

Enrichi par l’IA depuis 1998
Logiciel d'analyse de contenu et de « text mining » pour un traitement rapide et précis de grandes quantités d'informations non structurées
LISTE DES CARACTÉRISTIQUES DE WORDSTAT – LOGICEL DE TEXT MINING ET D’ANALYSE DE CONTENU
WordStat permet d’explorer le contenu des données textuelles grâce à ses multiples fonctions de text mining permettant d’extraire rapidement des thèmes et des tendances. Le logiciel permet également de categoriser le contenu des documents selon des concepts prédefinis grâce aux dictionnaires de catégorisation ou au développement de modèles d’apprentissage machine supervisées. Vous trouverez ci-dessous une liste des principales fonctions de text mining et d’analyse du contenu de WordStat.
Importation à partir de diverses sources
WordStat vous permet d’importer directement du contenu en plusieurs langues à partir de nombreuses sources :
- Importation de documents : Word, PDF, HTML, PowerPoint, RTF, TXT, XPS, ePUB, ODT, WordPerfect.
- Importation de fichiers de données : Excel, CSV, TSV, Access
- Importation à partir de logiciels statistiques : Stata, SPSS
- Importation de données de médias sociaux : Facebook, Twitter, Reddit, YouTube, RSS
- Importation de courriels : Outlook, Gmail, MBox
- Importation de données à partir de plateformes d’enquêtes en ligne : Qualtrics, SurveyMonkey, SurveyGizmo, QuestionPro, Voxco, triple-s
- Importation à partir d’outils de gestion de références : Endnote, Mendeley, Zotero, RIS
- Importation d’images : BMP, WMF, JPG, GIF, PNG, et extraire automatiquement toutes les informations associées à ces images, telles que l’emplacement géographique, le titre, la description, les auteurs, les commentaires, etc. et les transformer en variables.
- Importation de bases de données XML
- Connection et importation à partir d’une base de données ODBC.
- Importation de projets à partir de logiciels qualitatifs : Fichiers NVivo, Atlas.ti, Qdpx
- Surveillance de dossiers spécifiques et importation automatique de tous les documents et images stockés dans ce dossier.
Fonctions de traitement de texte
- Analyse de contenu sur une variable alphan umérique courte (jusqu’à 255 caractères) et sur des documents ANSI ou RTF plus longs (plusieurs Mo).
- Lemmatisation et indexation par racines contrôlées par un dictionnaire (anglais, français, italien et espagnol; contactez-nous pour d’autres langues).
- Capacité d’appeler un prétraitement externe des textes EXE ou DLL (indexation par racines porter et transformation n-grammes sont incluses)
- Exclusion facultative des pronoms, conjonctions, etc. à l’aide d’une liste d’exclusion définie par l’usager (liste d’arrêt).
- Catégorisation des mots ou de groupes de mots en utilisant les dictionnaires existants ou définis par l’usager.
- Catégorisation des mots basée sur des règles booléennes (ET, OU, PAS) et de proximité (PRÈS DE, APRÈS, AVANT)
- Substitution de mots et de groupes de mots et score à l’aide de caractères de substitution et de pondération.
- Analyse de fréquence sur des mots clés, des groupes de mots, des catégories ou des concepts dérivés, ou des codes définis par l’usager entrés manuellement dans un texte.
- Développement interactif et entretien facile des dictionnaires, des taxonomies ou du schéma hiérarchique de catégorisation.
- Éditeur de type glisser-déplacer pour assigner facilement des mots, des groupes de mots à l’intérieur des catégories !
- Capacité de limiter l’analyse à des parties spécifiques d’un texte ou d’exclure des commentaires et des annotations.
- Capacité d’effectuer une analyse sur un échantillon aléatoire de cas.
- Contrôle orthographique intégré avec le support pour différentes langues telles que l’anglais, le français, l’espagnol, etc.
- Thésaurus intégré (anglais seulement) pour aider à la création de taxonomies et de schémas complets de catégorisation.
- Filtrage de cas puissant sur tout champ numérique ou alphanumérique et sur toute occurrence de code (avec opérateurs booléens ET, OU, et NON).
