Les outils CAQDAS sont-ils adaptés aux grands ensembles de données ? novembre 26, 2025 - Blogs on Text Analytics

Les logiciels traditionnels d’analyse de données qualitatives assistée par ordinateur (CAQDAS) ont été conçus pour des projets de recherche qualitative de petite envergure. Cependant, l’avènement d’Internet et la tendance à la numérisation ont considérablement accru le volume de données à la disposition des chercheurs qualitatifs. Les plateformes de médias sociaux (Twitter, Facebook, etc.), les sites d’avis (TripAdvisor, Yelp, etc.), les avis sur les produits (sur Amazon et d’autres plateformes de commerce électronique) ainsi que les bases de données en ligne regorgeant de résumés de revues, d’articles complets, de transcriptions d’actualités, de documents juridiques, de rapports financiers et même de politiques publiques sous forme numérique, n’en sont que quelques exemples.
En 2008, dans un chapitre du SAGE Handbook of Online Research Methods, Grant Blank a observé que les outils de recherche qualitative existants n’évoluaient pas pour tirer parti de cette nouvelle richesse de données. Cela peut expliquer en partie le constat selon lequel la plupart des chercheurs qualitatifs continuent de se concentrer sur l’analyse détaillée d’échantillons de données qualitatives plus restreints, négligeant ainsi ces grands ensembles de données..
Cependant, plus de quinze ans plus tard, de nombreux outils CAQDAS ont mis en œuvre des techniques de traitement automatique du langage (TAL) et d’apprentissage automatique telles que l’analyse de sentiments, l’extraction automatique de thèmes et le minage d’opinions — des techniques spécifiquement conçues pour analyser de grandes quantités de données textuelles non structurées. On pourrait logiquement supposer que ces limitations des outils CAQDAS appartiennent au passé. Une approche plus prudente consisterait toutefois à évaluer les dernières versions de ces outils pour vérifier s’ils possèdent la capacité de mise à l’échelle et les performances nécessaires pour traiter de plus grands ensembles de données.
En décembre 2023, Steve Wright a présenté les résultats d’une telle évaluation. Il a tenté d’analyser des données provenant d’une vaste enquête. Il a mis à l’épreuve trois outils CAQDAS : NVivo, Atlas.ti et notre propre logiciel, QDA Miner, ainsi que Leximancer (qui, techniquement, relève davantage de la catégorie de la fouille de textes, tout comme notre logiciel WordStat). Sa conclusion a été que ni NVivo ni Atlas.ti n’étaient suffisamment rapides ou capables de passer à l’échelle (scale up), plantant souvent lors du traitement de grandes quantités de données textuelles.
Bien qu’il ait mentionné QDA Miner comme une exception, capable de passer à l’échelle et d’offrir des performances rapides pour de nombreuses tâches, il a néanmoins conclu que les logiciels de bureau (desktop), dans leur ensemble, ne seraient peut-être pas capables de gérer de grands volumes de données textuelles, suggérant plutôt que des solutions basées sur le cloud ou sur serveur pourraient être la réponse. Compte tenu de son observation concernant notre logiciel, une telle conclusion peut sembler hâtive et potentiellement trompeuse. Nous avons toujours consacré d’importants efforts de programmation pour garantir que QDA Miner puisse gérer de très grands ensembles de données et s’exécuter rapidement. Pourtant, la question demeure : quelle est la véritable capacité de mise à l’échelle de QDA Miner et quelle est sa rapidité réelle lors de l’analyse de grandes quantités de texte ? Comment se situe-t-il par rapport aux autres outils CAQDAS ?
Comparaison des performances et de la capacité de mise à l’échelle « scalability » des tâches de base en analyse qualitative
Pour répondre à ces questions, et tenter également d’identifier certains des facteurs pouvant expliquer les différences de performance et de capacité de mise à l’échelle « scalability », nous avons décidé de soumettre les principaux outils CAQDAS de bureau actuellement sur le marché à des tests sur de grands ensembles de données.
