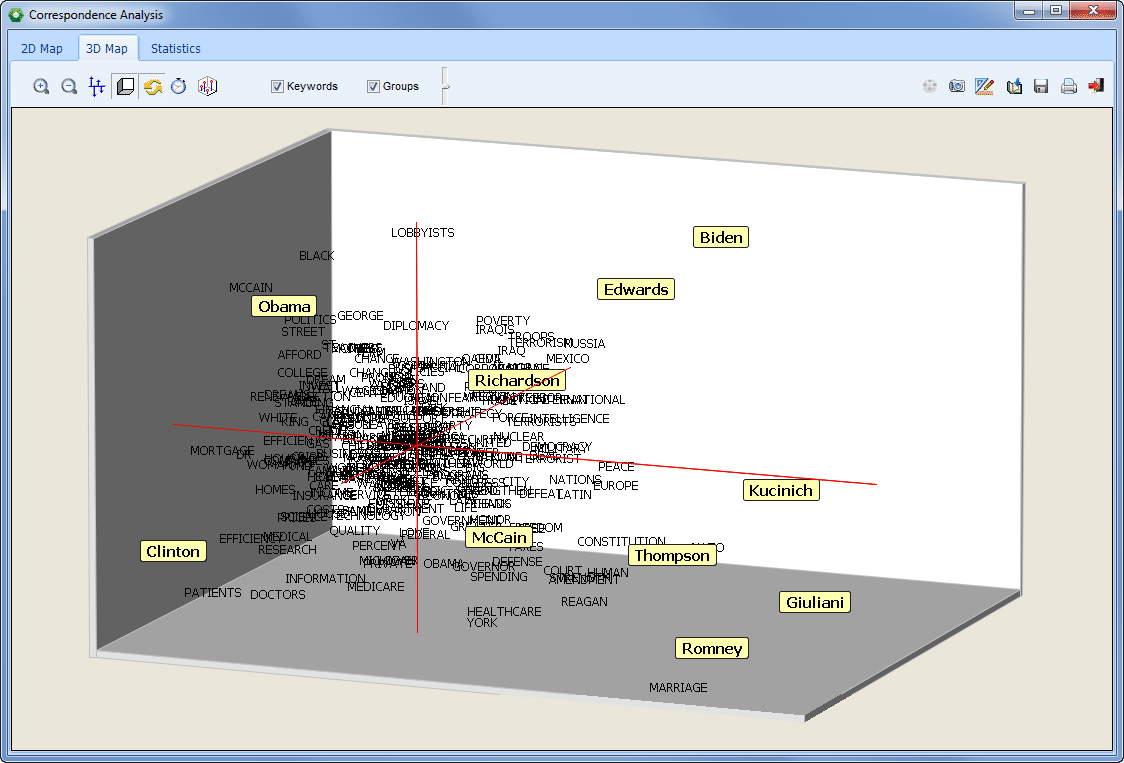
- Análisis de correspondencia (estadística, gráficos conjuntos 2D & 3D). Esta función es accesible desde la página de tabla cruzada y permite ver gráficamente la relación entre variables nominales y códigos que resultan de un análisis de contenido.
