L’analyse de sentiments dans les logiciels d’analyse de données qualitatives est-elle précise ? mai 21, 2024 - Blogs on Text Analytics

Nous avons vu dans notre précédent article de blog que QDA Miner et WordStat étaient beaucoup plus évolutifs et plus rapides que d’autres outils CAQDAS de bureau. Ces outils offrent néanmoins des techniques d’analyse de texte conçues pour traiter de grands ensembles de données, telles que l’analyse automatique des sentiments et l’extraction automatique de thèmes. Ce deuxième article de blog vise à évaluer la qualité des moteurs d’analyse des sentiments disponibles dans ces outils. Cependant, comparer les performances entre différents outils CAQDAS peut s’avérer très délicat. Atlas.ti calcule les sentiments en utilisant une catégorisation en trois points (Négatif, Positif et Neutre), tandis que NVivo inclut également une catégorie « mixte » pour les contextes comportant à la fois des éléments positifs et négatifs. MaxQDA utilise jusqu’à six classes, incluant une échelle en cinq points et un score « aucun sentiment ». WordStat ne crée pas une classification unique mais produit plutôt deux scores indépendants, l’un pour la positivité et l’autre pour la négativité.
Choisir des références qui s’alignent sur une telle variété de méthodes de classification peut être difficile. Nous avons créé quatre références en utilisant deux ensembles de données d’avis en ligne accessibles au public (avis sur des produits de beauté et avis Coursera provenant de Kaggle), des avis sur des compagnies aériennes extraits de TripAdvisor, et la référence Twitter de SemEval-2013 Task 2. Pour les trois ensembles de données d’avis, nous avons créé des références composées de 20 000 commentaires répartis équitablement entre des avis très négatifs (score de 1) et très positifs (score de 5). Nous avons exclu les scores intermédiaires pour réduire les décisions d’évaluation ambiguës. Par exemple, un score de quatre devrait-il être considéré comme mixte ou positif ? En sélectionnant des éléments clairement positifs et clairement négatifs, nous pouvions au moins évaluer les quatre moteurs sur leur capacité à identifier ces opinions extrêmes.
Pour WordStat, nous avons classé les résultats en utilisant une méthode rudimentaire en soustrayant le score de négativité du score de positivité, en classant les résultats supérieurs à zéro comme positifs, inférieurs à zéro comme négatifs et égaux à zéro comme neutres.
Nous avons calculé un premier score de précision en divisant les classifications correctes par le nombre total d’éléments classés comme positifs ou négatifs, en ignorant les éléments classés comme neutres ou mixtes. Ces résultats sont présentés dans le tableau 1 ci-dessous, avec les meilleurs scores affichés en gras et les plus faibles en rouge.
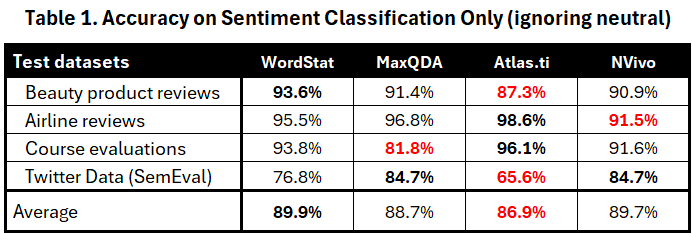
Cette métrique de précision suggère des performances comparables avec des scores de précision globale entre 86,9 % et 89,9 %. Chaque outil atteint le score le plus élevé sur au moins une des quatre références, ce qui suggère que chaque outil peut exceller sur certains types de données mais être moins performant sur d’autres. Pour cette raison, tout score de performance moyen semble trop dépendant du choix des références pour être un indicateur fiable de la performance globale.
Bien que les statistiques ci-dessus puissent sembler encourageantes, nous pensons qu’elles sont trompeuses. Puisque nos références ne comprenaient que les commentaires avec les scores de satisfaction les plus bas et les plus élevés, les catégoriser comme neutres ou mixtes produira probablement des erreurs de classification. Le tableau 2 évalue la couverture de ces quatre moteurs en rapportant le pourcentage d’éléments classés comme positifs ou négatifs.