Bien que nous ayons traité par le passé des projets QDA Miner contenant des millions d’enregistrements, nous avons décidé de commencer avec un ensemble de données beaucoup plus modeste, mais tout de même relativement volumineux du point de vue de la recherche qualitative. Les données consistaient en 50 425 commentaires sur des vols aériens extraits de TripAdvisor. Nous avons comparé les performances de QDA Miner avec celles de trois de ses concurrents : MaxQDA, Atlas.ti et NVivo. Tous ces outils de bureau intègrent des fonctionnalités de fouille de textes similaires à celles présentes dans notre logiciel WordStat, un logiciel dédié à la fouille de textes et à l’analyse quantitative de contenu.
Nous avons mesuré la vitesse de diverses tâches, y compris l’importation, la recherche de texte, l’encodage automatique, la récupération des segments codés, ainsi que certaines techniques exploratoires telles que la production d’un nuage de mots et d’un tableau de fréquence des mots, et l’extraction de n-grammes (locutions de 2 à 5 mots). Nous avons également examiné le temps nécessaire pour effectuer une analyse de sentiments, extraire des thèmes et exporter les segments de texte récupérés vers des fichiers Excel et .DOCX.
Étant donné que l’analyse de sentiments et l’extraction de thèmes ne sont pas disponibles dans QDA Miner mais sont normalement réalisées à l’aide du module complémentaire WordStat, nous avons indiqué la durée de ces opérations dans WordStat. Tous les tests ont été effectués sur un ordinateur Windows 11 équipé d’un processeur Intel Core i9-10900, de 64 Go de RAM et de 4 To d’espace disque (SSD M.2). Nous avons utilisé les dernières versions de chaque logiciel disponibles au 1er mai 2024.
Le tableau 1 présente les performances obtenues sur ces tâches. D’emblée, on constate une différence significative de performance lors de l’importation des données à partir d’une feuille de calcul Excel. Alors que QDA Miner a importé l’ensemble de données de test en environ 17 secondes, le temps d’importation pour les autres outils s’est échelonné de 1 heure 23 minutes pour Atlas.ti à 2 heures et 23 minutes pour NVivo (sans codage de thèmes ni de sentiments). MaxQDA a planté après une heure et demie, mais a tout de même réussi à importer le fichier, ce qui nous a permis de continuer à tester le logiciel. Une observation importante est que, pour les trois outils CAQDAS concurrents, la vitesse d’importation s’est considérablement dégradée à mesure que le nombre d’enregistrements importés augmentait. Pour des raisons évidentes, nous avons décidé de ne pas soumettre ces outils à des ensembles de données plus volumineux.
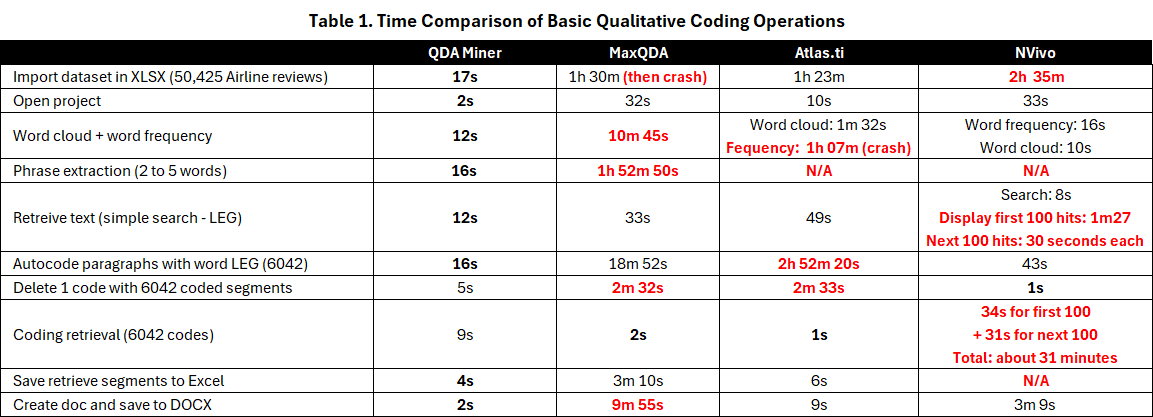
Les résultats restants pour toutes les autres tâches du tableau 1 démontrent clairement l’écart de performance substantiel entre QDA Miner et les autres outils. QDA Miner a accompli toutes les tâches en quelques secondes. Les procédures les plus longues ont été l’extraction de n-grammes (2 à 5 mots) et l’encodage automatique de 6 049 paragraphes, toutes deux n’ayant pris que 16 secondes. En comparaison, plusieurs de ces tâches ont pris plusieurs minutes, voire une heure ou plus, pour les trois autres logiciels. Les outils concurrents ont affiché leurs meilleures performances lors des opérations de recherche et de récupération, tandis que les pires performances ont été observées lors des opérations d’encodage automatique, au moment de tenter d’appliquer des codes à des segments de texte. L’encodage automatique dans Atlas.ti s’est avéré particulièrement problématique, saturant souvent la totalité des 64 Go de mémoire de l’ordinateur avant de planter. La même conséquence (saturation de la mémoire et plantage) s’est produite lors de la tentative de production d’un simple tableau de fréquence des mots dans Atlas.ti.
