

Powered by AI since 1998
Content analysis and text mining software for fast and precise processing of large amounts of unstructured information
THE NEW FEATURES OF WORDSTAT TEXT MINING SOFTWARE
What’s New in Version 8.0?
WordStat 8 has new features and options to increase flexibility and allow the software to be used by less-experienced and expert users alike.
We know you are being inundated by more and more text data and are looking for ways to analyze and categorize it. You are looking for tools to help you quickly find themes, context, important concepts, and meaning in large amounts of text data. We know this is a challenge for expert data scientists and less experienced researchers and analysts. Finding a way to support these groups was the thinking behind WordStat 8. We wanted to improve usability and flexibility while still improving performance and precision.
We believe the new approach of WordStat 8 accomplishes these goals. You can process enormous amounts of unstructured data in just seconds with minimal experience or easily build your own extensive categorization dictionaries to perform precise measurement of concepts.
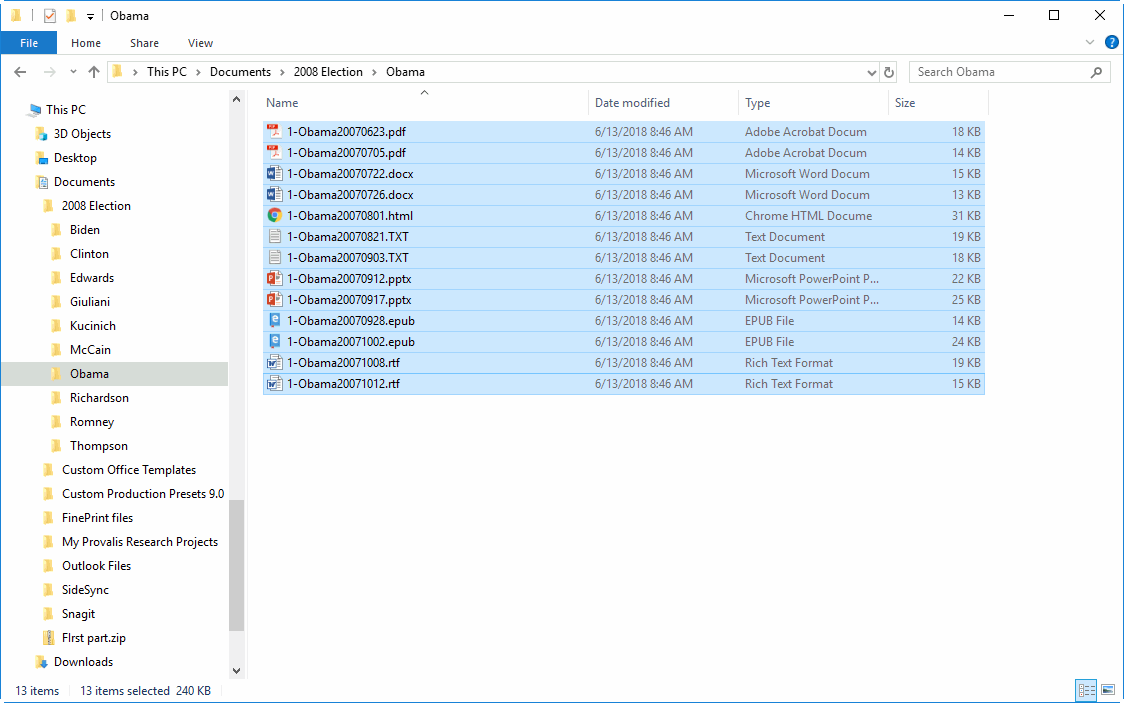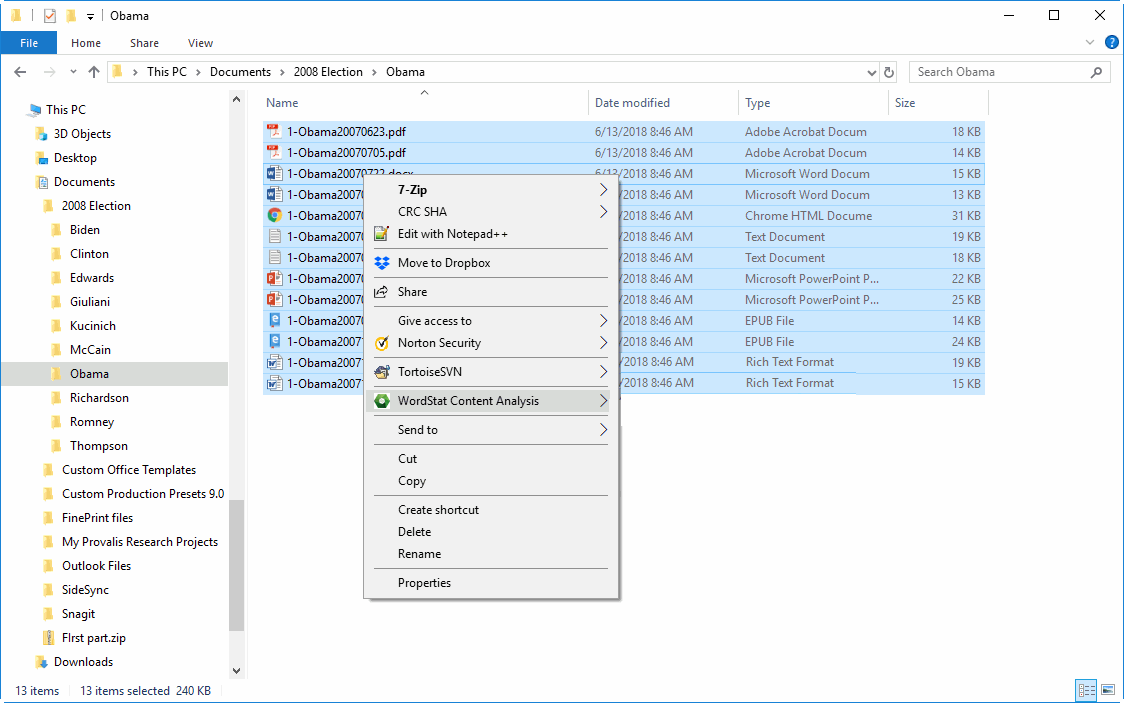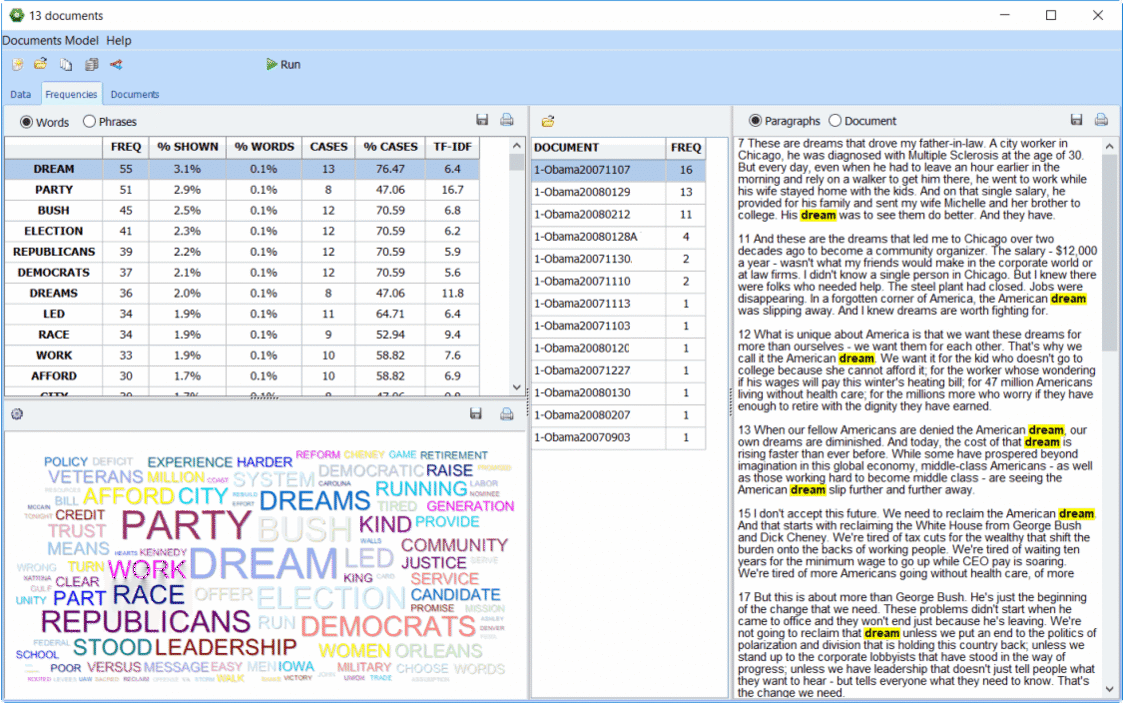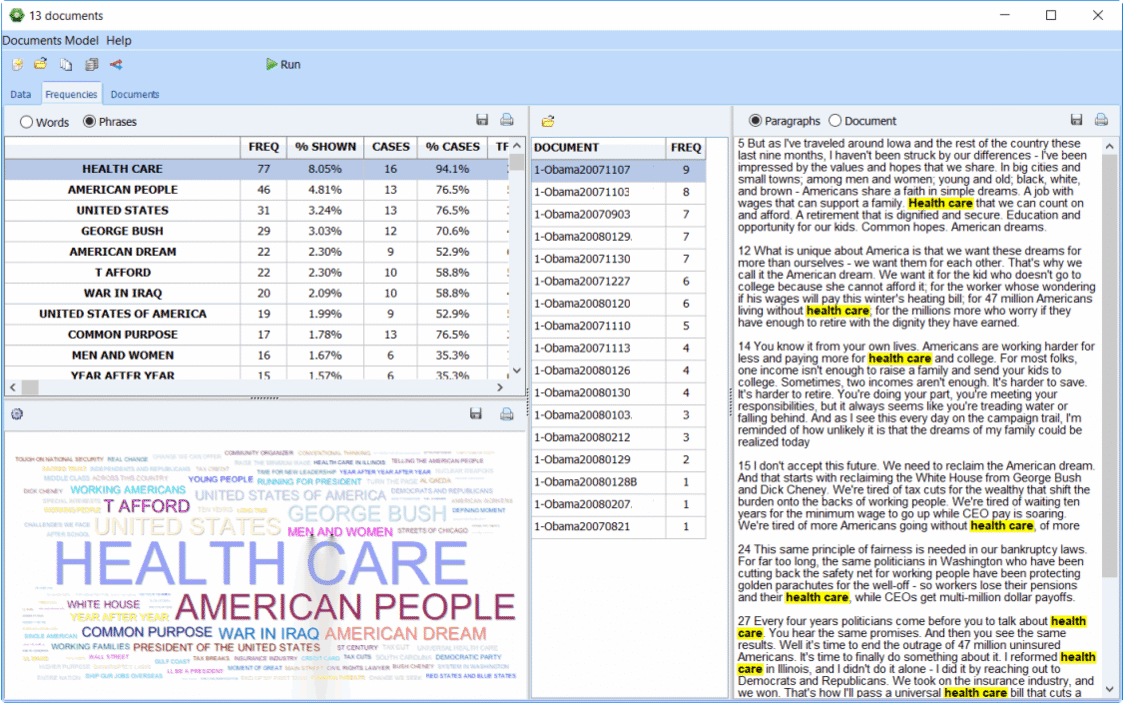
1. Standalone text mining platform
Learning a new software can be a daunting task. Especially a software with many features like WordStat. Previously, WordStat was an add-on module of QDA Miner. This required users not only to learn WordStat but also elements of QDA Miner, to set up their project. WordStat 8 is now a standalone product. This cuts down on the complexity and learning curve as users can now create their projects directly in WordStat. However, it may still be run as a content analysis add-on of QDA Miner, STATA, or SimStat.
You can now create a project in WordStat itself from different sources:
- Documents: MS Word, RTF, PDF, HTML, etc.
- Data files: Excel, CSV, Stata, etc.
- Web survey platforms: SurveyMonkey, Qualtrics, SurveyGizmo, etc.
