Powered by AI since 1998
Content analysis and text mining software for fast and precise processing of large amounts of unstructured information
Powered by AI since 1998
Content analysis and text mining software for fast and precise processing of large amounts of unstructured information
LES NOUVELLES FONCTIONNALITÉS DE WORDSTAT
Quoi de neuf dans la version 8.0?
Plus performante et plus flexible que jamais! La nouvelle version 8.0 offre de nombreuses nouvelles fonctionnalités et s’ajuste à votre niveau d’expertise en « text mining ».
Nous savons que vous êtes inondé de plus en plus de données textuelles et cherchez des moyens de les analyser et de les catégoriser. Vous recherchez des outils pour vous aider à trouver rapidement des thèmes, du contexte, des concepts importants et du sens dans de grandes quantités de données textuelles. Nous savons que c’est un défi pour les scientifiques de données et les chercheurs et analystes moins expérimentés. L’objectif de WordStat 8 était de trouver un moyen de soutenir ces groupes. Nous voulions améliorer la convivialité et la flexibilité tout en bonifiant les performances et la précision.
Nous sommes convaincus que la nouvelle approche de WordStat 8 permet d’atteindre ces objectifs. Vous pouvez traiter d’énormes quantités de données non structurées en quelques secondes avec une expérience minimale ou créer facilement vos propres dictionnaires de catégorisation complets pour effectuer une mesure plus précise des concepts.
1. Plateforme autonome de « text mining »
Apprendre un nouveau logiciel peut être une tâche ardue. Surtout un logiciel avec de nombreuses fonctionnalités comme WordStat. Auparavant, WordStat était un module complémentaire de QDA Miner. Les utilisateurs devaient donc non seulement apprendre WordStat mais aussi des éléments de QDA Miner, pour mettre en place leur projet. WordStat 8 est maintenant un produit autonome. Cela réduit la complexité et la courbe d’apprentissage puisque les utilisateurs peuvent maintenant créer leurs projets directement dans WordStat. Cependant, il peut toujours être utilisé comme un complément d’analyse de contenu de QDA Miner, STATA ou SimStat.