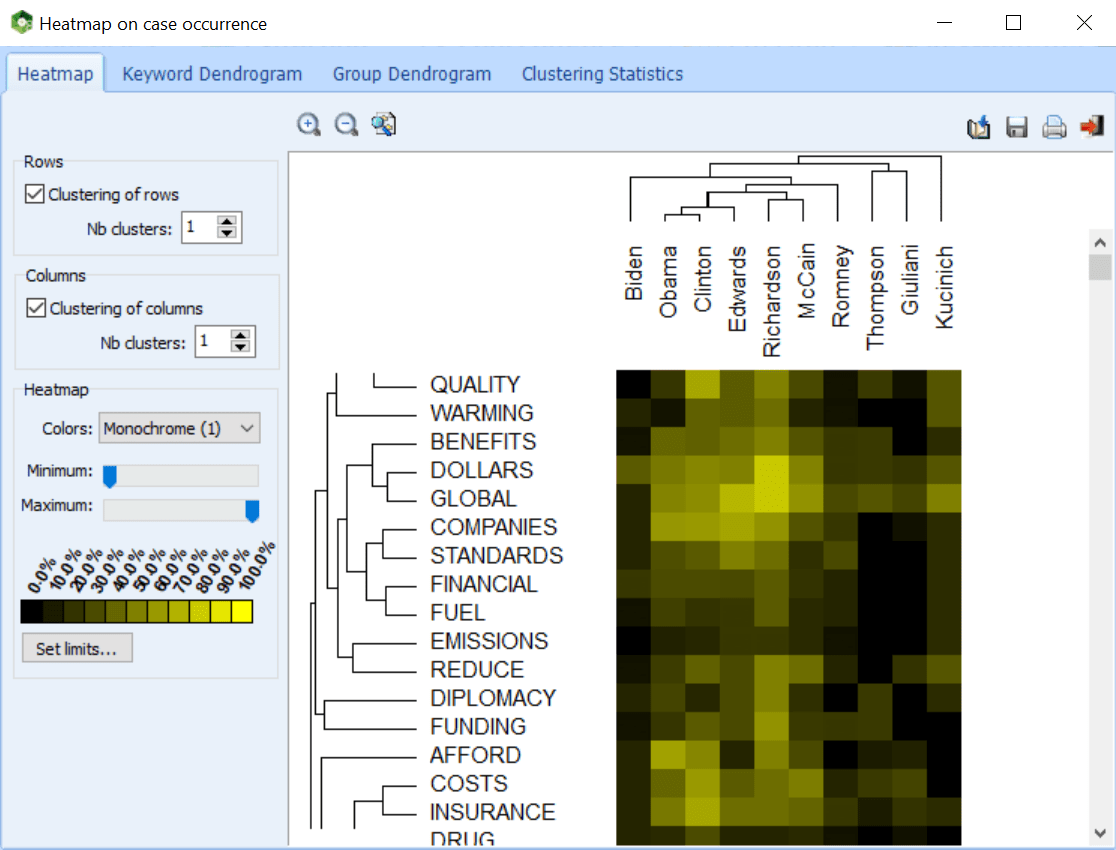
- Gráfico de mapa térmico (con clasificación dual de palabras clave y variables)
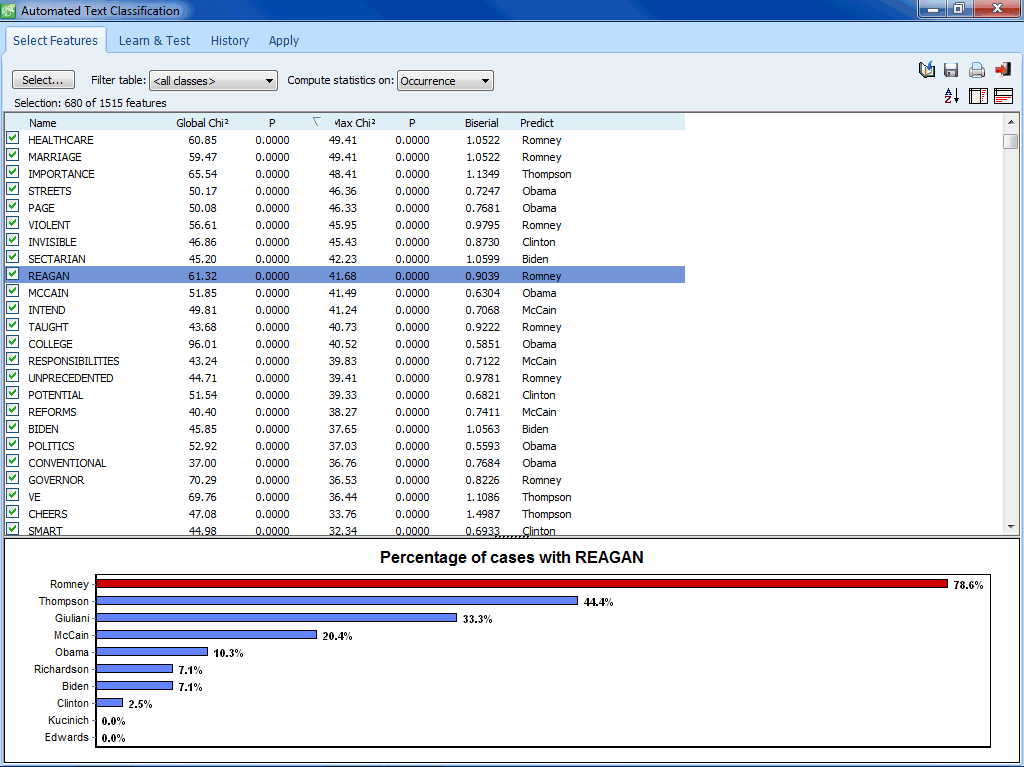
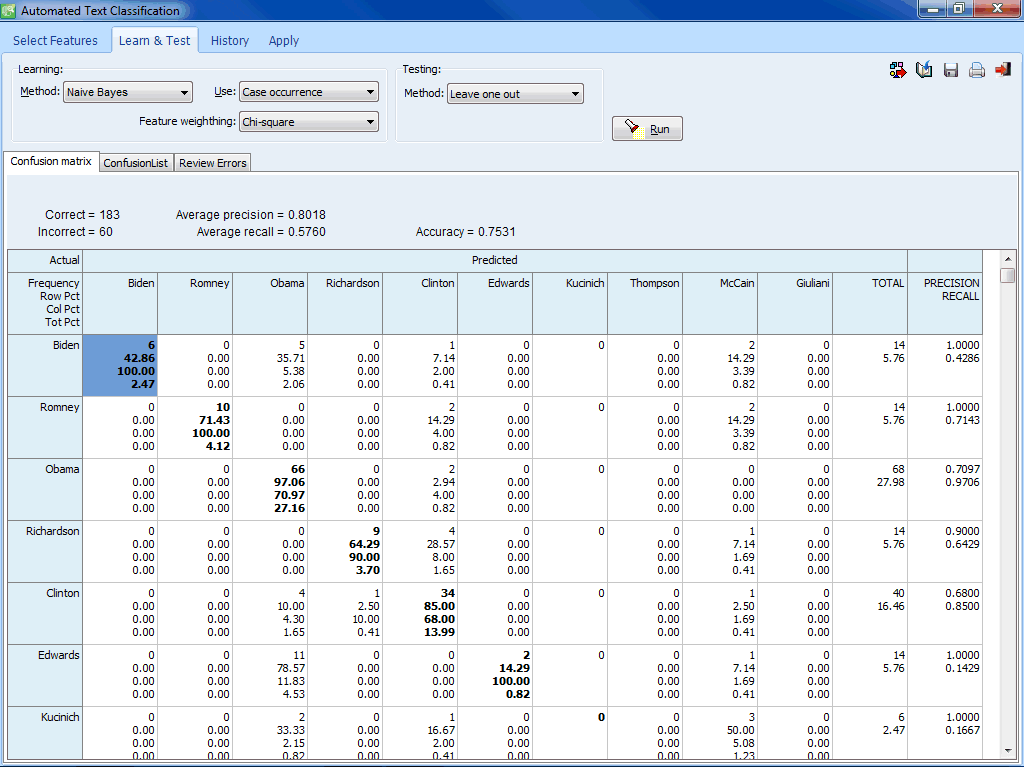
