

Content analysis and text mining software for fast and precise processing of large amounts of unstructured information
Content analysis and text mining software for fast and precise processing of large amounts of unstructured information
THE NEW FEATURES OF WORDSTAT TEXT MINING SOFTWARE
What’s New in Version 2024?
We’re delighted to announce the release of WordStat 2024. This new version includes important speed optimizations as well as several useful features for exploring in greater detail and in a more focused way large text collections. Here are some new and improved features:
1. Optimized Initial Text Processing
In Version 2024, WordStat has significantly enhanced the efficiency of the initial reading and processing of data files, resulting in expedited results. This improvement is particularly pronounced for projects comprising a large number of small documents, with the first operation now completing up to three times faster than in previous versions.
2. Apply Automatic Document Classification Models to Project Data
WordStat 2024 now allows the application of automatic document classification models for data transformation. Found on the Data page, this new feature facilitates the storage of predicted classes in a variable. Users can also opt to store the probability of the predicted class or probabilities of all classes.
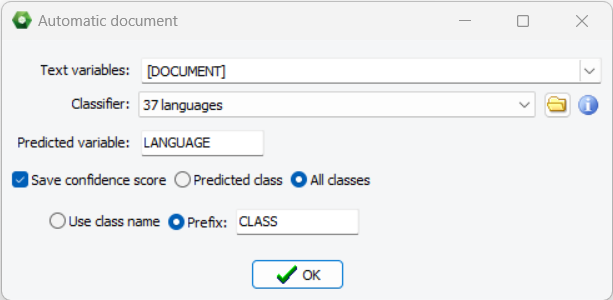
3. Improved Language Detection
WordStat 2024 introduces a new language identification classification model that can identify 37 languages accurately (most languages using Latin, Arabic or Cyrillic characters). It’s measured accuracy is above 98% on very small text segments (five words or less) and above 99.5% on longer documents. The classification model may be applied to create a language variable in a multilingual project, allowing one to filter and analyze different languages separately.
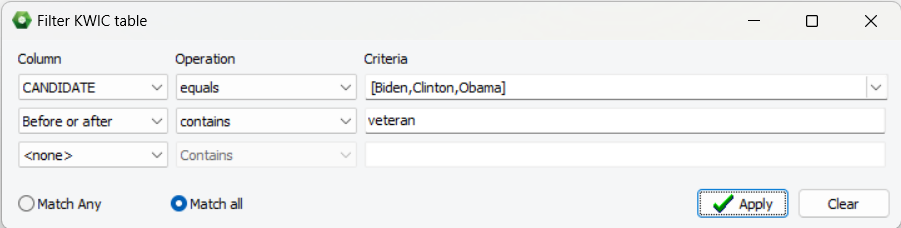
4. Filter KWIC tables on up to three criteria
A new filter option on the Keyword-in-Context page may now be used to filter the results of the KWIC table on any selected independent variables or on words or phrases appearing before or after the key item.
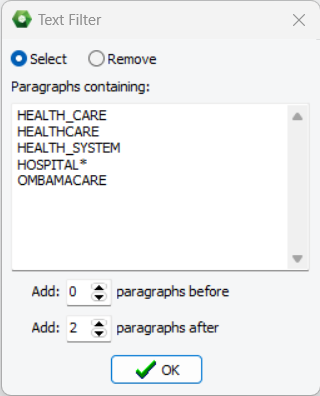
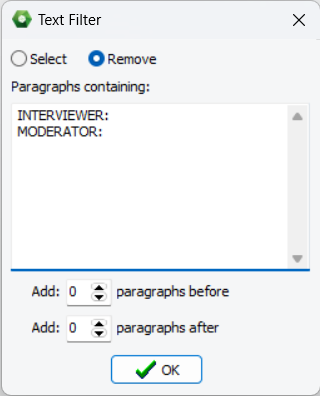
5. Select or Exclude Paragraphs using Text Filters
An advanced preprocessing feature enabled users to filter in or out paragraphs containing specific words or phrases. Multiple items can be specified and may be preceded or ended with an asterisk to represent zero, one, or several additional characters. One may also select specific numbers of paragraphs before or after the matching paragraph in order to include or exclude the surrounding context. This feature is especially useful to quickly focus the text analysis on specific topics in large datasets without the need to create a new dataset. When analyzing interview or focus group transcripts, it may also be used to remove interviewer’s questions or the moderator’s interventions if their interventions are clearly indicated by specific key strings.
6. Save Text Retrieval Results to a New Project File
When using the keyword retrieval function, a new button now allows one to save the obtained table as a new project file. This includes preserving options from the current project, such as pre- and post-processing settings, and the link to the categorization model. This feature proves especially handy for in-depth analysis of text segments on a specific topic or meeting specific conditions.
7. Copy Graphics’ Data to the Clipboard in Text Format
It is now possible to save data utilized for creating various graphics to the clipboard in tab-delimited format. One may then seamlessly paste the data in another application to generate tables or custom charts.
8. More Ways to Add Items to the Categorization Dictionary
Right clicking on items of a 2D correspondence plot or of a deviation table now allows one to add those items to an existing or a new category. This option is disabled or hidden when the selected item is already present in the current categorization model or refers to a content category.
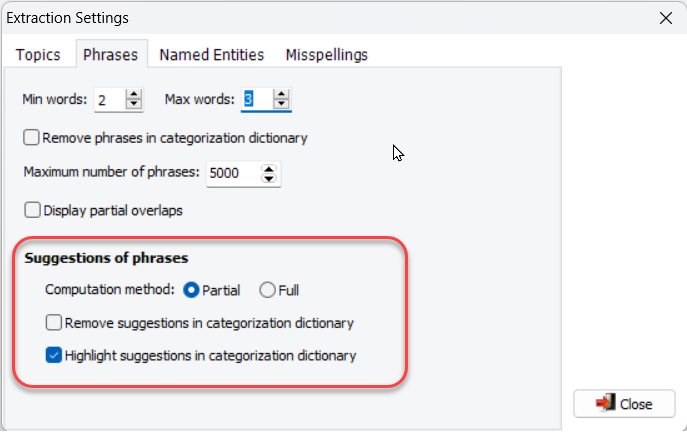
9. Filtering and Highlighting of Suggested Phrases.
New phrase extraction options have been added to remove or highlight (bold + italic) phrases already in the current categorization dictionary. Additionally, a filtering mechanism has been introduced, allowing users to set a minimum frequency to narrow down suggested phrases.
What’s New in Version 2023?
1. Improved Topic Enrichment
WordStat now adds more relevant phrases to the extracted topics, while also offering improved suggestions for additional phrases. Additionally, it now boasts greater accuracy in identifying false positive expressions, or exceptions, which can be incorporated into the topic model to help disambiguate words associated with contexts unrelated to the extracted topics.
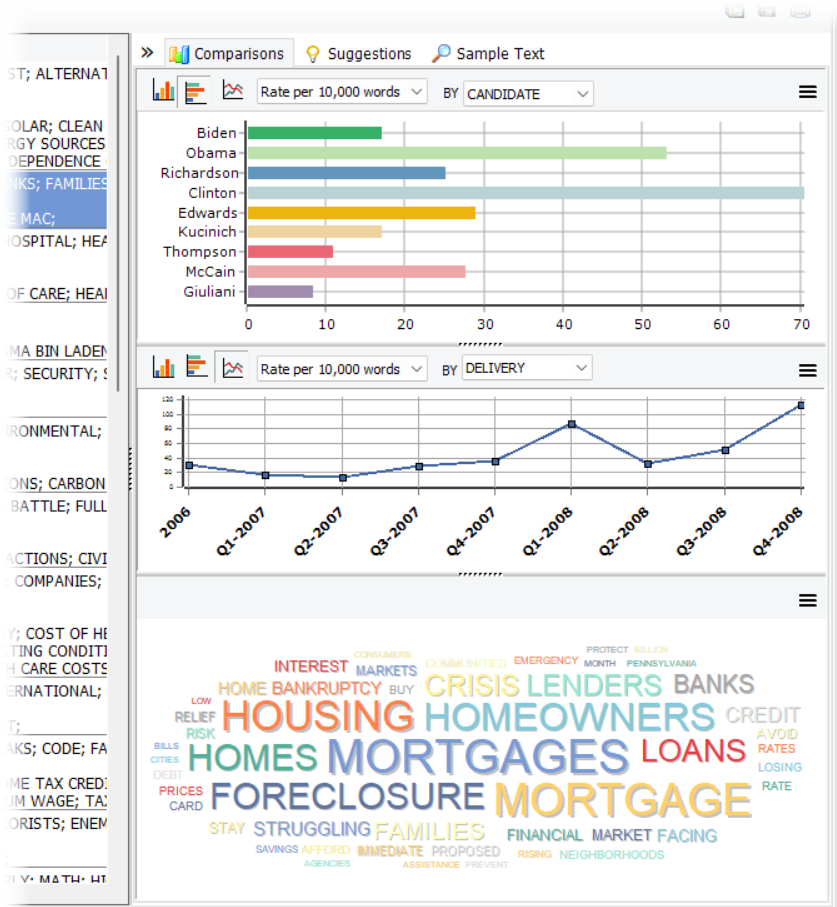
2. Topic Modeling Word Cloud
The comparison panel on the right-hand side of the topic model table now features a newly added word cloud that visually depicts the relative importance of the top words within the selected topic. This word cloud can be customized, copied to the clipboard, or saved to disk in standard graphic formats like BMP, PNG, or JPEG.