Vous pouvez maintenant créer un projet dans WordStat même à partir de différentes sources :
- Des documents : MS Word, RTF, PDF, HTML, etc.
- Fichiers de données : Excel, CSV, Stata, etc.
- Plateformes d’enquête en ligne : SurveyMonkey, Qualtrics, SurveyGizmo, etc.
- Outils de gestion des références : Endnote, Zotero, Mendeley.
- Services de médias sociaux : Twitter, Facebook, Reddit, flux RSS, Youtube
- Plateformes de messagerie électronique : Outlook, Gmail, Hotmail, Mbox, et format EML
- De nombreuses autres sources…
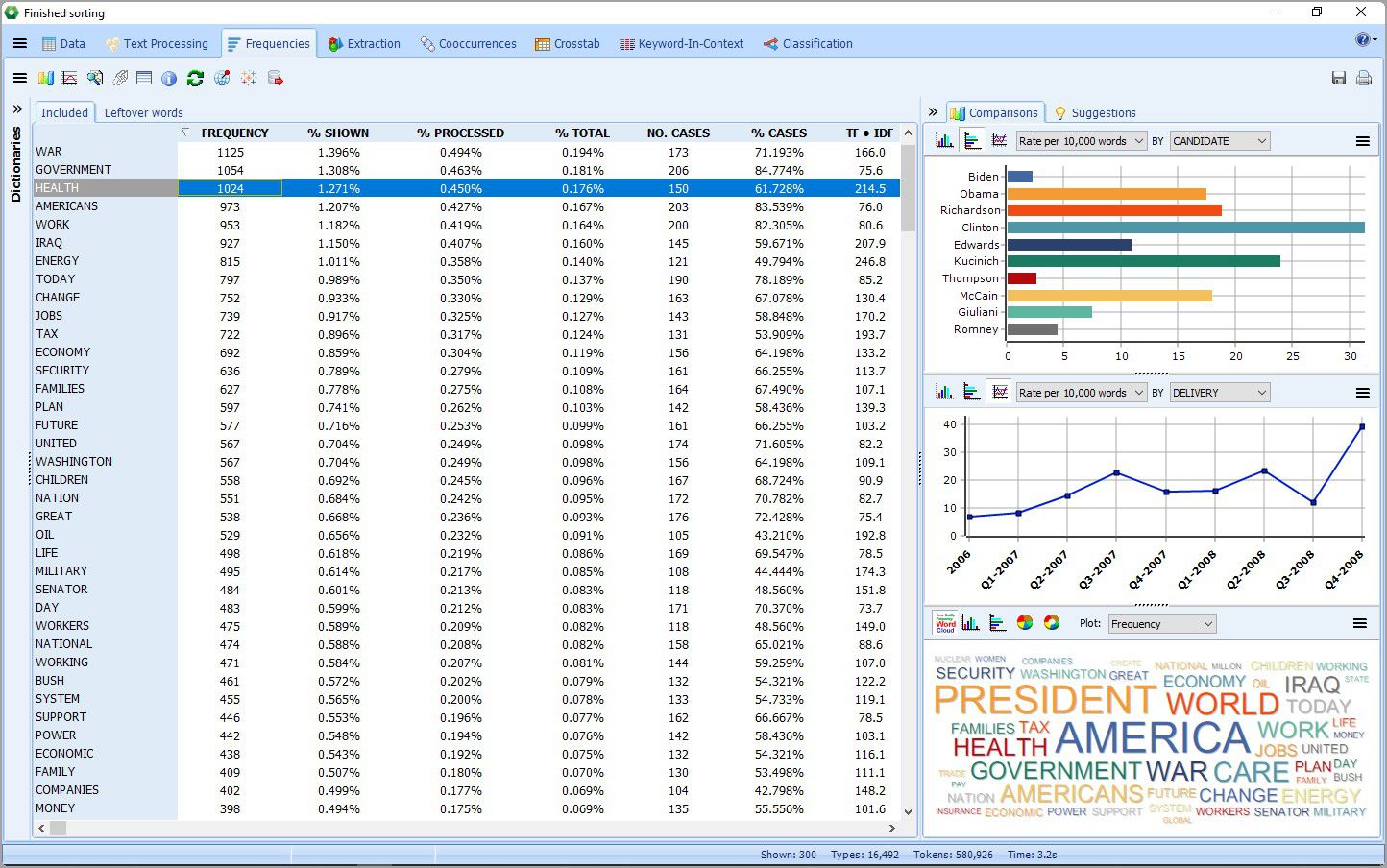
2. Nouveau mode Explorer
Un nouveau mode Explorateur a été implanté pour permettre aux utilisateurs avec peu d’expérience en text mining d’effectuer une extraction sémantique simple et rapide de grandes quantités de données textuelles. Vous pouvez identifier les mots et les phrases les plus fréquents et extraire les sujets les plus saillants de vos documents avec l’outil amélioré de modélisation thématique « topic modeling » de WordStat 8. Vous pouvez à tout moment passer en mode expert, qui vous donne accès à toutes les fonctionnalités de WordStat, y compris les dictionnaires d’analyse de contenu, les analyses croisées et les analyses de cooccurrence.
3. Modélisation thématique améliorée
La routine existante de la modélisation thématique ou « topic modeling » bénéficie de nombreuses améliorations telles qu’un algorithme d’extraction supplémentaire (NNMF) ainsi qu’un processus innovant d’enrichissement de thèmes. Cette technique permet d’aller au-delà du concept de type « bag-of-word » typique de l’extraction de thèmes classique. Elle permet de sélectionner automatiquement les expressions connexes et fournit des suggestions d’expressions supplémentaires et d’exceptions potentielles tout en corrigeant les fautes d’orthographes. Cette approche innovatrice permet une mesure plus précise et plus complète pour l’extraction des thèmes.
