

Enrichi par l’IA depuis 2007
Logiciel d’analyse qualitative et de méthodes mixtes, conçu pour une assistance avancée au codage, à l’analyse et à la rédaction de rapports
NOUVEAUTÉS DE LA VERSION 2025
Présentation de QDA Miner 2025 doté d’une IA générative
Au fil des ans, QDA Miner a été un pionnier dans l’intégration de l’IA dans l’analyse qualitative, en introduisant des fonctionnalités telles que la requête par l’exemple (2007), le codage par cluster et les outils de recherche de similarité de code (2011). L’arrivée de ChatGPT en novembre 2022 a marqué un saut significatif dans la compréhension du langage naturel, suscitant une vague de regain d’intérêt pour l’IA dans toutes les disciplines.
En réponse à cette évolution, Provalis Research a consacré deux années à une évaluation approfondie des capacités et des limites de l’IA générative. Cette période d’étude a permis d’explorer les domaines où l’IA générative peut véritablement enrichir la perspicacité humaine, soutenir les outils d’IA traditionnels, ou même constituer une solution autonome pour des tâches spécifiques. Les conclusions de cette évaluation ont mis en évidence la puissance de l’IA générative, tout en reconnaissant les défis notables qu’elle doit encore surmonter, notamment en termes d’évolutivité, de biais potentiels, de coûts de calcul élevés et de manque de transparence. Malgré ces limitations, il a été constaté que l’élaboration soignée d’invites peut contribuer à atténuer certains de ces problèmes et à faire de l’IA générative un outil précieux dans les contextes appropriés.
Dans le paysage actuel des logiciels d’analyse qualitative assistée par ordinateur (CAQDAS), de nombreuses implémentations d’IA générative fonctionnent comme des « boîtes noires » — laissant les utilisateurs dans l’ignorance quant à la technologie d’IA utilisée, au modèle qui alimente le système et à la manière dont les résultats sont générés. De plus, l’accès aux invites sous-jacentes qui ont produit ces résultats est généralement restreint. Cette opacité peut engendrer un manque de confiance dans les résultats et limiter la capacité des chercheurs à comprendre et à valider le processus analytique.
Avec QDA Miner 2025, une approche fondamentalement différente a été adoptée. Une fois de plus Provalis Research s’engage en faveur de la transparence et du contrôle par l’utilisateur. Ainsi, vous avez la liberté de choisir le moteur d’IA et le modèle qui correspondent le mieux à vos besoins et à votre budget. De plus, les invites proposées dans QDA Miner 2025 sont entièrement accessibles et modifiables, offrant aux utilisateurs la possibilité de les adapter et de les personnaliser. Il est même possible de concevoir des invites entièrement nouvelles pour des analyses sur mesure. Bien que nous envisagions d’explorer à l’avenir des flux de travail plus guidés ou automatisés pour des tâches complexes en plusieurs étapes, notre objectif principal demeure d’offrir aux chercheurs une clarté sur le processus et une confiance dans les résultats.
Cette orientation vers la transparence et le contrôle utilisateur distingue QDA Miner 2025 des autres solutions du marché et répond aux préoccupations croissantes concernant l’explicabilité de l’IA dans la recherche.
1. Choix Étendu de Moteurs et de Modèles d’IA
QDA Miner 2025 introduit une flexibilité sans précédent en matière de choix de moteurs et de modèles d’intelligence artificielle. Les utilisateurs ne sont plus contraints de s’engager dans un abonnement coûteux pour accéder à un moteur d’IA inconnu et à un modèle linguistique non divulgué. Cette nouvelle version offre la possibilité d’effectuer des analyses et des transformations de texte en utilisant le moteur de leur choix parmi quatre options en ligne : OpenAI, Gemini, Claude ou Mistral. En complément, une option hors ligne gratuite est également disponible grâce à l’intégration d’Ollama.
Cette diversité de choix permet aux chercheurs de sélectionner l’infrastructure d’IA qui correspond le mieux à vos besoins spécifiques en termes de performance, de coût et de préférences personnelles.

2. Nouvelles Routines d’Analyse et de Transformation de Texte Propulsées par l’IA
Nous avons évalué un large éventail de fonctionnalités reposant sur l’IA et retenu celles offrant les meilleures performances, tout en veillant à un juste équilibre entre vitesse de traitement et coût. Parmi les plus efficaces figurent l’analyse des sentiments, l’extraction des avantages et des inconvénients, la correction orthographique et la traduction automatique — des tâches qui produisent des résultats très fiables avec la plupart des moteurs d’IA. Nous avons également intégré un outil de notation de la lisibilité assistée par IA, ainsi que des outils de lemmatisation et de segmentation adaptés aux langues asiatiques (chinois, japonais, thaï, etc.) et de regroupement des tokens monosyllabiques en vietnamien.
QDA Miner 2025 vous permet également de créer vos propres scripts d’analyse ou de transformation de données, élargissant ainsi les capacités du logiciel — dans les limites de votre imagination et, bien entendu, de celles de l’IA générative actuelle.
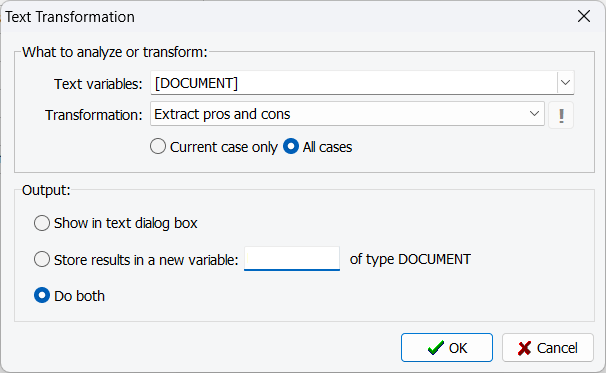
3. Recherche de texte par langage naturel optimisée par l’IA
En complément des nombreux outils de recherche déjà intégrés, QDA Miner 2025 prend désormais en charge les requêtes en langage naturel, propulsées par l’IA générative. Cette nouvelle approche permet aux utilisateurs de rechercher des phrases, des paragraphes ou même des documents entiers pertinents en formulant simplement leurs questions ou instructions en langage courant. Elle offre ainsi une souplesse inédite dans l’exploration des données textuelles, en supprimant la nécessité d’identifier les bons mots-clés ou de maîtriser une syntaxe de requête complexe. Les recherches deviennent plus intuitives, plus contextuelles — et s’affranchissent des limites de la recherche par simple correspondance de mots.
4. Fonctionnalités d’Extraction et de Résumé de Texte Assistées par l’IA
La performance des outils d’IA générative tend à diminuer lorsqu’ils sont confrontés à des documents très volumineux. Une solution efficace consiste à fragmenter ces documents en sous-ensembles plus courts, centrés sur un thème précis, en extrayant les segments pertinents.
La fonction EXTRACTION / RÉSUMÉ par IA de QDA Miner permet d’effectuer ces extractions sur l’ensemble des cas d’un projet, puis d’enregistrer les résultats dans une nouvelle variable de type document.
Au-delà de l’extraction simple, cette fonctionnalité offre également la possibilité de générer un résumé général du document complet ou un résumé thématique basé sur un sujet défini par l’utilisateur. En ciblant ainsi l’analyse sur des enjeux spécifiques, les segments obtenus peuvent servir de base à des requêtes de suivi plus précises et plus pertinentes — ce qui améliore considérablement la qualité et la pertinence des réponses produites par l’IA générative.
5. Filtrage de tableaux par l’IA
Les résultats de recherche issus de l’ensemble étendu de fonctionnalités de recherche textuelle de QDA Miner peuvent désormais être affinés à l’aide de requêtes en langage naturel. Bien que ces outils de recherche puissants puissent renvoyer un grand nombre de résultats, dont certains peuvent n’être que vaguement liés au sujet, le filtrage de texte basé sur l’IA aide à identifier rapidement les éléments les plus pertinents. Il peut également identifier les résultats non pertinents, ce qui facilite leur exclusion avant d’appliquer un code aux résultats restants Lorsqu’il est utilisé sur des résultats issus d’une recherche par codage, ce filtrage peut aussi servir d’outil de validation, en aidant à détecter d’éventuels faux positifs — c’est-à-dire des extraits qui ne correspondent pas vraiment à l’intention du code appliqué. Les fonctionnalités de recherche suivantes prennent actuellement en charge le filtrage en langage naturel :
• Recherche de texte
• Recherche par mot-clé
• Recherche par section
• Recherche par similarité
• Recherche par date et lieu
• Recherche par codage
6. Requêtes de suivi de l’IA définies par l’utilisateur
Les segments de texte récupérés grâce aux mêmes outils de recherche mentionnés ci-dessus peuvent également servir de base à des requêtes de suivi en langage naturel. Que vous cherchiez à identifier des sous-thèmes ou des sous-codes potentiels, à générer un résumé des résultats, à obtenir des suggestions pour une définition opérationnelle d’un code, ou même à obtenir des stratégies de recherche recommandées ou des lectures pertinentes, QDA Miner 2025 vous permet de poser vos propres questions – directement et intuitivement – en fonction des données que vous avez déjà extraites. Étant donné que ces requêtes sont appliquées à des segments de texte sélectionnés plutôt qu’à des documents complets, elles ont non seulement tendance à produire des résultats plus pertinents, mais réduisent également le temps et les coûts de traitement.