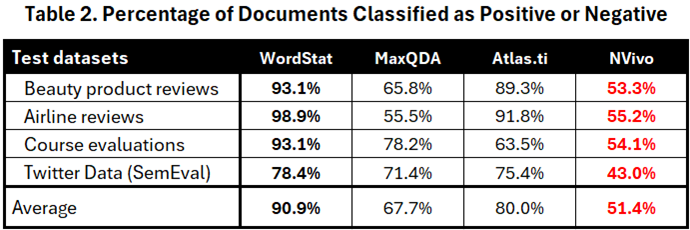
NVivo a la couverture la plus faible, catégorisant près de la moitié des éléments comme neutres ou mixtes, ce qui se traduit par un score de couverture de seulement 51,4 %. MaxQDA a également une couverture globale faible à 67,7 %, tandis qu’Atlas.ti ne catégorise que 20 % des éléments comme neutres, atteignant une couverture de 80,0 %. WordStat affiche la couverture la plus élevée à 90,9 %, avec seulement 9,1 % des éléments marqués comme neutres.
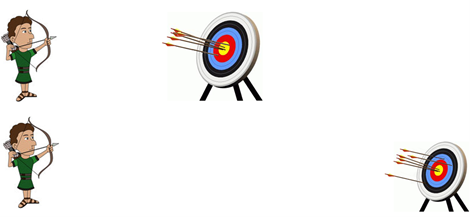
Si un moteur d’analyse des sentiments écarte facilement la moitié des éléments comme mixtes ou neutres et ne classe que les éléments les plus évidemment positifs et négatifs, on ne devrait pas être surpris d’observer de tels scores de précision élevés. La figure 1 ci-dessous illustre pourquoi les scores ci-dessus du tableau 1 peuvent être trompeurs. Bien que l’archer du haut atteigne clairement une meilleure précision, il serait difficile d’affirmer qu’il est le meilleur archer en raison de la disparité du niveau de difficulté auquel ils font face tous les deux.
Figure 1. Qui est l’archer le plus précis ? Qui est le meilleur archer ?
Puisque les références ont été choisies pour ne sélectionner que les scores les plus extrêmes, nous pourrions considérer tout ce qui est classé comme « neutre » ou « mixte » comme incorrect. Cela ne vise pas à minimiser ou à nier l’existence de commentaires contenant à la fois des éléments positifs et négatifs. Ils existent certainement et peuvent même être la règle plutôt que l’exception. Cependant, les catégoriser trop facilement comme mixtes peut probablement conduire à ignorer le déséquilibre évident entre les indicateurs positifs et négatifs et à ne pas identifier le ton réel du commentaire, une nuance qu’un humain reconnaîtrait facilement. Nous reconnaissons également la possibilité que certains éléments puissent effectivement être mixtes ou neutres, mais ils sont moins susceptibles de se produire dans ces ensembles de données extrêmes. Voici quelques exemples de commentaires catégorisés comme neutres par MaxQDA et Atlas.ti et comme mixtes par NVivo :
Service incroyable AF 1533 & AF 008, on nous a avisés d’un retard de 15 minutes 2 heures avant l’enregistrement.
Service médiocre, bagages perdus pour nous tous, etc. Service client médiocre. Service horrible, personnel très impoli et pas du tout sympathique. N’utilisez pas cette compagnie, si quelque chose tourne mal, ils s’en laveront complètement les mains.
Et qu’en est-il de ces commentaires de clients très satisfaits également catégorisés comme mixtes ou neutres par MaxQDA et NVivo :
Fiable. Service fiable et sans chichis. Personnel détendu et amical. Ponctuel. Les sièges en classe économie confort sont excellents.
Personnel amical. Personnel super amical qui a dépassé mes attentes en matière de service. Ce ne sera pas la dernière fois que je volerai avec Aer Lingus.
Nous avons constaté que les longs commentaires étaient particulièrement susceptibles d’être classés comme mixtes ou neutres par MaxQDA et NVivo. Cela est probablement dû à la probabilité plus élevée de rencontrer à la fois des mots positifs et négatifs dans les commentaires longs, même lorsqu’il existe une disparité importante entre les deux. Par exemple, dans un long commentaire, WordStat a identifié 74 éléments négatifs et seulement 4 positifs. Malgré cela, le commentaire a été catégorisé comme mixte par NVivo et neutre par Atlas.ti et MaxQDA. Même chose pour un autre commentaire clairement négatif contenant 50 indicateurs d’émotions négatives et seulement un élément positif.
Le tableau 3 présente des mesures de précision ajustées, calculées comme le pourcentage de prédictions correctes sur le nombre total d’éléments.