- Reference management tools: Endnote, Zotero, Mendeley
- Social media services: Twitter, Facebook, Reddit, RSS Feeds, Youtube
- Email platforms: Outlook, Gmail, Hotmail, Mbox, and EML format
- Many other sources…
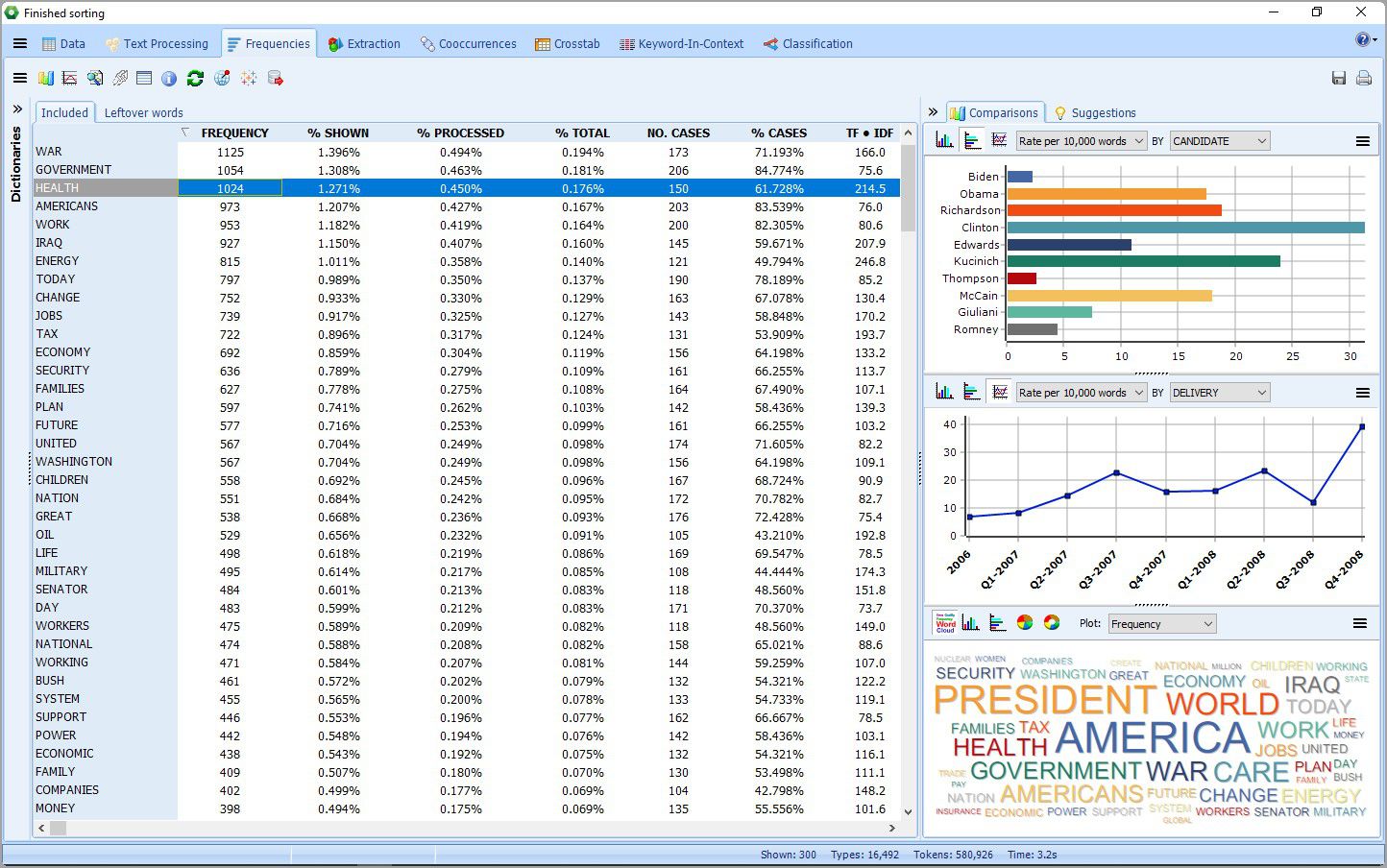
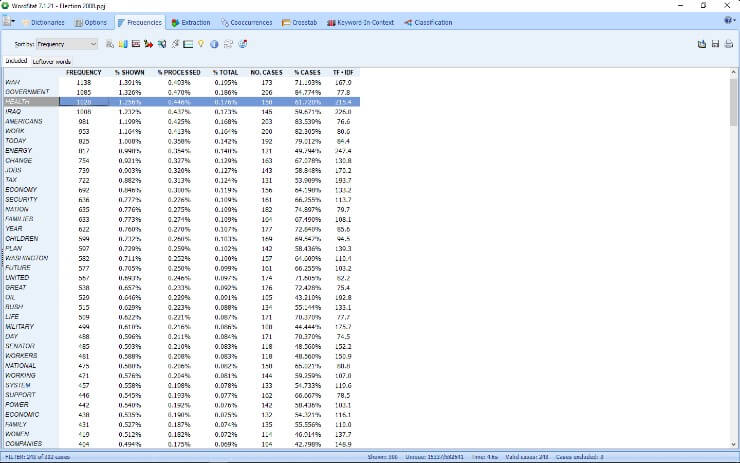
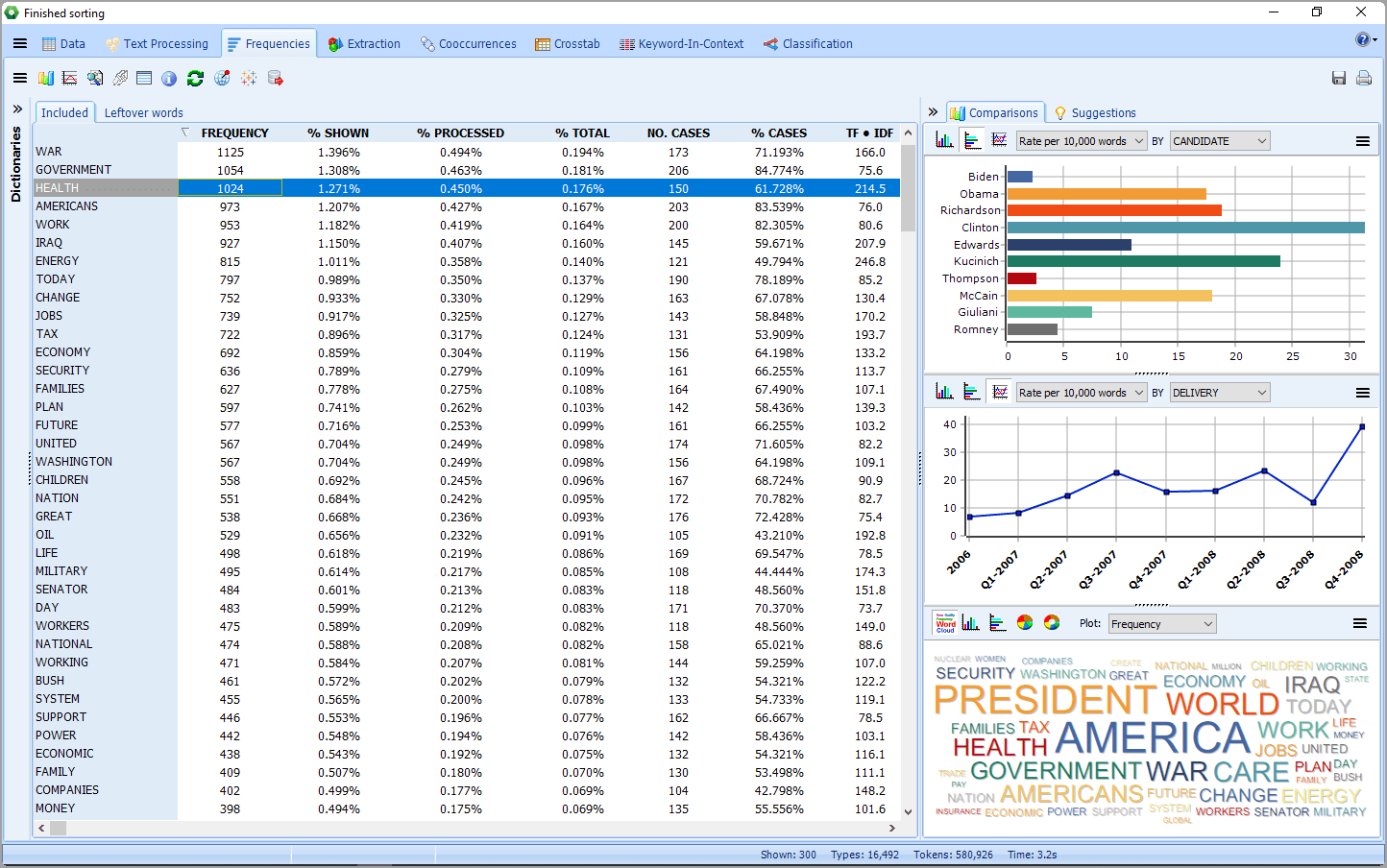
2. New explorer mode
A new Explorer mode has been implemented to allow users with little text mining experience to quickly and easily extract meaning from large amounts of text data. You can identify the most frequent words and phrases and