Impulsado por IA desde 1998
Software de análisis de contenido y minería de textos para un procesamiento rápido y preciso de grandes volúmenes de información no estructurada
UN ANÁLISIS DE CONTENIDO SUMAMENTE AVANZADO Y SOFTWARE DE MINERÍA DE TEXTO CON INIGUALABLES MANEJO Y CAPACIDADES DE ANÁLISIS
WordStat es un flexible y fácil de usar software de análisis de texto – si usted necesita herramientas de minería de texto para la extracción rápida de temas y tendencias o medición cuidadosa y precisa con herramientas de vanguardia en análisis de contenido cuantitativo. La integración transparente de WordStat con SimStat – nuestra herramienta de análisis de datos estadísticos – y QDA Miner – nuestro software de análisis de datos cualitativos – le da una flexibilidad sin precedentes para analizar el texto y relacionar su contenido a información estructurada, incluyendo datos categóricos y numéricos.
Fácil importación de bases de datos, hojas de cálculo y documentos (incluyendo PDF y HTML), así como exportación de resultados de análisis de texto formatos de archivo comunes en la industria (Excel, SPSS, ASCII, HTML, XML, MS Word) y gráficos (BMP, PNG y JPEG).
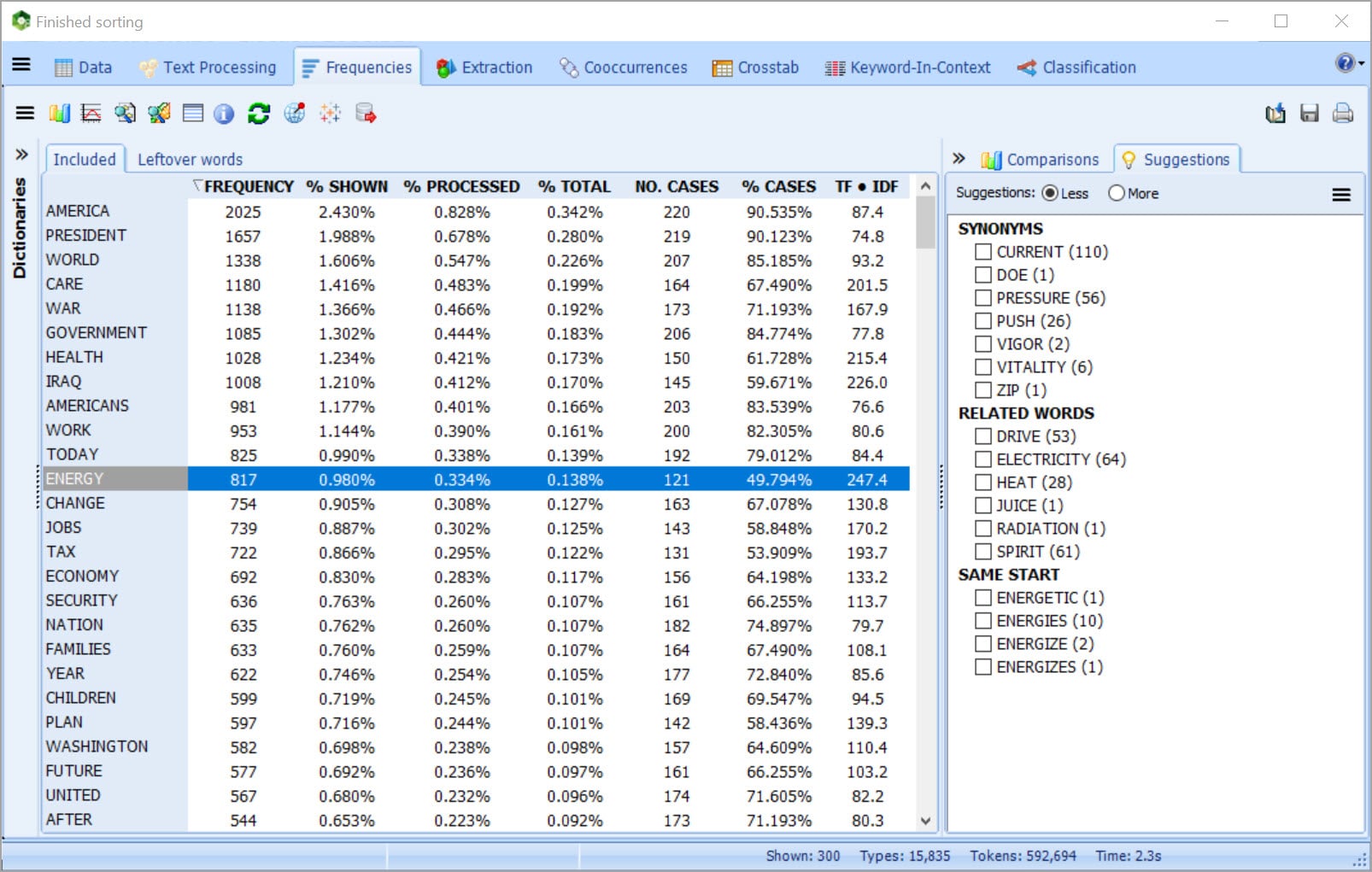
Potentes herramientas de análisis de contenido y de minería de texto para manejar grandes cantidades de información no estructurada. WordStat puede procesar hasta 20 millones de palabras por minuto e identificar todas las referencias a temas específicos o conceptos mediante diccionarios de categorización.
Herramientas de minería de texto y visualización exploratoria integradas, tales como clasificación, escalamiento multidimensional