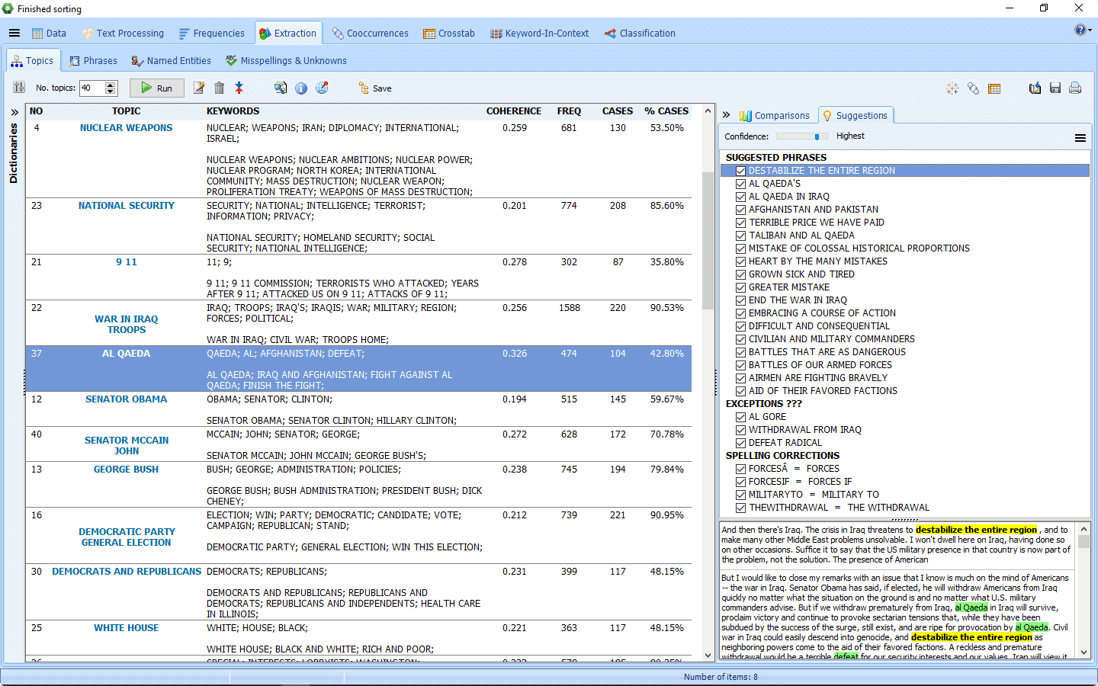
4. Affichages graphiques nouveaux et améliorés
WordStat 8 dispose de plusieurs nouveaux affichages graphiques pour vous aider à mieux comprendre les résultats de votre analyse de données. Nous avons amélioré les nuages de mots interactifs, les graphiques en anneau et en radar.
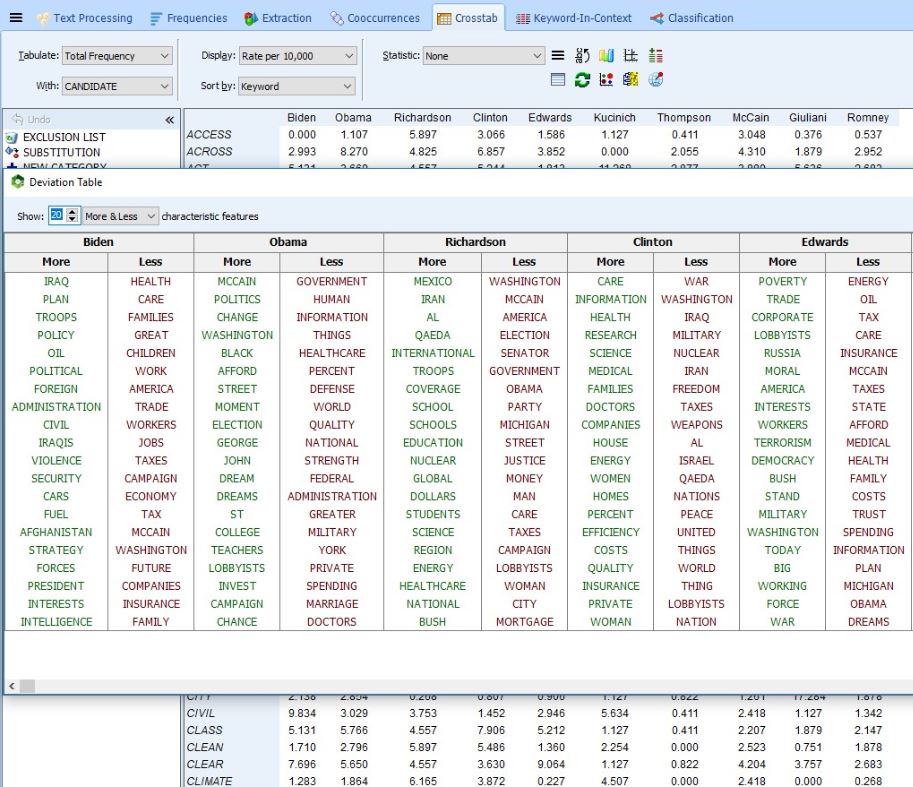
5. Table de déviation
Ceci est une toute nouvelle fonctionnalité incluse dans WordStat 8. Elle a été ajoutée après la publication et vous devez avoir téléchargé WordStat 8.0.7 ou une version ultérieure pour pouvoir y accéder. La table de déviation vous permet de voir les mots / phrases utilisés plus ou moins par rapport à d’autres variables. Vous devez d’abord activer le bouton Analyse croisée pour voir l’icône. Vous pouvez cliquer avec le bouton droit de la souris pour rechercher KWIC, Supprimer et enregistrer dans un onglet délimité, HTML ou bitmap. Pour en savoir plus sur cette fonctionnalité spécifique de WordStat 8, cliquez sur le lien suivant: Deviation Table
6. Exportation des résultats vers le logiciel Tableau
D’un simple clic, vous pouvez également exporter vos résultats vers Tableau Software pour utiliser ses outils avancés de visualisation de données interactives.