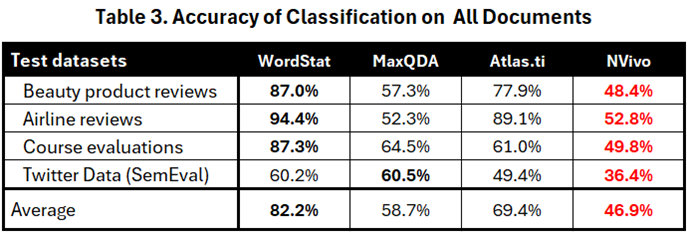
While table 1 did not show any substantial differences in scores, the new table clearly shows that WordStat achieved the best overall performance. Atlas.ti followed in second place with adequate performance on product reviews, but much lower performance on course evaluations and Twitter data. NVivo had the lowest average score of 46.9%, followed by MaxQDA. The adjusted scores also reveal significantly lower performance on Twitter data for all four engines.
One aspect of sentiment classification often neglected by researchers is the inherent bias of different engines. It’s important to understand that sentiment analysis is frequently used to create an overall sentiment index, allowing an organization to monitor over time sentiment toward its organization, its services or its products. Our choice of balanced benchmarks aims to avoid favoring any engine that might disproportionately identify more items as positive or negative. There is also a general tendency for satisfaction scores in surveys to be skewed toward positive evaluation, so an engine that overestimates positive sentiments might be unfairly advantaged over those with neutral or negative biases. Balanced benchmarks not only prevent this unfair comparison but also help identify such biases.
Table 4 shows the result scores obtained by subtracting 50% from the highest absolute percentage after excluding the “neutral” and “mixed” classifications. For example, if an application’s sentiment classification results in 62% positives and 38% negatives, the bias score is +12%. Conversely, if 57% are negative and 43% positive, the bias score is -7%.
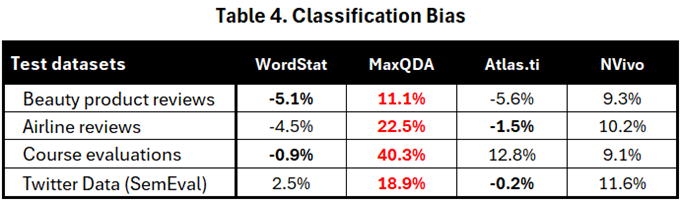
Table 4 clearly shows that MaxQDA consistently exhibits the strongest bias, often presenting an overly positive picture of reality. In the course evaluation benchmark, 90.3% of items classified as positive or negative were deemed positive, while only 9.7% were classified as negative. NVivo also demonstrates a clear positive bias, ranging from +9.1% to +11.6%. In contrast, the other two tools provide a more accurate representation. WordStat’s bias varies between -5.1% and +2.5%, while Atlas.ti generally stays close to the 50% mark, with the exception of the course evaluation benchmark, where it shows a positive bias of +12.8%.
One might rightly argue that the choice of a binary classification may unduly favor tools with few or no “neutral” scores. To address this potential bias, we built three new benchmarks using the first three datasets, selecting an equal number of review scores ranging from very unsatisfied (score of 1) to very satisfied (score of 5). We excluded the Twitter data since it consisted only of binary classifications. Each of the three benchmarks contains 10,000 reviews, with 2,000 randomly selected reviews for each score from the full dataset.
Given that WordStat produces a numerical sentiment score with no theoretical limits, while the other software outputs three (Atlas.ti), four (NVivo), or six (MaxQDA) classes, we determined that the Spearman Rho correlation would be the best comparison method. This statistic provides a more robust measure of how strongly the sentiment engine results correlate with the star ratings assigned by customers. It focuses on the direction of change (increasing/decreasing) rather than the exact magnitude, ensuring a fair comparison between sentiment engines with different output formats.
Table 5 presents the correlation results for all four software. The results from these three benchmarks show that the sentiment scores obtained by WordStat had the highest correlation with the star ratings. Atlas.ti ranked second, while NVivo’s sentiment results had the lowest correlation with the ratings.
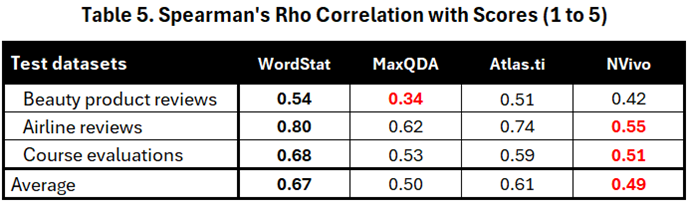
Cette dernière expérience écarte la possibilité que les références (benchmarks), constituées uniquement de scores très négatifs et très positifs, avantagent indûment les moteurs présentant des taux de classification plus élevés et moins de résultats neutres ou mixtes. Les moteurs les plus précis pour identifier ces positions extrêmes sont également ceux qui affichent la corrélation la plus élevée avec l’éventail complet des opinions.
