FUNCIONES
QDA Miner es un software de análisis cualitativo fácil de usar para organizar, codificar, anotar, recuperar y analizar colecciones de documentos e imágenes. QDA Miner ofrece más asistencia informática para la codificación que cualquier otro software de investigación cualitativa en el mercado, lo que le permite codificar documentos de forma más rápida y también más confiable.
Este software de análisis de datos cualitativos integra herramientas estadísticas y de visualización avanzadas para identificar rápidamente patrones y tendencias, explorar pautas en su codificación, así como describir, comparar y probar hipótesis. Esta es una de las razones por las que QDA Miner es considerado por muchos como el primer y único software cualitativo de métodos mixtos verdadero en el mercado actual.
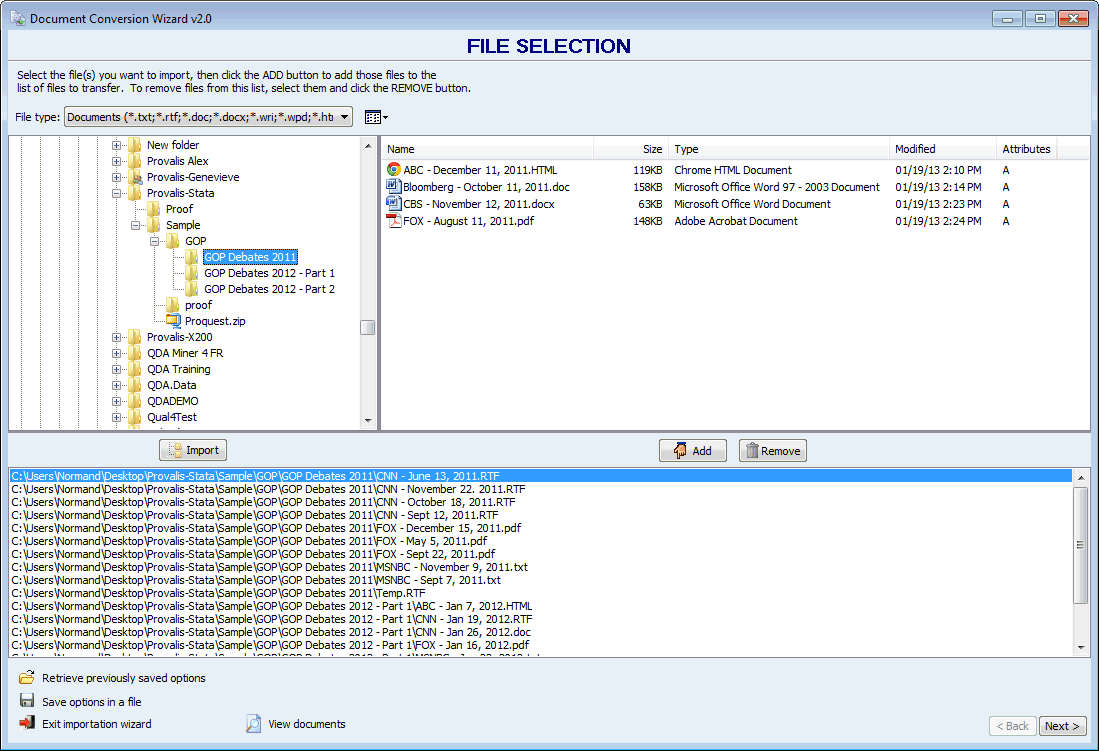
Importación desde múltiples fuentes
QDA Miner le permite importar directamente contenido en varios idiomas desde diversas fuentes:
- Importar documentos: Word, PDF, HTML, PowerPoint, RTF, TXT, XPS, ePUB, ODT, WordPerfect.
- Importar archivos de datos: Excel, CSV, TSV, Access.
- Importar desde redes sociales: Reddit, YouTube, RSS.
- Importar desde correos electrónicos: Outlook, Gmail, MBox.
- Importar desde encuestas web: Qualtrics, SurveyMonkey, Surveygizmo, QuestionPro, Voxco, triple-s.
- Importar desde herramientas de gestión de referencias: Endnote, Mendeley, Zotero, RIS.
- Importar gráficos: BMP, WMF, JPG, GIF, PNG. Extraiga automáticamente cualquier información asociada a esas imágenes, como ubicación geográfica, título, descripción, autores, comentarios, etc., y transfórmelos en variables.