extract the most salient topics in your documents with the improved topic modeling tool of WordStat 8. At any time you can switch to the expert mode which gives you access to all of WordStat features including content analysis dictionaries, crosstabs, and cooccurrence analyzes features.
3. Improved topic modeling
The existing topic modeling routine benefits from numerous improvements such as an additional extraction algorithm (NNMF) for faster topic extraction, as well as an innovative topic enrichment process. This technique allows one to move beyond the “bag-of-word” solution typical of traditional topic modeling by automatically selecting related phrases and providing suggestions for additional expressions, potential exceptions as well as spelling corrections. All these innovations should lead to a more precise and comprehensive measurement of salient topics in your text collection.
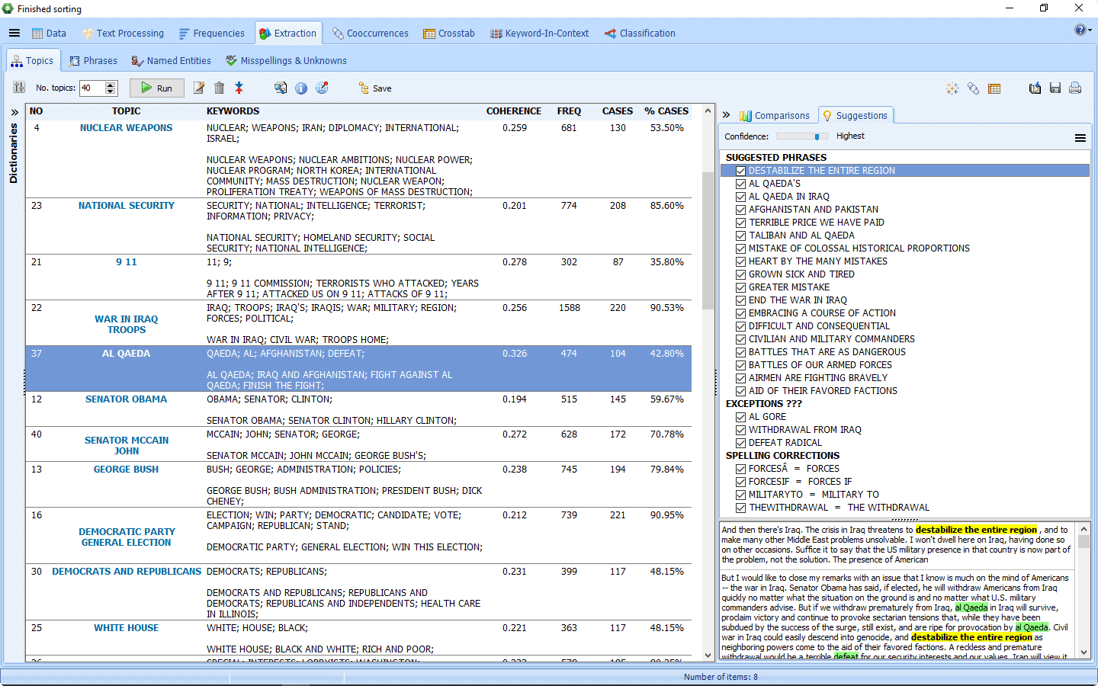
4. New and improved graphic displays
WordStat 8 has several new graphic displays to help you better understand the results of your data analysis. We have improved, interactive word clouds, donut, and radar charts.