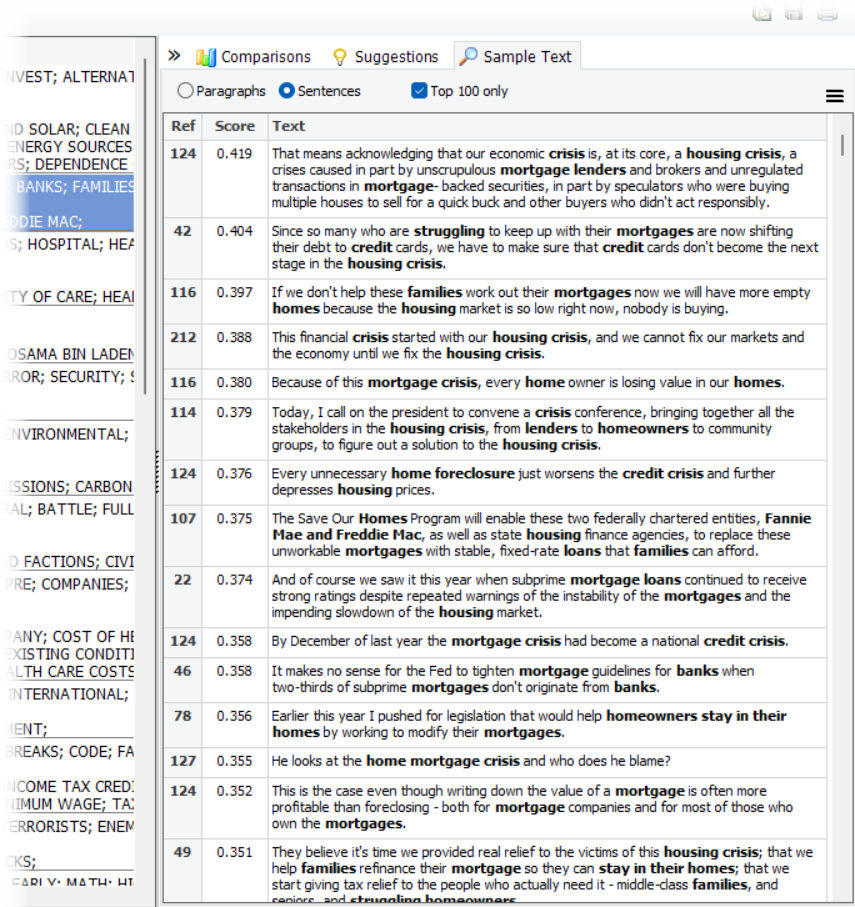
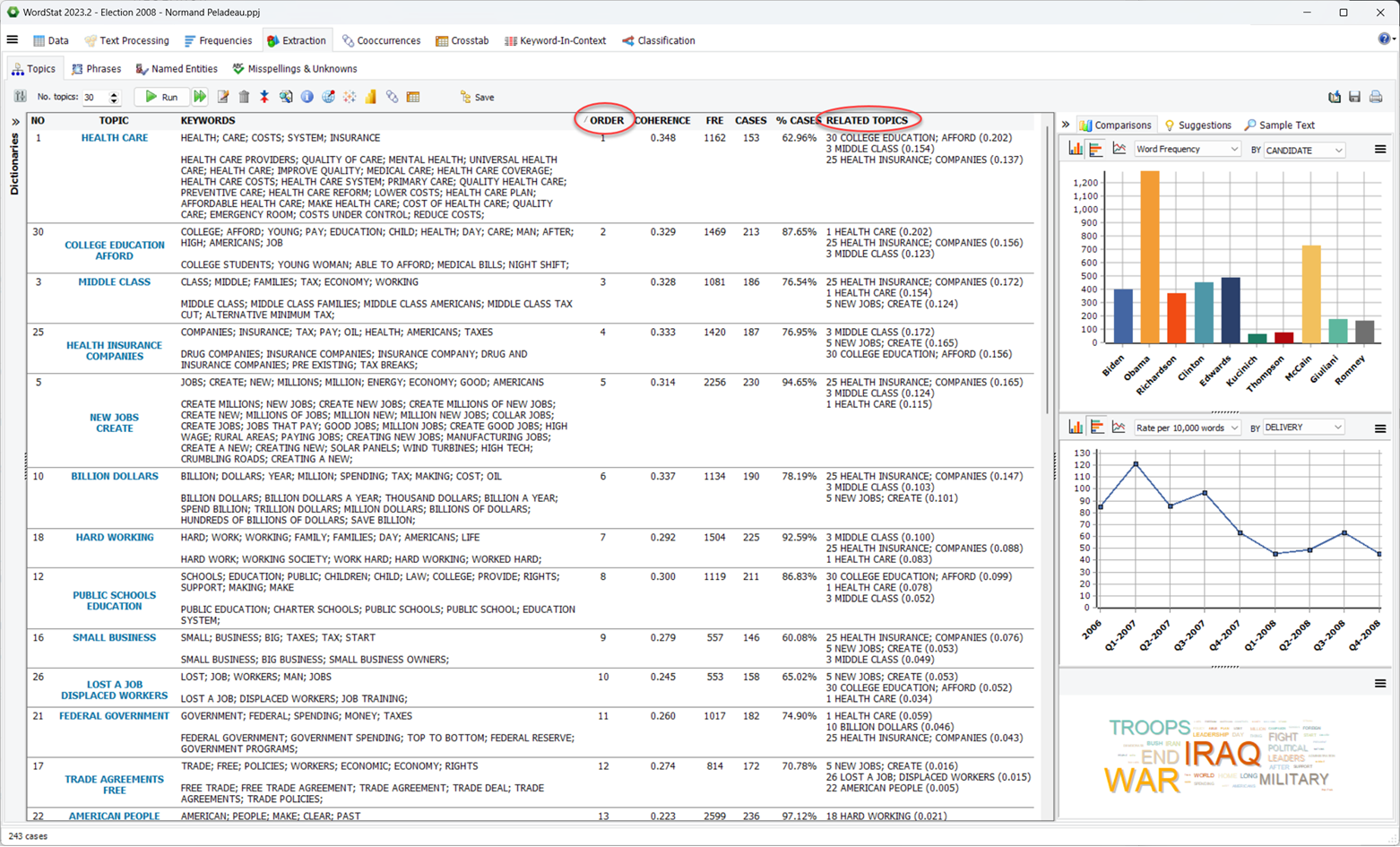
3. New integrated text retrieval feature
A new convenient Sample Text panel on the right-hand of the topic grid can be activated to automatically display sentences or paragraphs that match the selected topic. These text segments are presented in descending order of relevance, with topic words displayed in bold, making it easy to understand the essence of each topic and identify key examples that can be used to illustrate it. This powerful tool provides users with a deeper understanding of their data and facilitates more effective communication of their findings.
4. Improved Top Enrichment Speed
Thanks to significant optimization efforts, the topic enrichment process has been dramatically accelerated, resulting in performance gains of up to 10 to 20 times faster than previous versions.
5. Instantaneous Phrase Extraction
Leveraging the power of multicore processing, phrase extraction is now seamlessly integrated with the main text processing, enabling users to access results almost instantaneously. For instance, on a dataset of over 50,000 customer reviews, extracting the 5000 most frequent phrases can now be completed in just 0.4 seconds, compared to the 14 seconds required by the previous version.
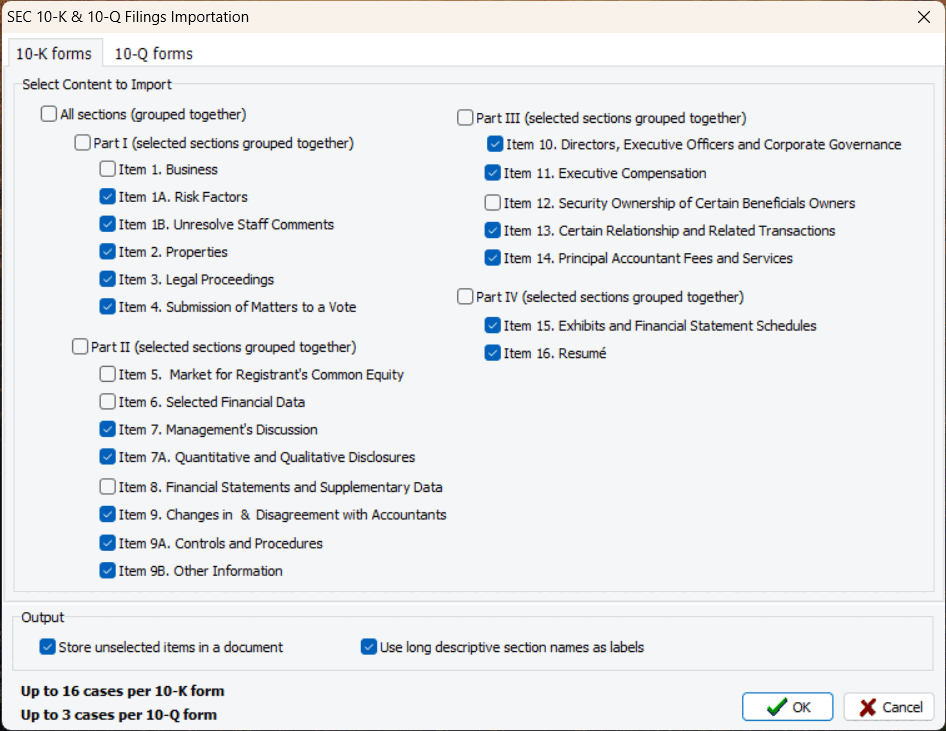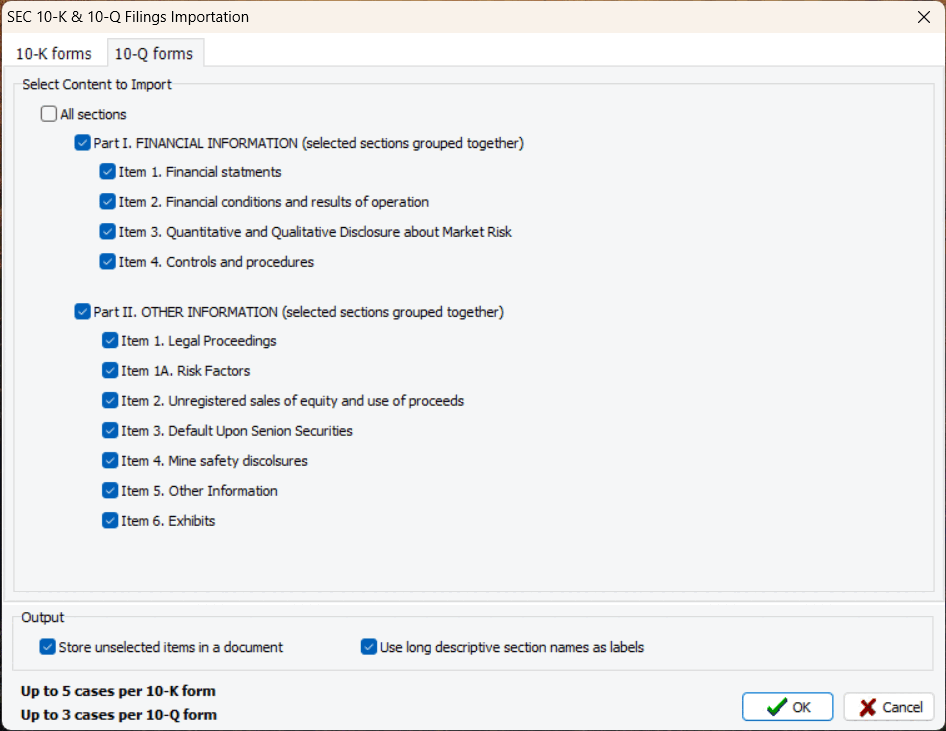
6. Importation of 10-K and 10-Q Financial Filings (2023.1)
A new importation routine enables users to import specific sections of 10-K and 10-Q financial filings, and store them separately or merge them into single documents. The extraction routine automatically recognizes the company’s name, time period (quarter and year), and stores them as variables for easy analysis.
7. Export Text Analysis Results to Power BI (2023.1)
WordStat now offers seamless integration with Microsoft Power BI, allowing users to export text analysis results and metadata to Power BI Desktop for interactive dashboards and reports. By exporting text analysis results and metadata to Power BI Desktop, users can create compelling visualizations, gain deeper insights from their data, and easily share their findings with others.