- Importar desde bases de datos XML.
- Conexión a bases de datos ODBC disponible.
- Importar proyectos desde software cualitativo: Archivos NVivo, Atlas.ti, Qdpx.
- Importar y analizar documentos en varios idiomas, incluyendo idiomas con escritura de derecha a izquierda.
- Monitorear una carpeta específica e importar automáticamente cualquier documento o imagen almacenada en ella, o supervisar cambios en el archivo de origen original o en servicios en línea.

Organice sus datos
Varias funciones le permiten organizar fácilmente sus datos de manera que el proceso de codificación y análisis sea sencillo:
- Agrupe, etiquete, clasifique, añada o elimine documentos rápidamente, o busque duplicados.
- Asigne variables a sus documentos de forma manual o automática mediante el Asistente de Conversión de Documentos (por ejemplo: fecha, autor o datos demográficos como edad, sexo o ubicación).
- Reordene, añada, elimine, edite y recodifique variables fácilmente.
- Filtre casos en función de los valores de las variables o de si un documento contiene códigos o no.
- Transforme texto codificado en variables. Esto es muy útil para extraer metadatos relevantes de documentos no estructurados o para transformar un proyecto no estructurado en uno estructurado.
Gestione su libro de códigos
La creación de un libro de códigos es un paso importante en un proyecto de análisis de datos cualitativos. QDA Miner proporciona herramientas específicas que le ayudan a crear y gestionar su libro de códigos de forma creativa:
- Cree y edite fácilmente un libro de códigos.
- Asigne un color y una nota (memo) a un código.
- Asocie una lista de palabras clave a un código para recuperar fácilmente segmentos de texto que contengan dichas palabras.
- Los diccionarios creados con WordStat pueden importarse a QDA Miner y transformarse en códigos y categorías.
- Guarde su libro de códigos en el disco en un archivo independiente para que pueda ser importado y utilizado en otro proyecto.
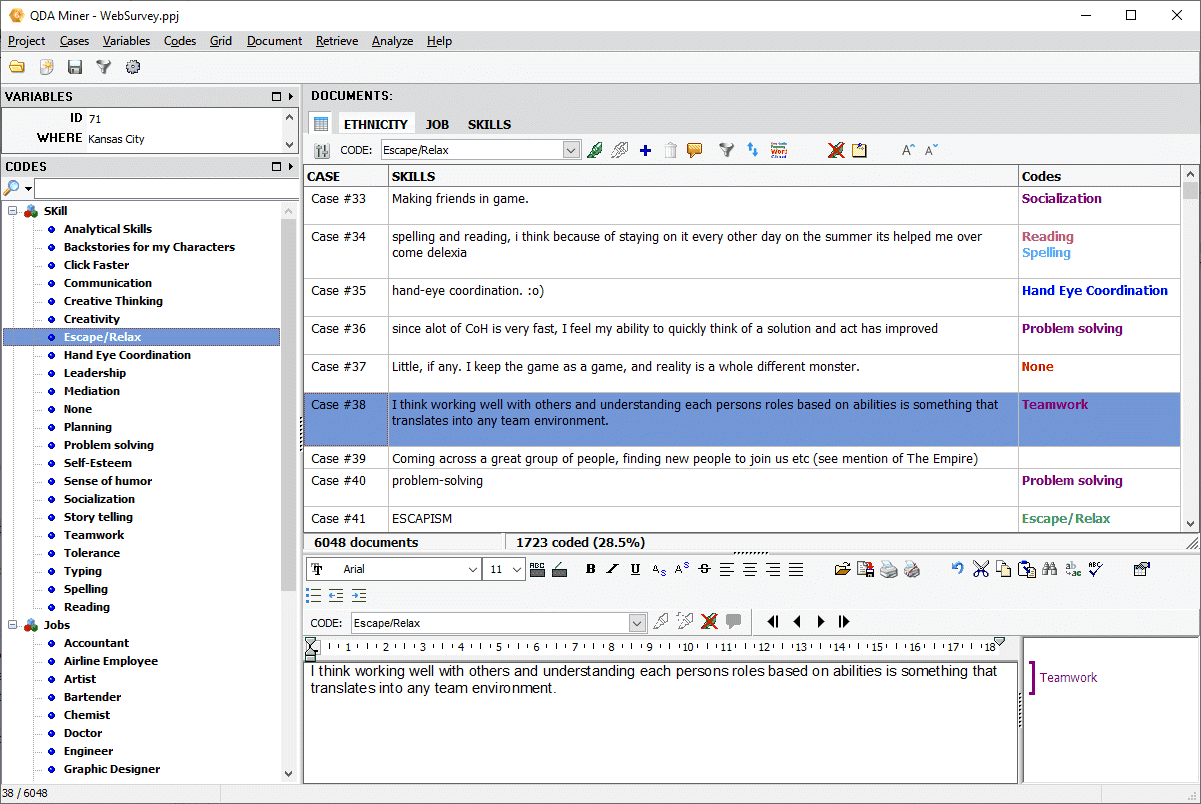
Realice codificación en pantalla
Codifique segmentos de texto e imágenes mediante un proceso de etiquetado cualitativo intuitivo:
- Utilice la codificación y anotación en pantalla de textos e imágenes con una función sencilla de arrastrar y soltar para asignar códigos.