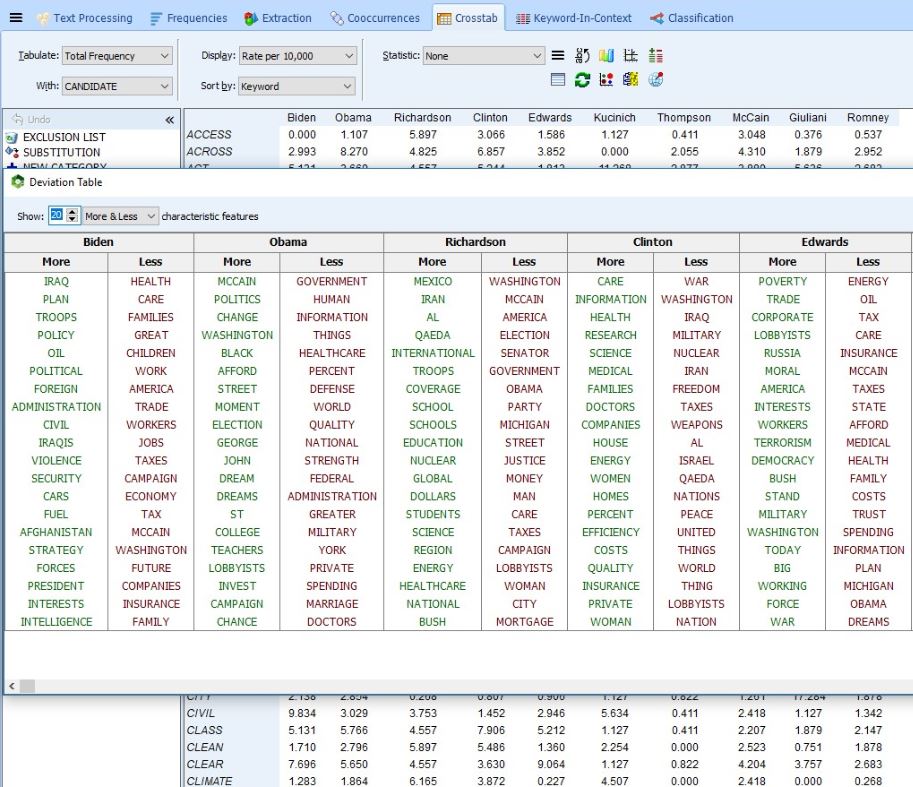
5. Deviation table
This is a brand new feature included in WordStat 8. It was added after the release and you need to have downloaded WordStat 8.0.7 or later to have access to it. The Deviation Table allows you to see words/phrases used more or less as compared to other variables. You first need to activate the crosstab button to see the icon. You can right-click to find KWIC, Delete and save to Tab Delimited, HTML or Bitmap. To learn more about this specific feature of WordStat 8, click on the following link: deviation-table/
6. Export results to Tableau Software
With a simple click, you can also export your results to Tableau Software to use its advanced interactive data visualization tools.
![]()
7. Improved content analysis dictionary building
Several new features and improvements have been made to the categorization dictionaries section, to help you be more precise in your text search and get more accurate results.
Case sensitive entries: the categorization dictionaries and the exclusion list now support case-sensitive entries to disambiguate words such as “Bill” and “bill”, “Buck” and “buck” or “us” and “US”.