![]()
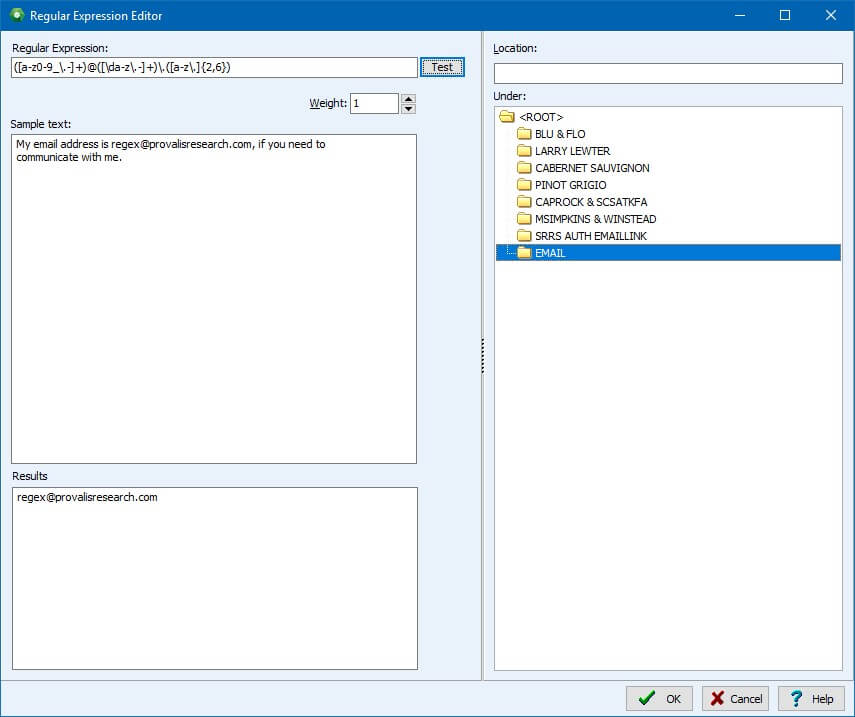
7. Amélioration de la construction de dictionnaires pour l’analyse de contenu
Plusieurs nouvelles fonctionnalités et améliorations ont été apportées à la section des dictionnaires de catégorisation afin de vous aider à être plus précis dans votre recherche de texte et à obtenir des résultats plus précis.
Entrées sensibles à la casse: les dictionnaires de catégorisation et la liste d’exclusion prennent désormais en charge les entrées sensibles à la casse afin de lever toute ambiguïté entre des mots tels que « Bill » et « bill », « Buck » et « buck » ou « us » et « US ».
Recherches d’expressions régulières (Regex): nous avons créé un éditeur d’expressions régulières dans lequel vous pouvez créer vos propres formules de regex pour extraire rapidement des informations spécifiques à partir de vos données textuelles, telles que des adresses électroniques ou des codes postaux.
Nouveau processus de substitution: nous avons amélioré le processus de substitution en le scindant en deux. En le séparant de notre processus de lemmatisation, vous pouvez repérer facilement les substitutions et garder votre dictionnaire de contenu exempt de fautes d’orthographe.
Les listes d’exclusions et de substitutions, de même que votre dictionnaire de catégorisation, peuvent désormais être sauvegardés dans un fichier de modèle de catégorisation. Ce fichier peut être utilisé pour d’autres projets WordStat ainsi que dans QDA Miner, WordStat Document Explorer ou dans notre SDK.