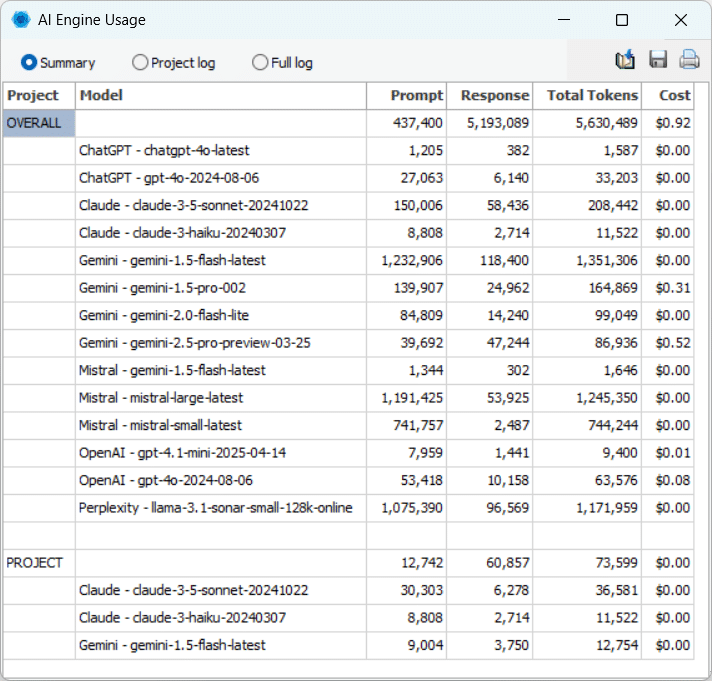
7. Suivi des tokens et estimation en temps réel des coûts d’utilisation de l’IA
Avant d’exécuter une requête, QDA Miner affiche une estimation précise du coût, calculée en fonction du modèle d’IA sélectionné et de la longueur du texte fourni. L’utilisateur peut consulter le nombre estimé de tokens en entrée, ainsi que le coût associé, avec une indication du tarif par million de tokens en sortie (cette dernière ne pouvant être estimée à l’avance). Ce système permet de comparer facilement les performances et les tarifs des différents modèles, d’optimiser ses choix et d’éviter des traitements coûteux, notamment lors de l’analyse de grandes quantités de données ou dans le cadre de traitements par lots. Cela facilite la comparaison entre les performances et les coûts des différents moteurs et modèles, permettant aux utilisateurs de prendre des décisions éclairées et d’éviter les traitements onéreux, notamment lors de l’analyse de grands volumes de données ou dans le cadre de traitements par lots.
Pour accompagner la gestion budgétaire, QDA Miner assure également un suivi cumulatif de l’utilisation des tokens et des coûts, par modèle, moteur et projet. Ce suivi complet permet une allocation plus efficace des ressources, évite les dépassements imprévus et garantit une transparence totale sur les dépenses liées à l’IA.
8. Recherche de similarité de code améliorée
La recherche de similarité de codage de QDA Miner s’appuie sur l’apprentissage automatique supervisé pour identifier des phrases ou des paragraphes similaires à des segments déjà codés — qu’ils proviennent du projet en cours ou d’un projet antérieur entièrement codé. Cet outil permet de repérer des contenus potentiellement oubliés en analysant l’ensemble des documents à la recherche de passages non codés présentant des similitudes avec des codages existants.
Dans QDA Miner 2025, cet outil a été amélioré : il est désormais possible de limiter la recherche aux seuls documents non codés. Cette nouvelle option est particulièrement utile pour la mise à jour de projets en cours, car elle permet d’appliquer des schémas de codage existants à des documents nouvellement ajoutés ou encore non traités, tout en évitant les doublons dans les documents déjà codés.
NOUVEAUTÉS DE LA VERSION 2024
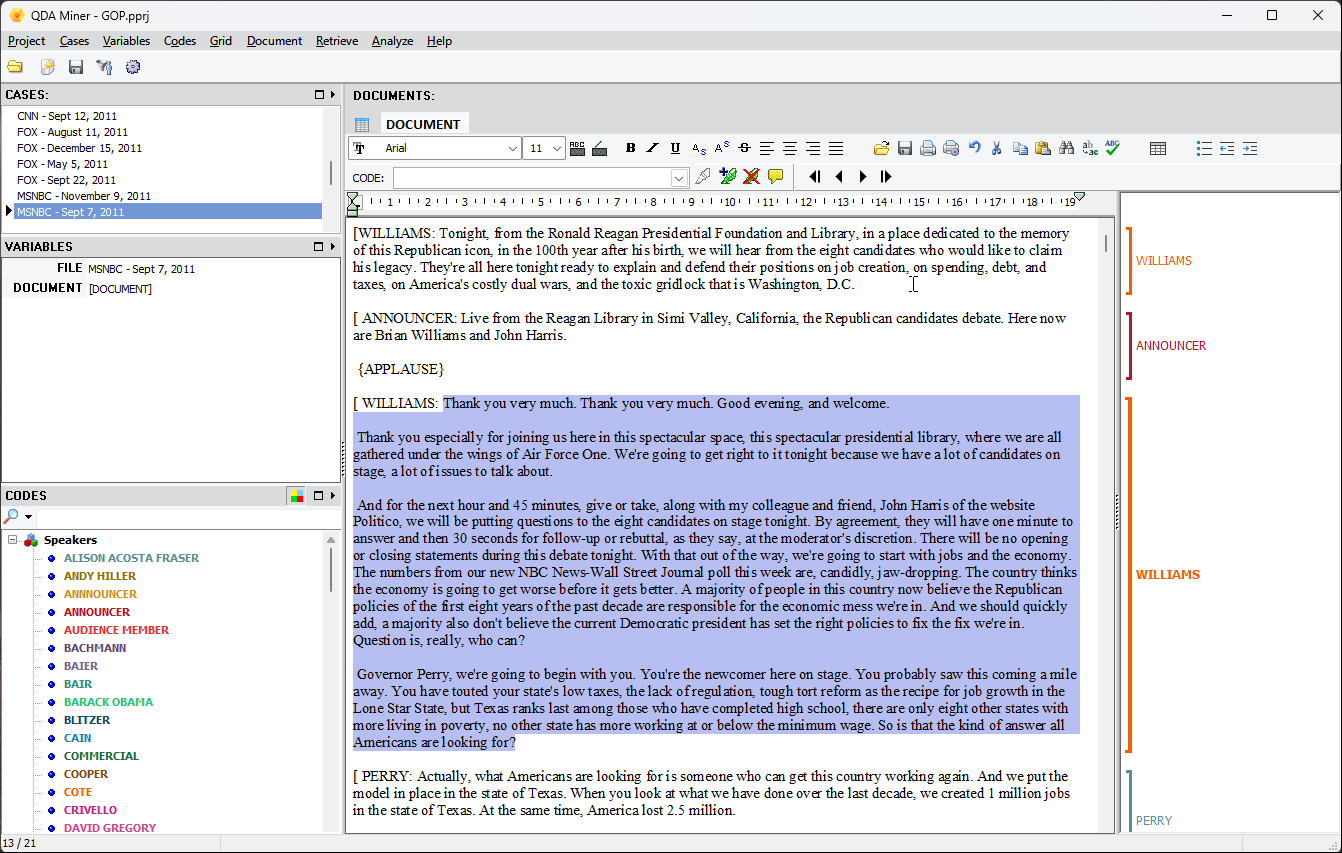
1. Nouvel outil d’extraction des locuteurs et de codage automatique des prises de parole
Un nouvel outil permet d’extraire automatiquement les étiquettes de locuteurs à partir de transcriptions d’entretiens, de groupes de discussion ou de débats, ce qui permet de coder les interventions de tous les participants ou seulement de certains d’entre eux. Le traitement avancé reconnaît les variations courantes dans les noms utilisés pour désigner un même intervenant (phénomène fréquent dans les transcriptions de débats publics) et les regroupe automatiquement. L’utilisateur peut ensuite modifier le nom du code attribué à chaque locuteur, choisir une couleur, ou encore désactiver ou supprimer certaines étiquettes.
Cet outil peut également être utilisé pour repérer automatiquement les éléments répétitifs dans des formulaires ou des rapports structurés, et leur appliquer un codage.

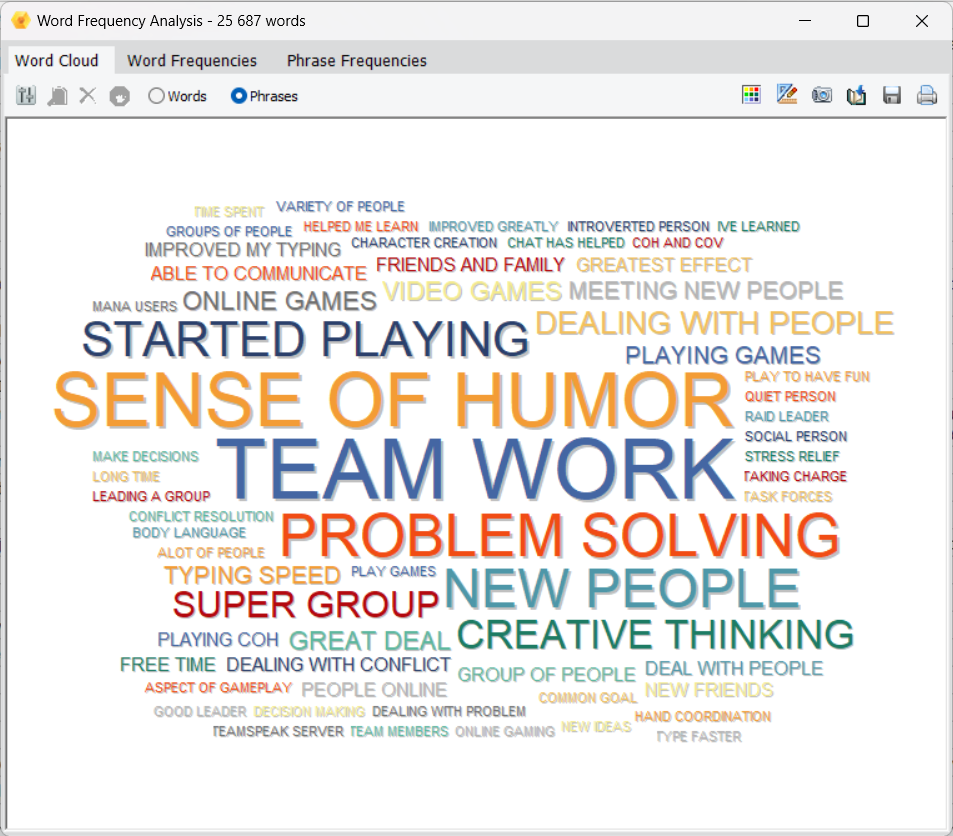
2. Analyse de la fréquence des expressions
Les nuages de mots interactifs et les tableaux de fréquence ont été améliorés pour afficher non seulement les mots les plus fréquents, mais aussi les expressions courantes, ce qui permet de dégager certains thèmes ainsi que des tournures ou formulations typiques.
Cette liste peut être générée à partir de n’importe quelle variable textuelle du projet, ou à partir des résultats d’opérations de recherche (texte, codage, section ou mots-clés)
Il est possible de personnaliser le nuage d’expressions (police, couleur, forme, etc.), de déplacer certaines expressions vers la liste des mots vides, ou encore de lancer des recherches textuelles directement depuis le nuage ou le tableau.