- Impression de qualité présentation de tableaux.
- Exportation de n’importe quel tableau vers Excel, ASCII, fichiers de valeurs séparées par des tabulateurs ou des virgules, ou des fichiers HTML.
- Mise en relief flexible des mots clés (l’éditeur de texte peut afficher toutes les catégories en utilisant différentes couleurs)

Extraction rapide des connaissances en utilisant le mode Explorer
Extraire rapidement et facilement des connaissances à patir de grandes quantités de données textuelles grâce au mode Explorer, spécialement conçu pour les personnes peu expérimentées en matière de text mining.
Identifier les mots et les expressions les plus fréquents et extraire les thèmes les plus saillants de vos documents grâce à l’outil de modélisation thématique. À tout moment, vous pouvez passer en mode Expert qui vous donne accès à toutes les fonctionnalités de WordStat.
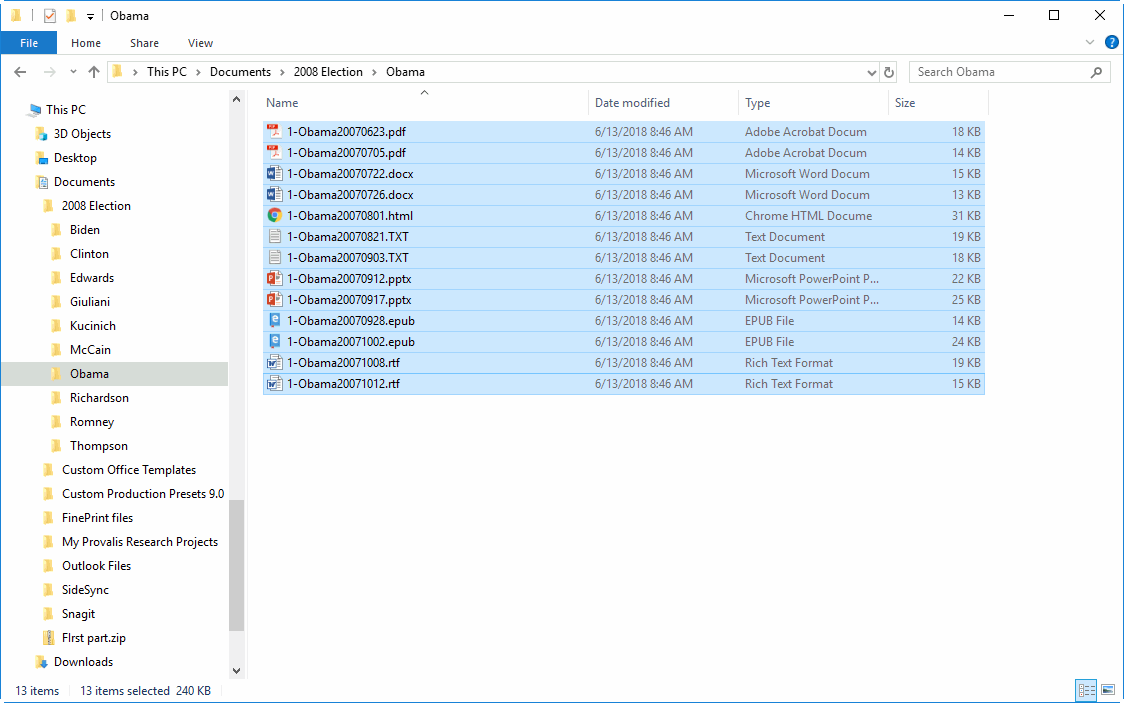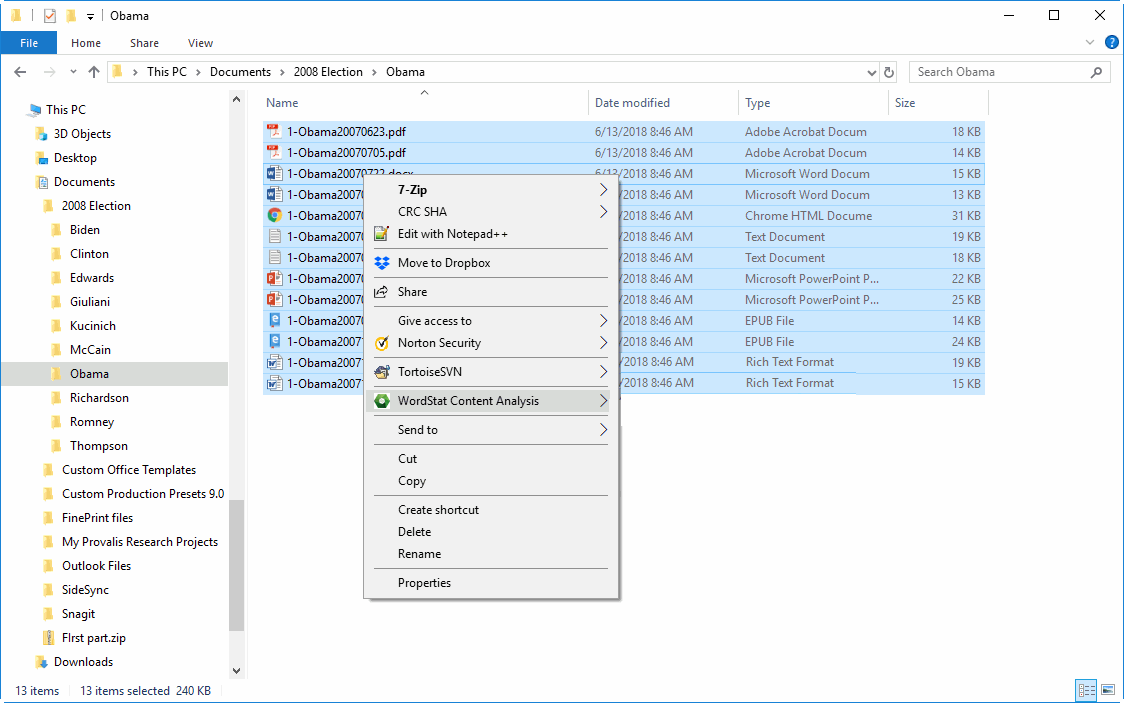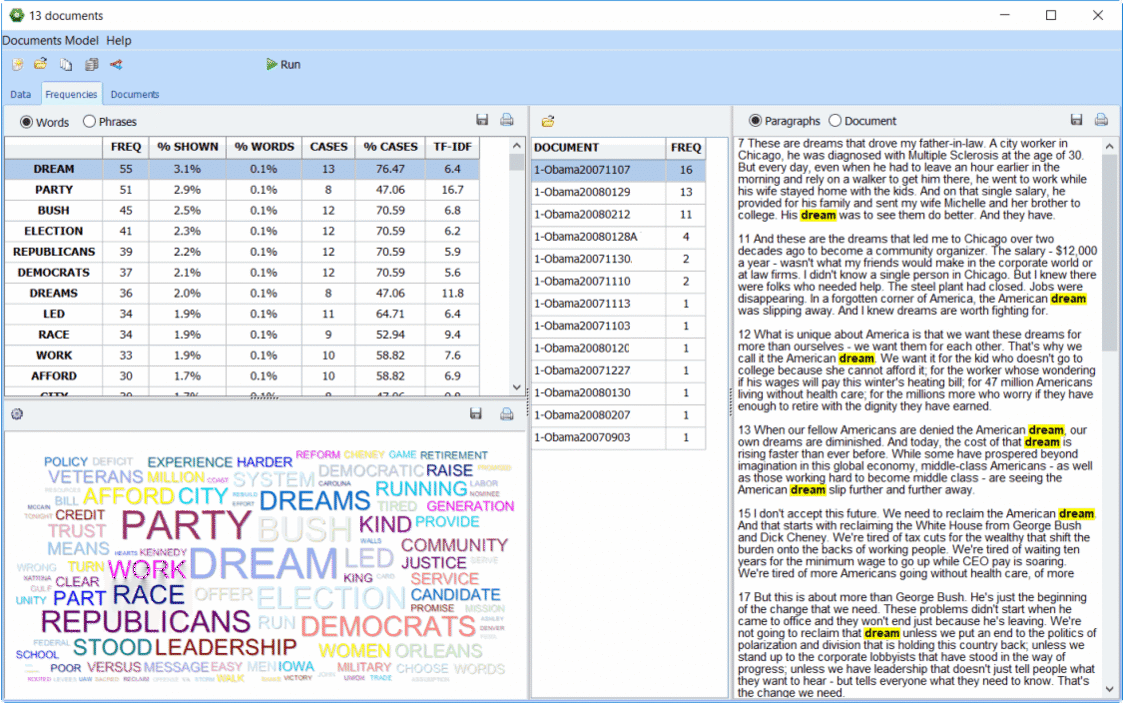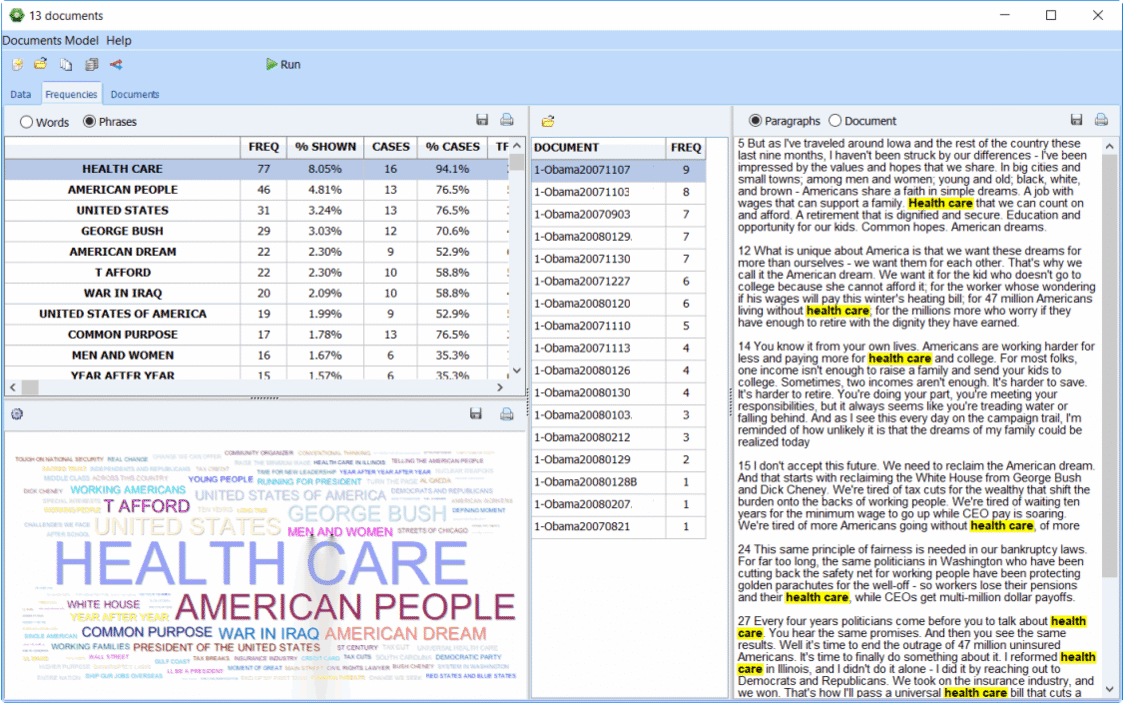
Analyse univariée de la fréquence des mots clés
- Analyse univariée de la fréquence des mots (mot ou compte de catégories et occurrence des enregistrements).
- Matrice mot x co-occurence du mot.
- Matrice de données mot x cas.
- Analyse multidimensionnelle intégrée avec cartes 2D et 3D.
- Graphe de proximité



Fonction d’extraction
- Le chercheur de vocabulaire extrait les termes techniques, les noms de produits et de compagnies aussi bien que les fautes d’orthographe courantes.
- Le chercheur de groupes de mots permet d’identifier facilement les expressions et les groupes de mots récurrents.
