

Powered by AI since 1998
Content analysis and text mining software for fast and precise processing of large amounts of unstructured information
LAS NUEVAS CARACTERÍSTICAS DEL SOFTWARE DE MINERÍA DE TEXTOS WORDSTAT
¿Qué hay de nuevo en la versión 9.0?
1. Soporte completo de Unicode
Siempre intentamos seleccionar técnicas de análisis de texto independientes del idioma. Esto ha permitido a los usuarios analizar datos de texto en más de 50 idiomas. Sin embargo, para analizar los idiomas no soportados por su instalación predeterminada de Windows, el usuario necesitaba cambiar algunas configuraciones de Windows. Y aunque era posible analizar conjuntos de datos en varios idiomas, algunas combinaciones de idiomas simplemente no eran posibles. La nueva versión Unicode de WordStat permite analizar cualquiera de ellas sin necesidad de cambiar la configuración, así como nuevos idiomas que antes no eran compatibles, como el chino, el japonés o el tailandés. También se han añadido rutinas de segmentación de palabras para los tres idiomas asiáticos anteriores.

2. Integración de scripts de pre y postprocesamiento en R y Python
En 2018, introdujimos la posibilidad de crear scripts de preprocesamiento en Python en WordStat 8. La versión 9.0 amplía esta capacidad ofreciendo la posibilidad de crear scripts de preprocesamiento también en R. Y lo que es más importante, ahora es posible crear scripts de posprocesamiento en esos dos lenguajes de programación que permiten realizar análisis personalizados sobre los datos de texto originales o transformados o sobre los resultados cuantificados obtenidos mediante el análisis de contenido de esos documentos. Esta característica ofrece un sinfín de posibilidades para ampliar las funciones de WordStat, como la implementación de nuevos algoritmos de aprendizaje automático, técnicas avanzadas de modelamiento estadístico o transformación de datos personalizados. Se han incluido scripts de ejemplo para calcular métricas de legibilidad del texto, detectar idiomas, aplicar otras técnicas de modelamiento de tópicos (LDA o STM) o crear modelos predictivos mediante aprendizaje automático (SVM, kNN, etc.).
![]()

3.Corrección ortográfica automática
Se ha escrito desde cero un nuevo motor de corrección ortográfica para conseguir correcciones ortográficas mucho más rápidas y precisas, lo que permite implementar una función de corrección ortográfica automática con un impacto mínimo en la velocidad de procesamiento de texto existente en WordStat. La corrección ortográfica inteligente puede incluso corregir la ortografía de términos desconocidos, como vocabularios técnicos, nombres propios, etc. Los resultados pueden guardarse automáticamente en la lista de sustituciones para su revisión y corrección.
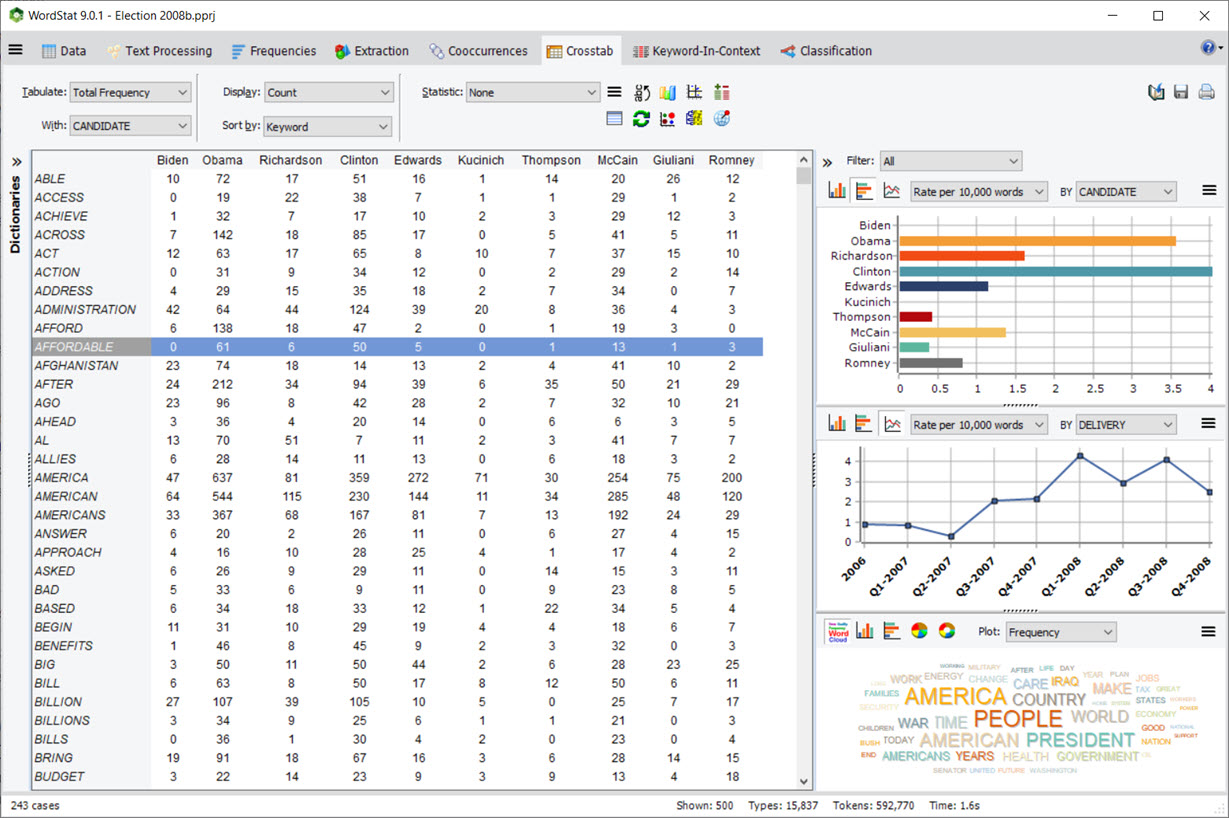
4. Tablas cruzadas con paneles de gráficos y filtrado
La página de tabulación cruzada incluye ahora un panel de gráficos que permite trazar rápidamente la distribución de las filas seleccionadas de la tabla de tabulación cruzada para los valores de la variable seleccionada o de cualquier otra variable. Un cuadro de lista de filtrado también permite analizar dichas distribuciones para un solo valor o un conjunto de valores de la variable seleccionada.