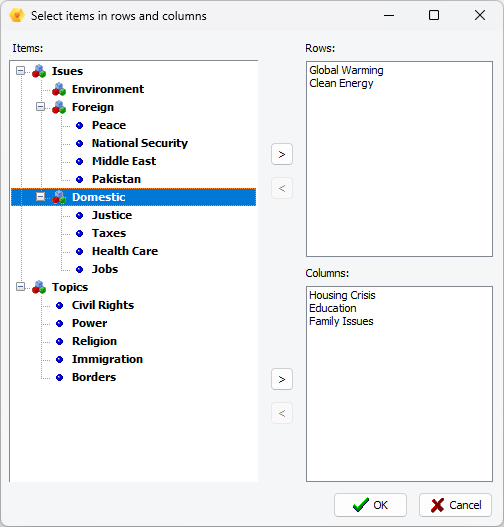
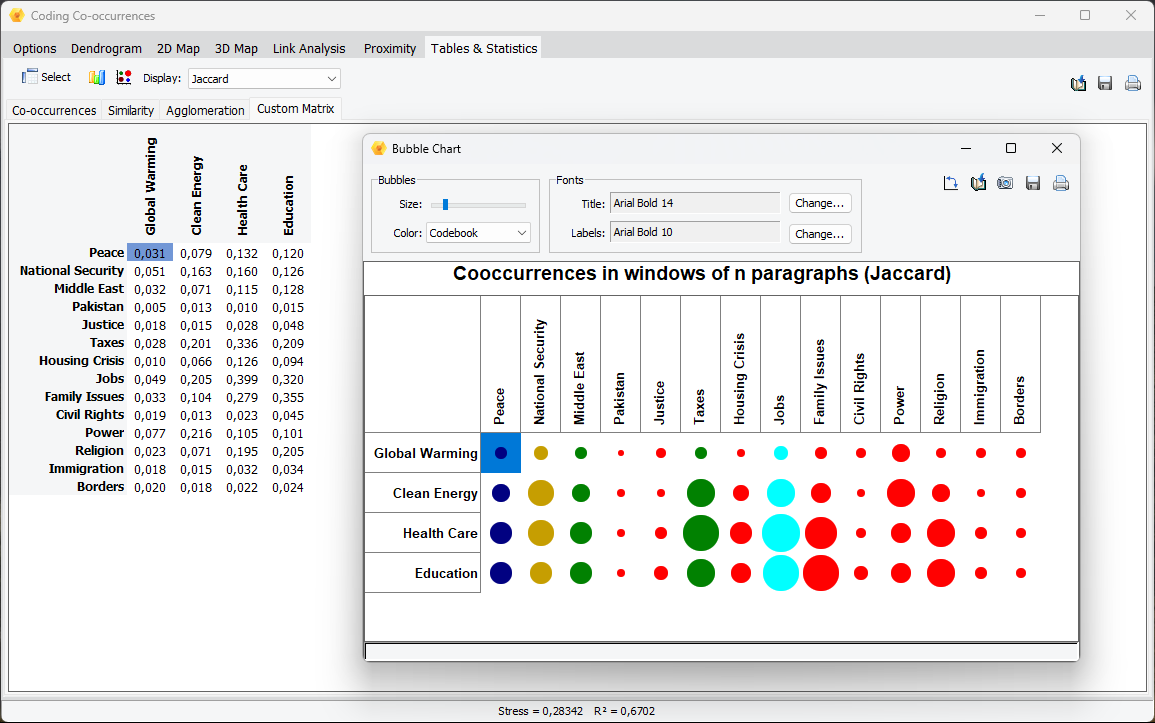
3. Création de matrices et de graphiques de cooccurrences et de similarités personnalisés
Un nouvel ensemble d’options a été ajouté aux boîtes de dialogue Cooccurrence et Similarité de code, permettant de créer des tableaux personnalisés comparant des ensembles de codes ou de cas définis par l’utilisateur. On peut choisir parmi sept statistiques à afficher dans le tableau résultant, puis créer diverses représentations graphiques du tableau obtenu, y compris des diagrammes à bulles, des histogrammes, des graphiques linéaires et des graphiques en aires.
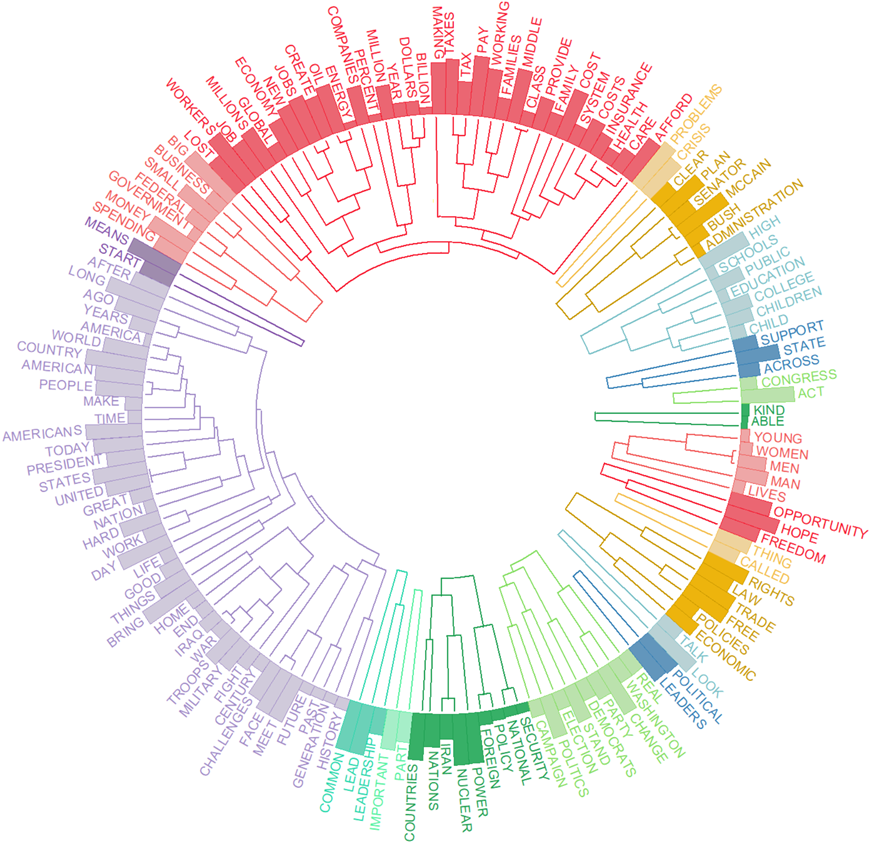
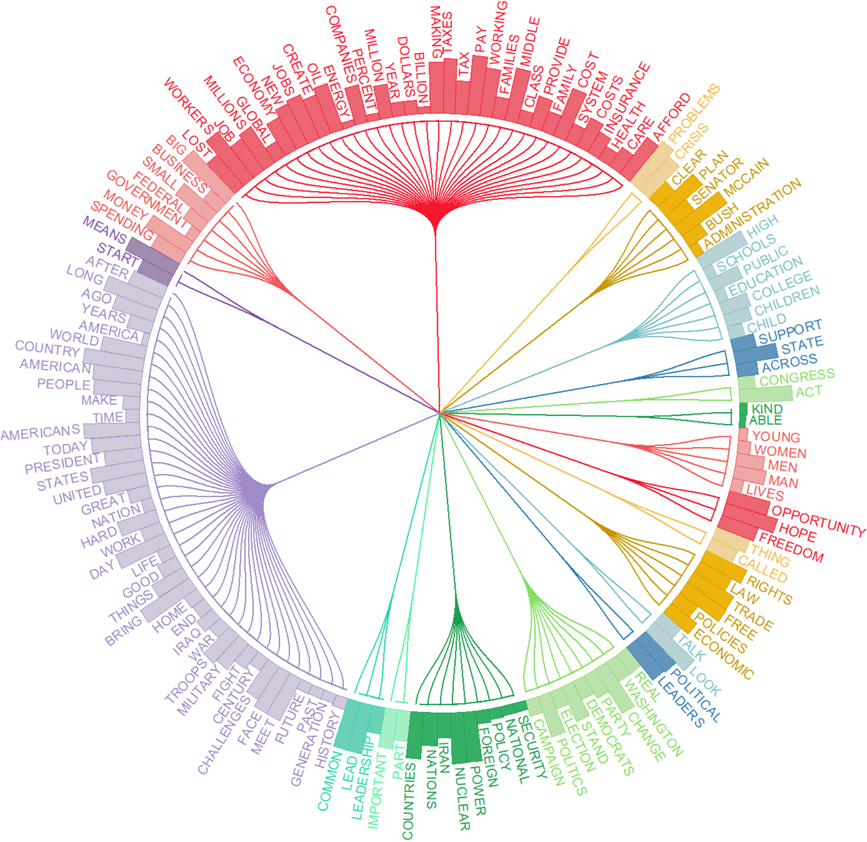
4. Dendrogrammes circulaires
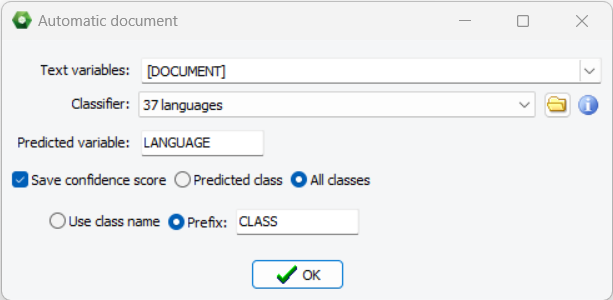
5. Application de modèles de classification automatique de documents aux données du projet
QDA Miner 2024 permet désormais l’application de modèles de classification automatique de documents pour la transformation des données. Cette nouvelle fonctionnalité facilite le stockage des classes prédites dans une variable. Les utilisateurs peuvent également choisir de stocker la probabilité de la classe prédite ou les probabilités de toutes les classes.
6. Copie des données graphiques dans le presse-papiers au format texte
Il est désormais possible d’enregistrer les données utilisées pour la création de divers graphiques dans le presse-papiers au format texte délimité par des tabulations. On peut ensuite coller facilement les données dans une autre application pour générer des tableaux ou des graphiques personnalisés.
7. Nouveau modèle de détection automatique de la langue
QDA Miner 2024 inclut désormais un nouveau modèle de classification pour l’identification de la langue, capable d’identifier avec précision 68 langues. Sa précision mesurée est supérieure à 95 % sur les petits segments de texte (six mots ou moins) et supérieure à 97 % sur les documents plus longs. Le modèle de classification peut être appliqué pour créer une variable de langue dans un projet multilingue, ce qui permet de filtrer et d’analyser les différentes langues séparément.