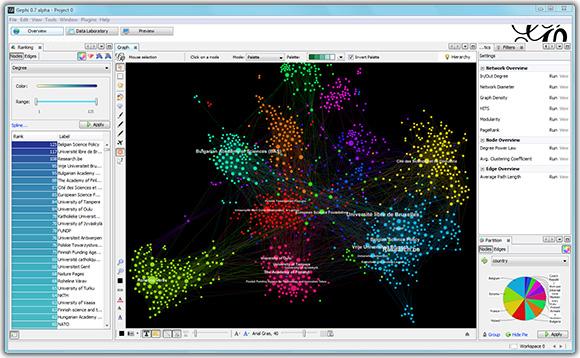
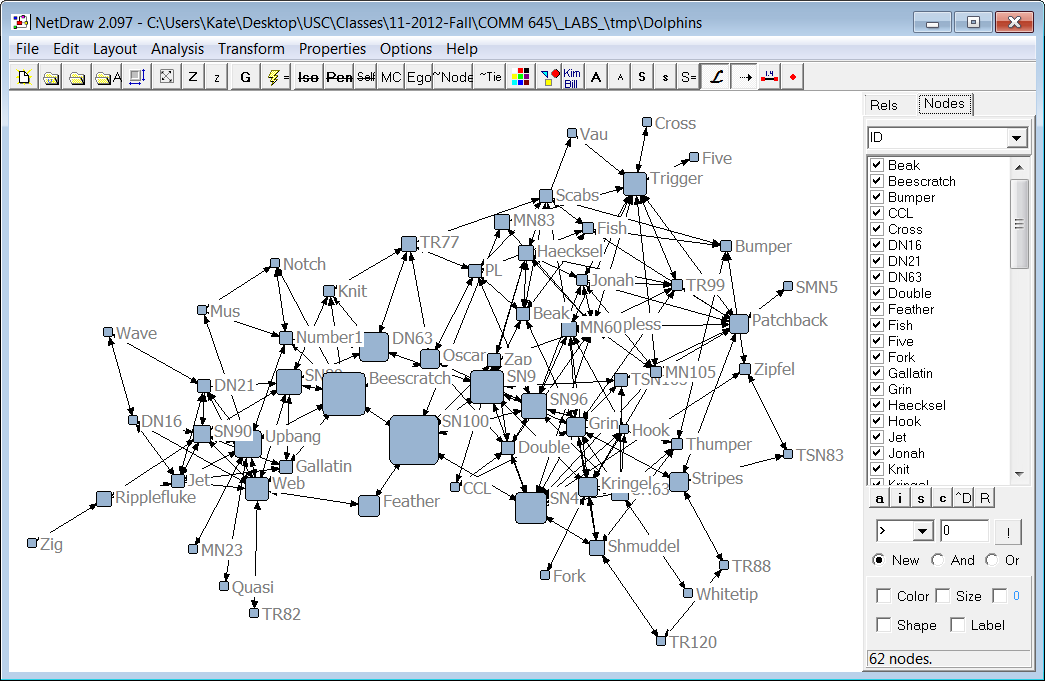
8. Push Co-occurrence Data to Gephi or NetDraw (2023.1).
With the new option available from the Dendrogram page, users can now export co-occurrence data, along with additional information such as frequency and cluster number, to social network analysis software like Gephi and NetDraw. These tools provide powerful visualizations that help users identify patterns and relationships within their data. Gephi offers layout algorithms and interactive features for real-time exploration, while NetDraw provides visualization options for network graphs.
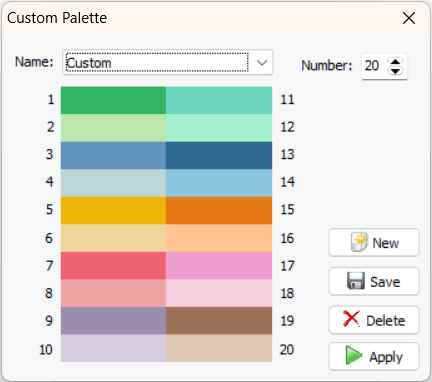
9. Custom Chart Palettes (2023.1)
WordStat 2023 introduces a new feature that allows users to create custom color palettes. This feature provides greater control over the colors used for charts, word clouds, clustering, and other visualizations, enabling users to customize their output to suit their specific needs.
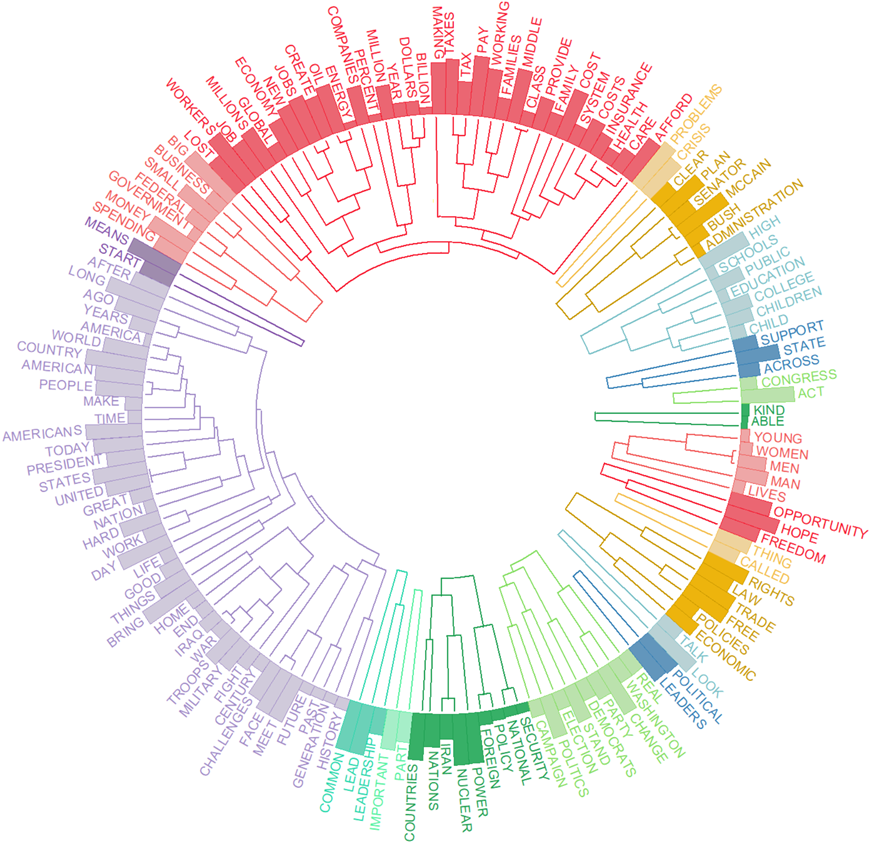
10. Circular Dendrograms (version 2023.2)
The new circular dendrograms use space more efficiently than vertical ones. In a vertical dendrogram, the height of the dendrogram can become quite large, requiring more vertical space to display. Circular dendrograms, on the other hand, arrange the branches in a circle, making more efficient use of space. Circular dendrograms may be more aesthetically pleasing and can be more visually appealing in presentations and publications.
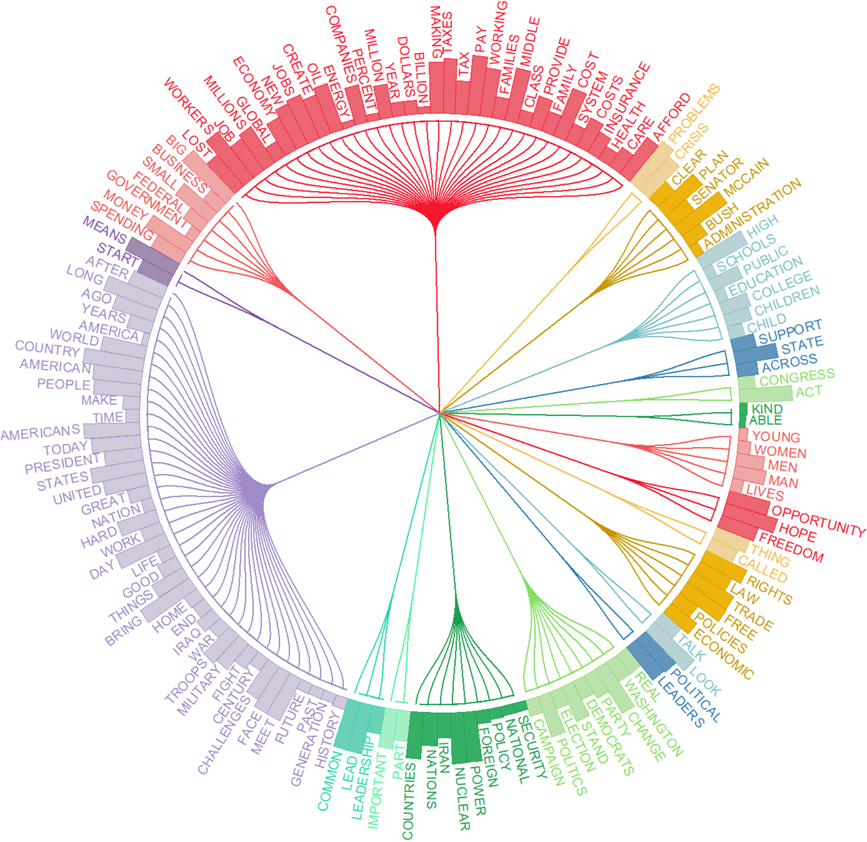
11. Topic clustering and inter-topic similarity information (version 2023.2)
A new topic modeling option allows one to perform cluster analysis on a topic solution. An additional column will display the top 3 most similar topics. It will also order topics so that similar topics will tend to be close to each other.
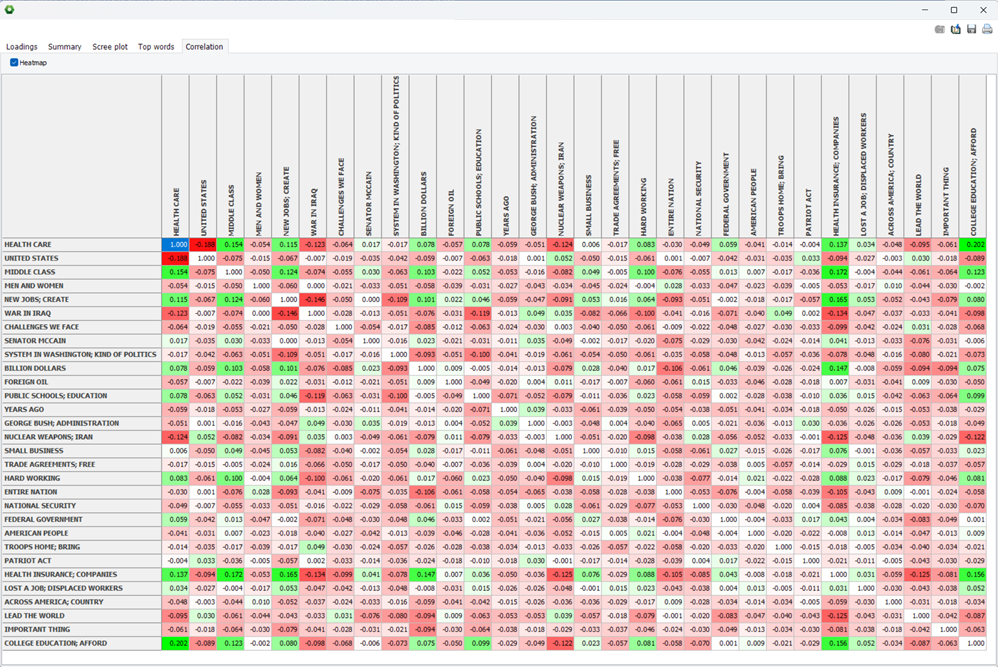
12. Topic correlation table (version 2023.2)
The topic statistics dialog box now includes a topic-topic correlation table allowing one to assess similarity between topics. Columns can be sorted to order topics in ascending or descending order of similarity and an optional heatmap can highlight related items in shade of green (positively correlated) or red (negatively related).