- Varias funciones ofrecen mayor flexibilidad y facilidad de uso, como la división y fusión de códigos, el cambio de tamaño sencillo de los segmentos codificados, la búsqueda y sustitución interactiva de códigos o la agrupación virtual.
- Añada hipervínculos a selecciones de texto o segmentos codificados para dirigirse a una página web, un archivo, otro caso de su proyecto u otros segmentos de texto codificados o no codificados.
- Muestre una vista gráfica general de la codificación de su documento actual para obtener un vistazo rápido de la distribución espacial de la codificación.



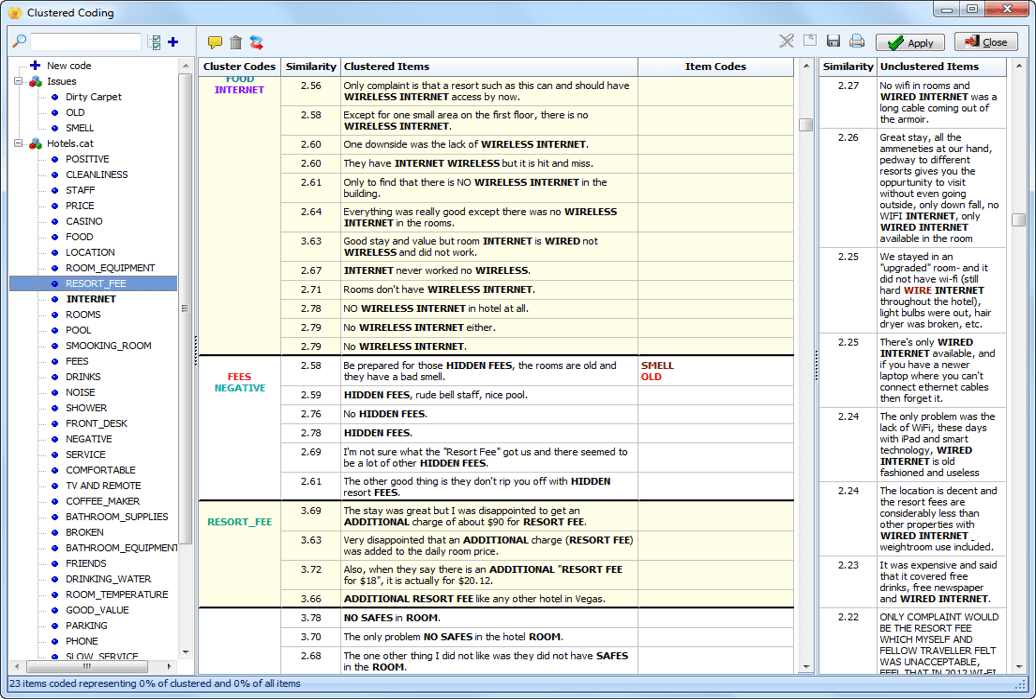
Acelere su codificación
Codifique sus documentos de forma más rápida y confiable con siete herramientas de búsqueda y recuperación de texto:
- La herramienta de Recuperación de Palabras Clave (Keyword Retrieval) puede buscar cientos de palabras clave y frases relacionadas con una misma idea o concepto, permitiéndole localizar todas las referencias a un solo tema.
- La herramienta de Recuperación de Secciones (Section Retrieval) es ideal para recuperar y codificar automáticamente secciones en documentos estructurados.
- La herramienta de Consulta por Ejemplo (Query by Example) puede entrenarse para recuperar segmentos de texto que tengan un significado similar a los ejemplos que usted le proporcione.