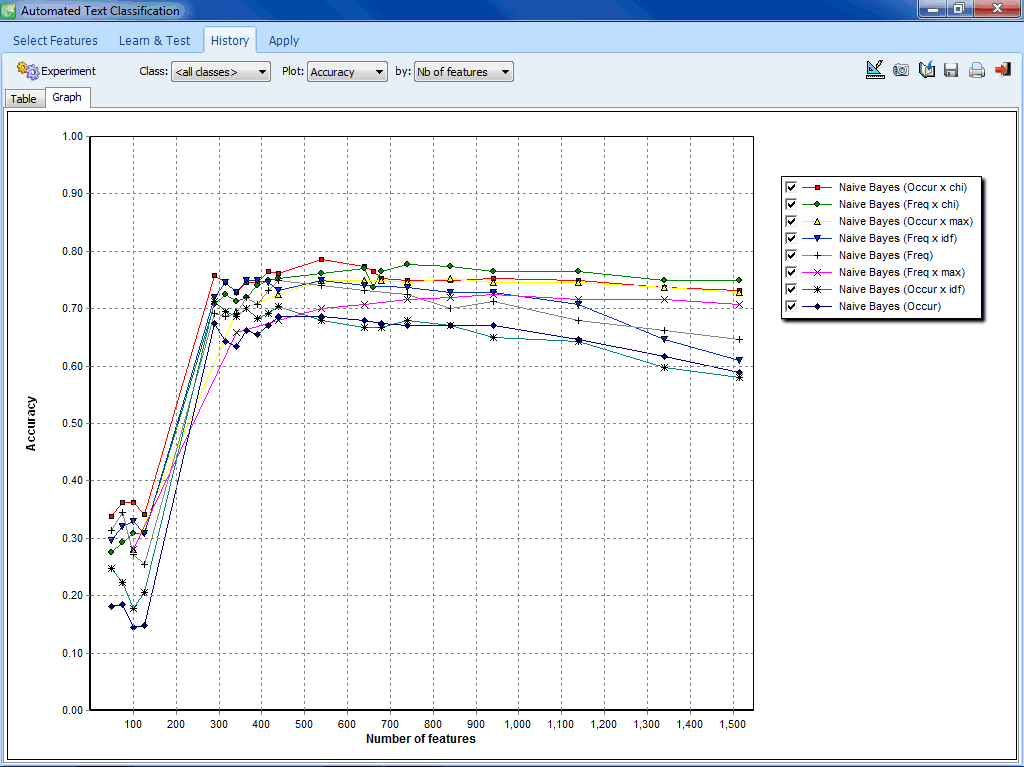
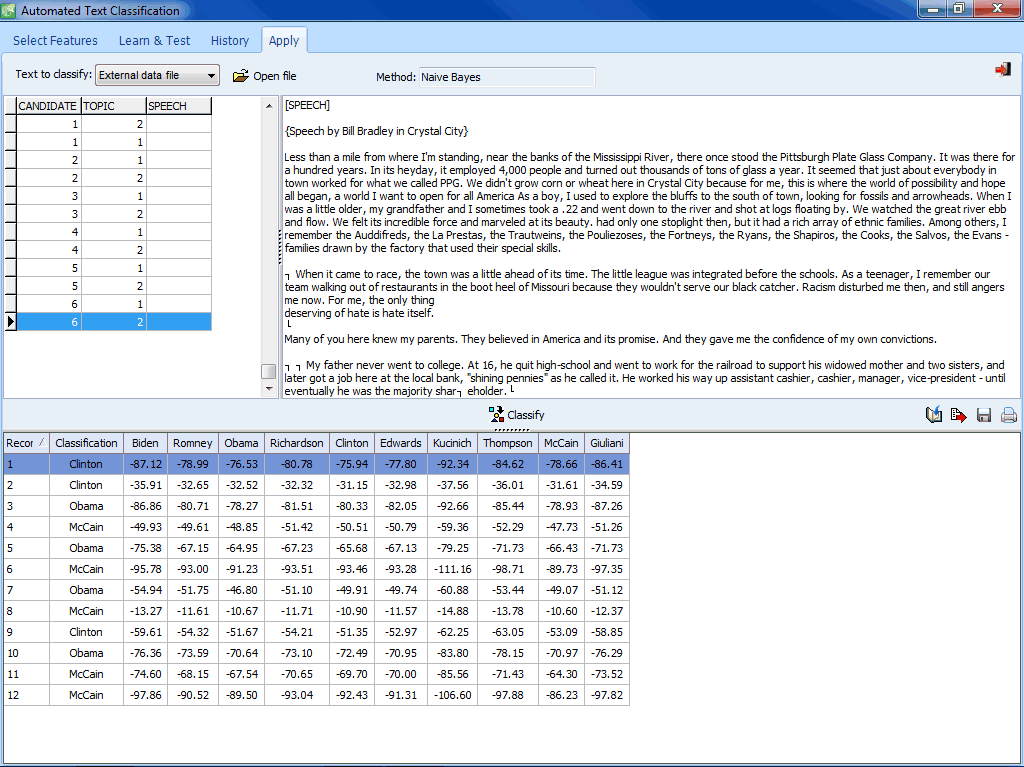
Clasificación automatizada de texto
- Algoritmos de maquinaria de aprendizaje (Bayesiano ingenuo y K-Vecinos más cercanos) para la clasificación de documentos.
- Función flexible de selección para la selección automática de los mejores subconjuntos de atributos.
- Diversos métodos de validación (dejando uno afuera, validación cruzada de n-iteraciones, muestra subdividida).