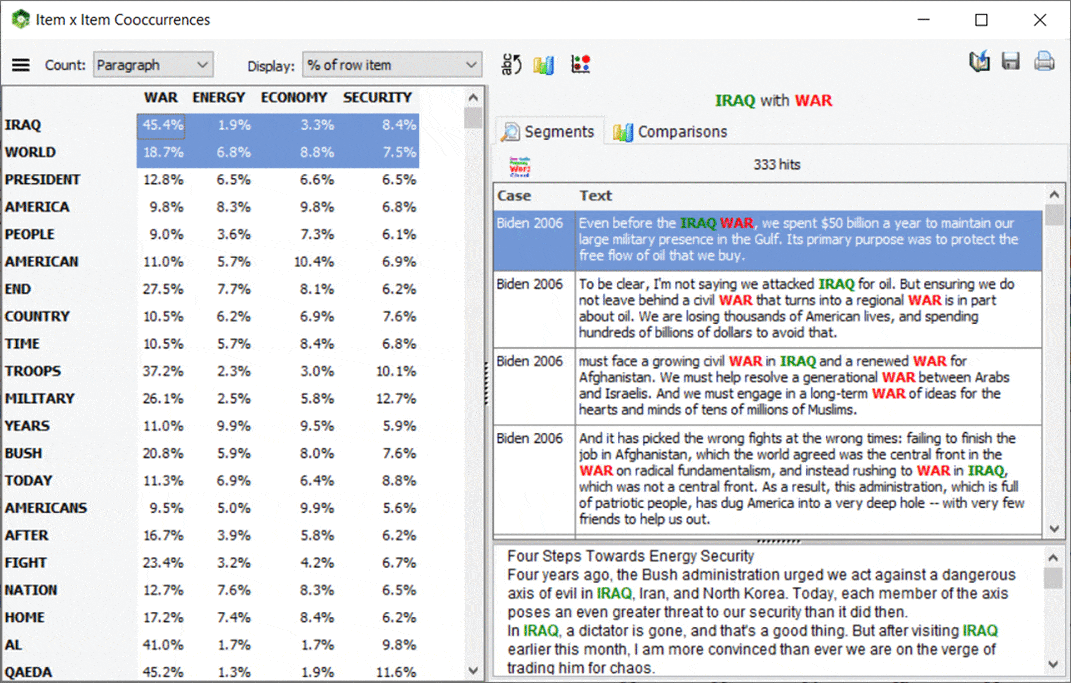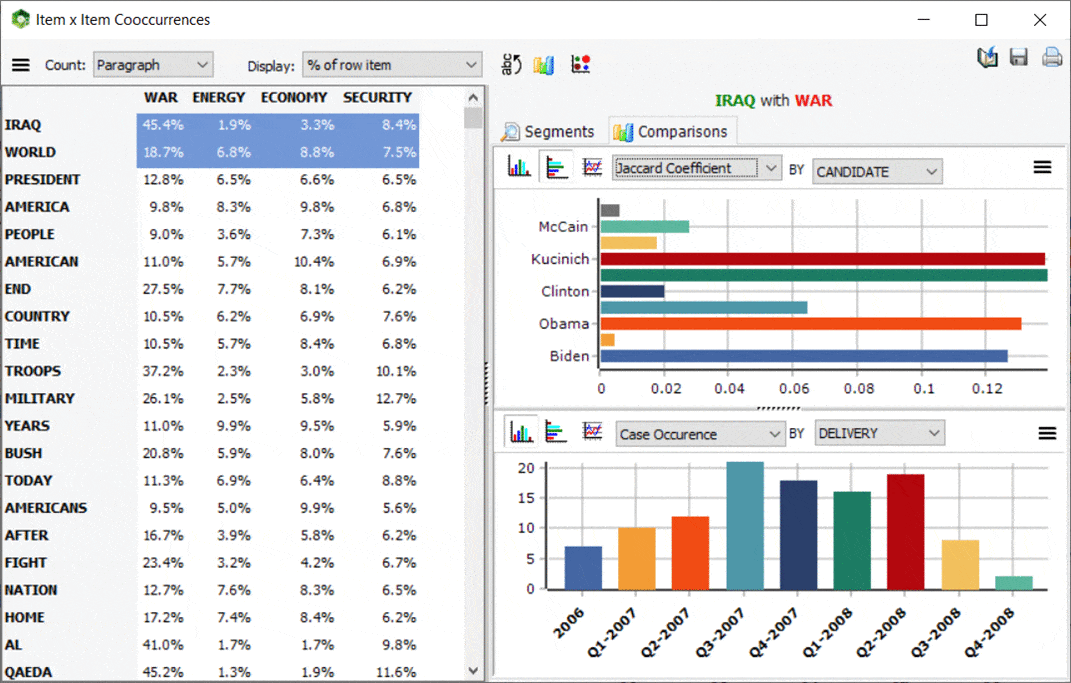
5. Matriz de co-ocurrencia interactiva
Se ha añadido una nueva función de matriz interactiva a la página de co-ocurrencias que permite centrarse en co-ocurrencias específicas. Los resultados principales consisten en una tabla que muestra una selección de varias estadísticas de co-ocurrencia. Esta matriz también es muy interactiva y permite transformar determinadas filas en nuevas columnas o viceversa, mediante simples operaciones de arrastrar y soltar. A la izquierda, un panel de gráficos permite también evaluar la distribución de una co-ocurrencia específica a través de otras variables. También se puede obtener una vista rápida de todos los segmentos de texto asociados a una co-ocurrencia específica. Esta nueva función de WordStat se puede llamar desde la lista de frecuencias, seleccionando los elementos de destino (palabras o categorías de contenido) que deben mostrarse como columnas, haciendo clic con el botón derecho y seleccionando matriz de co-ocurrencias.