Introduced in Version 2022
1. Highly optimized topic modeling with factor analysis
In WordStat 2022, we implemented a new multithreaded factor analysis routine that is up to 65 times faster than prior versions. It means that large problems that would have taken an hour to compute can now be obtained in less than a minute. We were also able to increase the factor analysis capacity to 10,000 words (from 3,000 in prior versions).
Our own research efforts have shown that topic modeling using factor analysis produces topic solutions that are more coherent as well as more diverse than topic modeling techniques relying on LDA and neural network techniques (Peladeau & Davoodi, 2018; Peladeau, 2022). It also has the additional benefit of being stable, yielding identical results every time. However, its main inconvenience has always been its speed and capacity. This brought us to implement in WordStat 8, a special topic extraction routine using non-negative matrix factorization (or NMF). This technique yields much more quickly results that are quite similar to those obtained using factor analysis. However, its probabilistic implementation causes results to differ slightly from one run to the other, which some researchers find somewhat disturbing. It is important to note that almost all other popular topic modeling techniques in computer sciences produce topic solutions that are even more unstable than our custom implementation of NMF. The much-improved speed and capacity of the new factor analysis topic modeling routine will likely be appreciated by those looking for optimal and stable topic solutions.
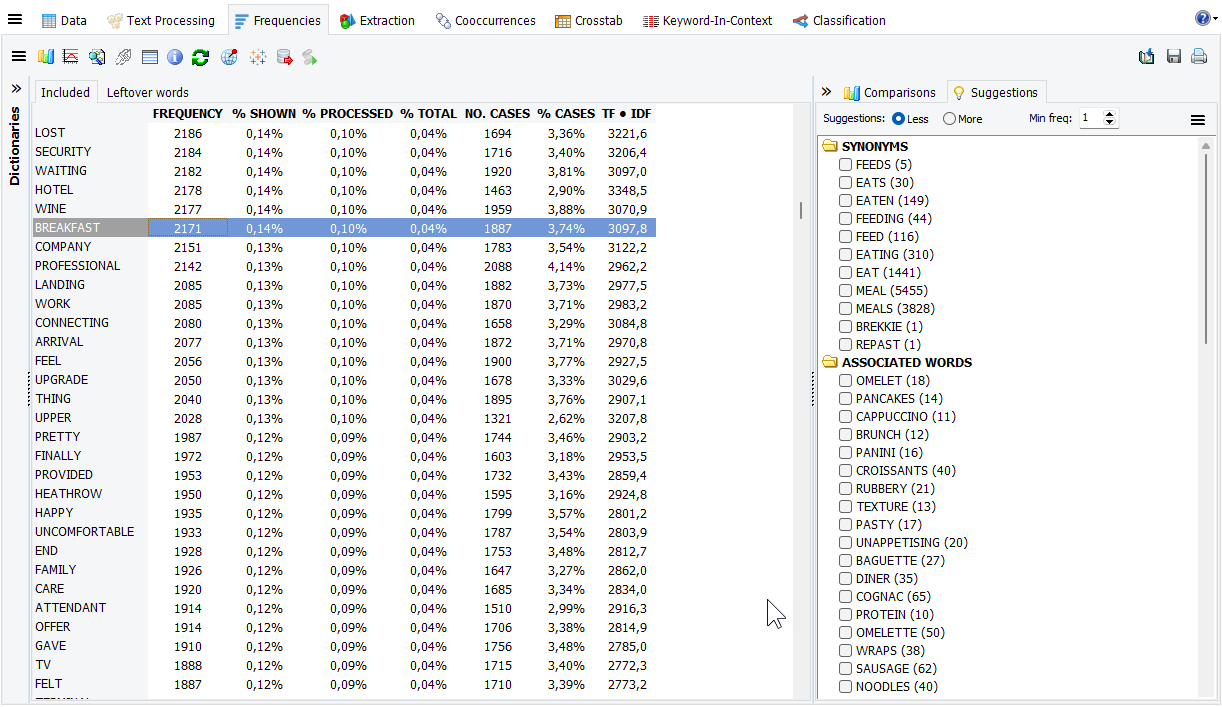
2. Improved suggestions on the Frequencies page
The Suggestions panel in prior versions of WordStat displayed synonyms, antonyms, and related words for languages for which a thesaurus was available. It also presented words starting with the same initial letters, allowing one to identify some misspellings as well as related words. A new Associated Words section now retrieves from the text corpus other words semantically, syntactically, and statistically related to the selected word(s) in the frequency table. This new feature should work in any language. Entries will be listed, by default, in descending order of relevance. Synonyms, antonyms, and related words will also be sorted in descending order of relevance, facilitating the identification of appropriate suggestions. One is still able to sort those entries alphabetically or in descending order of frequency. Also, a new frequency filtering option lets one to filter out low-frequency suggestions, allowing one to focus on more frequent suggestions.
Since this new way of extracting related words and ordering suggestions is language-independent, it will be especially useful for people analyzing languages for which there is no thesaurus. Yet, we found that even when such linguistic resources are available, the additional suggestions based on the contextual use of words, and the sorting of existing synonyms and related words by relevance should greatly facilitate the identification of appropriate items.
3. New suggestions tab for the phrase extraction routine.
The Overlap panel has been replaced with a Suggestions panel, displaying phrases semantically, syntactically, or statistically related to the selected row(s) in the phrase frequency table, in addition to the overlapping phrases. This feature is also language-independent.
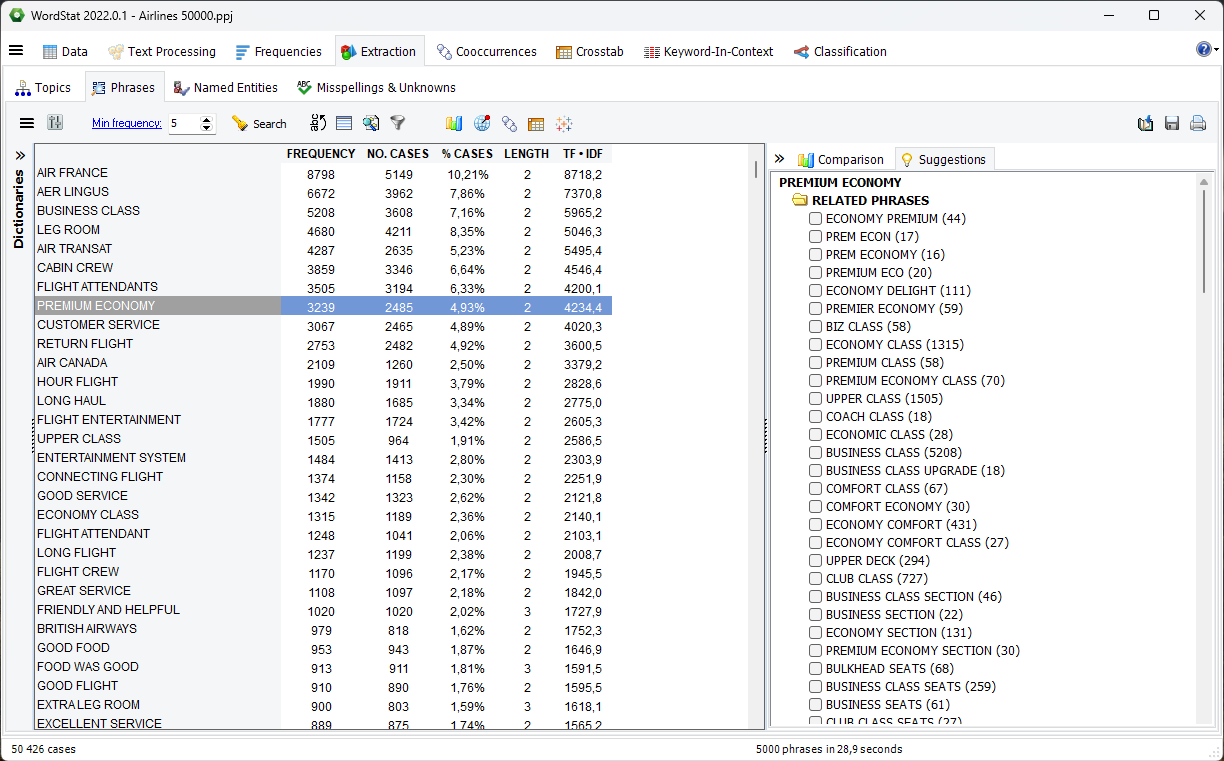
4. Improvement to Named Entity Recognition.
A new Related panel has been added to the Named Entity Recognition page. Selecting, a single named entity will bring related named entities, as well as those belonging to the same class (people, place, organization, etc.). Selecting more than one example of a specific class (for example, several cities) will also retrieve more items belonging to this class. A contextual menu also allows one to move any item to the categorization dictionary or to the exclusion list. A keyword-in-context search may also be performed on selected suggestions.
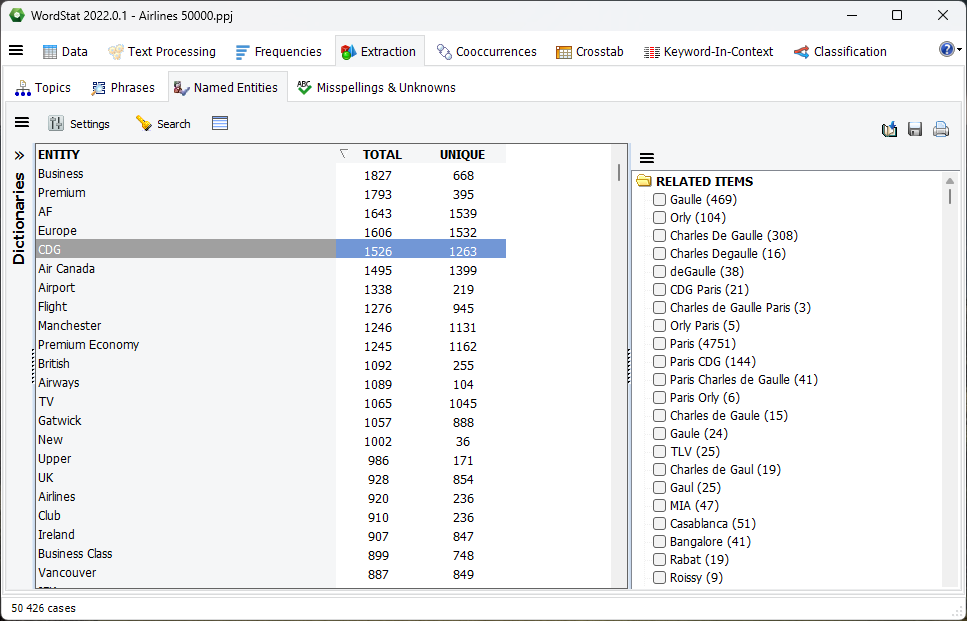
5. Highlighting of contextual words in keyword-in-context tables.
When assessing words in a categorization dictionary or candidate for inclusion one often needs to look at the presence of additional keywords in the context of the appearance of a target word or phrase. A new highlighting feature allows one to specify a list of words and phrases to look for in the surrounding context of the word. This list is automatically populated when the KWIC list is called from the topic modeling or from the dendrogram or when assessing items in a content category containing multiple entries.