NOUVEAUTÉS DE LA VERSION 2023
1. Nouveau format de fichier pour une prise en charge Unicode complète
QDA Miner prend désormais en charge le format de fichier .pprj de WordStat, ce qui permet une meilleure prise en charge de toutes les langues humaines. Bien que la version précédente de QDA Miner puisse être utilisée pour analyser du texte dans presque toutes les langues, les variables de chaîne et les codes ne pouvaient être écrits qu’en utilisant des caractères ANSI associés à la page de codes Windows. La version 2023 supprime cette limitation. Lorsqu’un fichier .ppj existant est ouvert, QDA Miner 2023 demandera de convertir le projet actuel au nouveau format. Un nouveau fichier de projet portant le même nom et au même emplacement, mais avec l’extension .pprj, sera créé, en conservant le fichier .ppj original intact. Si nécessaire, il est toujours possible de travailler sur le fichier .ppj précédent ou de l’exporter.
2. Importation des fichiers de projet QDA Miner Lite 3.0
Comme QDA Miner 2023, le logiciel gratuit QDA Miner Lite 3.0 prend désormais entièrement en charge Unicode et stocke les données dans un nouveau format de fichier avec l’extension. qlt. QDA Miner 2023 peut désormais importer ce nouveau format de fichier. qlt ainsi que les fichiers .qdp créés avec les versions 1.x et 2.x de QDA Miner Lite.
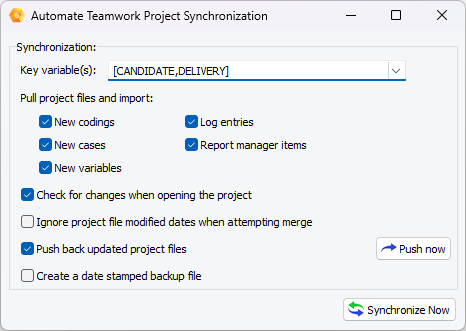
3. Fonction de synchronisation automatique pour le travail d’équipe
Dans les projets qualitatifs de grande envergure, plusieurs codeurs peuvent travailler simultanément sur le même ensemble de données. La fonction de synchronisation automatique permet à l’administrateur du projet de centraliser et automatiser tout le processus : distribution des fichiers aux membres de l’équipe, collecte de leur travail, fusion des contributions, puis renvoi des projets mis à jour — le tout en un seul clic.
4. Nouvelles fonctionnalités de rédaction pour la suppression des informations sensibles
QDA Miner offre deux méthodes pour supprimer les informations confidentielles ou sensibles des textes codés : une méthode destructive et une méthode non destructive. Dans la méthode destructive, le texte à effacer est remplacé par des rectangles noirs. D’autre part, la méthode non destructive consiste à masquer le texte en l’affichant avec une police noire sur un fond noir. Lors de l’utilisation de la méthode non destructive, seul l’affichage dans la fenêtre principale du document est affecté. Aucune information n’est perdue, et les utilisateurs peuvent facilement visualiser le texte caché en le sélectionnant dans la fenêtre du document. Le texte rédigé reste également visible lorsqu’il est récupéré à partir de n’importe quelle fonction de recherche de QDA Miner, ce qui permet aux utilisateurs de voir le texte intégral. La méthode non destructive est particulièrement utile lors de l’impression de copies papier de documents contenant des informations sensibles noircies.
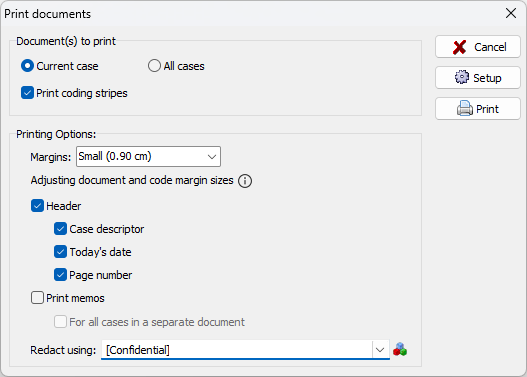
5. Impression de documents avec marques de code et mémos
Dans certaines situations, il peut être nécessaire de produire une copie imprimée de documents avec les codages et les mémos existants, par exemple lorsqu’il faut inclure des documents codés dans un rapport ou faire réviser le codage par un autre membre de l’équipe. QDA Miner 2023 permet d’imprimer soit le document actuel, soit tous les documents avec des options pour définir différentes tailles de marges, rédiger certains segments de texte, définir un en-tête avec le descripteur de cas, la date actuelle et les numéros de page, et imprimer les mémos soit à la fin du document, soit, lors de l’impression de tous les documents, sur des pages séparées.
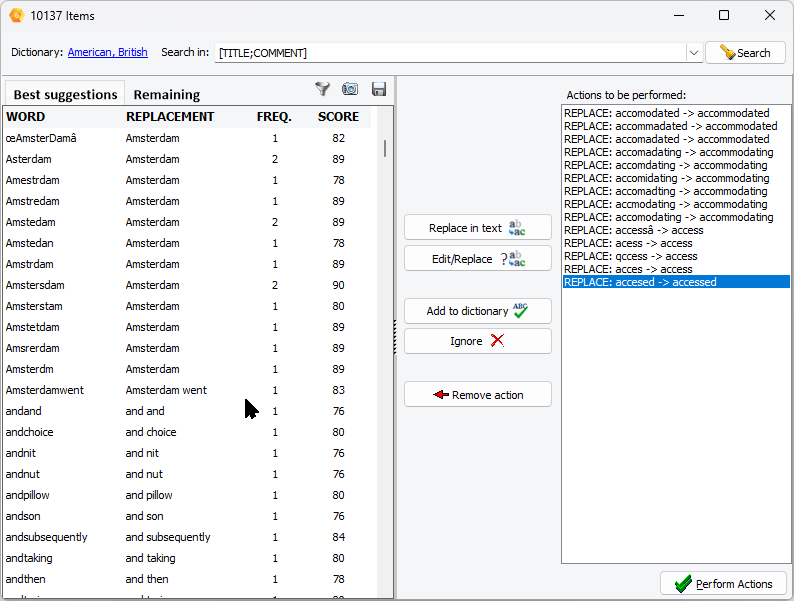
6. Correction orthographique semi-automatique rapide
QDA Miner offre désormais un moyen très efficace d’identifier et de corriger tous les mots mal orthographiés d’un projet. Ce processus semi-automatique parcourra tous les documents des projets et identifiera tous les mots qui ne figurent pas dans le dictionnaire orthographique sélectionné. Il proposera également automatiquement des remplacements suggérés pour la plupart des mots, en tenant compte non seulement de la similarité avec un mot connu, mais aussi de sa présence et de sa fréquence dans le corpus analysé. Il tentera même de suggérer des corrections orthographiques pour les mots qui ne figurent pas dans le dictionnaire orthographique, tels que les noms propres, les termes techniques ou les néologismes.
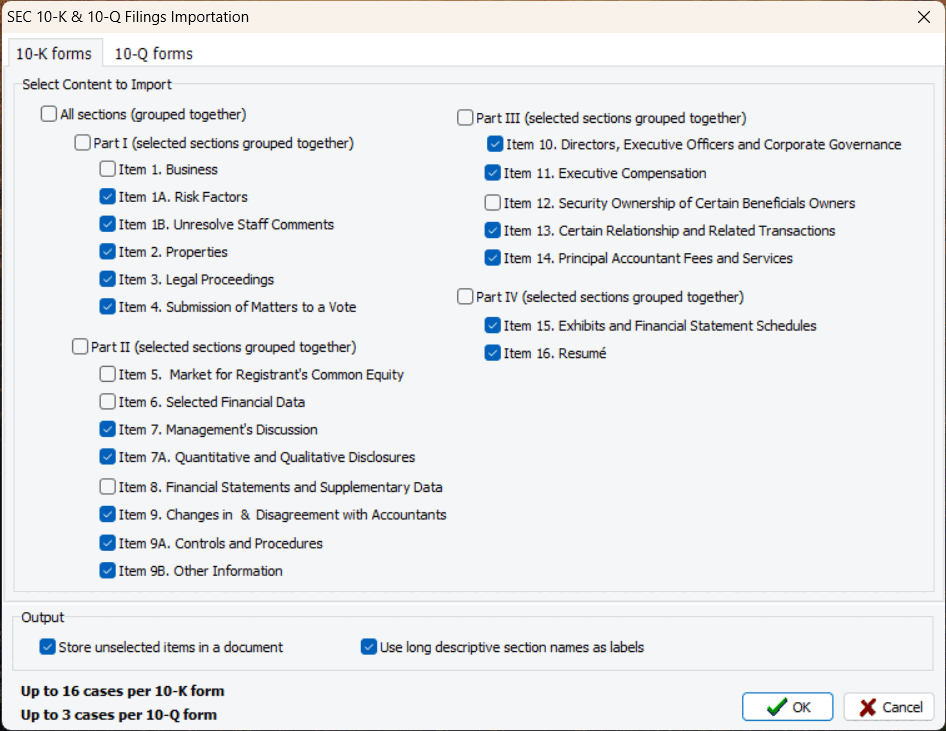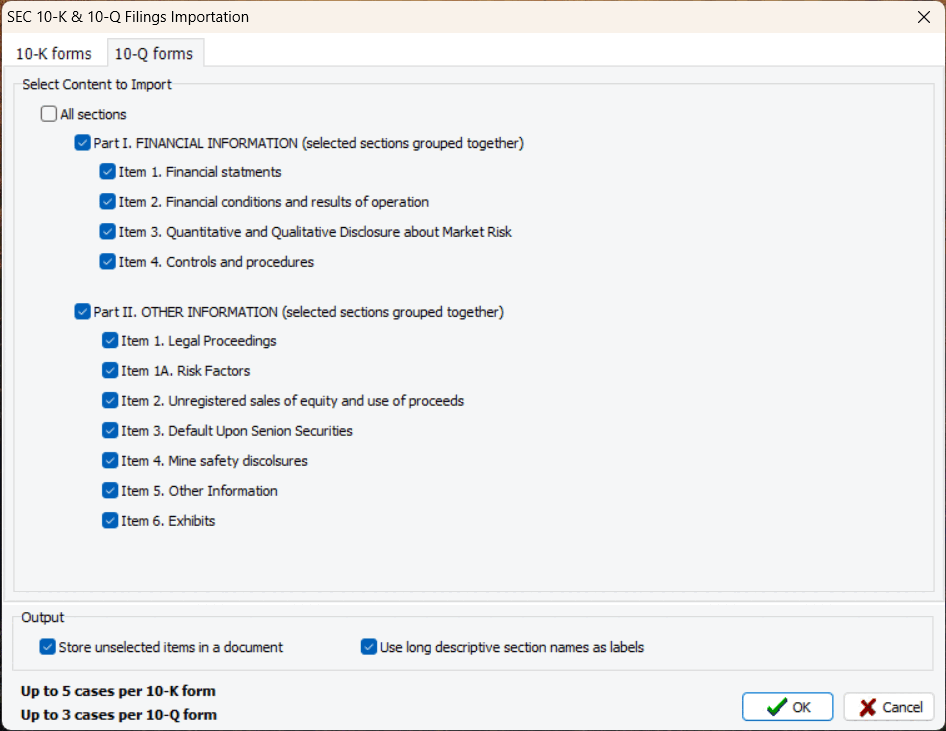
7. Importation des documents financiers 10-K et 10-Q
Une nouvelle routine d’importation permet aux utilisateurs d’importer des sections spécifiques des documents financiers 10-K et 10-Q, et de les stocker séparément ou de les fusionner en un seul document. La routine d’extraction reconnaît automatiquement le nom de l’entreprise, la période (trimestre et année) et les stocke comme variables pour une analyse facile.