Création et comparaison de normes
- Capacité de créer des fichiers de normes basés sur l’analyse de fréquence des mots ou des catégories de contenu.
- Comparaison des fréquences obtenues aux fichiers de normes précédemment sauvegardés.
Fonction de récupération de mots clés
- Une fonction puissante de recherche de mots clés permet l’identification des unités de textes (documents, paragraphes ou phrases) contenant un mot clé ou une combinaison de mots clés avec filtrage facultatif des cas.
- Capacité d’attacher des codes QDA Miner aux segments extraits.
- Les segments extraits peuvent être exportés sur disque en format tabulaire (Excel ou fichiers textes délimités) ou sous forme de rapports (RTF)

Analyse de la co-occurrence des mots clés
- Affichage intégré du groupement et des dendrogrammes de co-occurrence des mots clés.
- Analyse de proximité de premier et de second ordre .
- Graphe de proximité pour identifier facilement tous les mots clés qui co-occurent avec un mot clé cible.
- Analyse multidimensionnelle 2D et 3D sur la fréquence conjointe ou la co-occurrence des mots ou des catégories.
- Critères flexibles de co-occurrence des mots clés (dans un cas, une phrase, un paragraphe, une fenêtre de n mots, un segment défini par l’usager) aussi bien que les méthodes de groupement (proximité de premier et de second ordre, choix des mesures de similarité).
- Extraction facile des textes à partir des dendrogrammes ou des graphes de proximité.
Modélisation thématique
Obtenez un aperçu des thèmes les plus saillants à partir d’un grand volume de textes, en utilisant des techniques avancées d’extraction automatique de thèmes combinant le traitement du langage naturel et l’analyse statistique (NNMF ou analyse factorielle). L’analyse se fait non seulement sur les mots mais aussi sur les expressions et les mots connexes (y compris les fautes d’orthographe).
Alors que dans l’analyse hiérarchique par grappes, un mot peut n’apparaître que dans une seule grappe, la modélisation thématique permet d’associer un mot à plusieurs thèmes, une caractéristique qui représente de manière plus réaliste la nature polysémique de certains mots ainsi que les contextes multiples dans lesquels les mots sont utilisés.