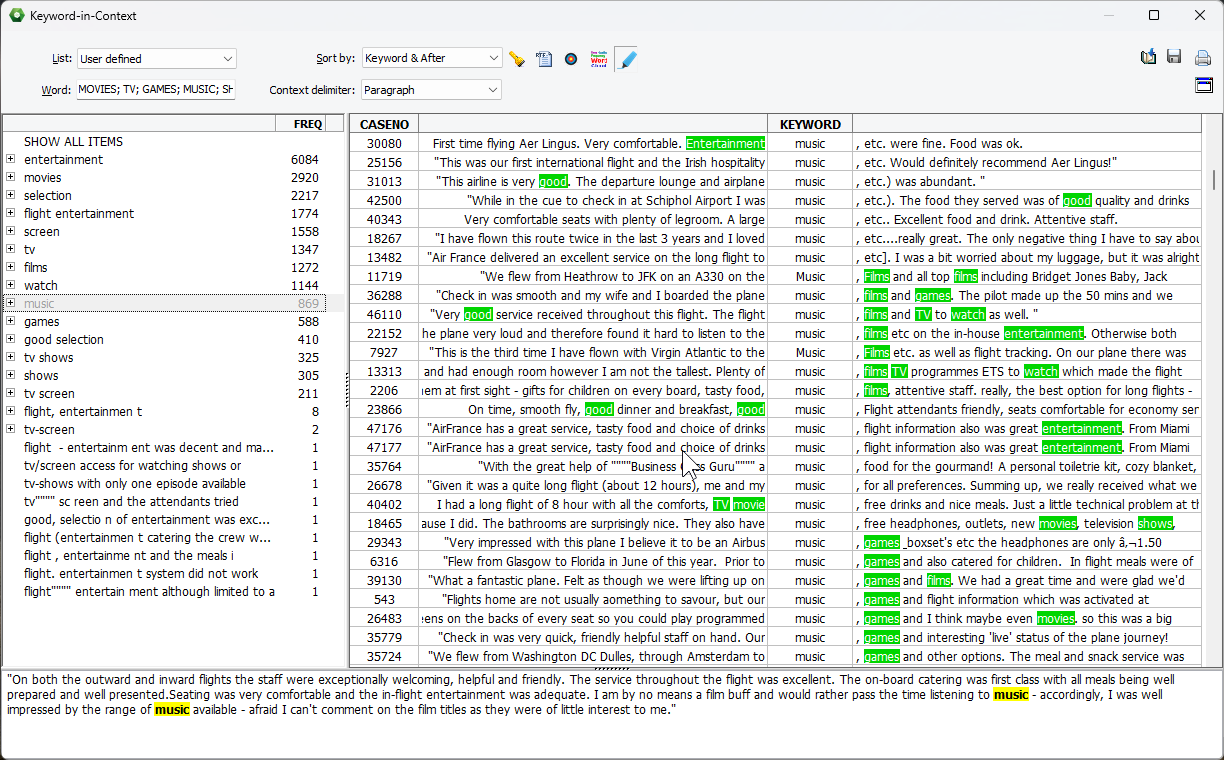
6. Filtering items in correspondence plots on frequency or distance from the origin.
Correspondence plots of more than a few hundred items may create a dark mass of overlapping items at the center of the plot (the origin). A new slider control has been added to hide items that are either less frequent or close to this origin. Unless one wants to identify what is common to all classes of an independent variable, the most interesting items are those that are far from the origin since they are the ones that characterized different classes. Filtering out those items allows one to identify differentiating items more easily.
7. Improved keyword retrieval
Results of a keyword search are now sorted in descending order of relevance, taking into consideration both the frequency and variety of matched items in relationship with the length of the retrieved text segment. A new frequency column can also be used to sort on frequencies only.
8. Computation of a string variable by concatenation
A new data transformation command allows one to compute a string variable by concatenating values of several existing variables (number, strings, dates, etc.) as well as typed text. Such a procedure may also be used to initialize a string variable with a constant string value.
9. Persistent comparison chart settings
The chart type and statistics as well as the color palette of these comparison charts are now linked to the variable name and are stored in the project settings. Those options should remain constant across pages (frequencies, phrases, topics modeling, dendrogram, etc.) and between sessions reducing the need to constantly readjust those options.
What’s New in Version 9.0?
1. Full Unicode Support
We always try to select language-independent text analytics techniques. This has allowed users to analyze text data in more than 50 languages. However, to analyze languages not supported by their default Windows installation, the user needed to change some Windows settings. And while it was possible to analyze datasets in multiple languages, some combinations of languages were simply not possible. The new Unicode version of WordStat allows one to analyze any of these without any setting changes as well as new languages previously not supported such as Chinese, Japanese, or Thai. Word segmentation routines for the previous three Asian languages have also been added.

2. Integration of R and Python Pre- and Post-Processing Scripts
In 2018, we introduced the possibility to create Python preprocessing scripts to WordStat 8. Version 9.0 extends this capability by offering the possibility to create preprocessing scripts in R as well. More importantly, it is now possible to create post-processing scripts in those two programming languages allowing one to perform custom analysis on the original or transformed text data or on quantified results obtained through content analysis on those documents. Such a feature offers endless possibilities to extend the features of WordStat such as implementing new machine learning algorithms, advanced statistical modeling techniques, or custom data transformation. Sample scripts have been included to compute text readability metrics, detect languages, apply other topic modeling techniques (LDA or STM) or create predictive models using machine learning (SVM, kNN, etc.).
![]()

3. Automatic Spelling Correction
A new spell-checking engine has been written from scratch to achieve much faster and more accurate spelling corrections, allowing the implementation of an automatic spelling correction feature with minimal impact on the existing text processing speed of WordStat. The intelligent spelling correction can even correct the spelling of unknown terms such as technical vocabularies, proper nouns, etc. Results can be automatically saved to the substitution list for revision and corrections.
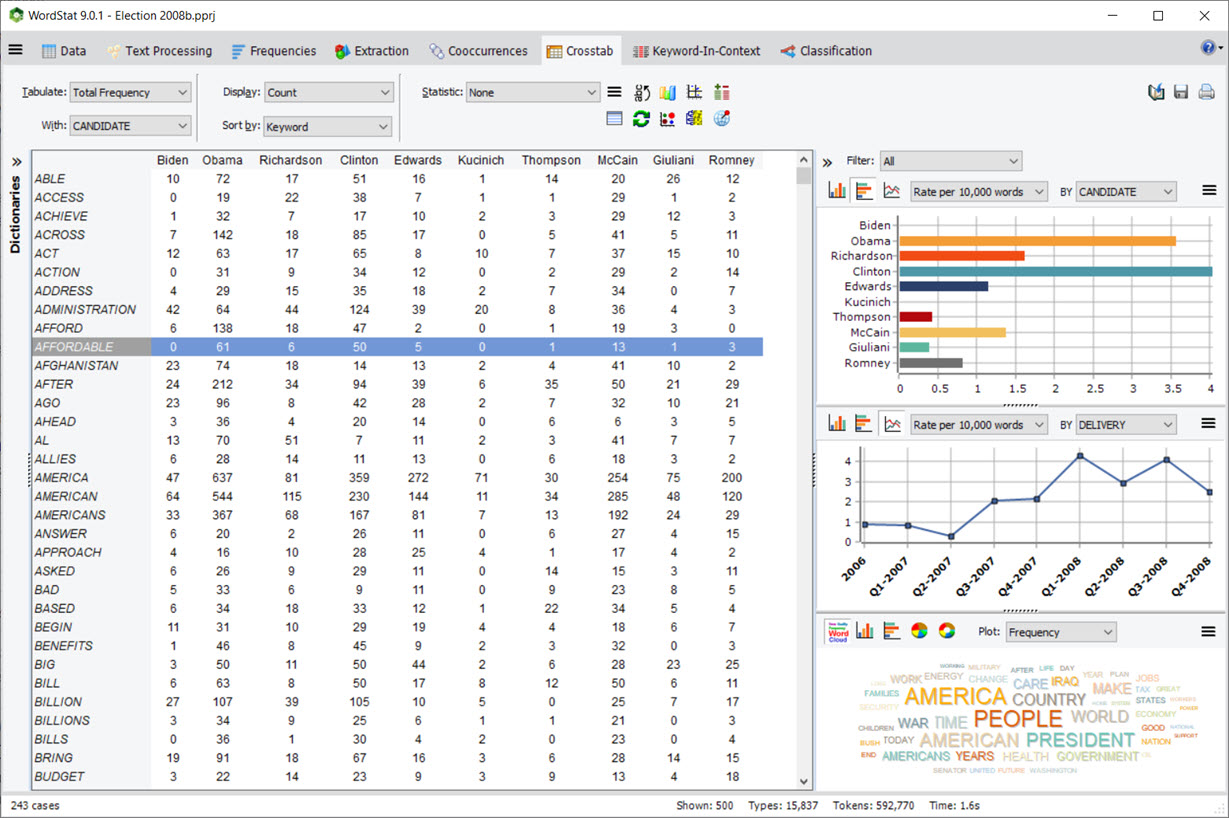
4. Crosstabulation with Charting Panels and Filtering
The crosstab page now includes a chart panel allowing one to quickly plot the distribution of selected rows of the crosstabulation table for the values of the currently selected variable or any other variable. A filtering list box also allows one to analyze such distributions for a single value or a set of values of the selected variable.