8. Exportation des résultats d’analyse qualitative vers Power BI
QDA Miner offre désormais une intégration transparente avec Microsoft Power BI, permettant aux utilisateurs d’exporter les résultats d’analyse textuelle et les métadonnées vers Power BI Desktop pour des tableaux de bord et des rapports interactifs. En exportant les résultats d’analyse qualitative et les métadonnées vers Power BI Desktop, les utilisateurs peuvent créer des visualisations attrayantes, obtenir des informations plus approfondies à partir de leurs données et partager facilement leurs conclusions avec d’autres.

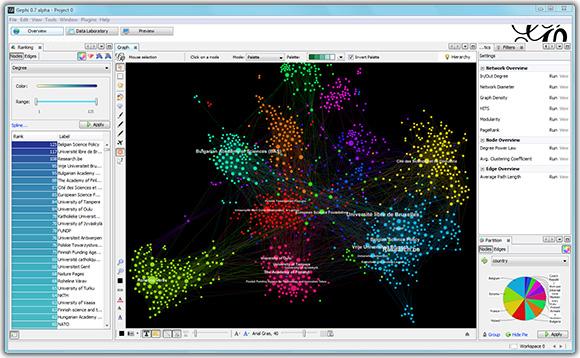
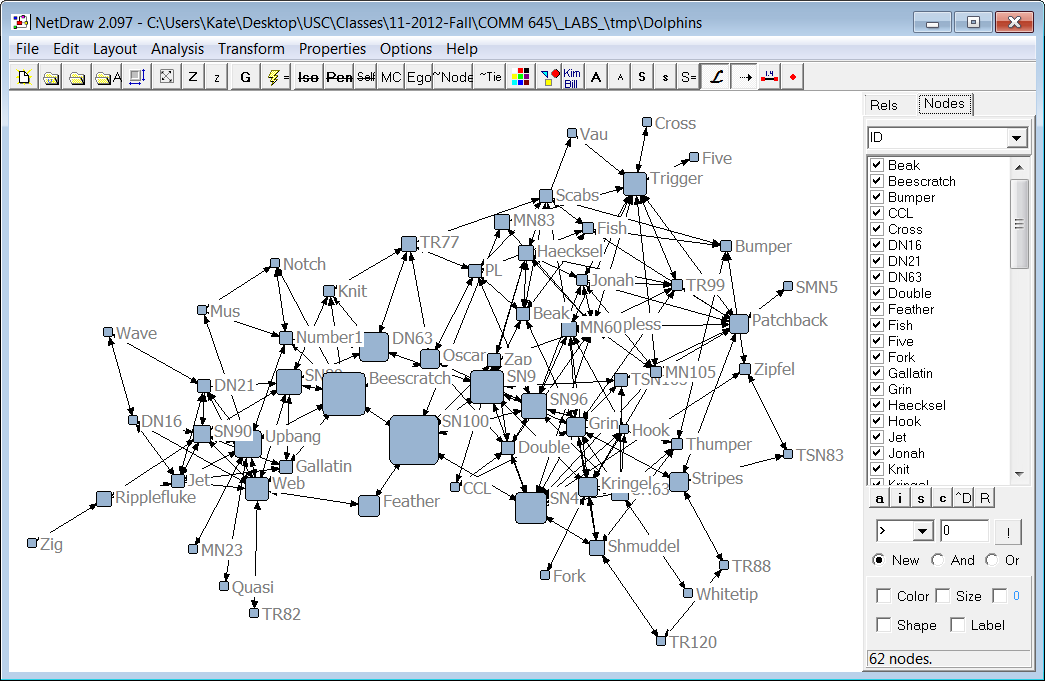
9. Transfert des données de cooccurrence vers Gephi ou NetDraw
Grâce à la nouvelle option disponible depuis la page Dendrogramme, les utilisateurs peuvent désormais exporter les données de cooccurrence, ainsi que des informations supplémentaires telles que la fréquence et le numéro de cluster, vers des logiciels d’analyse de réseaux sociaux comme Gephi et NetDraw. Ces outils offrent de puissantes visualisations qui aident les utilisateurs à identifier les motifs et les relations au sein de leurs données. Gephi propose des algorithmes de mise en page et des fonctionnalités interactives pour l’exploration en temps réel, tandis que NetDraw offre des options de visualisation pour les graphes de réseaux.
10. Palettes de couleurs personnalisées pour les graphiques
QDA Miner 2023 introduit une nouvelle fonctionnalité qui permet aux utilisateurs de créer des palettes de couleurs personnalisées. Cette fonctionnalité offre un meilleur contrôle sur les couleurs utilisées pour les graphiques, les nuages de mots, le clustering et autres visualisations, permettant aux utilisateurs de personnaliser leur sortie en fonction de leurs besoins spécifiques.
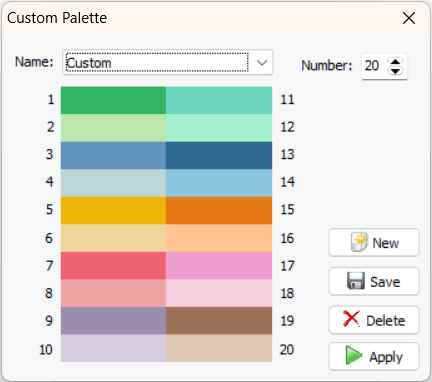
11. Paramètres d’extraction de clusters améliorés
Des boutons peuvent désormais être utilisés pour resserrer ou relâcher les critères utilisés pour le regroupement, ce qui entraîne un regroupement de moins ou de plus d’éléments.
12. Boîte de dialogue améliorée pour l’extraction des codages
La fonction d’extraction des codages comprend désormais des boutons permettant d’ajouter un mémo à un segment codé, de modifier ou supprimer ce mémo, ainsi que de changer ou retirer le code associé à un passage de texte.
13. Boîte de dialogue améliorée pour l’extraction des mémos
La boîte de dialogue d’extraction des mémos propose désormais des boutons pour ajouter un mémo à un segment codé, le modifier ou le supprimer, ainsi que pour changer ou retirer le code associé à un passage de texte.
NOUVEAUTÉS DE LA VERSION 6.0 DE QDA MINER
1. Nouvelle visualisation en tableau pour la codification des réponses courtes
Bien qu’elle soit idéale pour la codification de longs documents, la fenêtre de visualisation standard du QDA Miner, centrée sur le document, était moins bien adaptée à la codification de courts segments de texte, comme les réponses aux questions ouvertes ou les brefs commentaires. QDA Miner 6 offre un nouveau mode de visualisation sous forme de grille ou de tableau qui constitue un moyen pratique et très efficace de codifier ce type de données textuelles. Elle inclut des fonctionnalités telles que :
- Codage et annotation par glisser-déposer.
- Filtrage des réponses à l’aide d’expressions de recherche textuelle avec opérateurs booléens
- Filtrage des réponses en fonction du nombre de codes (codés, non codés, plus de n codes, etc.) ainsi que de la présence ou de l’absence de codes spécifiques
- Possibilité de trier les réponses par ordre alphabétique, par la longueur du texte, le nombre de codes ou le numéro de cas.
- Affichage du nombre et le pourcentage de réponses codées,
- Permet de générer un nuage et une analyse de la fréquence de mots sur le contenu de la grille de codification.
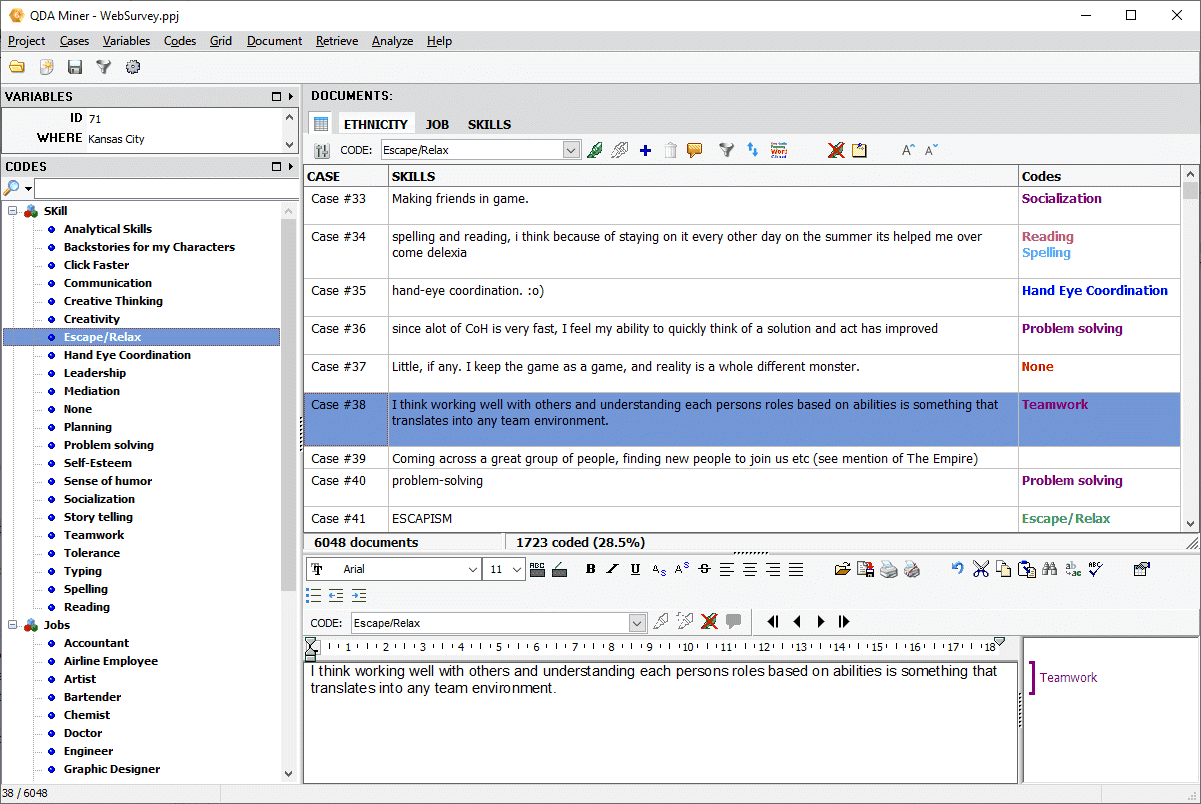
2. Matrices de citations
La matrice de citation vous permet de créer une grande table contenant tous les segments de texte codé et/ou les commentaires où chaque case représente l’intersection d’un code spécifique avec soit un cas spécifique, soit la valeur d’une variable catégorielle ou numérique (groupe d’âge, sexe, source, etc.). Ce type d’affichage combiné offre une visualisation synthétique du corpus codé idéale pour passer en revue le travail effectué par les codeurs, repérer facilement les schémas, créer des récapitulatifs clairs des résultats, etc. Cette matrice peut être créée à partir de la nouvelle commande MATRICE DE CITATIONS pour obtenir une matrice d’extraits de textes sous format codes x cas. Elle peut également être créée à partir de la commande CODAGE PAR VARIABLES pour afficher les éléments codés par toutes les valeurs d’une variable. Elle dispose des fonctionnalités suivantes :
- Affiche soit la totalité des commentaires, soit des commentaires ciblés.