8. Interface améliorée
L’interface améliorée vous permet d’accéder rapidement aux résultats et de les comparer, permettant ainsi d’extraire des informations précieuses en quelques secondes.
WordStat 7
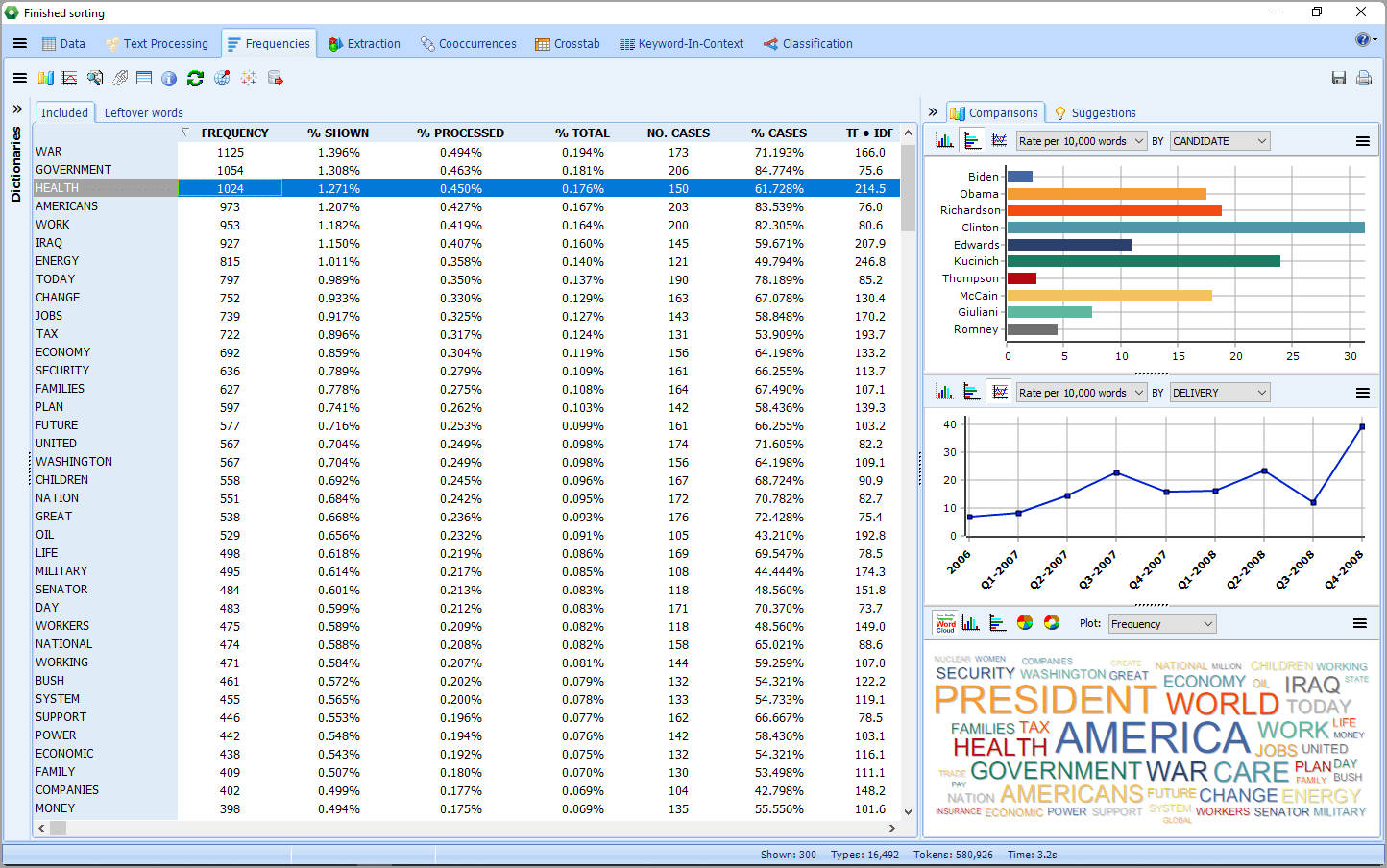
WordStat 8
9. Transformez le texte à l’aide de Python
WordStat 8 ouvre la possibilité aux spécialistes du traitement autmatique des langues (TAL) d’utiliser Python et sa gamme complète de bibliothèques open-source pour prétraiter ou transformer des documents textuels en vue de leur analyse dans WordStat. Cette nouvelle fonctionnalité augmente la flexibilité de WordStat et permet aux utilisateurs d’utiliser leurs compétences en programmation Python.