- Módulo de experimentación permite la comparación sencilla de modelos predictivos y el afinamiento de modelos de clasificación.
- Los modelos de clasificación pueden guardarse en el disco y aplicarse más tarde utilizando un programa de utilidad independiente para la clasificación de documento, un programa de línea de comandos o una biblioteca de programación. Nota: La línea de comando y la biblioteca de programación son parte del material para el desarrollador del software WordStat (SDK) que se vende por separado.
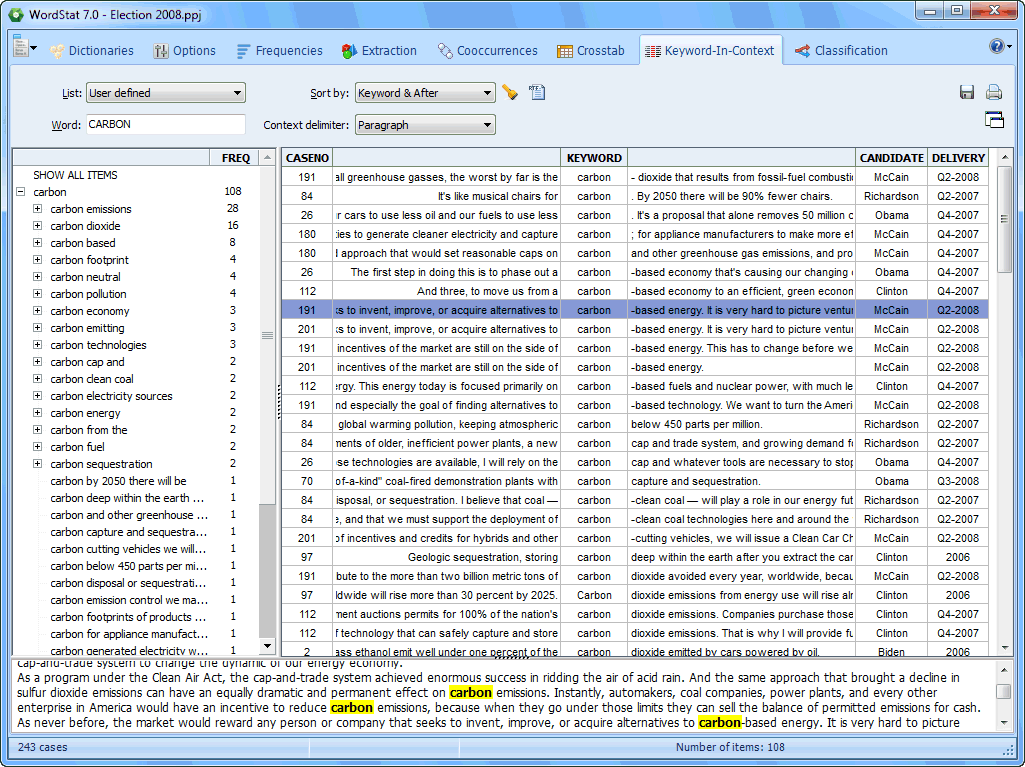
Palabra clave-en-contexto (KWIC)
- Capacidad para presentar una tabla KWIC para examinar el contexto textual de una palabra, patrón de palabras, o categoría.
- Capacidad para ordenar la tabla a partir de cualquier variable independiente (numérica).
- Capacidad para ir desde la palabra en contexto KWIC a la variable textual a fin de visualizar o editar el texto original.
- La lista KWIC puede guardarse en archivos de datos para procesamiento posterior.
- Pantalla KWIC personalizada (párrafo, oración o segmento definido por el usuario).
- Reporte de concordancia (presenta todos los resultados como una lista de párrafos, oraciones o segmentos definidos por el usuario).
Integración total con un software estadístico
- Las variables alfanuméricas pueden guardarse en el mismo archivo que las otras variables numéricas.
- La selección de variable, análisis estadístico y análisis de contenido se ejecutan dentro del mismo programa.
- Los resultados de matriz son automáticamente agregados a los resultados estadísticos existentes.
- Nuevas variables que representan la ocurrencia de palabras, palabras clave o conceptos pueden agregarse al archive de datos existente o exportarse a un Nuevo archive de datos a fin de ser enviados la subsiguiente análisis estadístico (tal como análisis de conglomerado de palabras o casos, análisis de coordenada principal, análisis de correspondencia, regresión múltiple, etc.).
