Explorance intègre WordStat pour automatiser l’analyse des données non structurées collectées a partir des formulaires d’évaluation des cours. January 17, 2018 - Nouvelles à propos de Recherches Provalis
L’entreprise eXplorance est un leader mondial de solutions de Learning Experience Management pour la gestion des entreprises et des établissements d’enseignement supérieur. eXplorance sert plus de 9 millions d’utilisateurs et de clients à l’échelle internationale. Sa plateforme d’évaluation collecte de grandes quantités de données au moyen de questionnaires, d’enquêtes et d’outils d’évaluation à 360°. Les données ainsi collectées aident les organisations à mesurer les besoins, les attentes, les aptitudes et les compétences des employés et facilitent l’implantation d’un cycle d’amélioration continue.
DÉFI
Les données massives sont omniprésentes et déstabilisent les entreprises. Maîtriser les flots de données et les traiter convenablement pour en extraire les informations pertinentes constitue un véritable casse-tête. Autant dans une université que dans une entreprise, le challenge consiste à transformer cette immense quantité de données brutes générées quotidiennement en avantage compétitif. Dans la plupart des universités, les étudiants sont invités à la fin de chaque trimestre à produire des évaluations sur la prestation de l’enseignement. Les questionnaires d’évaluation contiennent généralement des questions fermées, des scores et des questions ouvertes pour permettre à l’étudiant de s’exprimer librement. Les gestionnaires d’établissement d’enseignement ont besoin d’analyser rapidement cette quantité considérable de données pour évaluer les compétences pédagogiques des professeurs et chargés de cours, et mesurer l’impact et l’efficacité des programmes dans le but d’améliorer la qualité des services et de favoriser l’engagement et la réussite. Bien que très performant et offrant une grande variété d’outils de mesure, le système de collecte de données mis au point par eXplorance ne permet pas d’analyser les commentaires textuels, pourtant si riches en informations. En effet, seules les données provenant des questions fermées et les scores se présentent sous une forme immédiatement exploitable. L’ensemble des informations non structurées sous forme textuelle nécessite un traitement préalable avant d’être analysé. L’usage des méthodes traditionnelles d’analyse de données non structurées devient impossible devant la taille considérable des données récoltées. Pour les clients d’eXplorance confrontés à ce défi, une stratégie efficace d’analyse de ce type de données est essentielle.
PROJET
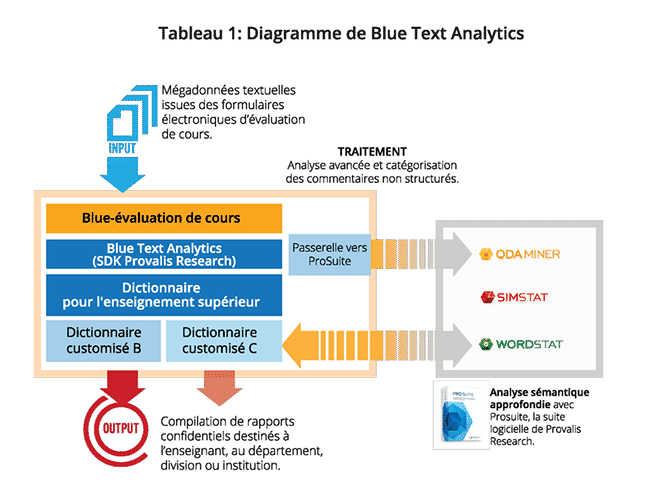
Pour garder sa position de leader et répondre au besoin de ses clients, eXplorance a demandé la collaboration de Provalis Research afin de mettre au point une nouvelle plateforme analytique tout-en-un, capable d’automatiser l’analyse de données non structurées collectées à partir des formulaires d’évaluation et de faciliter leur interprétation. La stratégie proposée par Provalis Research a consisté, dans un premier temps, à utiliser le logiciel d’analyse sémantique WordStat pour faire une recherche exploratoire de contenu, en utilisant des techniques de traitement automatique des langues (TAL), de statistiques textuelles et d’apprentissage machine pour extraire rapidement les principaux thèmes et catégories de mots. Pour ce faire, les experts de Provalis Research ont analysé plus de 1,8 million d’évaluations de cours provenant d’étudiants à travers le monde et construit un corpus de 35 millions de mots. La complexité et l’hétérogénéité des données analysées ont nécessité l’utilisation de
techniques de désambiguïsation, de mots-clés en contexte (KWIC) et de correction orthographique. Toutefois, ces opérations ont dû être effectuées avec prudence, étant donné le caractère international des données et les spécificités linguistiques régionales. Par exemple, en Nouvelle-Zélande, le mot « paper » réfère à un cours, alors qu’il peut désigner une épreuve écrite, un document, un article, un journal ou un exposé dans les autres pays anglo-saxons. Par la suite, les fonctionnalités d’aide à la construction de dictionnaires de WordStat ont été mises à contribution pour développer et valider une taxonomie customisée contenant des dizaines de milliers de mots, d’expressions et de règles réparties dans une centaine de catégories. Enfin, la trousse de développement logiciel (SDK) de Provalis Research a été utilisée pour créer Blue Text Analytics (BTA) et traiter automatiquement les questions ouvertes.
TÉMOIGNAGE
« Provalis a une approche rigoureuse en analyse sémantique […] L’approche d’analyse de texte par les méthodes mixtes de Provalis a permis une meilleure compréhension de données recueillies par notre système. » eXplorance a des clients partout dans le monde et « l’outil d’analyse sémantique développé par Provalis prend en considération les spécificités linguistiques régionales, le contexte et les erreurs d’orthographe » a déclaré Samer Saab, le fondateur et PDG d’eXplorance.
CONCLUSION
L’approche proposée par Provalis Research a permis à eXplorance d’implanter Blue Text Analytics (BTA) avec succès. Grâce à cette plateforme analytique tout à fait unique sur le marché, l’entreprise dispose désormais d’un avantage compétitif difficilement imitable.
En combinant les techniques de traitement automatique des langues, les statistiques textuelles et l’apprentissage machine, les logiciels d’analyse sémantique de Provalis Research permettent d’extraire rapidement de l’information pertinente à partir d’un grand volume de documents. Ainsi, il suffit d’une fraction de temps pour identifier et extraire les principaux thèmes, des tendances, des opinions ou des sentiments.