6. Importación de archivos Nexis UNI y Factiva
Introducido en QDA Miner 6.0 en 2020, ahora también es posible en WordStat importar transcripciones de noticias desde los archivos de salida de LexisNexis y Factiva. Tras seleccionar uno o varios archivos .DOCX o RTF obtenidos de esos servicios, WordStat extraerá y almacenará en variables separadas el título y el cuerpo de la transcripción de noticias, su fuente, la fecha de publicación y otra información relevante. Esta función debería resultar útil para la gestión de reputación, la gestión de marca, la comunicación de crisis, el análisis del encuadre de medios de comunicación, los estudios comparativos de medios, etc.

7. Procesamiento por lotes de modelos temáticos
La elección del número de tópicos a extraer mediante técnicas de modelamiento de tópicos sigue siendo una cuestión para la que, hasta donde sabemos, no existe una respuesta definitiva. Incluso podemos plantear dudas sobre la existencia de tal número óptimo. De hecho, se puede incluso sugerir que la información obtenida mediante diferentes configuraciones puede muy bien servir para diferentes propósitos o revelar diferentes aspectos de una realidad. En este contexto de incertidumbre, los investigadores suelen querer comparar varias soluciones. La nueva función de procesamiento por lotes permite calcular múltiples modelos temáticos variando sistemáticamente el número de tópicos a extraer y, en el caso del método probabilístico (por ejemplo, NNMF), realizar varias ejecuciones utilizando los mismos ajustes para evaluar la estabilidad de los resultados. Todas las soluciones de modelo de tópicos se agregan temporalmente en el gestor de informes, lo que permite comparar las soluciones obtenidas en varias ejecuciones utilizando diferentes configuraciones.
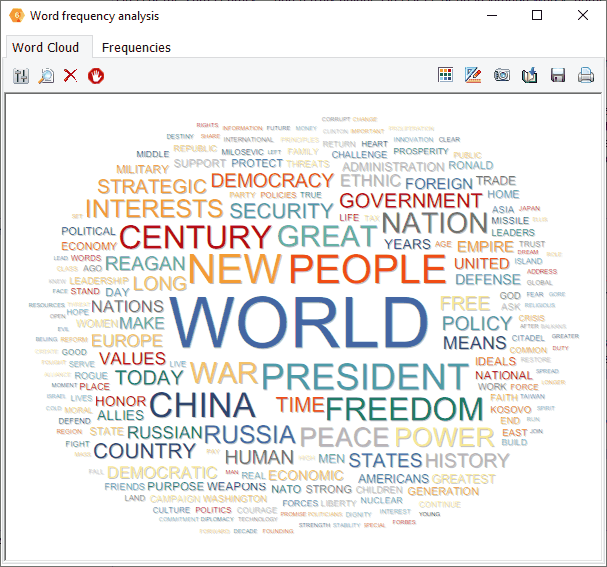
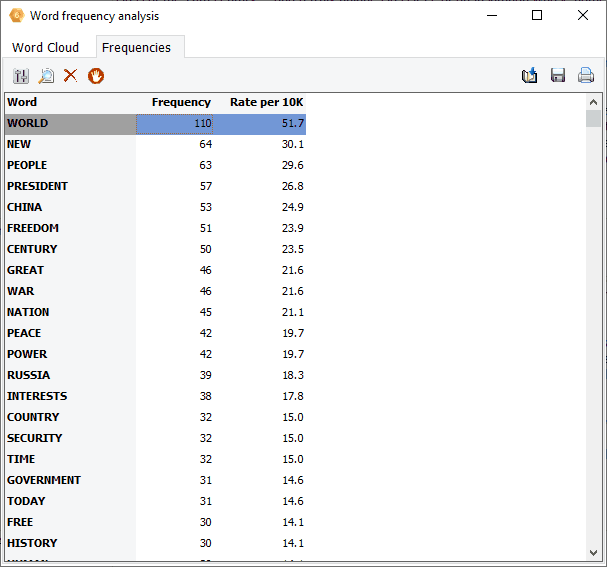
8. Crear nubes de palabras en las recuperaciones de palabras clave y resultados KWIC
Ahora se pueden obtener nubes de palabras interactivas y tablas de frecuencia de palabras directamente en los resultados de recuperación de palabras clave y de palabras clave en contexto (KWIC), lo que permite identificar rápidamente las palabras asociadas a categorías de contenido específico, o las que aparecen antes o después de un elemento específico.