y gráfico de proximidad para extraer rápidamente temas e identificar automáticamente patrones sin necesidad de leer los documentos.
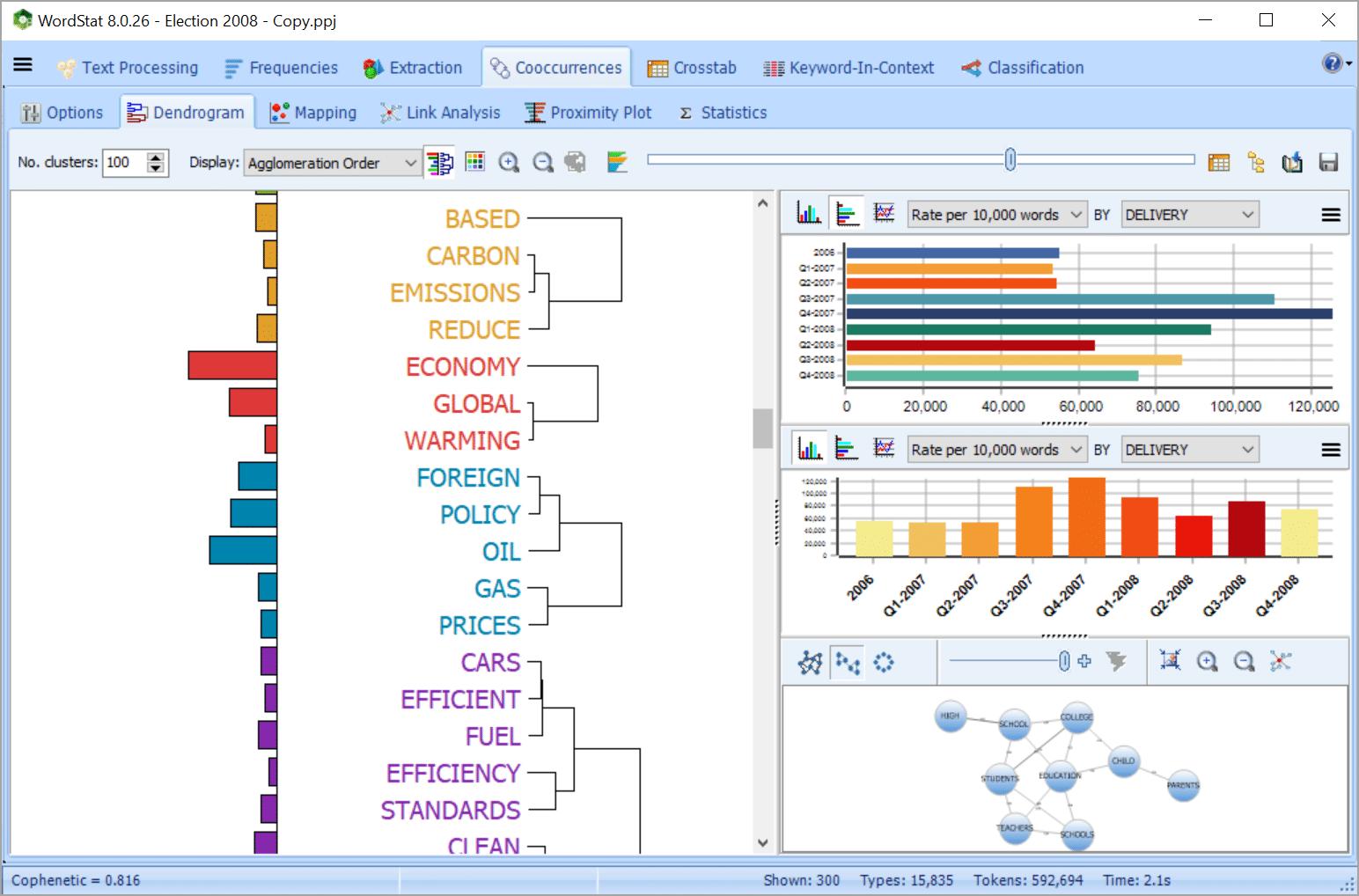
Relacione texto no estructurado con información estructurada tales como fechas, números o datos categoriales para identificar tendencias temporales o diferencias entre los subgrupos o para evaluar las relaciones de cualquier tipo de datos categoriales o numéricos tales como grupos de edad, grado, etc.
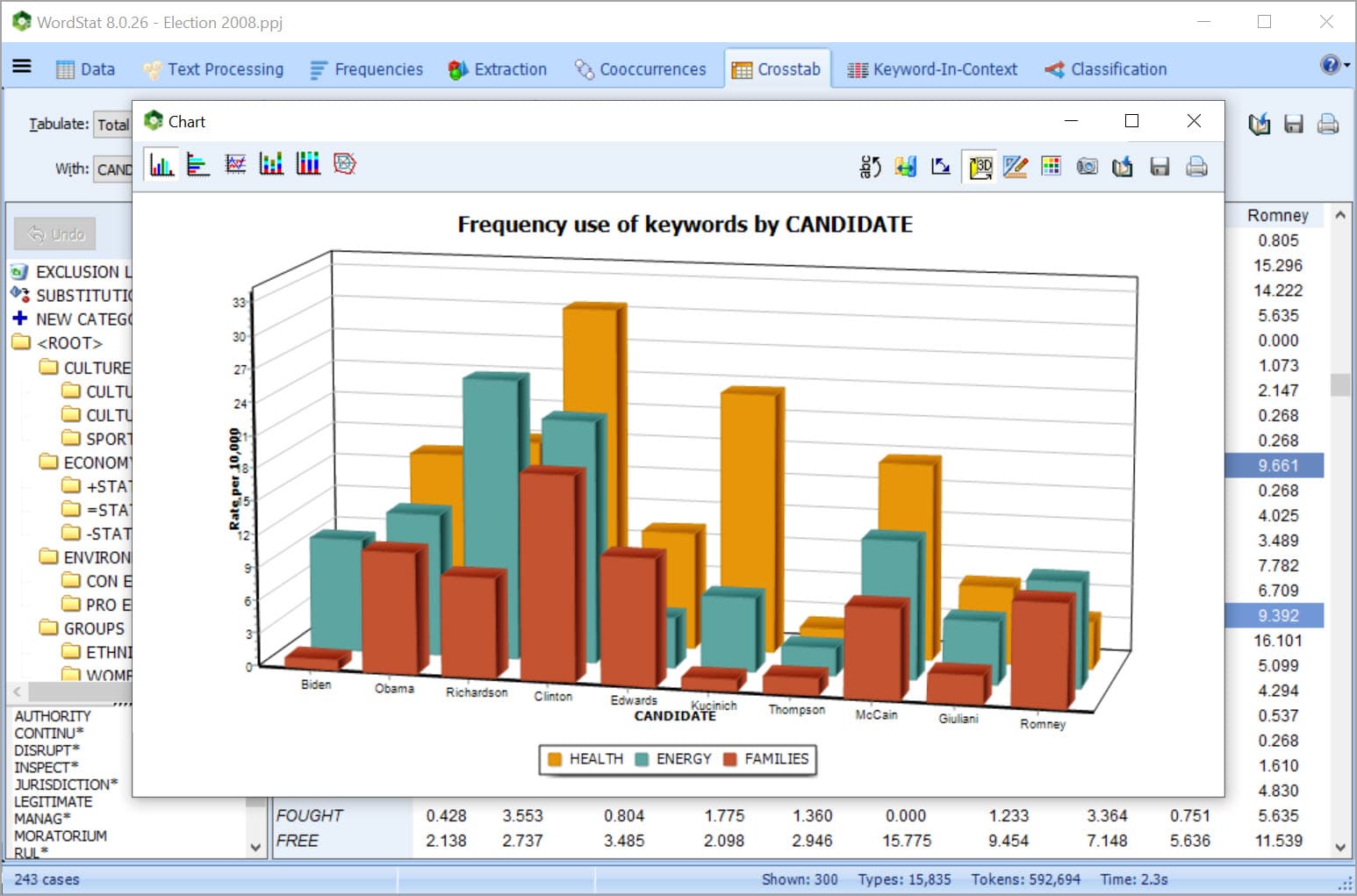