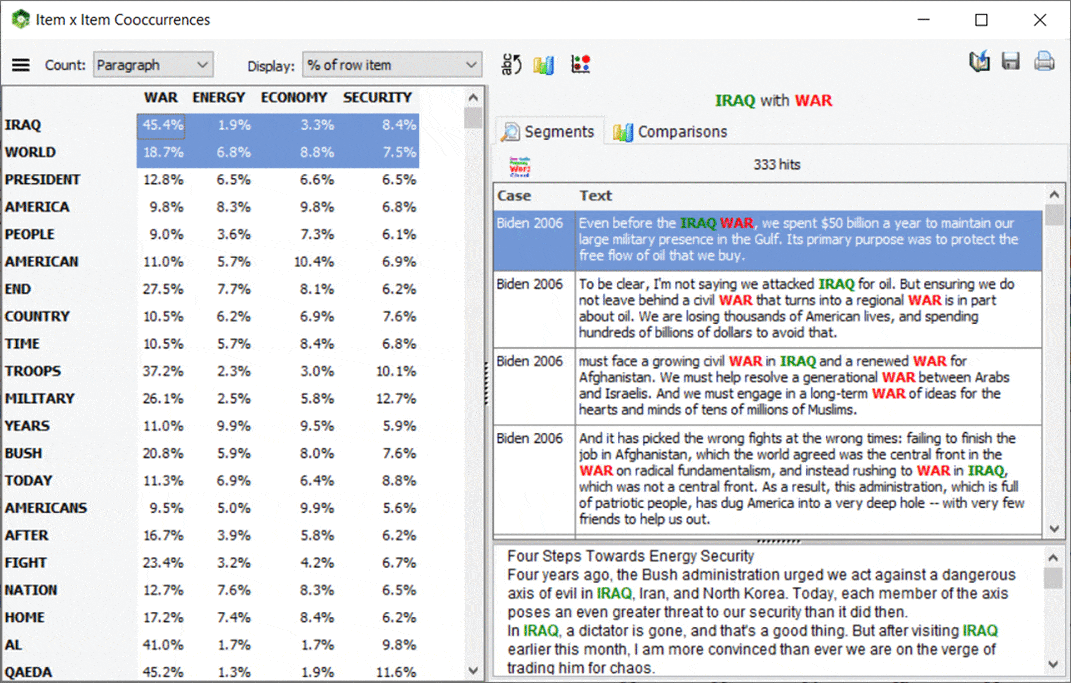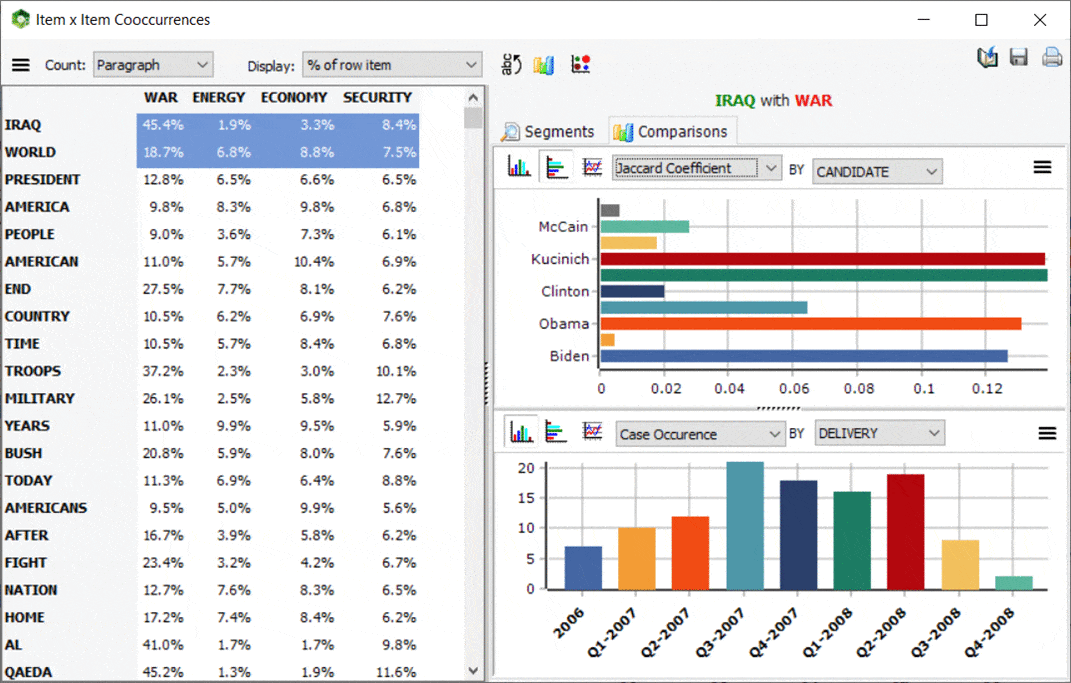
5. Interactive Co-occurrence Matrix
A new interactive matrix feature has been added to the co-occurrences page allowing one to focus on specific co-occurrences. The main results consist of a table displaying a choice from various co-occurrence statistics. Such matrix is also highly interactive allowing one to transform specific rows into new columns or vice versa using simple drag-and-drop operations. A charting panel on the left also allows one to assess the distribution of a specific co-occurrence across other variables. One may also obtain a quick view of all text segments associated with a specific co-occurrence. This new feature of WordStat may also be called from the frequency list by selecting target items (words or content categories) that should be displayed as columns, right-clicking, and selecting Co-Occurrence Matrix.
6. Importation of Nexis UNI and Factiva Files
Introduced in QDA Miner 6.0 in 2020, it is now also possible in WordStat to import news transcripts from the LexisNexis and Factiva output files. After selecting one or multiple .DOCX or RTF files obtained from those services, WordStat will extract and store in separate variables the title and body of the news transcript, its source, the publication date, and other relevant information. Such a feature should prove useful for reputation management, brand management, crisis communication, media framing analysis, comparative media studies, etc.

7. Batch Processing of Topic Models
Choosing the number of topics to extract using topic modeling techniques remains a question for which there is, to our knowledge, no definitive answer. We may even raise doubts as to whether such an optimal number exists. In fact, one may even suggest that information obtained using different settings may well serve different purposes or reveal different aspects of a reality. In such a context of uncertainty, researchers often want to compare various solutions. The new batch processing feature allows one to compute multiple topic models by systematically varying the number of topics to extract, and for the probabilistic method (e.g. NNMF), to perform several runs using the same settings in order to assess the stability of the results. All topic model solutions are temporarily aggregated in the report manager allowing one to compare solutions obtained in multiple runs using different settings.
8. Create Word Clouds on Keyword Retrievals & KWIC Results
Interactive word clouds and word frequency tables can now be obtained directly on keyword retrieval and keyword-in-context (KWIC) results allowing one to quickly identify words associated with specific content categories, or those appearing, before, after a specific target item.
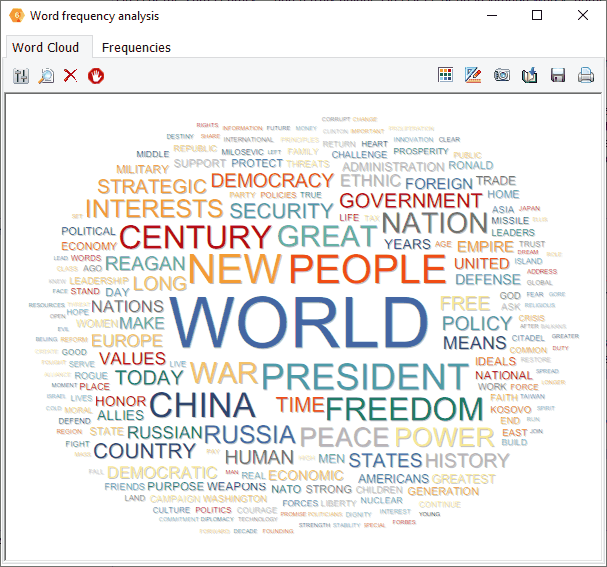
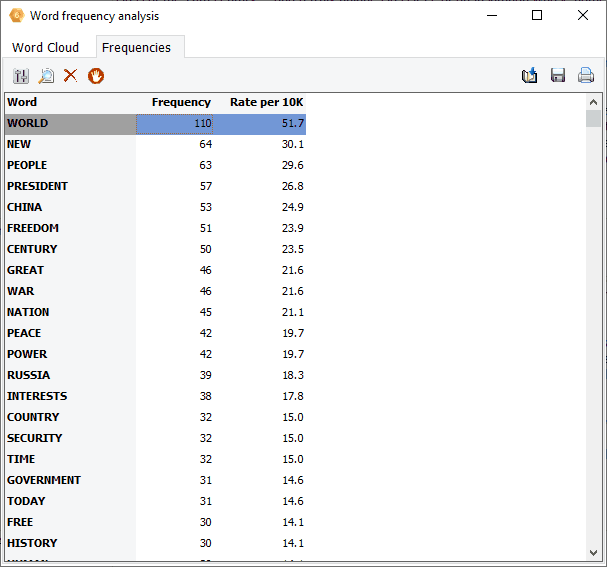
9. More Powerful Proximity Rules
The number of conditions in proximity rules has been increased from four to a maximum of twenty conditions. If you believe it is not enough, let us know.
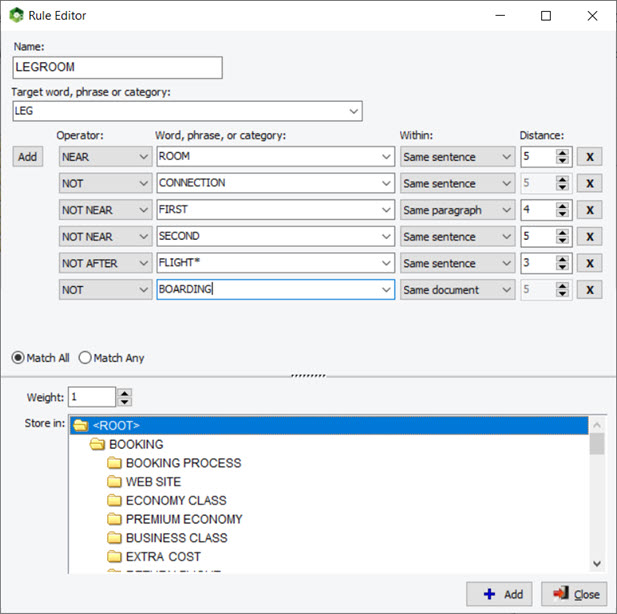
10. Preview Effect of Wildcards and Dictionary Interactions
Using wildcards in a dictionary is quite powerful yet potentially troublesome since it could match items that you may not have thought of. For example, an entry like TAX* may allow you to match TAX, TAXES, TAXATION, but will also match words such as TAXI, TAXONOMY, TAXIDERMY, etc. Also, WordStat rules for matching items and preventing double-counting may also produce unexpected results caused by other entries in your categorization model. A new panel on the right of the exclusion and categorization pages allows you to easily identify new entries that would be matched using a *wildcard at the end of a word but also of possible conflicts with other entries in your dictionary.