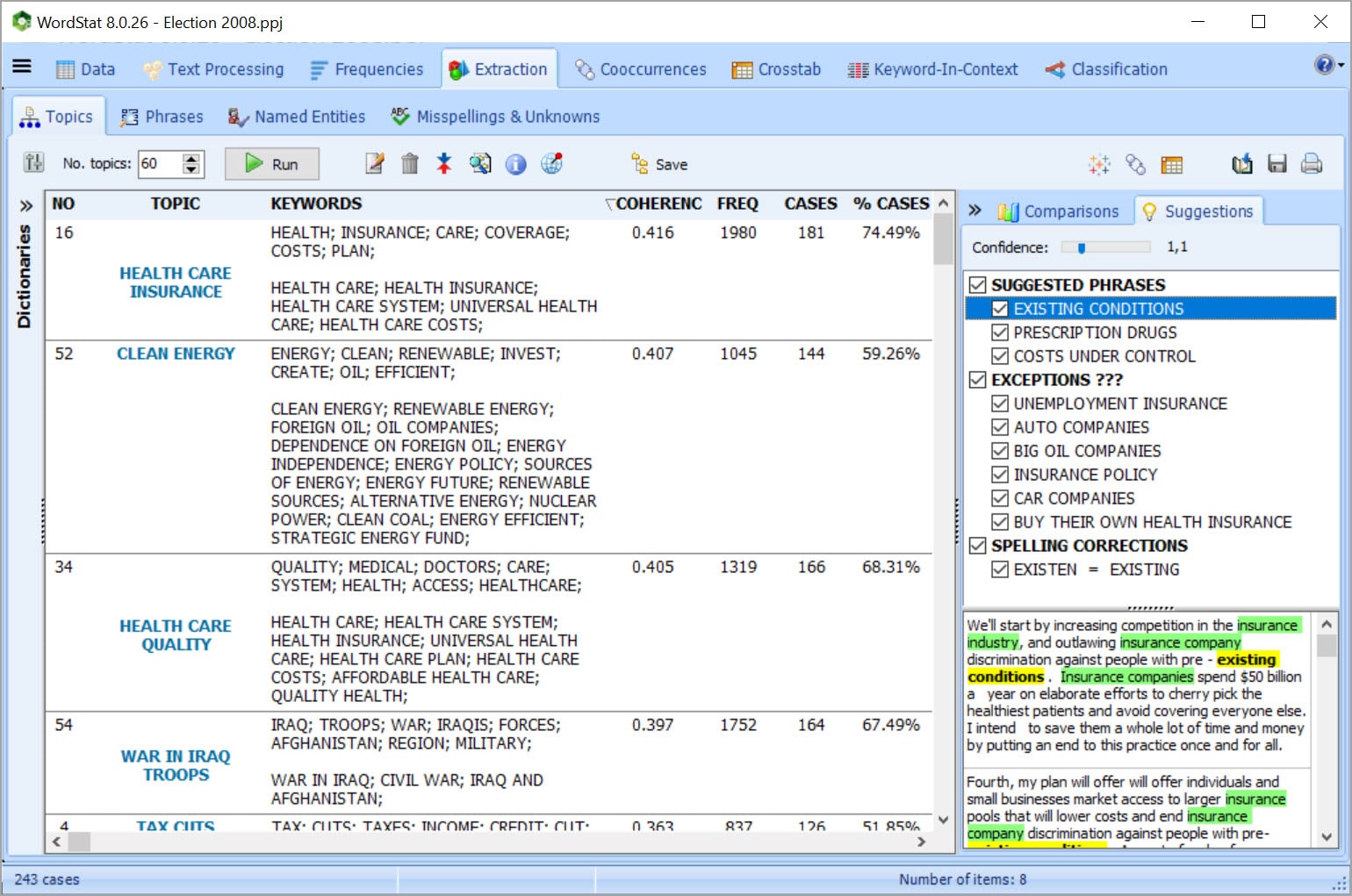
Analyse de similarité des cas ou des documents
- Les groupements hiérarchiques, les analyses multidimensionnelles et les graphes de proximité peuvent être utilisés pour explorer la similarité entre les documents ou les cas.
Réponses multiples et comparaisons
- Peut exécuter l’analyse univariée des fréquences et des tableaux croisés sur l’information stockée dans plusieurs champs alphanumériques (mémos ou variables de chaînes de caractères).
- Comparaison de l’occurrence des mots clés entre différents champs.
- Calcul de l’accord inter-juges (pourcentage d’accord, Kappa de Cohen, pi de Scott, R de Krippendorff et barre-r, marges libres) basé sur les codes entrés manuellement dans différentes variables
Comparaisons bivariées entre les sous-groupes
- Comparaison bivariée entre tout champ textuel et toute variable nominale ou ordinale (sexe du répondant, sous-groupes spécifiques, années de la publication, etc.).
- Choix entre 11 mesures différentes d’association afin d’évaluer la relation entre l’occurrence des mots et les variables nominales ou ordinales (Chi-carré, rapport de probabilité, Tau-a, Tau-b, Tau-c, D de Somers symétrique, Dxy et Dyx de Somers asymétriques, Gamma, R de Pearson, Rho de Spearman).
- Calculs statistiques sur la fréquence absolue ou relative .
- Capacité de trier la matrice selon l’ordre alphabétique des mots, la fréquence des mots ou l’occurrence des mots, sur les statistiques obtenues ou sur leurs probabilités.
- Comparaison visuelle des items entre les sous-groupes en utilisant les diagrammes à barres et à lignes


- Analyse de correspondance (statistiques, graphes combinés 2D et 3D). Cette nouvelle fonction est accessible à partir de la page de tableaux croisés et permet d’obtenir une représentation graphique de la relation entre les variables nominales et les codes résultant d’une analyse de contenu.
- Cartes thermiques (avec groupement double des mots clés et des variables).