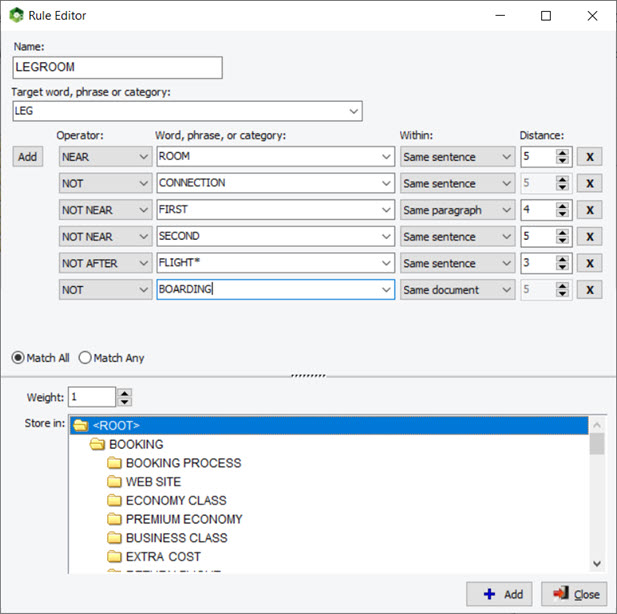
9. Reglas de proximidad más potentes
Se ha incrementado de cuatro a un máximo de veinte condiciones el número de condiciones en las reglas de proximidad. Si cree que no es suficiente, escríbanos.
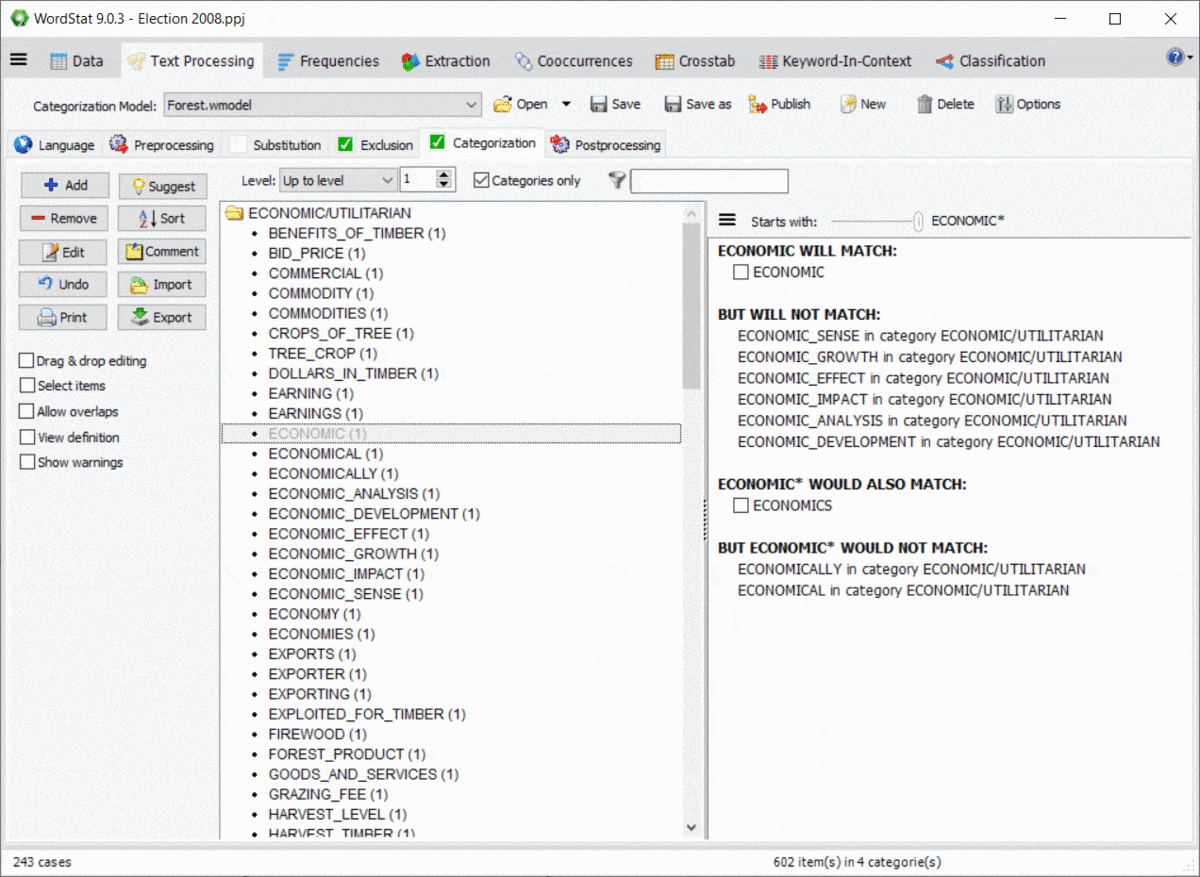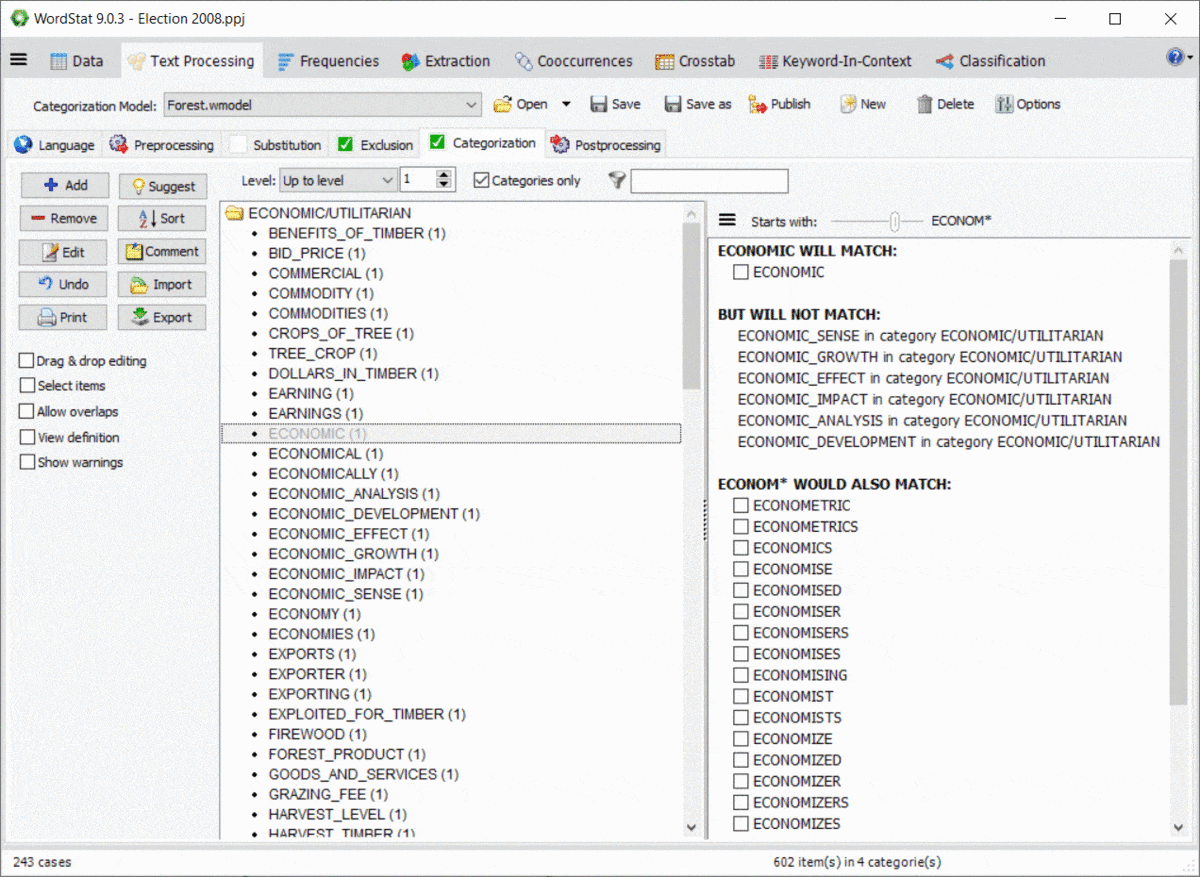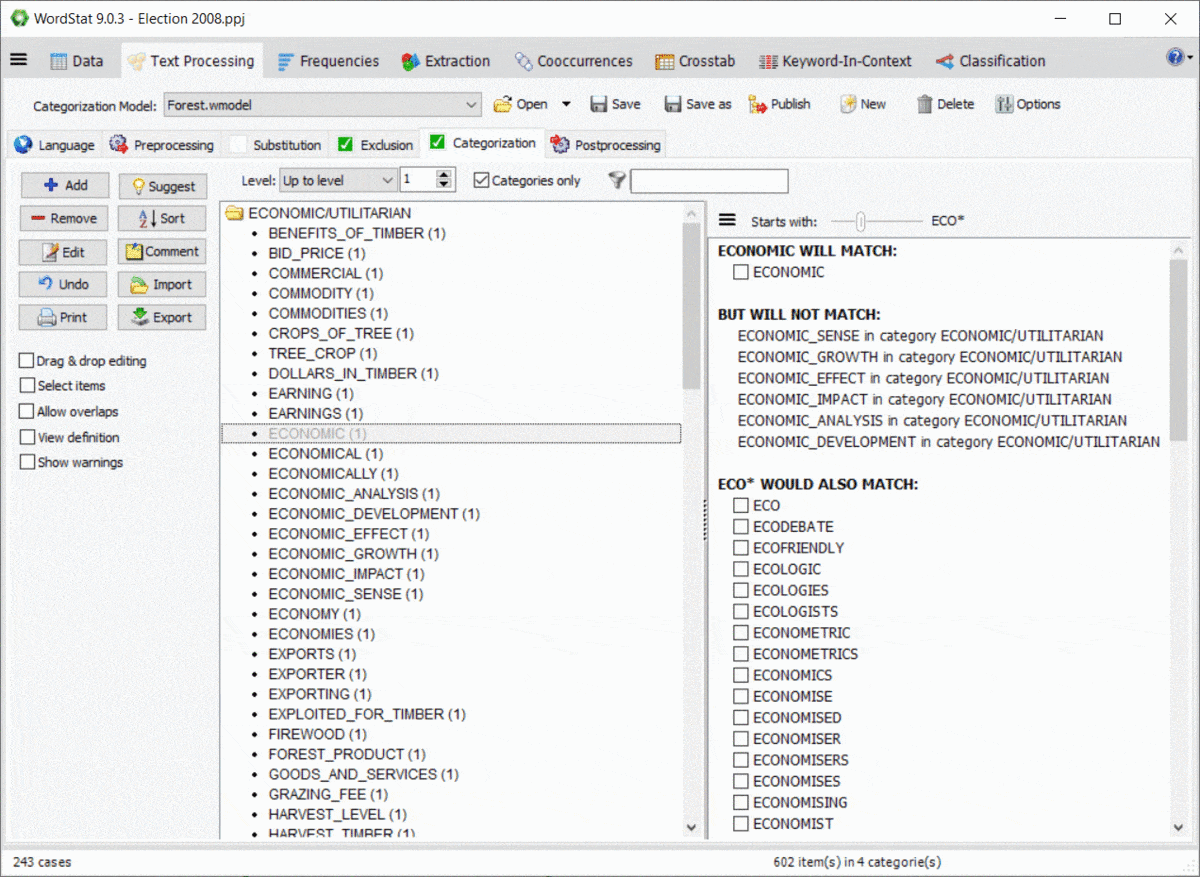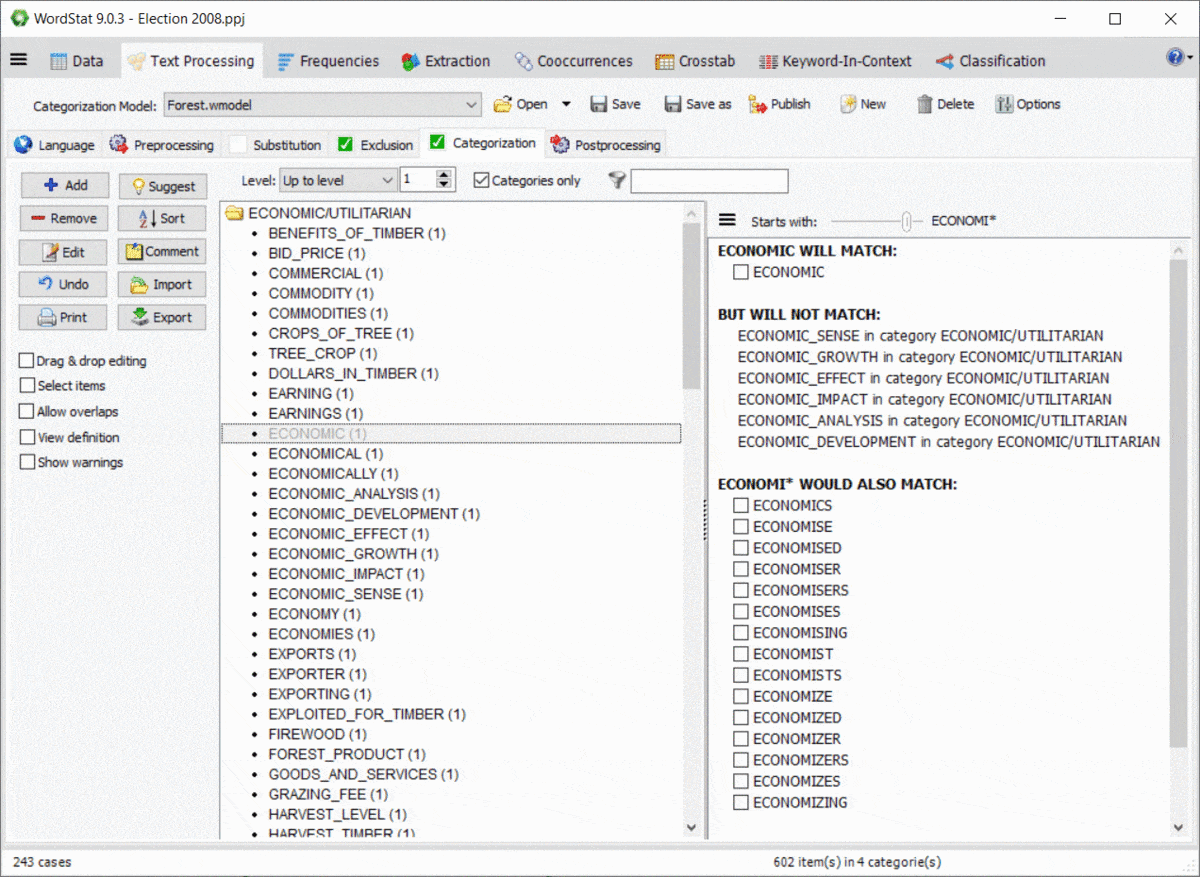
10. Vista previa del efecto de los comodines y las interacciones del diccionario
El uso de comodines en un diccionario es bastante potente, pero potencialmente problemático, ya que podría coincidir con elementos en los que no se había pensado. Por ejemplo, una entrada como TAX* puede permitirle coincidir con TAXI, TAXQUEÑO, TAXATIVO, pero también coincidirá con palabras como TAXISTA, TAXONOMÍA, TAXIDERMIA, etc. Además, las reglas de WordStat para emparejar elementos y evitar el doble conteo también pueden producir resultados inesperados causados por otras entradas en su modelo de categorización. Un nuevo panel a la derecha de las páginas de exclusión y categorización le permite identificar fácilmente las nuevas entradas que se emparejarían utilizando un *comodín al final de una palabra, y también posibles conflictos con otras entradas de su diccionario.