Utilice un diccionario de clasificación existente o desarrolle su propio diccionario con las palabras seleccionadas, patrones de palabra, frases, así como reglas de proximidad, para una medición precisa de conceptos. Alternativamente, uno puede utilizar maquinaria de aprendizaje para la clasificación automática de documentos.
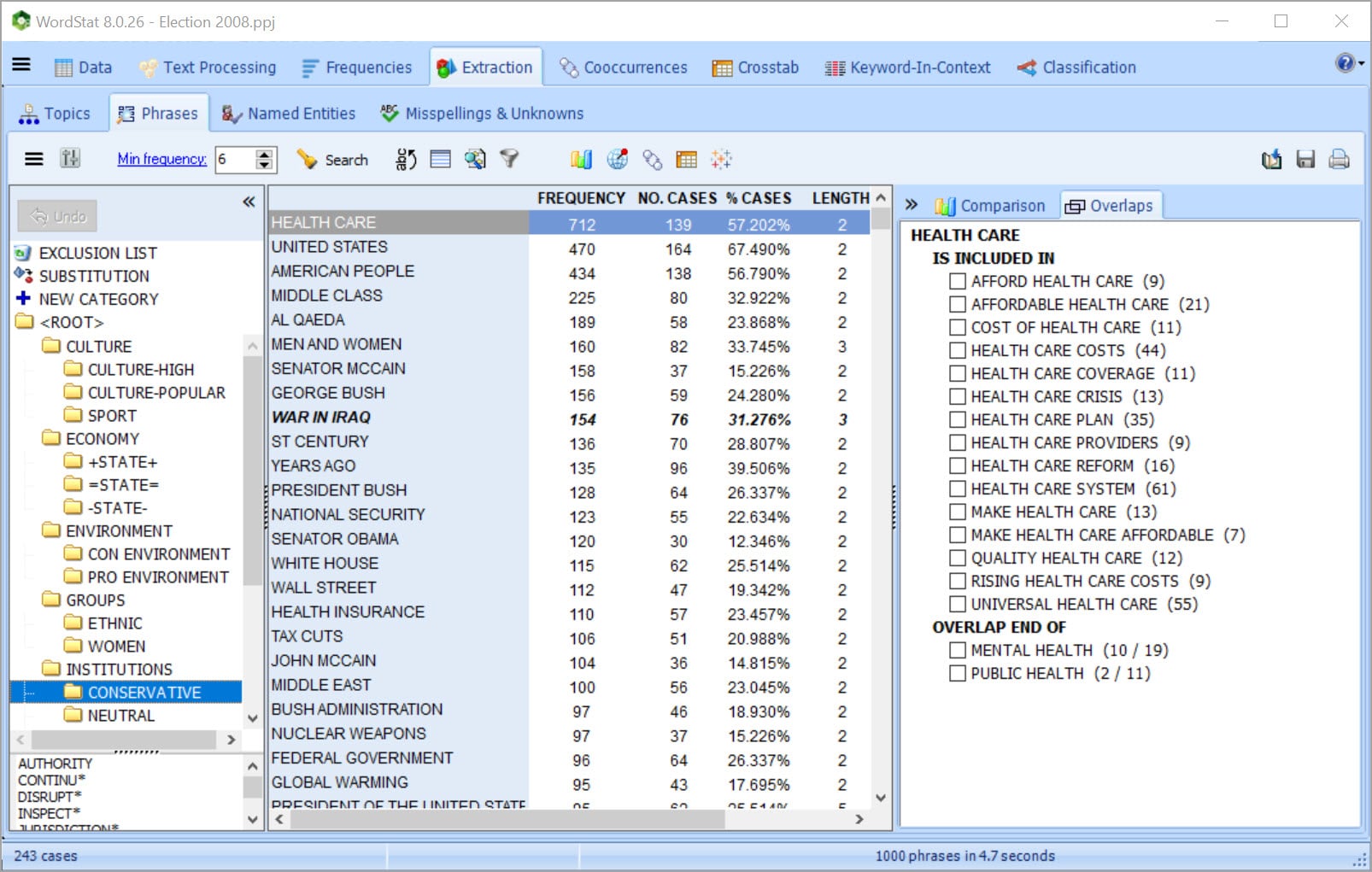
Verdaderamente única asistencia por computadora para la construcción de diccionarios con herramientas para la extracción de frases comunes, términos técnicos, abreviaciones y faltas de ortografía y para