Classification automatisée des textes
- Algorithmes appris par l’ordinateur (naïf de Bayes et voisins à k-proximité) pour la classification de documents.
- Fonction de sélection flexible pour le choix automatique des meilleurs sous-ensembles d’attributs.
- Nombreuses méthodes de validation (tous sauf un, d’ordre n, échantillon séparé).
- Le module d’expérimentation permet la comparaison facile des modèles de prédiction et l’ajustement des modèles de classification.
- Les modèles de classification peuvent être sauvegardés sur disque et être appliqués plus tard en utilisant un utilitaire de classification de documents autonome, un programme à lignes de commande ou une bibliothèque de programmation. Note : Le programme à lignes de commande et la bibliothèque de programmation font partie du kit du développeur du logiciel WordStat (SDK) vendu séparément.




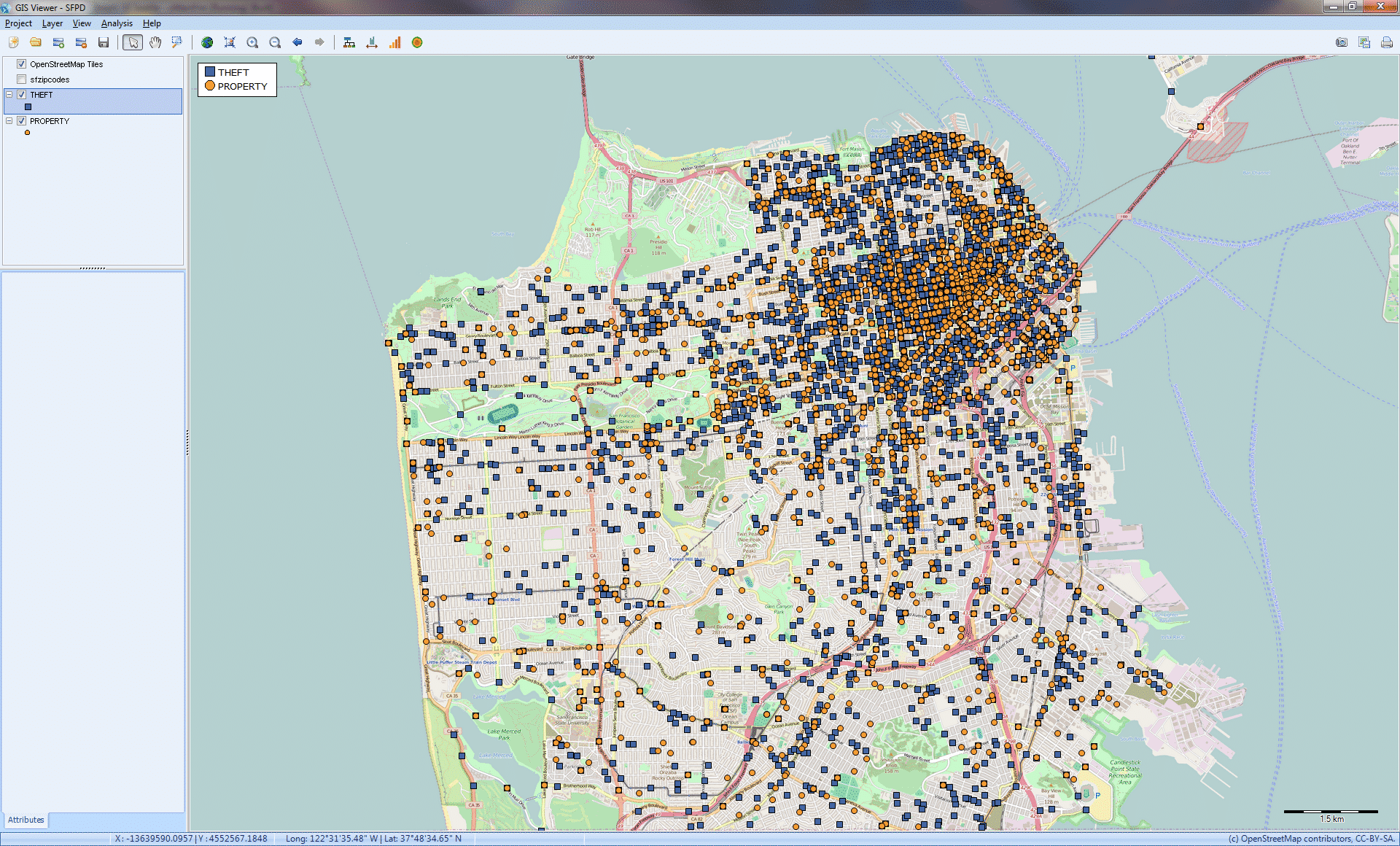
Transformation des données textuelles en cartes interactives (cartographie SIG)
Associez des données textuelles non structurées à des informations géographiques et créez des cartes interactives de points de données et des cartes thermiques. Un service web de géocodage permet de transformer les noms de lieux, les codes postaux et les adresses IP en latitude et en longitude.