En tant qu’éditeur de WordStat, nous reconnaissons que la publication de comparaisons peut être perçue comme biaisée. Notre intention initiale n’était pas de démontrer la supériorité de notre outil d’analyse de sentiment, mais de souligner l’importance d’évaluer les outils de manière critique plutôt que de se fier aveuglément à leurs résultats. Bien avant que l’analyse de sentiment ne soit intégrée aux outils CAQDAS, nous étions sceptiques quant à sa popularité croissante au sein des plateformes d’analyse de texte d’entreprises telles que Clarabridge, Lexalytics et Bitext. Certaines de ces entreprises revendiquaient une grande précision pour leurs outils, suggérant même qu’ils pouvaient obtenir des résultats similaires quel que soit le type de données ou le domaine. Nous savions que c’était irréaliste. Il nous a fallu des années avant de décider de publier notre propre dictionnaire de sentiments, car nous étions initialement réticents à le faire. Nous avons toujours insisté sur la nécessité de la personnalisation plutôt que d’utiliser le dictionnaire tel quel. Les résultats des comparaisons ci-dessus suggèrent que notre dictionnaire fonctionne bien sur les avis de produits et de services. Cependant, considérez la précision de 60,2 % sur les données Twitter indiquée dans le tableau 4 : elle n’est que légèrement supérieure à la précision de 50 % qui serait obtenue par le simple hasard. Qu’en est-il de ses performances sur les évaluations d’employés, les avis sur les services de santé ou les actualités politiques ? La seule façon de déterminer son efficacité dans ces domaines est de procéder à des tests rigoureux sur de tels ensembles de données.
Nous soutenons que WordStat se distingue en matière d’analyse de sentiment grâce à sa transparence : contrairement aux moteurs de type « boîte noire », les utilisateurs ont la flexibilité de personnaliser notre dictionnaire ou même de développer le leur. Ce niveau de personnalisation n’est pas disponible dans les trois autres outils CAQDAS. Au fil des années, nous avons investi des efforts considérables dans le développement et le test de notre dictionnaire de sentiments, en élargissant ses lexiques de mots positifs et négatifs, en analysant l’impact des négations et en traitant les doubles négations. Toutefois, même avec ces avancées, nous reconnaissons qu’il existe des situations où nous ne nous fierions pas entièrement à ses résultats. C’est pourquoi nous rappelons continuellement à nos utilisateurs de ne pas se fier uniquement à notre dictionnaire tel quel et soulignons l’importance de la personnalisation ou de tests approfondis.
En rendant ces comparaisons publiques, nous espérons inciter nos concurrents à améliorer leurs moteurs d’analyse de sentiment, en visant une meilleure précision et une réduction des biais. Quant à nous, nous restons déterminés à tester notre dictionnaire de sentiments sur de nouveaux ensembles de données, en identifiant diligemment les domaines où il pourrait être moins performant. Si possible, nous améliorerons ses performances ou, à défaut, nous communiquerons de manière transparente toute limitation à nos utilisateurs.
En tant qu’entreprise de développement de logiciels, il aurait été beaucoup plus simple pour nous d’adopter l’approche de nos concurrents et de prendre une licence pour une API d’analyse de sentiment existante ou d’utiliser des bibliothèques de TAL (Traitement Automatique du Langage) établies en Python ou en R. Cela nous aurait permis de produire rapidement des résultats dans plusieurs langues tout en ignorant les lacunes potentielles ou, pire, en les dissimulant. Nous comprenons que de nombreux utilisateurs s’appuient sur ces moteurs « boîtes noires » et qu’il peut être irréaliste d’attendre d’eux qu’ils évaluent de manière critique la précision des résultats. Cependant, nous estimons avoir la responsabilité de ne pas induire nos utilisateurs en erreur. Avec les nombreuses « solutions » de sentiment qui inondent le marché, dont beaucoup ont des niveaux de performance inconnus, il est impératif de faire preuve de prudence. Si certaines solutions peuvent être efficaces, notre expérience nous a montré que d’autres laissent à désirer. Par conséquent, une évaluation approfondie est urgente pour garantir que les utilisateurs ne soient pas trompés.