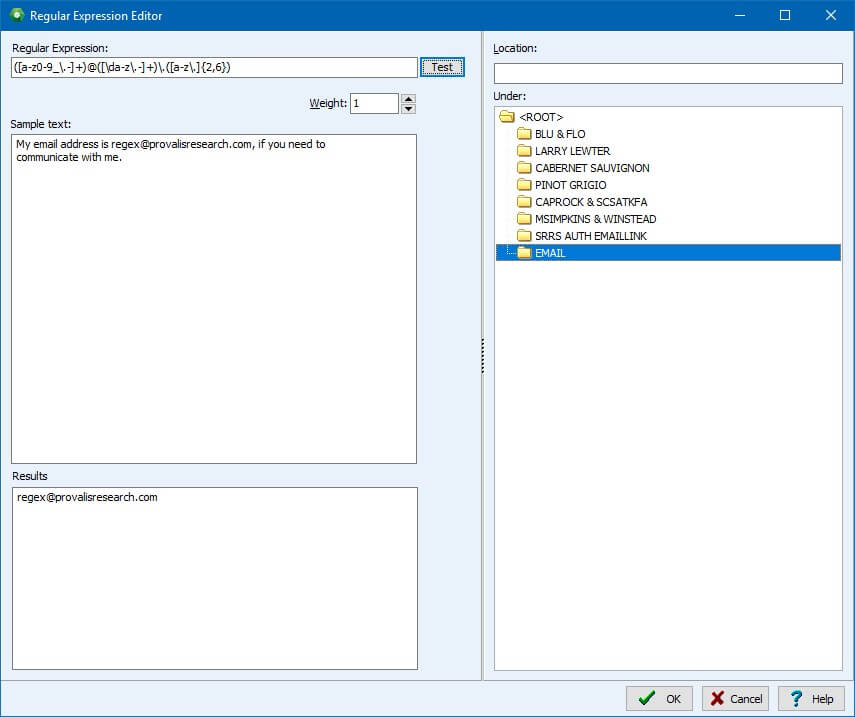
Regular Expression (Regex) Searches: we have created a Regular Expression Editor where you can create your own Regex formulas to quickly extract specific information from your text data such as email addresses or postal codes.
New Substitution process: we have improved the substitution process by splitting it in two. By separating it from our lemmatization process you can easily track substitutions and keep your content dictionary free of misspelled words.
Exclusion and substitution lists along with your categorization dictionary can now be saved into a categorization model file. This file can be used on other WordStat projects as well as in QDA Miner, WordStat Document Explorer, or in our SDK.
8. Improved interface
The improved interface allows you to quickly access and compare results, so you can extract valuable insights in a few seconds.
WordStat 7
WordStat 8
9. Transform text using Python scripts
WordStat 8 opens the possibility of NLP data scientists to use Python script and its full range of open-source libraries to preprocess or transform text documents for analysis in WordStat. This new feature increases the flexibility of WordStat and allows users to use their Python programming skills.
![]()
10. Numerical transformation
A new numerical transformation dialog box allows you to compute numerical variables from other variables with up to 50 transformation functions including trigonometric, statistical, random number functions. Conditional transformation can also be performed using an IF-THEN-ELSE logical structure.
![]()
11. Binning
A binning feature can now be used to transform continuous values into a smaller number of distinct categories. It may be used to reduce the effect of numerical outliers, abnormal distributions, or convert a continuous numerical variable into an ordinal one. It is especially useful for creating graphical displays of comparisons when the number of distinct values in the numerical variable is too
12. Analysis of emojis
Emojis have become ubiquitous in social media, text messaging, emails and other electronic communications and are often used to represent an object, express an idea or sentiment, or add a nuance to a written message. They are often an integral part of the message and can hardly be ignored. WordStat 8.0 can transform emojis into their text representation, allowing you to analyze them either on their own or as part of the whole message.

13. Explore your documents from Windows Explorer
The new Document Explorer tool allows users to quickly explore the content of their documents from Windows Explorer without the need to import documents or create a project. You just have to select the documents you would like to explore or the folder containing them, right-click and select Explore to quickly identify the most frequent words and phrases and where they are in your documents. With a simple right-click, you can also perform a semantic search on your documents using an existing categorization dictionary or classify documents using a prediction model in WordStat. Watch the WordStat Document Explorer Video Demo
New features of WordStat 7 can be viewed here