identificar rápidamente en su colección de texto, los sinónimos, antónimos y palabras relacionadas.
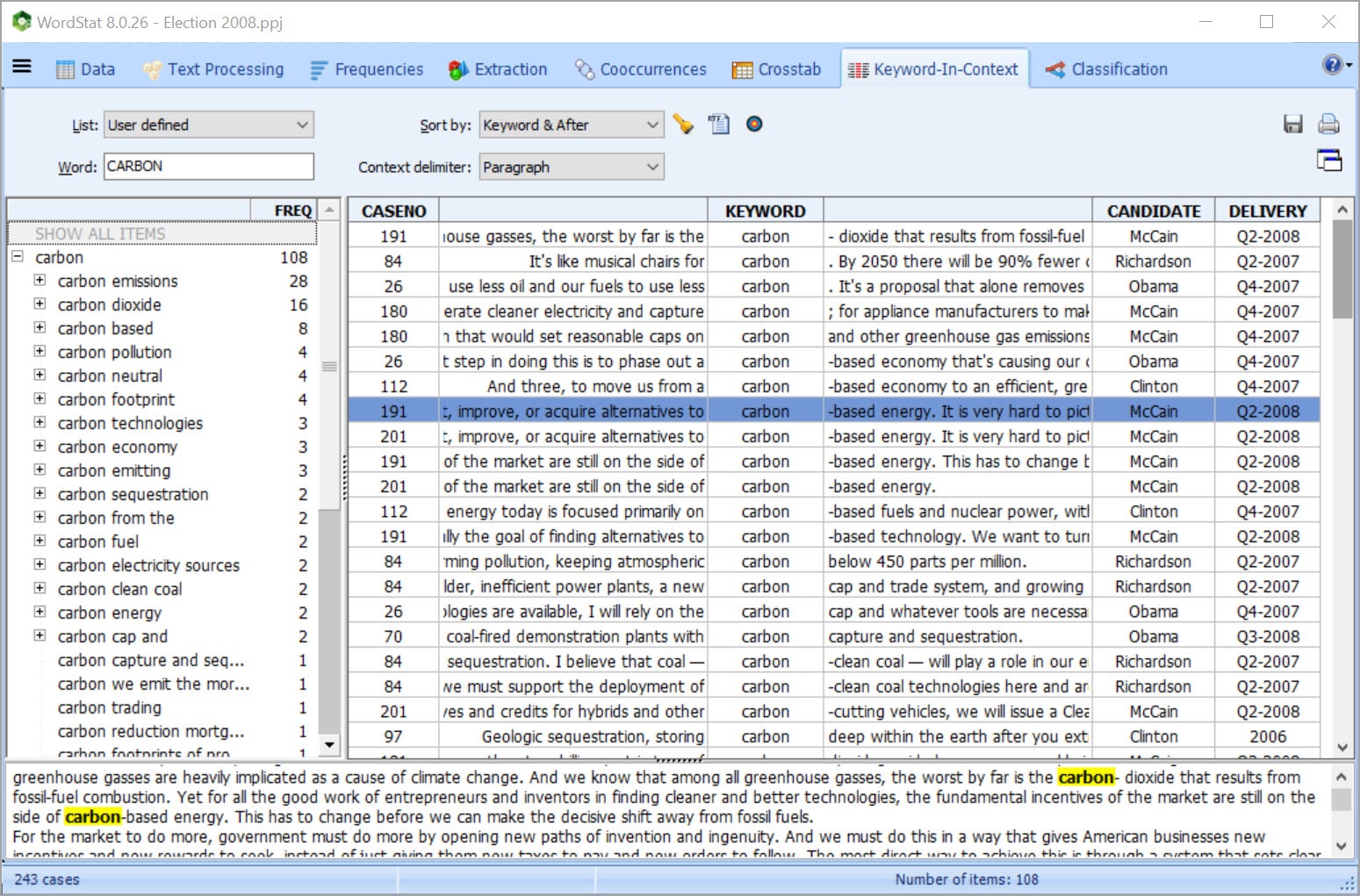
Acceso con un clic a las herramientas de recuperación de palabras clave en contexto y palabra clave para facilitar la identificación y codificación de segmentos relevantes de texto, para la validación de diccionarios, desambiguación del sentido de la palabra o para mirar detalladamente los documentos de origen.
Incomparable integración con una herramienta de codificación cualitativa de última generación (QDA Miner), permite la exploración más precisa de datos o el análisis más profundo de determinados documentos o particulares segmentos de texto cuando es necesario.
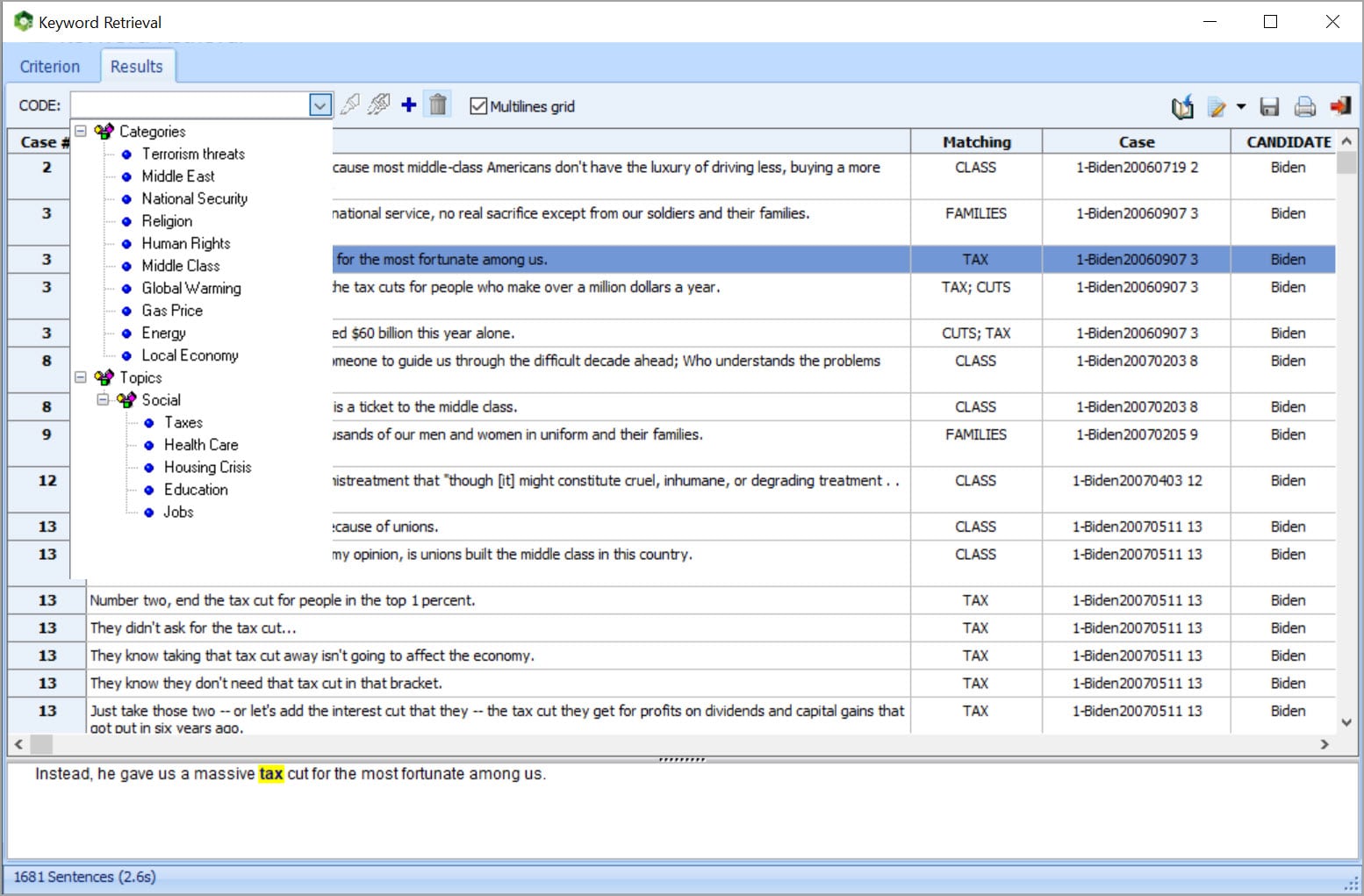
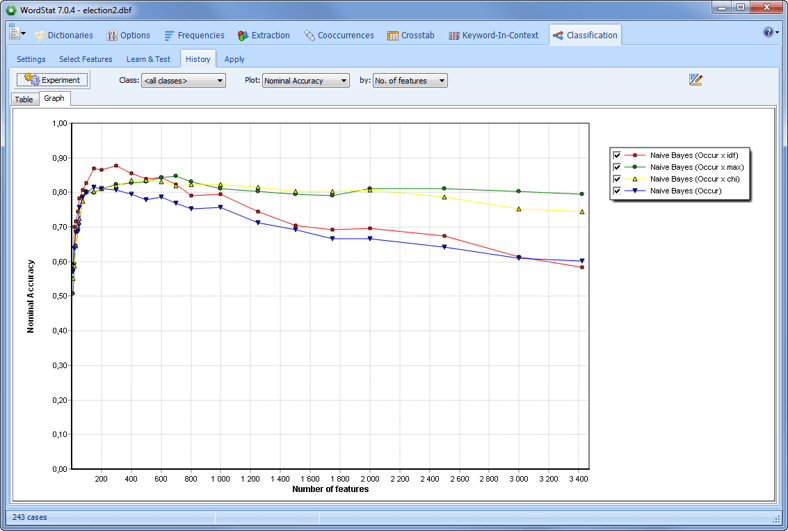
Máquina de aprendizaje para la clasificación automática de documentos utilizando los algoritmos Bayes Ingenuo y K-Vecinos más Cercanos junto con herramientas de selección y validación de características automáticas. Los modelos de clasificación pueden guardarse en el disco y aplicarse en nuevos datos.