- Le texte de chaque cellule peut être modifié avec un éditeur de texte permettant d’ajuster la police de caractère, la taille et couleur du texte, de formater les paragraphes, etc.)
- Les annotations de type mémo peuvent être jointes à des cellules de texte
- Les lignes et les colonnes peuvent être transposées.
- La matrice peut être exportée sur disque dans de nombreux formats, dont Excel, CSV, TSV et un nouveau format PGRD permettant de réviser et d’éditer le tableau en dehors de QDA Miner à l’aide d’un visionneur/éditeur de matrice disponible gratuitement.
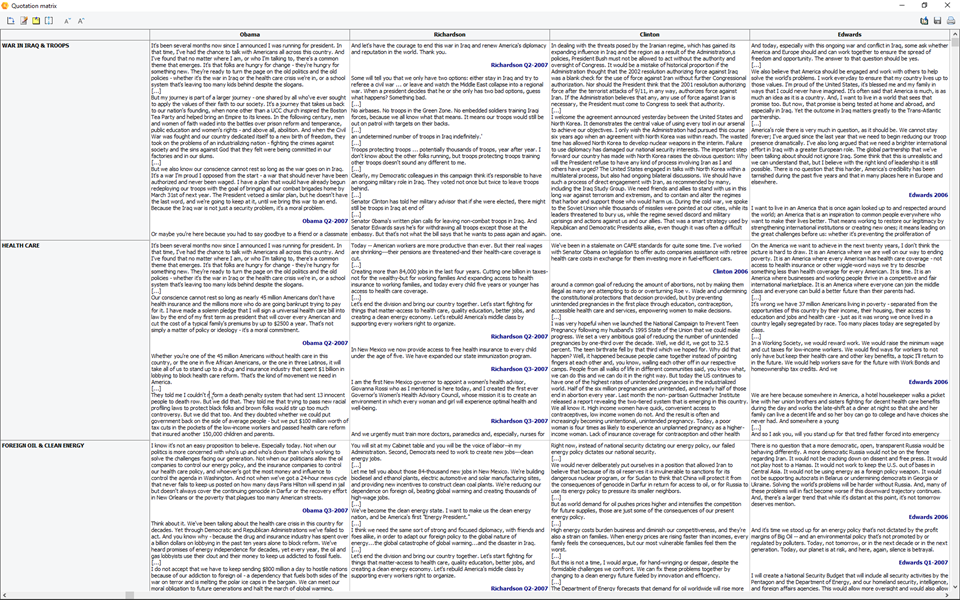
3. Fonction d’annotation plus flexible
Vous pouvez désormais joindre jusqu’à six types de commentaires à un seul code. Les annotations peuvent servir à différentes fins telles que la formulation d’une hypothèse, la communication de points critiques aux membres de l’équipe, le résumé, etc. Vous ne serez plus limité à un seul type de commentaire. La suppression de cette contrainte et l’introduction de la matrice de citation (voir ci-dessus) offrent de nouvelles possibilités pour générer une visualisation synthétique des récapitulatifs, des points critiques, des hypothèses, etc. Cela vous offre une plus grande flexibilité sur la façon d’instruire, d’expliquer les codes, de poser et de répondre aux questions.
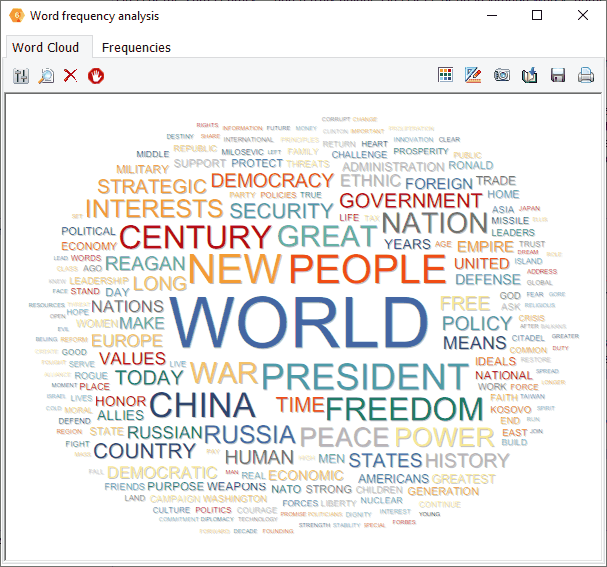
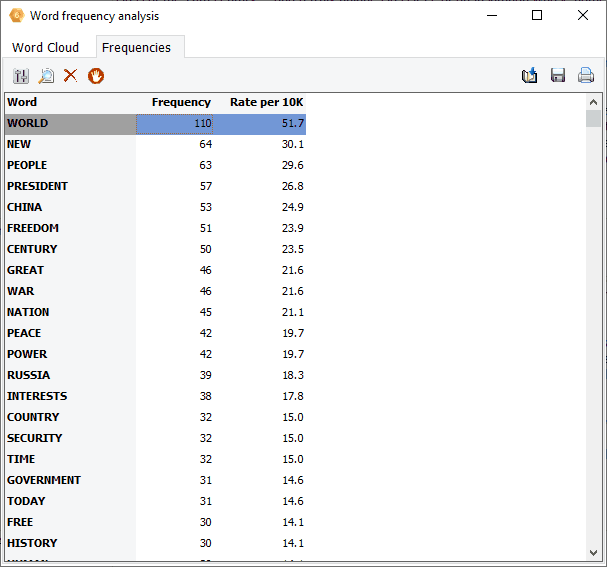
4. Analyse de fréquence de mots et le nuage de mots
Des nuages de mots interactifs et des tableaux de fréquence des mots peuvent désormais être obtenus sur toute variable de type document ou sur les résultats des opérations de recherche (recherche de texte, de codage, de section ou de mot-clé) que ce soit pour un seul document ou pour le texte affiché dans nouvelle la grille de codage. Le nuage de mot peut être personnalisé (police, couleur, forme, etc.). On peut également définir une liste de mots vides et effectuer des recherches de texte à partir du nuage lui-même ou du tableau associé.
5. Importation de fichiers Nexis UNI et Factiva
L’importation des articles de journaux, transcriptions de nouvelles télévisées, des brevets et documents juridiques à partir des fichiers LexisNexis Nexis et Factiva est désormais possible. Après avoir sélectionné un ou plusieurs fichiers .DOCX obtenus auprès de ces services, QDA Miner extraira et stockera sous forme de différentes variables le titre et le contenu de la transcription, sa source, la date de publication ainsi que d’autres informations pertinentes.

6. Importation optimisée des fichiers Excel, CSV et TSV
Lors de l’importation de fichiers à partir de fichiers Excel, CSV ou TSV, une boîte de dialogue vous offre la possibilité de sélectionner des variables, d’importer des descriptions supplémentaires de variables et d’effectuer des conversions de variables en simultané.
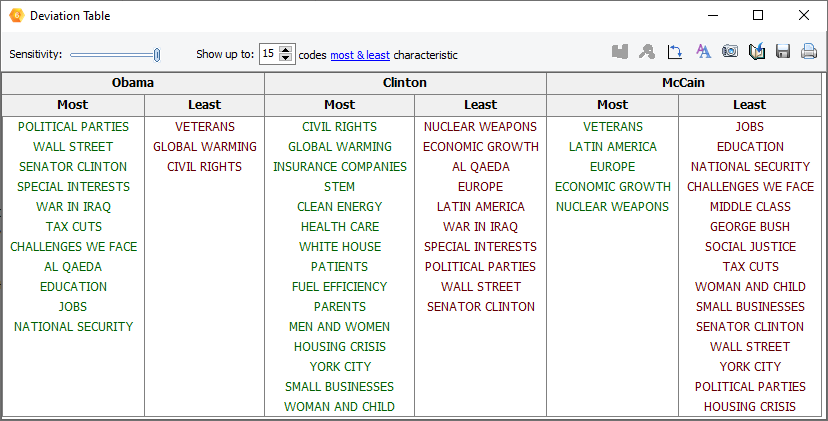
7. Table de déviations
La fonction CODAGE PAR VARIABLES offre désormais la possibilité de produire un tableau de déviations pour obtenir une vue synthétique des codes les plus et les moins caractéristiques des différentes valeurs d’une variable indépendante par rapport aux autres classes de cette variable.
8. Exportation des résultats vers le logiciel Tableau
D’un simple clic de souris, vous pouvez désormais exporter vos résultats vers le logiciel Tableau afin de profiter de ses outils interactifs avancés de visualisation. Cette option est accessible à partir de la commande FRÉQUENCE DE CODAGE et de la commande CODAGE PAR VARIABLE.