Mot clé en contexte (KWIC)
- Capacité d’afficher un tableau KWIC pour examiner le contexte textuel d’un mot, d’un modèle de mots, ou d’une catégorie.
- Capacité de trier le tableau sur toutes les variables (numériques) indépendantes.
- Capacité de passer d’un mot clé KWIC à la variable textuelle afin de visualiser ou d’éditer le texte original.
- La liste KWIC peut être archivée dans des fichiers de données pour une utilisation ultérieure.
- Affichage KWIC personnalisable (paragraphe, phrase ou segment défini par l’usager).
- Rapport de concordance (affichage de tous les résultats comme une liste de paragraphes, de phrases ou de segments définis par l’usager)
: voir le contexte textuel d'un mot")
Intégration complète avec un logiciel statistique
- Des variables alphanumériques peuvent être stockées dans le même dossier que celui de toutes les autres variables numériques.
- Le choix des variables, l’analyse statistique et l’analyse du contenu sont exécutés dans le même programme.
- Des extrants de matrice sont automatiquement ajoutés aux extrants statistiques existants.
- De nouvelles variables représentant l’occurrence des mots, des mots-clés ou des concepts peuvent être ajoutées au fichier de données existant ou être exportées vers un nouveau fichier de données afin d’être soumises à d’autres analyses statistiques (telles que l’analyse hiérarchique sur des mots ou des cas, l’analyse en composante principale, l’analyse de correspondance, la régression multiple, etc.).
- Des données peuvent être importées et exportées sous différents formats de fichiers comprenant dBase, Paradox, MS Excel, Quattro pro, Lotus 1-2-3, SPSS pour DOS, SPSS pour Windows, fichiers de données délimités par des virgules ou des tabulateurs, etc.
- Capacité d’exécuter une transformation numérique et alphanumérique ou d’appliquer des filtres sur les enregistrements du fichier de données pour limiter l’analyse à des sous-groupes spécifiques.
Programmes utilitaires
- Assistant de construction de dictionnaires pour trouver les mots apparentés (synonymes, antonymes, homonymes, méronymes, hyperonymes, hyponymes) dans un thésaurus WordNet (anglais seulement). (100000 synonymes, 120000 racines de mots)




- Le classificateur de documents WS, un petit programme autonome servant à appliquer les modèles de catégorisation et de classification précédemment sauvegardés à des documents externes.
- WSTOOLS – Utilitaire pour importer facilement des documents de différentes tailles dans les fichiers de base de données Simstat. Divers formats de fichiers peuvent être directement importés :
- Texte (avec conversion facultative de ASCII DOS à ANSI Windows)
- HTML (avec ou sans suppression des étiquettes HTML)
- RTF
- MS Word *
- WordPerfect *
- MS Excel * (* la compatibilité avec des versions spécifiques de ces formats de fichiers peut différer selon votre version de Windows et sa configuration.)
- Suppression facultative des espaces en début et en fin de mot, et des retours de fin de ligne.
- Extraction des variables numériques et alphanumériques des documents.
- Les options d’extraction peuvent être sauvegardées sur disque et utilisées plus tard.
- Les documents peuvent être stockés en format ANSI ou RTF.