- La herramienta de Extracción de Clústeres (Cluster Extraction) agrupa frases o párrafos similares en grupos (clústeres) y le permite codificarlos mediante un editor flexible de arrastrar y soltar.
- La búsqueda por Similitud de Código (Code Similarity) recupera todos los segmentos de texto similares a los que ya han sido codificados. Incluso se pueden buscar elementos similares a códigos definidos en proyectos codificados anteriormente.
- La herramienta de extracción de Fecha y Ubicación es ideal para localizar y etiquetar rápidamente referencias a fechas o ubicaciones geográficas.
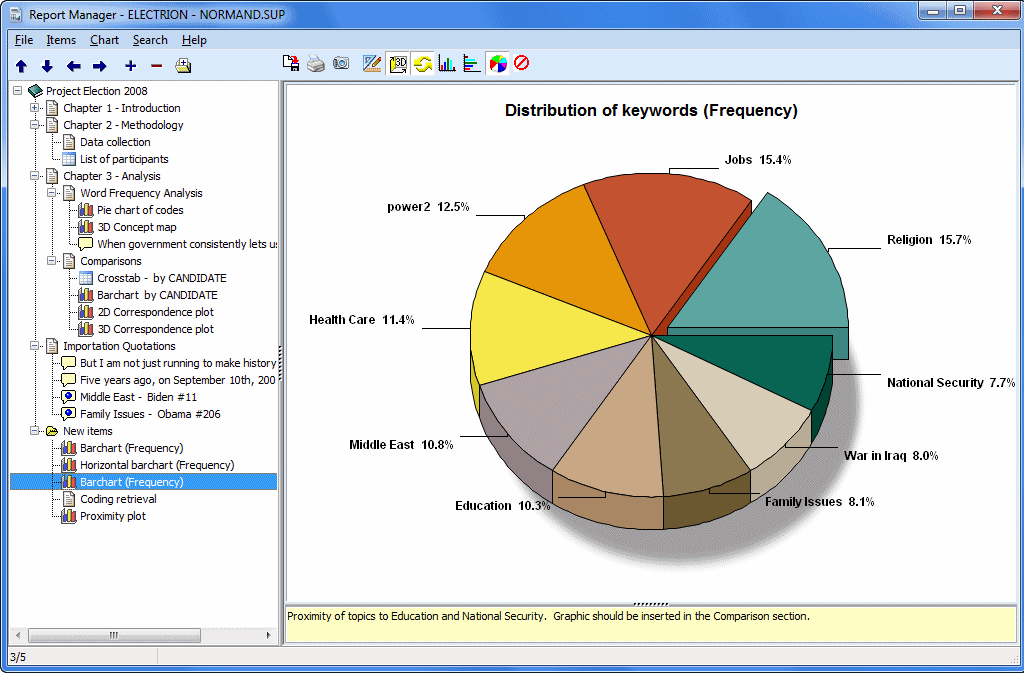
Analice, visualice y explore
Se han integrado numerosas herramientas estadísticas y de visualización en QDA Miner para identificar rápidamente patrones y tendencias, explorar datos, describir, comparar y probar hipótesis:
- Analice la frecuencia de los códigos y explore las conexiones entre ellos mediante el Análisis de Conglomerados (Cluster Analysis), Análisis de Vínculos, Análisis de Secuencias o Escalamiento Multidimensional.
- Observe la relación entre los valores de las variables y los códigos utilizando Tablas Cruzadas, Análisis de Correspondencias o Mapas de Calor (Heatmaps).
- Calcule pruebas estadísticas como Chi-cuadrado, Correlación de Pearson, entre otras, para ayudarle a identificar las relaciones más sólidas. No es necesario adquirir un software estadístico por separado.




Grafique eventos mediante mapas GIS y etiquetado temporal
Todas estas funciones innovadoras convierten a QDA Miner en la herramienta cualitativa de geoetiquetado más potente del mercado:
- Asocie coordenadas geográficas y temporales a una selección de texto o a cualquier segmento de texto codificado o área gráfica, lo que permite localizar eventos tanto en el espacio como en el tiempo.
- Las coordenadas geográficas pueden importarse desde archivos KML o KMZ, o cortarse desde Google Earth y pegarse en QDA Miner. De este modo, se puede saltar fácilmente de un geovínculo a Google Earth.