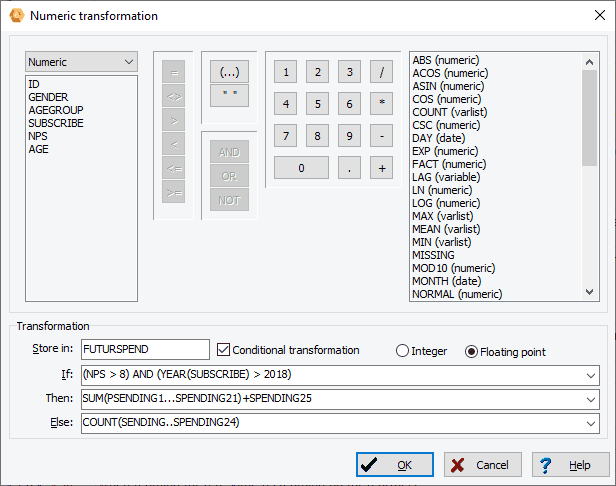
9. Transformation numérique
Une nouvelle boîte de dialogue de transformation numérique vous permet de calculer des variables numériques à partir d’autres variables avec jusqu’à 50 fonctions de transformation, y compris des fonctions trigonométriques, statistiques et de nombres aléatoires. La transformation conditionnelle peut également être effectuée à l’aide d’une structure logique SI-ALORS-SINON.
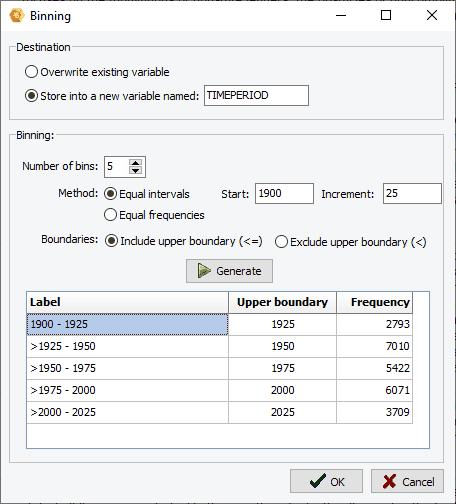
10. Regroupement de variables numériques par classe « Binning »
Une fonction de regroupement permet désormais de transformer les valeurs continues en un plus petit nombre de classes bien définies. Elle peut être utilisée pour réduire les effets de valeurs numériques aberrantes, de distributions anormales, ou pour convertir les valeurs d’une variable numérique continue en classes ordinales. Elle est particulièrement intéressante pour créer des représentations graphiques comparatives lorsque la variable numérique comporte un nombre trop élevé de valeurs distinctes.
11. Prise en charge des valeurs manquantes
Vous pouvez désormais associer aux variables numériques, catégorielles et courtes chaînes de caractères jusqu’à trois valeurs qui seront traitées comme des données manquantes.
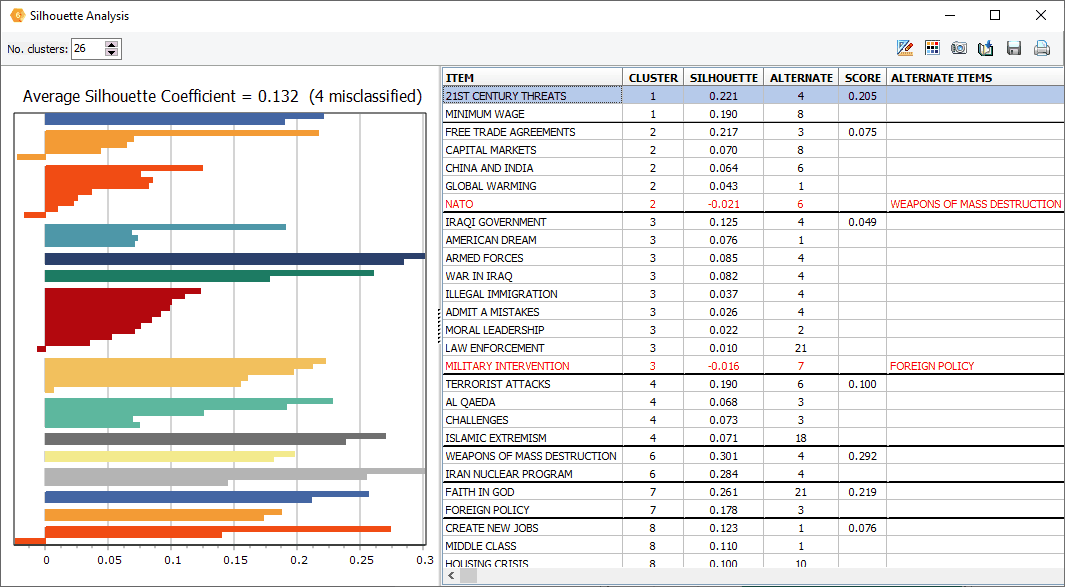
12. Tracé de silhouette
Une nouvelle fonction d’analyse de silhouette a été ajoutée à l’analyse hiérarchique des grappes, permettant d’évaluer la qualité de la partition de chaque cluster et d’identifier les éventuels éléments incorrectement classifiés.
13. Transformation des variables dates
Les variables de type dates et dates et heures peuvent désormais être utilisées pour créer d’autres variables catégorielles ou numériques telles que les jours du mois ou de la semaine, les mois, les années, etc.
![]()
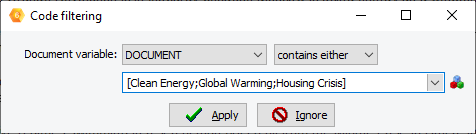
14. Optimisation de la procédure de filtrage des codes
La fonction de filtrage par code peut désormais être utilisée pour filtrer les Cas en fonction de la présence, de l’absence de codes spécifiques ou de différentes combinaisons de codes.
15. Graphique en anneau, aires, radar et barres empilées 100%
Un graphique en anneau (ou beignet) peut maintenant être utilisé pour afficher des codes relatifs (menu FRÉQUENCE DE CODAGE) ou des fréquences de classe (menu VARIABLES | STATISTIQUES). La boîte de dialogue CODAGE PAR VARIABLES ajoute également la possibilité de créer un graphique en radar, un diagramme à barres empilées 100% ainsi que deux types de graphiques en aires (empilés et empilés 100%).
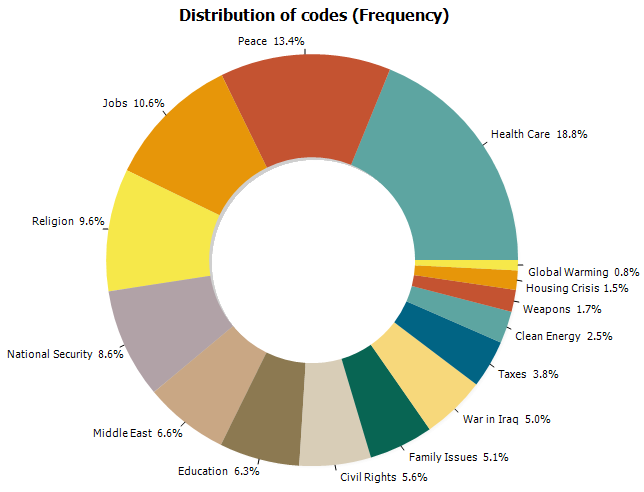
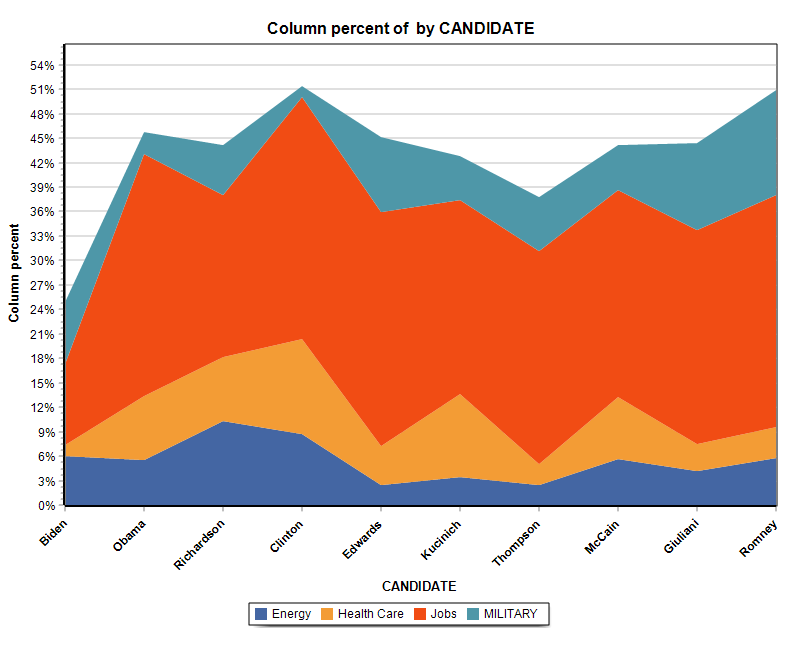
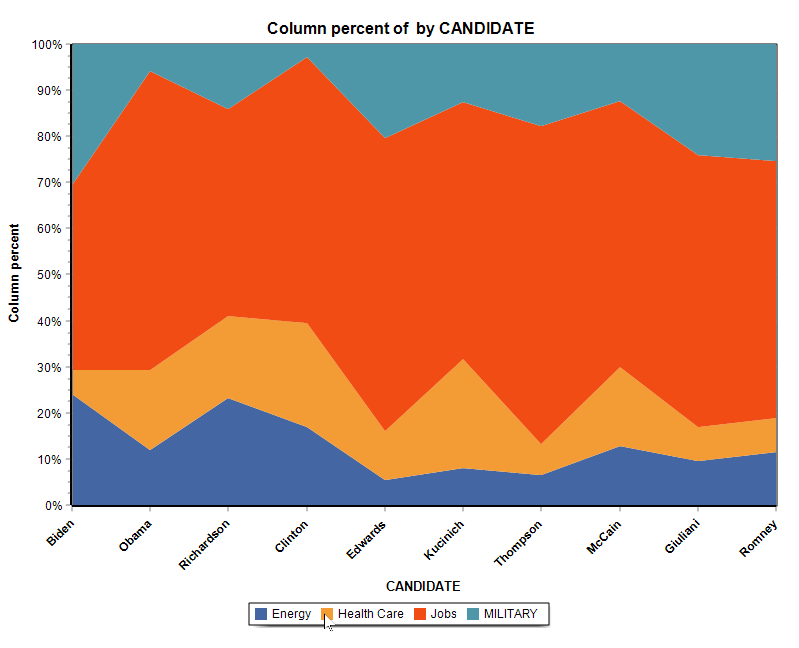
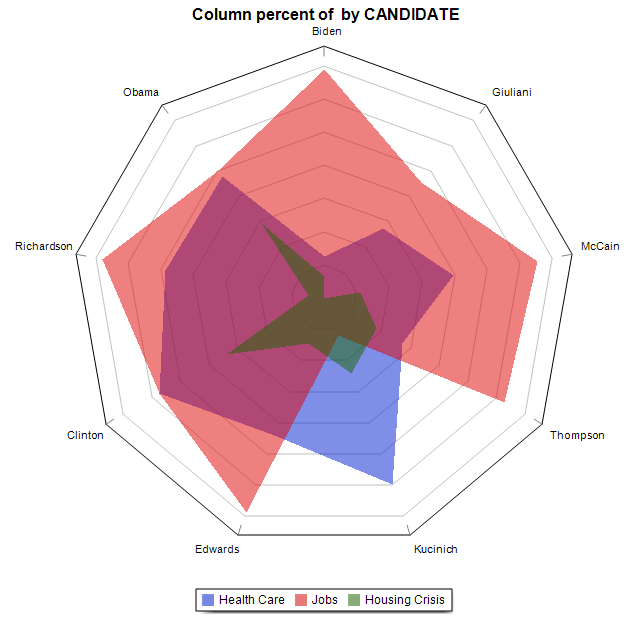
16. Déplacement des séries dans les diagrammes de comparaison
La position relative d’une série dans un diagramme de comparaison (à barre, en aires, etc.) généré à partir de la boîte de dialogue CODAGE PAR VARIABLES peut maintenant être ajustée manuellement, ce qui permet d’obtenir des visualisations plus attrayantes ou plus révélatrices.