11. Protección con contraseña de los archivos del proyecto
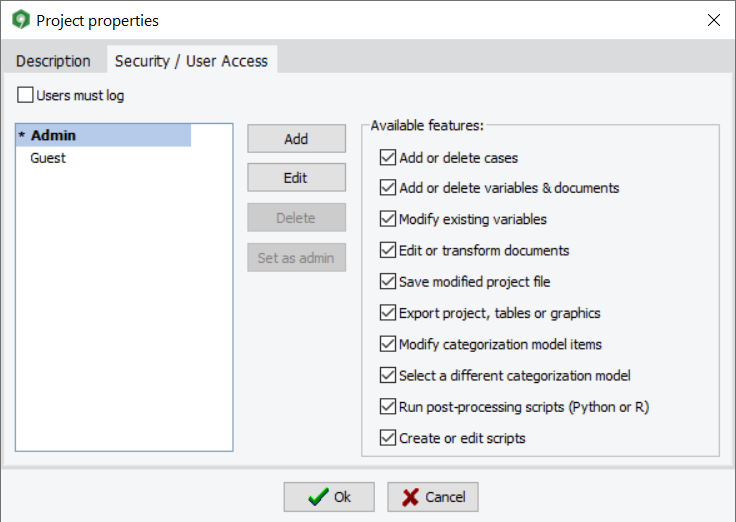
WordStat 9.0 ofrece ahora la posibilidad de proteger con contraseña los archivos de proyecto, restringiendo el acceso a proyectos específicos para usuarios autorizados. Un cuadro de diálogo permite al administrador del proyecto crear nuevas cuentas de usuario y especificar qué operaciones puede realizar cada usuario. Se puede limitar la edición, importación o transformación de datos, así como la exportación de datos, tablas y gráficos del proyecto. También se puede optar por dejar que los usuarios realicen cualquier transformación que deseen, pero impedir que guarden el archivo del proyecto.
12. Nuevas opciones para la limpieza de datos
La página de preprocesamiento incluye ahora opciones para eliminar automáticamente las URL de los mensajes de texto, así como las designaciones de los hablantes en las transcripciones de noticias y entrevistas.
13. Nuevos gráficos de áreas apiladas
La función de gráficos de la página de tablas cruzadas añade la posibilidad de crear dos tipos de gráficos de áreas apiladas.
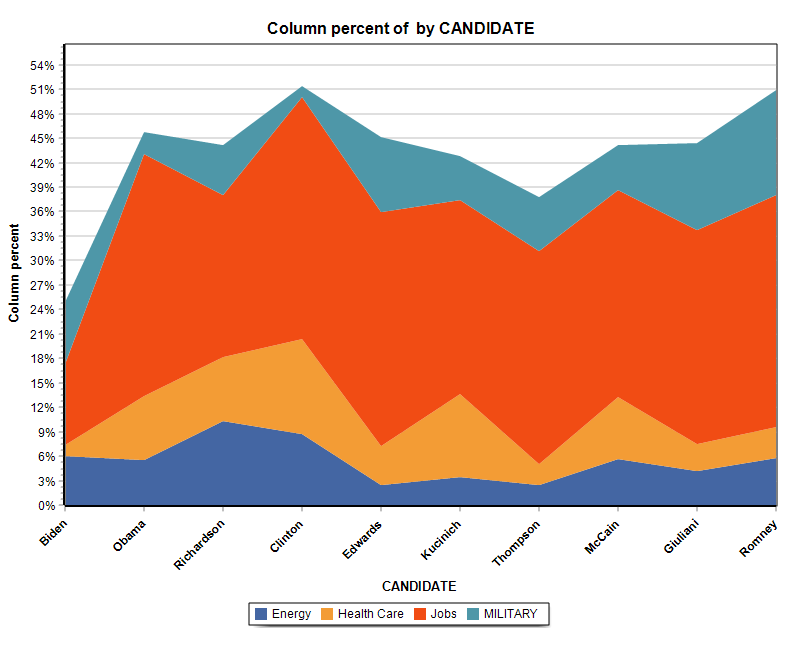
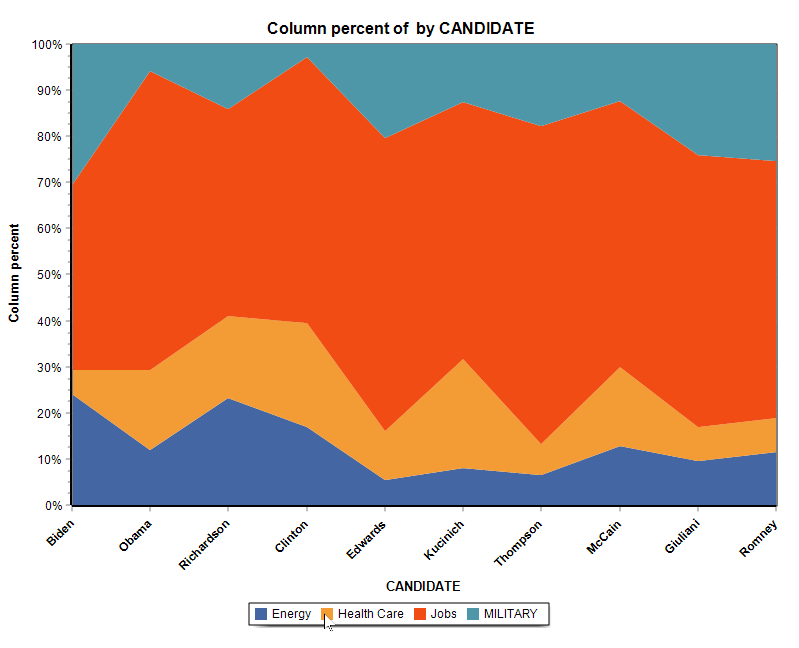
14. Elementos coloreados en el gráfico de correspondencia
Ahora pueden utilizarse gradientes de color para representar la posición de elementos específicos o clases de variables en tercera dimensión (profundidad) o en el gráfico de correspondencia 2D y 3D. Pueden elegirse hasta cuatro colores para crear esos gradientes.