- Se puede utilizar una herramienta flexible de recuperación de vínculos para filtrar y seleccionar eventos geovinculados o etiquetados temporalmente relevantes, y mostrarlos en un mapa geográfico o en una línea de tiempo.
- En QDA Miner, los usuarios pueden recuperar datos codificados basándose en el tiempo y la ubicación, y graficar eventos en cronologías y mapas.
Utilice el servicio de geocodificación integrado
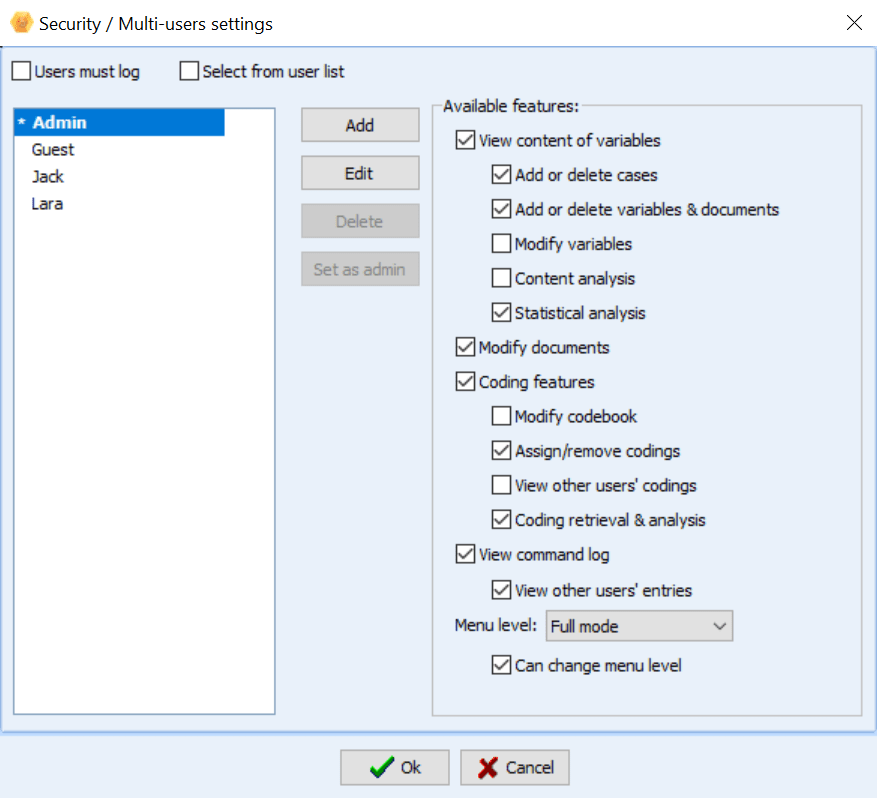
Obtenga un soporte de trabajo en equipo sin igual
QDA Miner apoya el trabajo en equipo de manera altamente eficaz a través de funciones dedicadas:
- Funciones de soporte de equipo mejoradas, como una herramienta flexible de configuración multiusuario que le permite definir qué puede o no hacer cada miembro del equipo.
- Obtenga asistencia en la duplicación y distribución de proyectos a los miembros del equipo.
- Una potente función de fusión (merge) que reúne en un solo proyecto las codificaciones, anotaciones, informes y entradas de registro de diferentes codificadores que trabajan de forma independiente.
- Un módulo único de evaluación del acuerdo entre jueces (inter-raters agreement) para garantizar la confiabilidad de la codificación de múltiples usuarios.
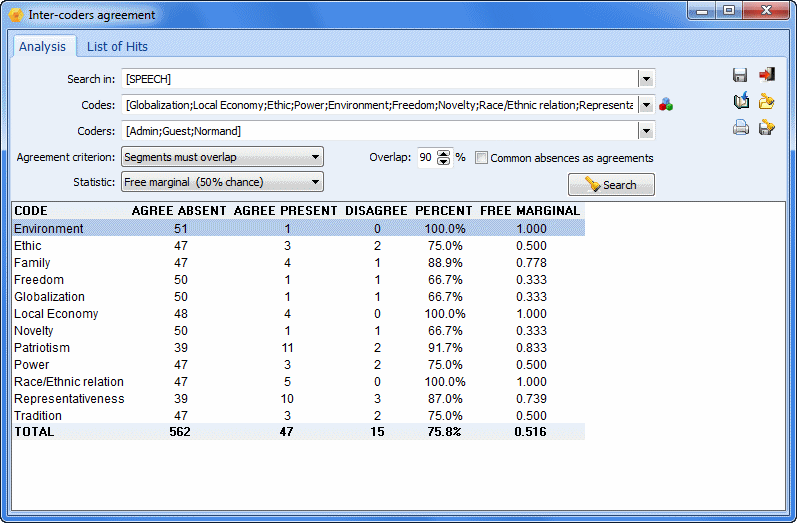
Rastree los cambios
Un potente registro de comandos (log) realiza un seguimiento de cada acceso al proyecto, operación de codificación, transformación, consulta y análisis realizado. Es muy útil para documentar el proceso de análisis cualitativo y supervisar el trabajo en equipo.