Des trois autres outils CAQDAS, NVivo a semblé offrir les performances les plus constantes, outre sa très faible performance pour l’importation de l’ensemble de données. Il est toutefois important de noter que, bien que NVivo ait obtenu le meilleur résultat pour une recherche de texte simple avec 8 secondes, il lui a fallu 1 minute et 36 secondes pour afficher les 100 premiers résultats, et 30 secondes supplémentaires pour chaque tranche de 100 résultats suivants. En revanche, QDA Miner a recherché et récupéré l’ensemble des 6 045 segments en 12 secondes, suivi de MaxQDA (33 secondes) et d’Atlas.ti (49 secondes). Cela peut également ne pas refléter les performances sur d’autres opérations. Par exemple, nous avons dû interrompre une requête de codage matricielle dans NVivo qui, selon nos estimations, aurait pris plus de 16 jours à s’exécuter, une opération qui a pu être réalisée en quelques secondes dans MaxQDA ou QDA Miner.
Comparaison des performances et de la capacité de mise à l’échelle « scalability » des tâches de fouille de textes
D’une manière générale, WordStat a été le plus rapide sur les tâches de fouille de textes (voir le tableau 2), mais les comparaisons ne sont pas aussi simples que ce que nous avons vu plus haut. Chaque outil diffère grandement dans sa façon d’effectuer l’analyse de sentiments. NVivo analyse et encode automatiquement les réponses selon le sentiment en une seule opération, ce qui prend un peu plus de 14 minutes. Atlas.ti et MaxQDA calculent d’abord le sentiment, puis permettent à l’utilisateur d’encoder automatiquement les commentaires dans une seconde opération. Bien que la partie analyse soit effectuée rapidement en moins d’une minute pour les deux, l’encodage automatique s’est avéré plutôt lent pour MaxQDA, prenant plus de 28 minutes, tandis qu’Atlas.ti a planté après plus de six heures de traitement.
WordStat a été le plus rapide pour appliquer l’analyse de sentiments, ne prenant que 11 secondes. Cependant, alors que tous les autres outils classent les réponses dans des catégories mutuellement exclusives, WordStat calcule deux scores indépendants pour la positivité et la négativité. Trois opérations supplémentaires ont donc été nécessaires pour obtenir une catégorisation : 1) enregistrer les deux scores de sentiment dans des variables numériques, 2) calculer la différence entre ces deux variables et 3) recoder les valeurs obtenues en trois classes (positive, négative et neutre). Cette manipulation a cependant pu être réalisée en moins d’une minute avec un temps de traitement cumulé de 22 secondes.

Les outils diffèrent également grandement dans la méthode qu’ils utilisent pour extraire des sujets ou des thèmes et, bien que les résultats obtenus soient assez différents, l’objectif demeure le même : fournir une description rapide du contenu d’une grande quantité de texte non structuré. Lorsque l’on applique ces techniques sur un ensemble de données de 243 discours, ce qui représente approximativement 1 100 pages de texte, on constate que WordStat réalise cette opération en seulement 3 secondes. Toutes les autres applications ont pris entre une minute et deux minutes et demie. À notre avis, de telles performances restent tout à fait raisonnables compte tenu de la grande quantité de texte analysée. Pour cette raison, l’aspect le plus important à prendre en compte est la qualité des résultats obtenus et leur utilité pour identifier le sujet de ces documents, un point que nous aborderons plus tard.