15. Gráfico de burbujas mejorado
Ahora es posible transponer filas y columnas de los gráficos de burbujas.
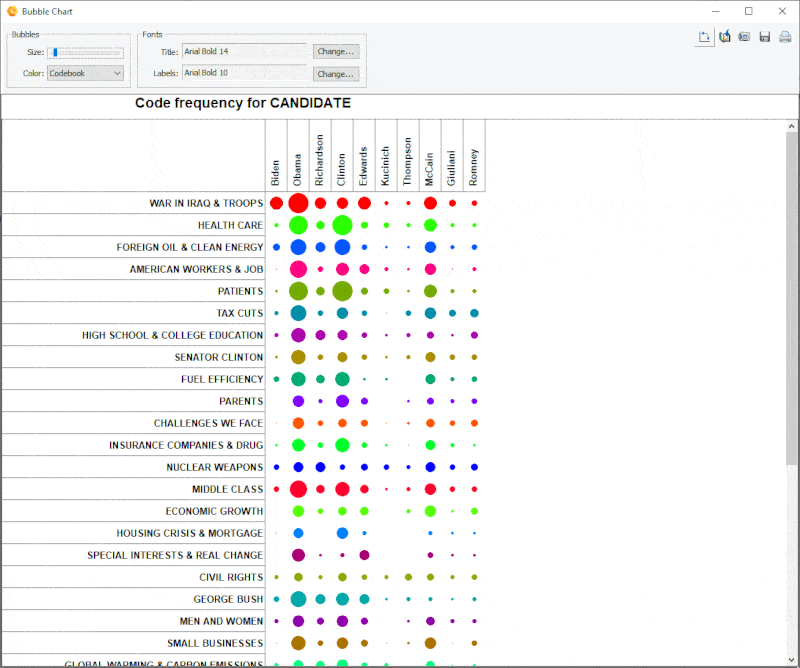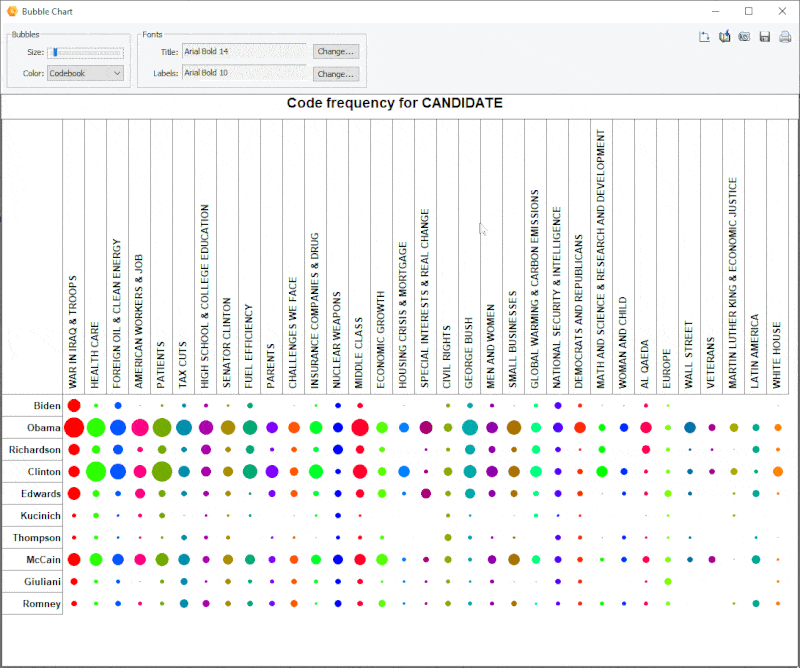
16.Buffer de análisis de enlaces
Un búfer de análisis de enlaces permite volver a diagramas de enlaces anteriores y luego avanzar.
17. Enriquecimiento de tópicos más rápido y preciso
WordStat va más allá del típico modelamiento de tópicos, ofreciendo ‘una característica única de enriquecimiento de tópicos que identifica frases asociadas, excepciones potenciales y errores ortográficos. También genera automáticamente nombres de tópicos relevantes. Con la versión 9, esta función de enriquecimiento de tópicos es ahora dos veces más rápida que antes y realiza una mejor desambiguación del sentido de la palabra para obtener una lista más precisa de excepciones. También ofrece mejores sugerencias para la corrección ortográfica.
18.Mayor velocidad y precisión de las correcciones ortográficas existentes
La función de corrección ortográfica existente es ahora hasta 30 veces más rápida, necesitando sólo uno o dos segundos para sugerir correcciones ortográficas para decenas de miles de palabras desconocidas.
19. Nuevo formato de archivo .PPRJ
Se ha creado un nuevo formato de archivo con una nueva extensión de archivo (.pprj), que proporciona un mejor soporte para los datos Unicode. Sin embargo, WordStat 9 mantiene la compatibilidad con las versiones anteriores de todo nuestro software y puede abrir y analizar los archivos de proyecto actuales (.ppj) creados por QDA Miner, SimStat o versiones anteriores de WordStat.
20. Numerosas mejoras adicionales
Se han realizado varias opciones adicionales y mejoras en la interfaz de los cuadros de diálogo, gráficos, gestión de datos y funciones de análisis de datos existentes.
Las nuevas características de WordStat 8 pueden verse aquí