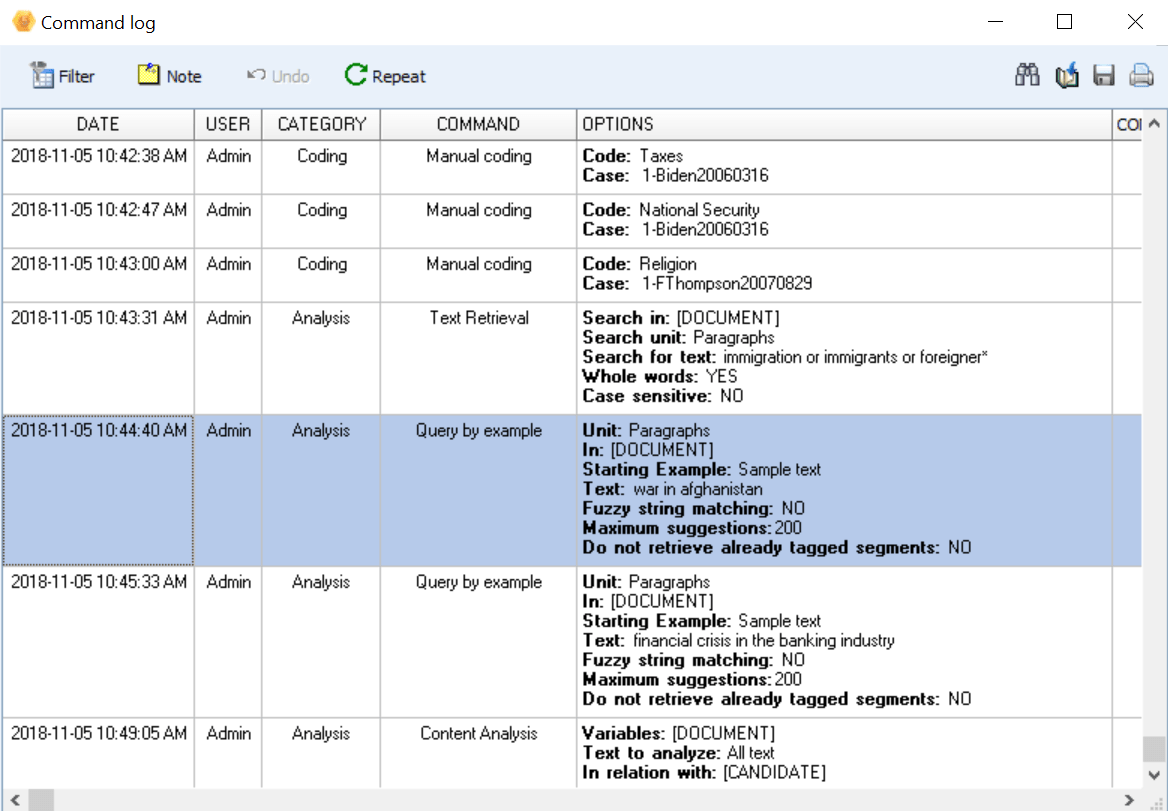
Exporte y comparta resultados
En QDA Miner, puede crear fácilmente gráficos de calidad para presentaciones (barras, sectores, burbujas y mapas conceptuales) y guardarlos como imagen (PNG, JPEG, BMP, WMF, EMF). Las tablas con estadísticas también pueden exportarse fácilmente en diferentes formatos como Word, Excel, CSV, HTML, XML y archivos ASCII delimitados. Las tablas estadísticas de QDA Miner pueden exportar estadísticas directamente a SPSS o Stata (versiones 8 a 15).