- Los datos pueden importarse desde y exportarse a diferentes formatos de archivo, incluyendo dBase, Paradox, Excel, Quattro Pro, Lotus 1-2-3, SPSS para DOS, SPSS para Windows, archivos de texto separados por coma o tabuladores, etc.
- Capacidad para ejecutar transformación numérica y alfanumérica o aplicar filtros sobre registros del archivo de datos para restringir el análisis a subgrupos específicos.
Programas de utilidad
- Asistente para la construcción de diccionario para encontrar palabras relacionadas (sinónimos, antónimos, holónimos, merónimos, hiperónimos, hipónimos) en un tesauro basado en una red de palabras solo en inglés (WordNet). (100,000 sinónimos, 120,000 palabras raíz)
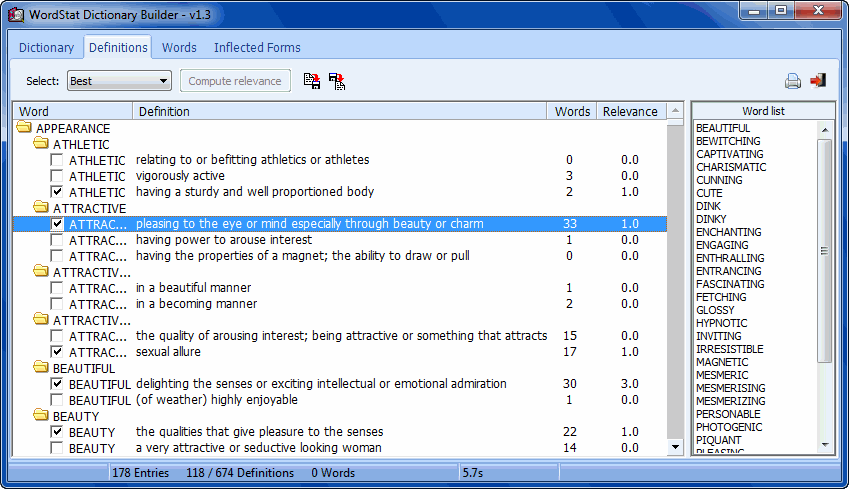
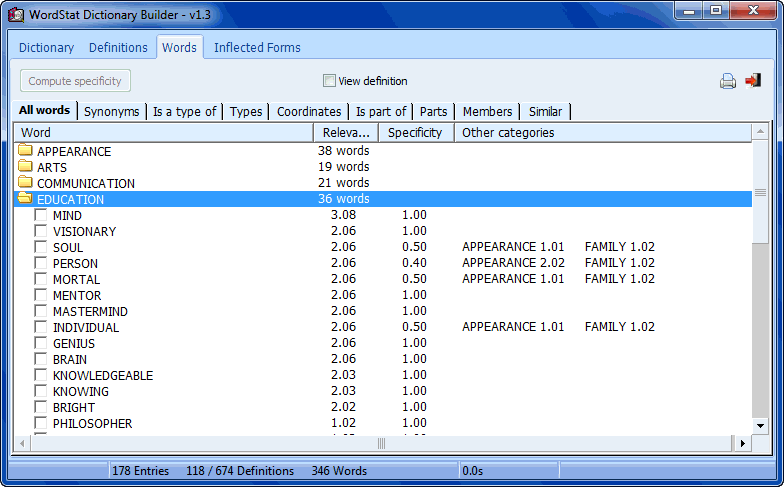
- WS Clasificador de Documento, una pequeña aplicación independiente para aplicar los modelos de clasificación y categorización previamente guardados a documentos externos.
- Asistente para la conversión de documentos- Programa de utilidad para importar fácilmente documentos. Diversos formatos de archive pueden ser importados directamente, tales como solo texto (ANSI, Unicode) HTML, RTF, MS Word, WordPerfect, Adobe PDF,
- Eliminación opcional del espaciado inicial y final y puntos y aparte.
- Extracción de variables numéricas, alfanuméricas y de fecha desde documentos estructurados.
- Las opciones de extracción pueden guardarse en un disco y ser recuperadas posteriormente.
- Los documentos pueden guardarse como texto ANSI o como documentos RTF.