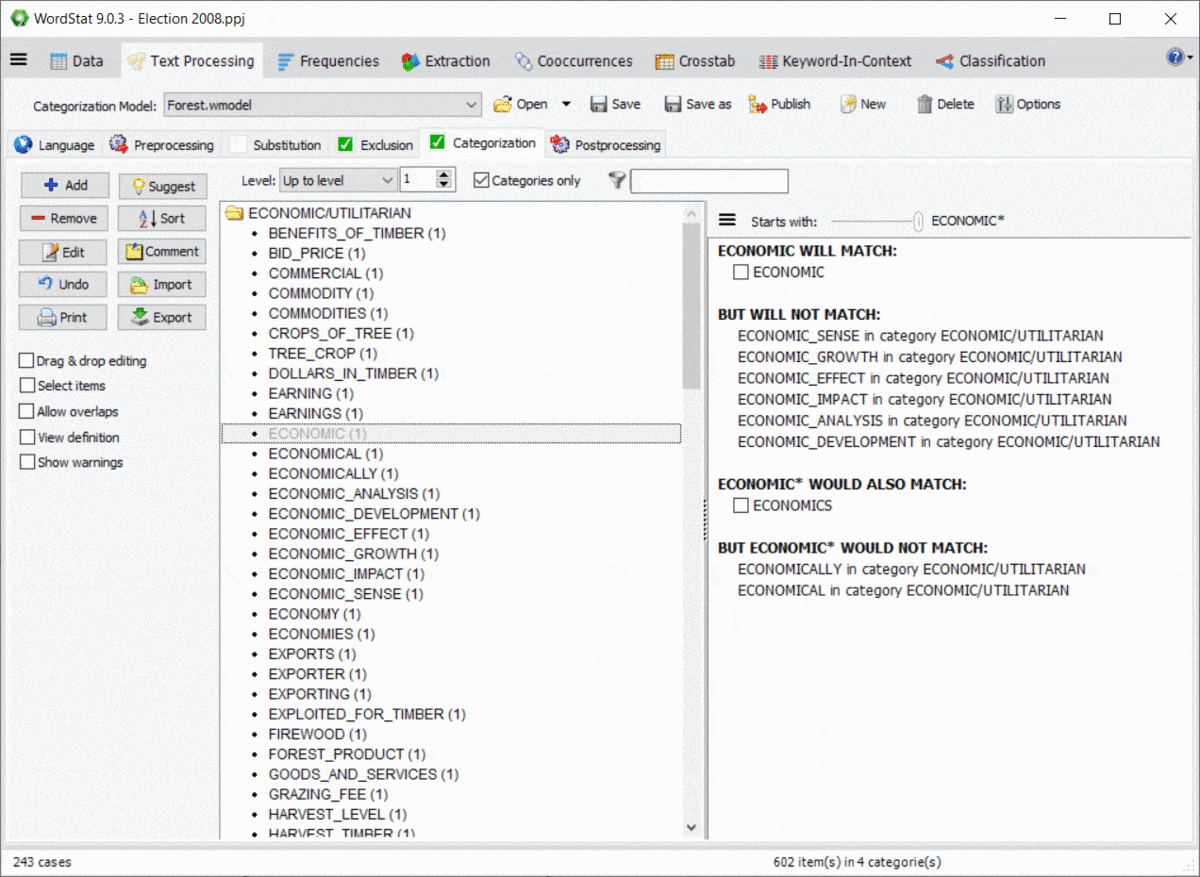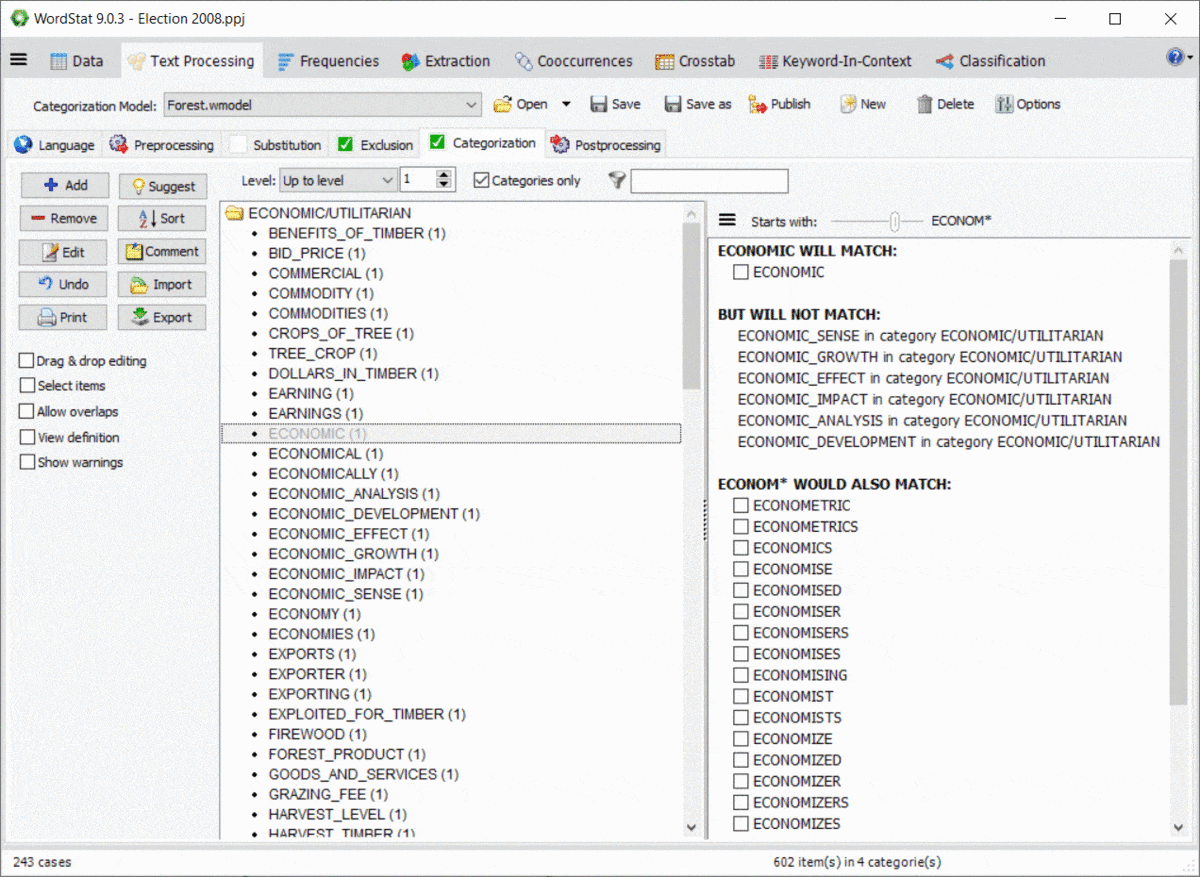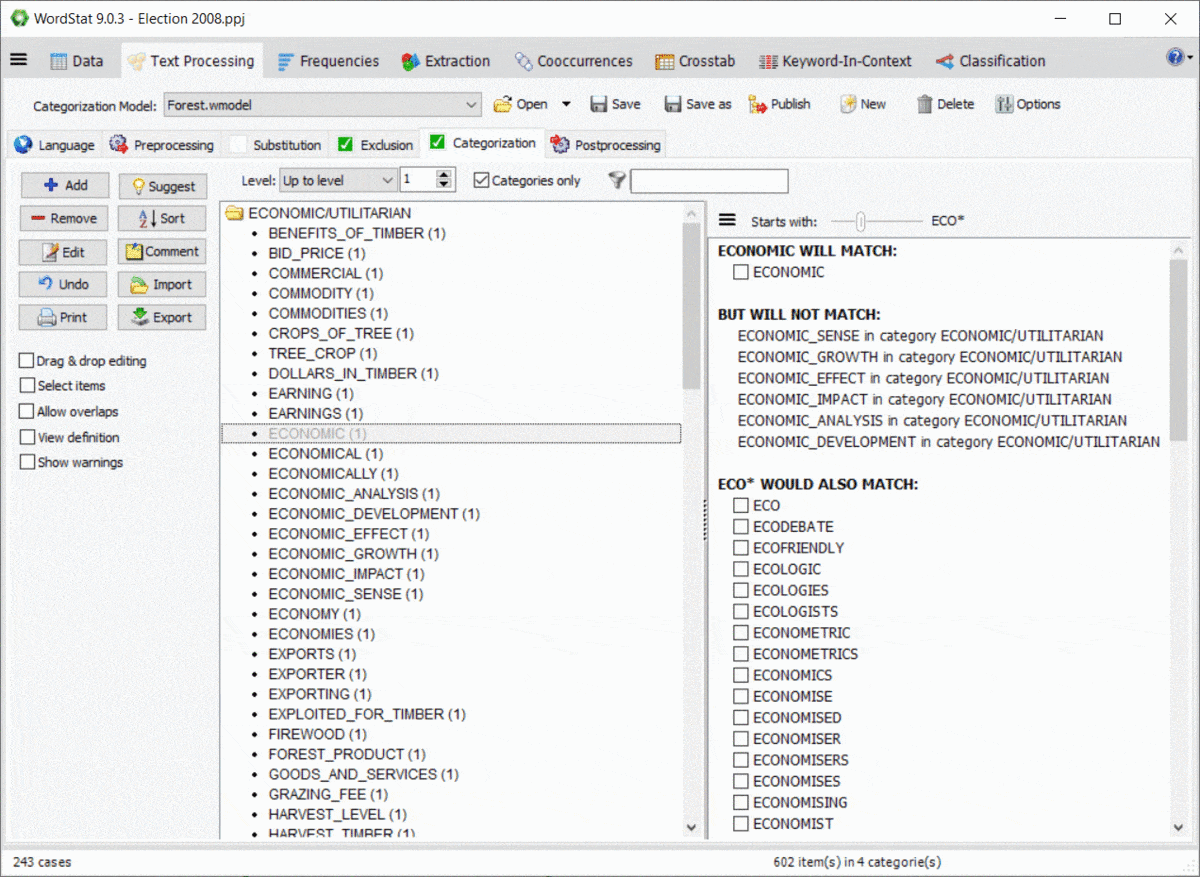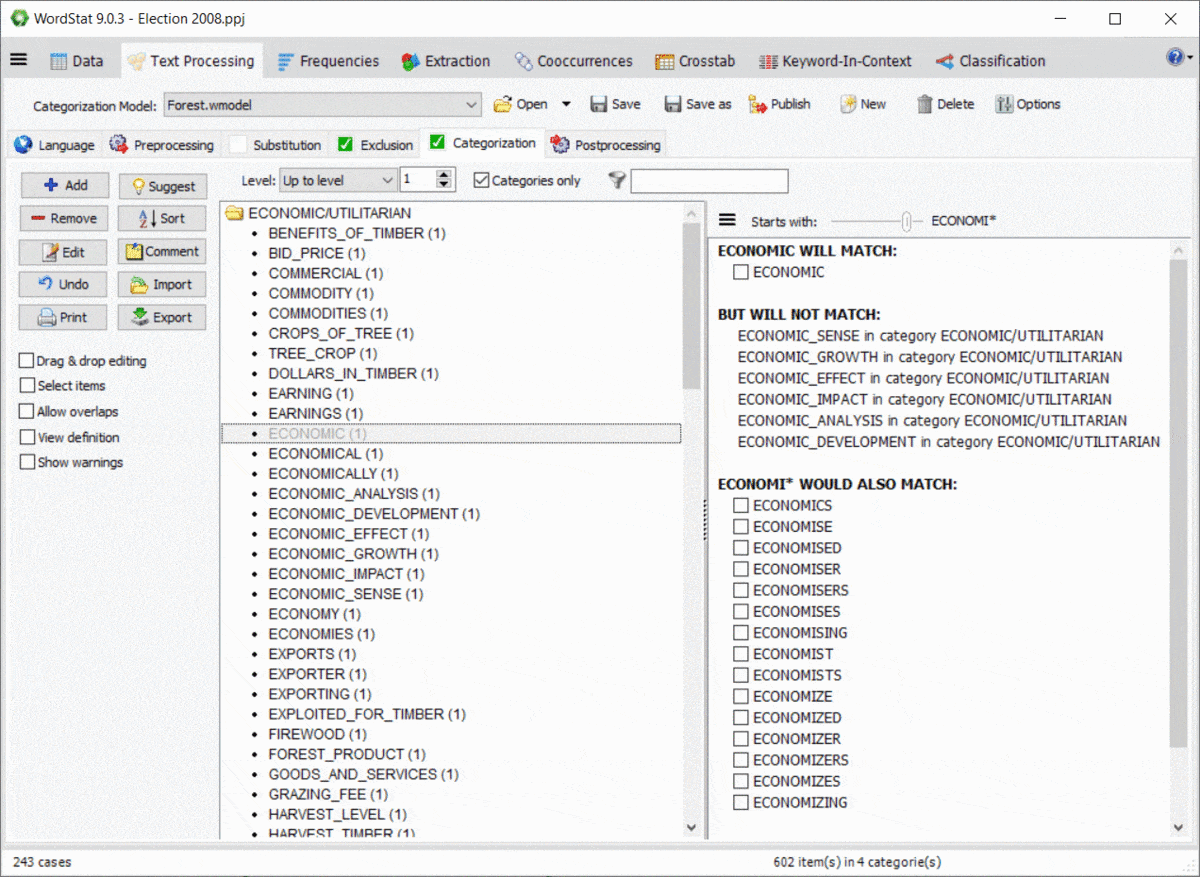
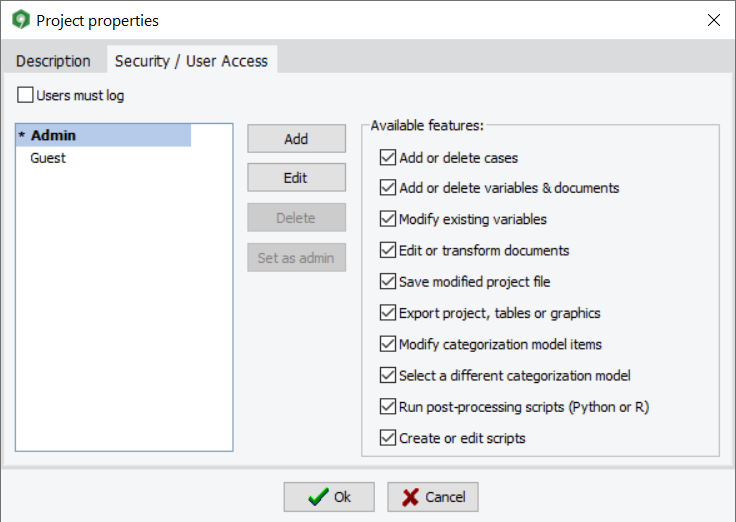
11. Password protection of project files
WordStat 9.0 now offers the possibility to password protect project files, restricting the access of specific projects to authorized users. A dialog box allows the project administrator to create new user accounts and specify which operation each user can perform. One may limit data editing, data importation, or transformation, as well as exportation of project data, tables, and graphics. Alternatively, you may choose to let the users perform any transformation they want but prevent them from saving the project file.