Comparaison de l’utilisation de la mémoire
Documenter l’utilisation de la mémoire de ces outils CAQDAS durant l’expérience a fourni des informations précieuses, expliquant potentiellement certains des problèmes de stabilité (plantages) et des différences de performance que nous avons rencontrés. Les résultats présentés dans le tableau 3 nous ont surpris. La mesure initiale a porté sur la quantité de mémoire utilisée par chaque logiciel lors de son lancement, avant même l’ouverture d’un fichier de données. L’utilisation de la mémoire variait de 246 Mo pour Atlas.ti à 325 Mo pour MaxQDA, NVivo se situant au milieu avec 305 Mo. En comparaison, QDA Miner n’en utilisait qu’une infime fraction, soit seulement 8,5 Mo. Cet écart s’est creusé après le chargement de l’ensemble de données de test, l’utilisation de la mémoire passant de 594 Mo pour NVivo à un montant considérable de 1,4 Go pour Atlas.ti. En revanche, l’utilisation de la mémoire de QDA Miner n’a augmenté qu’à 14 Mo. Fait notable, la taille du projet n’a pas affecté de manière significative l’utilisation de la mémoire de QDA Miner. Nous avons chargé une version beaucoup plus volumineuse de l’ensemble de données sur les compagnies aériennes, comprenant plus d’un million d’enregistrements, et l’utilisation de la mémoire est restée inchangée à 14 Mo.

Discussion
Nous ne pouvons que spéculer sur les raisons de l’utilisation si élevée de la mémoire et de la lenteur des performances observées dans les autres outils CAQDAS. Les choix de langages de programmation et de plateformes (.NET et QT) pourraient être un facteur. Cependant, nous ne pouvons écarter la possibilité d’algorithmes et de structures de données inefficaces, ainsi qu’un manque d’efforts d’optimisation des performances ou de stratégies de gestion de la mémoire. Puisque leur marché principal a toujours été constitué de chercheurs qualitatifs analysant des projets relativement modestes, ces optimisations ne répondaient peut-être pas à un besoin pressant. En revanche, QDA Miner a été conçu à l’origine comme un logiciel qualitatif pouvant également servir de module de base pour notre logiciel de fouille de textes WordStat ; ainsi, la gestion de grands ensembles de données n’était pas un ajout tardif, mais une exigence initiale.
Ce dernier point souligne que la comparaison ci-dessus ne reflète pas nécessairement la pertinence de ces outils pour la recherche qualitative typique. Si les besoins impliquent l’analyse de quelques dizaines de transcriptions d’entretiens ou de quelques centaines de réponses à une enquête, n’importe lequel de ces outils gérerait probablement ces projets sans effort. Cependant, si l’ensemble de données se compose de milliers de pages, ou de dizaines de milliers, voire de centaines de milliers de réponses ouvertes ou de commentaires de clients, la comparaison suggère clairement que QDA Miner est le seul parmi ces quatre outils CAQDAS à offrir la capacité de mise à l’échelle et les performances nécessaires pour traiter efficacement de tels grands ensembles de données. La nécessité de fournir une assistance à l’encodage aux utilisateurs ayant de grands projets est également la raison pour laquelle QDA Miner propose plusieurs fonctionnalités d’assistance reposant sur l’apprentissage automatique supervisé et non supervisé (cf. requête par l’exemple, recherche de similarité de codes, encodage par grappes).
Cet article de blogue s’est concentré sur la vitesse et les besoins en mémoire des différents outils CAQDAS. La question de l’utilité et de la précision des fonctionnalités d’analyse de texte disponibles dans ces outils reste entière. Ce sera le sujet du prochain article (voir L’analyse de sentiments dans les logiciels d’analyse de données qualitatives est-elle précise ?).
Références :
Blank, G. (2008). Online research methods and social theory. In N. Fielding, R. Lee, & G. Blank (Eds.), The SAGE Handbook of Online Methods (pp. 537–549). London: Sage.
Wright, S. (December 2023). Transparency in Qualitative Analysis using Machine Learning: Making Informed Choices and Explaining Insights [Video Presentation]. Presented at the Symposium on A.I. in Qualitative Analysis. CAQDAS Networking Project.