![]()
10. Transformations numériques
Une nouvelle boîte de dialogue de transformation numérique vous permet de calculer des variables numériques à partir d’autres variables avec jusqu’à 50 fonctions de transformation, notamment des fonctions trigonométriques, statistiques et de nombres aléatoires. Une transformation conditionnelle peut également être effectuée en utilisant une structure logique de type IF-THEN-ELSE.
![]()
11. Binning
Une fonction de binning peut maintenant être utilisée pour transformer des valeurs continues en un plus petit nombre de catégories distinctes. Elle peut être utilisée pour réduire l’effet des valeurs numériques aberrantes, des distributions anormales, ou convertir une variable numérique continue en une variable ordinale. Elle est particulièrement utile pour créer des représentations graphiques de comparaisons lorsque le nombre de valeurs distinctes dans la variable numérique est trop important.
12. Analysis des emojis
Les emojis sont devenus omniprésents dans les médias sociaux, les messages texte, les courriels et autres communications électroniques. Ils sont souvent utilisés pour représenter un objet, exprimer une idée ou un sentiment, ou ajouter une nuance à un message écrit. Ils font souvent partie intégrante du message et peuvent difficilement être ignorés. WordStat 8.0 peut transformer les emojis en leur représentation textuelle, ce qui vous permet de les analyser soit seuls, soit en tant que partie intégrante du message.

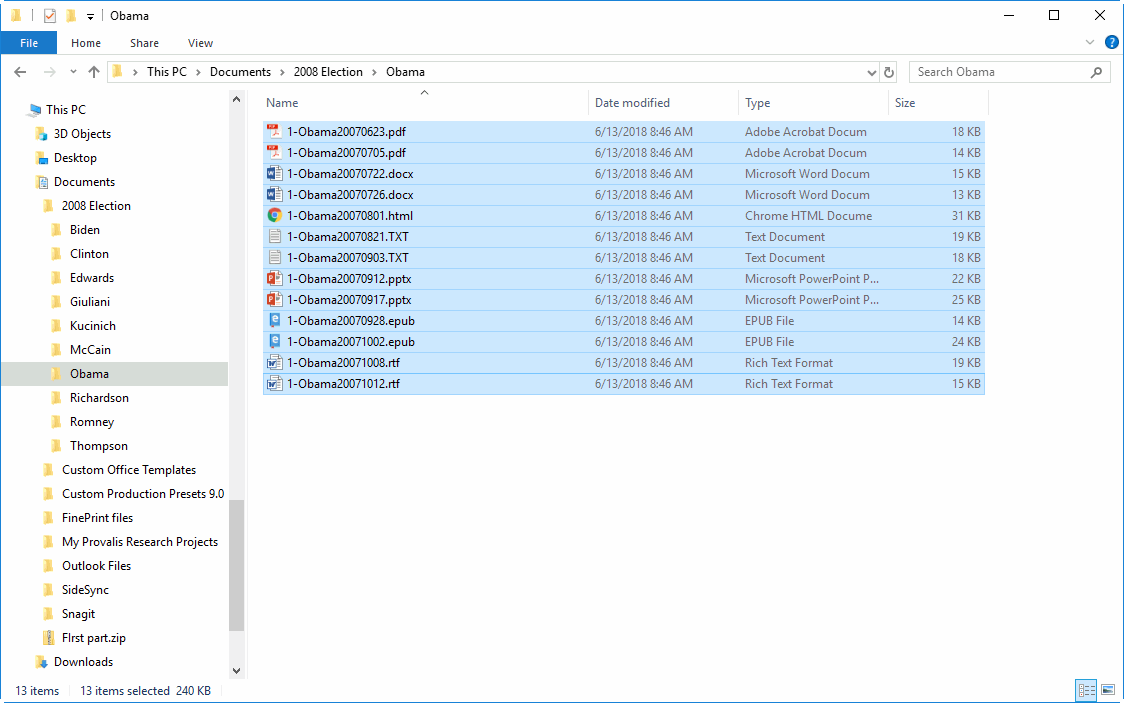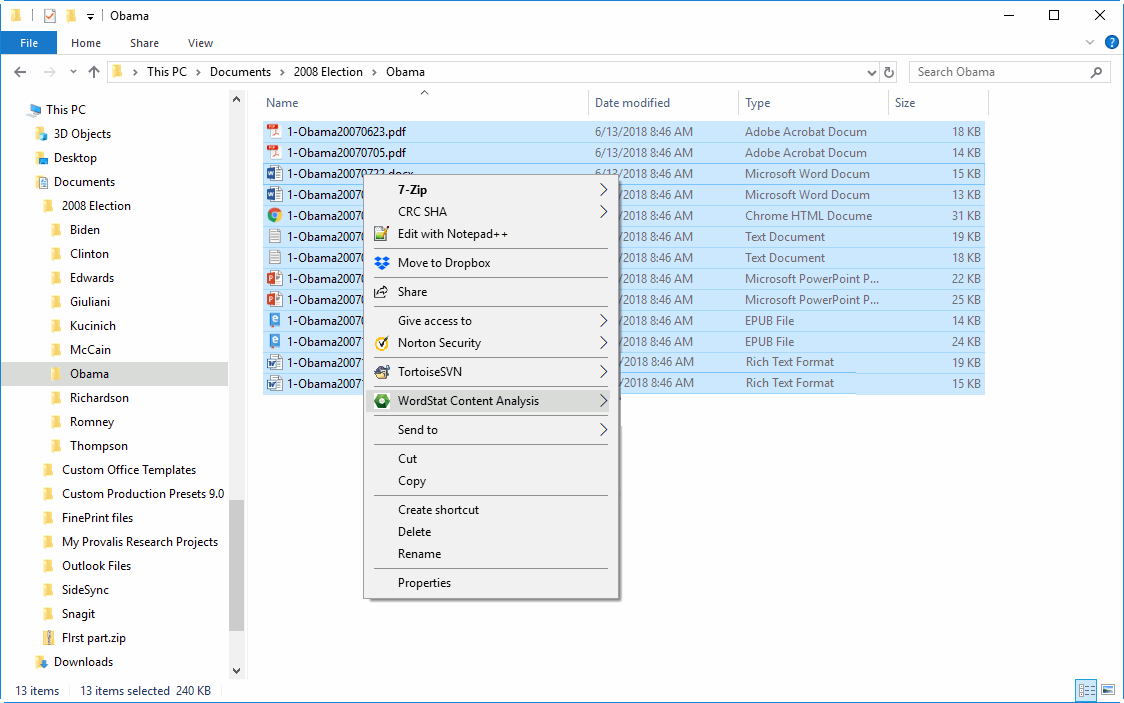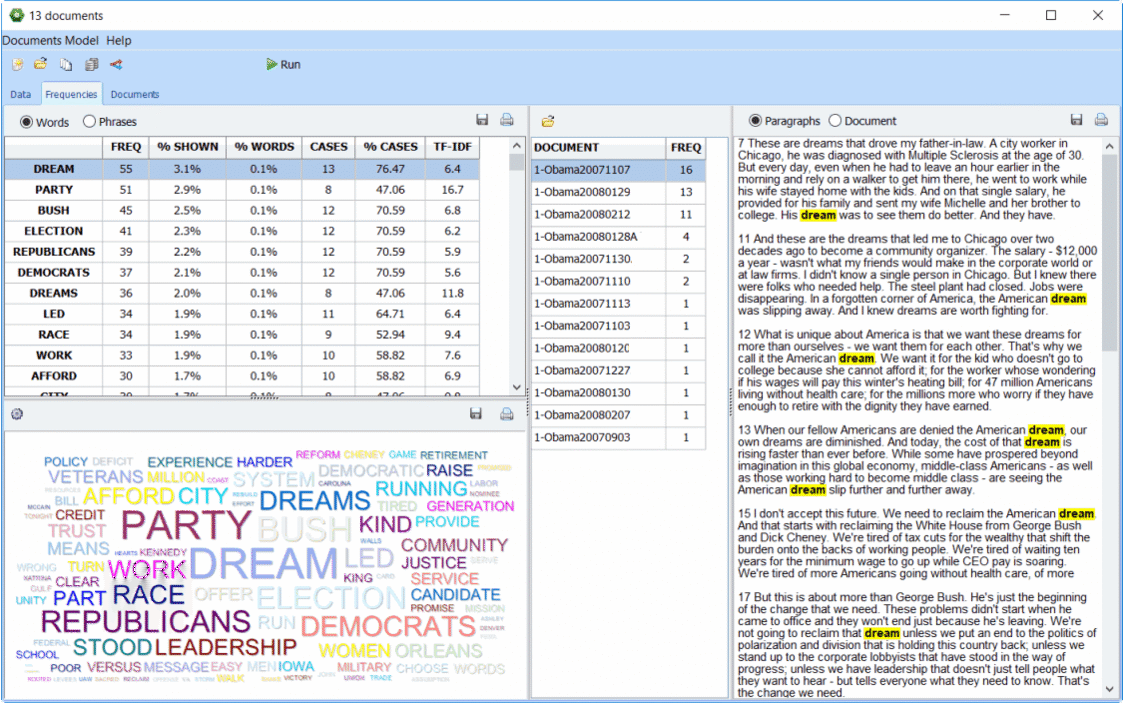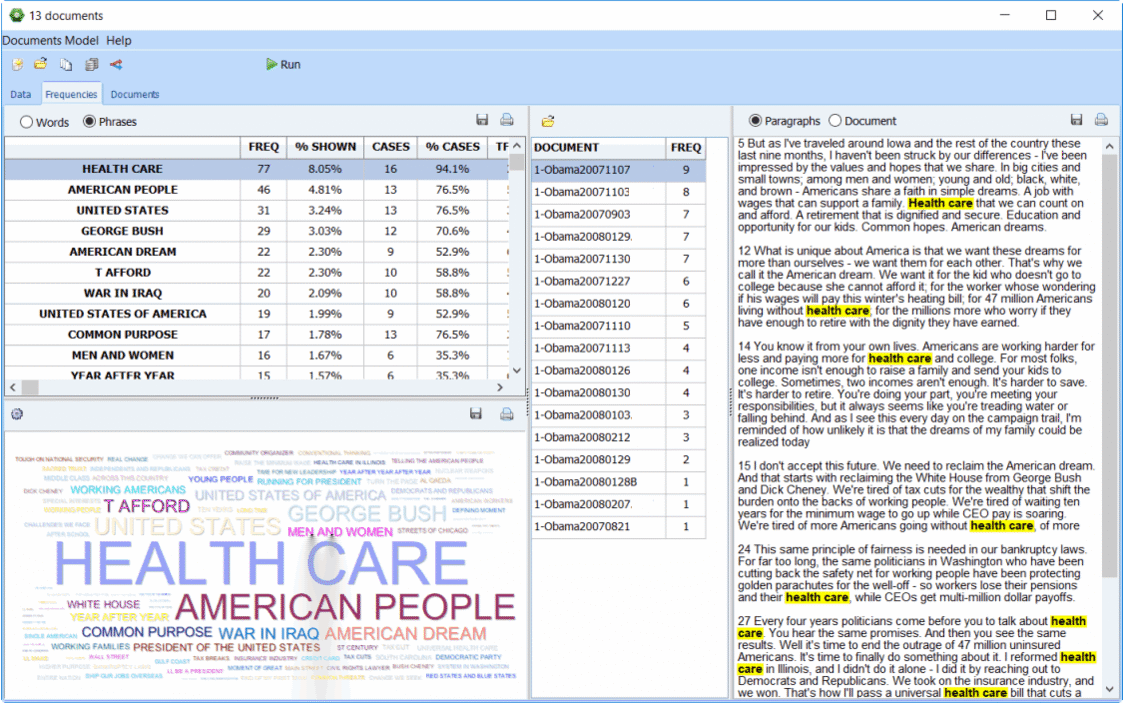
13. Explorez vos documents directement à partir de Windows Explorer
Le nouvel outil Explorateur de documents permet aux utilisateurs d’explorer rapidement le contenu de leurs documents à partir de l’Explorateur Windows, sans qu’il soit nécessaire d’importer des documents ou de créer un projet. Il vous suffit de sélectionner les documents que vous souhaitez explorer ou le dossier qui les contient, de faire un clic droit et de sélectionner Explorer pour identifier rapidement les mots et les phrases les plus fréquents et leur emplacement dans vos documents. D’un simple clic droit, vous pouvez également effectuer une recherche sémantique sur vos documents en utilisant un dictionnaire de catégorisation existant ou classer des documents à l’aide d’un modèle de prédiction dans WordStat. Voir le vidéo de démonstration du WordStat Document Explorer