12. New Options for Cleaning Data
The preprocessing page now includes options to automatically remove URLs from text messages as well as speakers’ designations in news and interview transcripts.
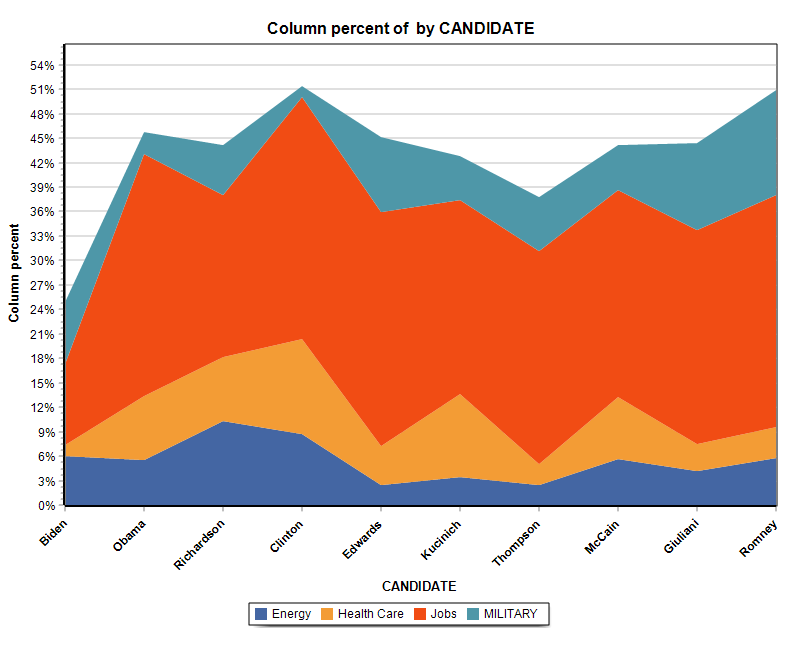
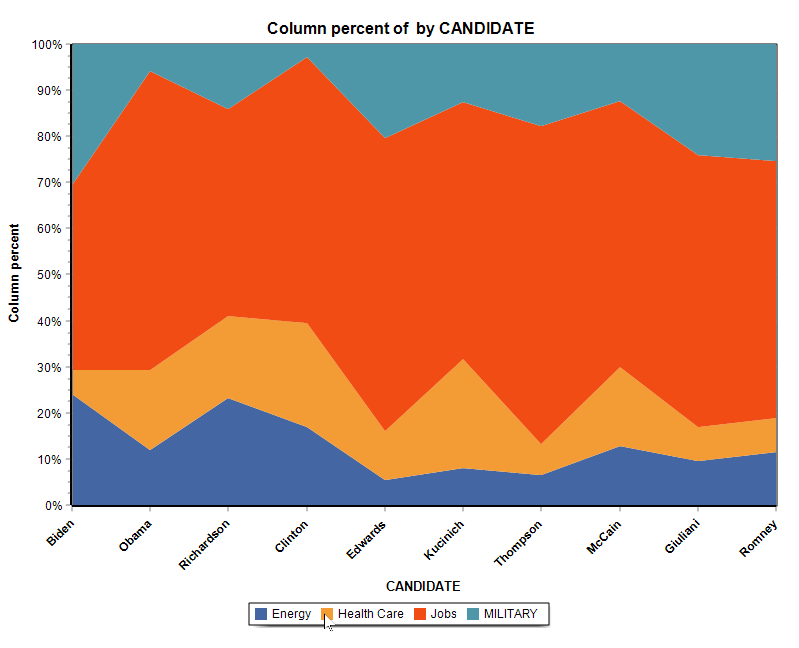
13. New Stacked Area Charts
The charting feature of the Crosstab page adds the possibility to create two types of stacked area charts.
14. Colored Items in Correspondence Plot
Color gradients may now be used to represent the position of specific items or variable classes on the third (depth) dimension or 2D and 3D correspondence plot. Up to four colors may be chosen to create those gradients.

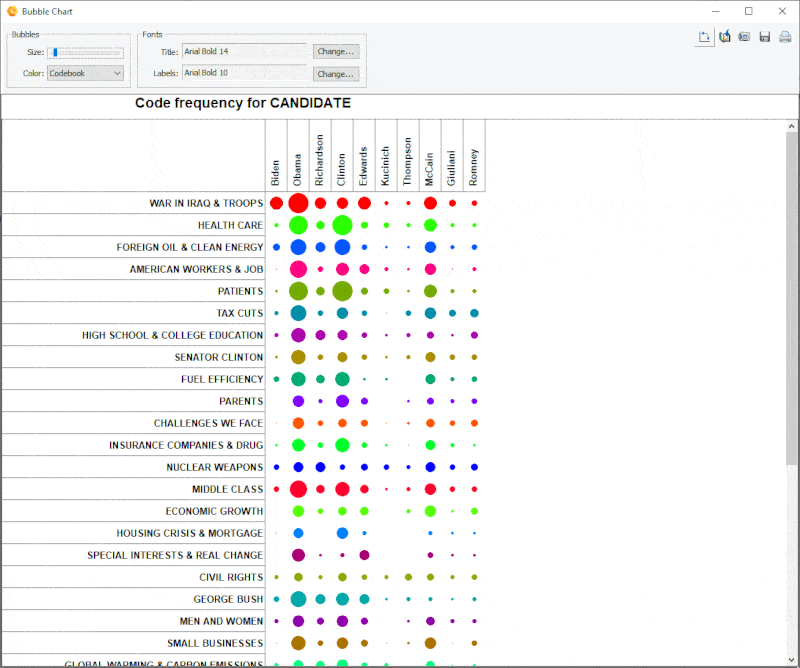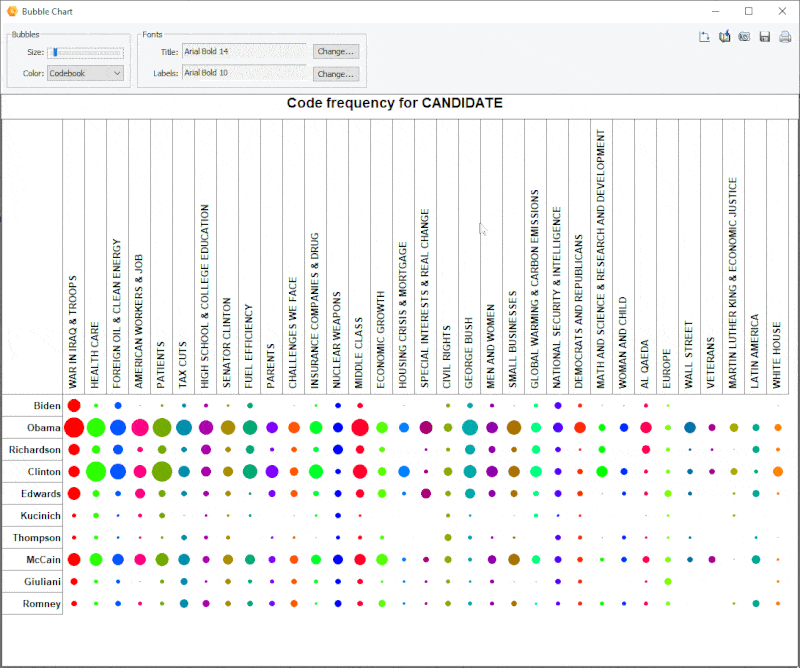
15. Improved Bubble Chart
It is now possible to transpose rows and columns of bubble charts.
16. Link Analysis Buffer
A link analysis buffer allows one to move back to previous link diagrams and then forward.
17. Faster and More Precise Topic Enrichment
WordStat goes beyond typical topic modeling, offering ‘a unique topic enrichment feature that identifies associated phrases, potential exceptions, and misspellings. It also generates relevant topic names automatically. With version 9, this topic enrichment feature is now twice as fast as before and performs better word-sense disambiguation for a more accurate list of exceptions. It also provides better suggestions for spelling corrections.
18.Improved Speed and Accuracy of Existing Spelling Corrections
The existing spelling correction feature is now up to 30x faster, requiring only a second or two to suggest spell corrections for tens of thousands of unknown words.
19. New .PPRJ File Format
A new file format with a new file extension (.pprj) was created, providing improved support for Unicode data. However, WordStat 9 retains backward compatibility with the prior versions of all our software and can open and analyze current project files (.ppj) created by QDA Miner, SimStat, or older versions of WordStat.
20. Numerous Additional Improvements
Several additional options and interface improvements have been made to existing dialog boxes, graphics, data management, and data analysis features.
New features of WordStat 8 can be viewed here