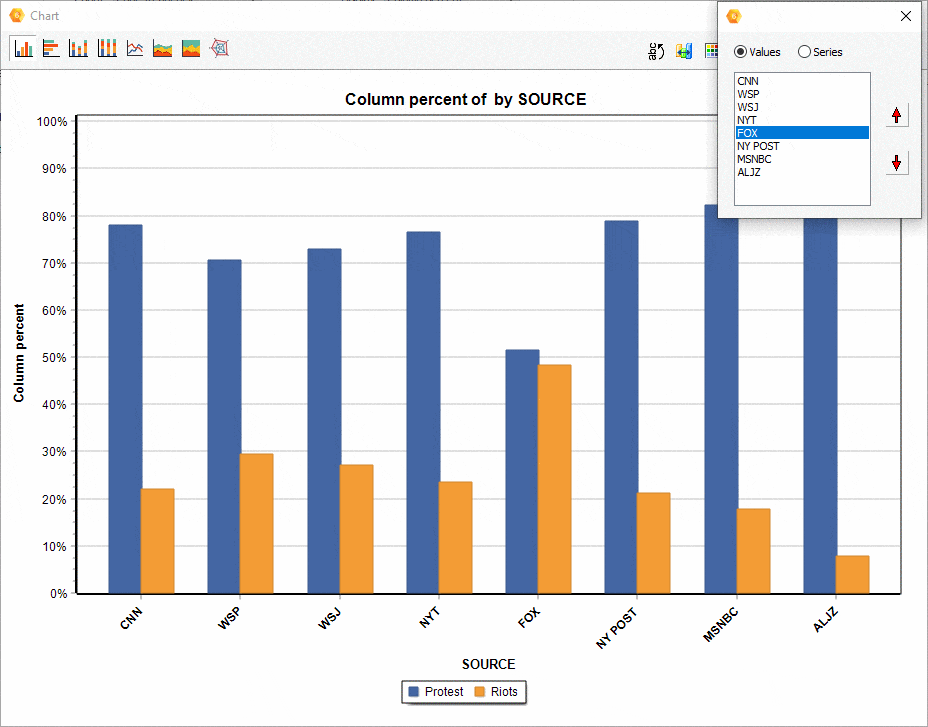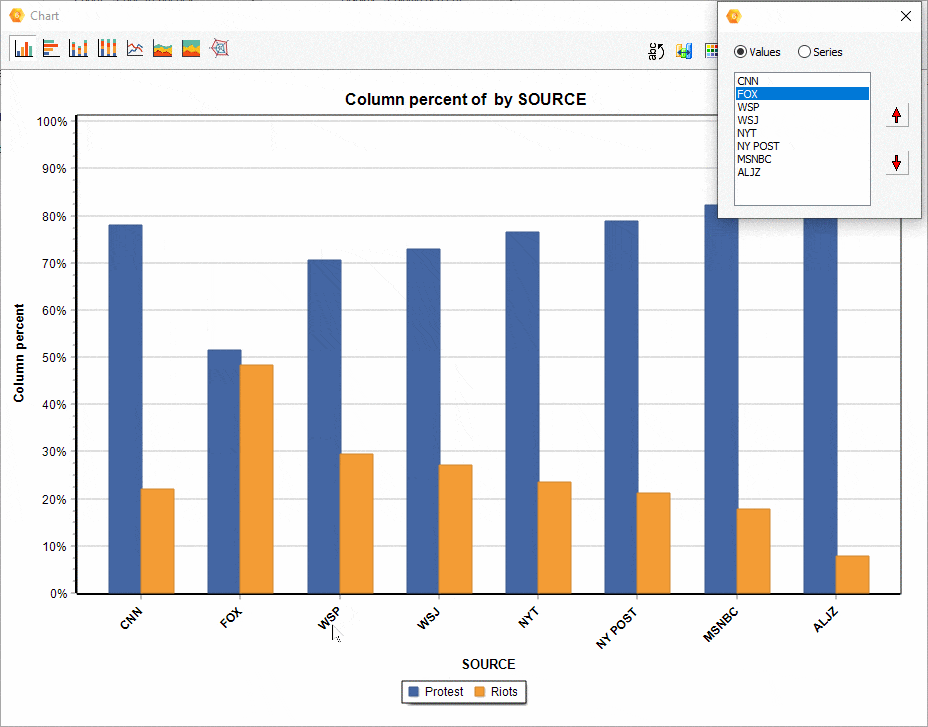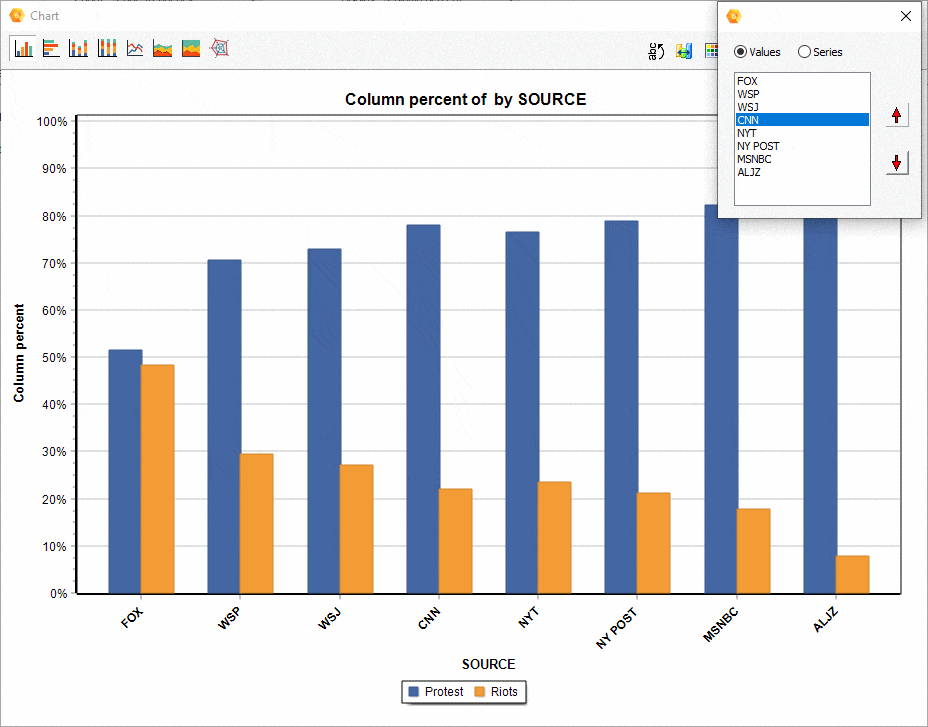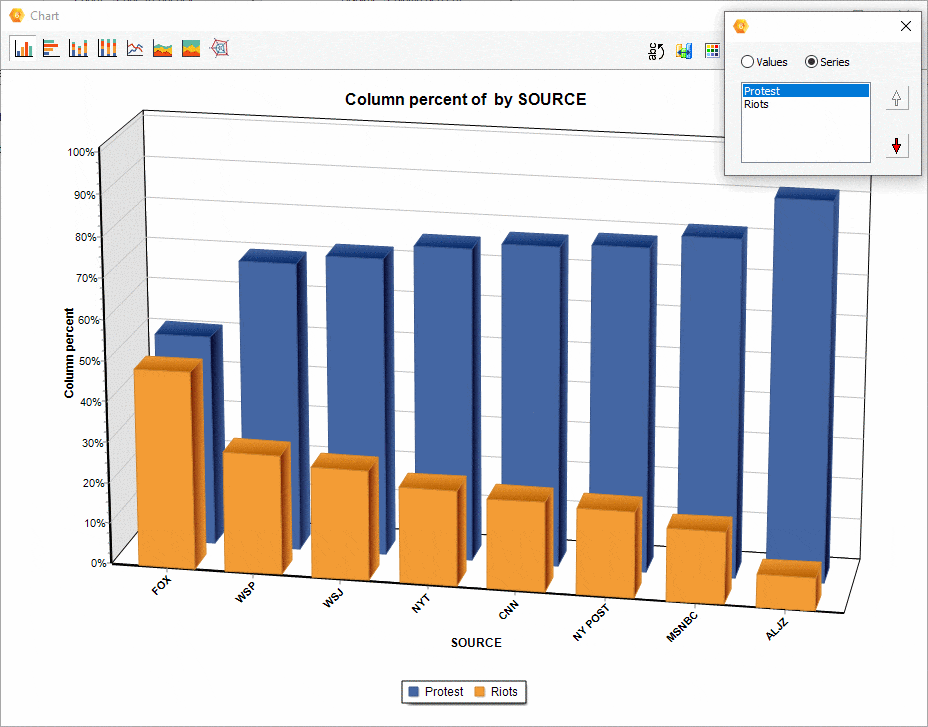
17. Attribution de code de couleurs aux items du graphe de correspondance
La position de mots spécifiques ou de classes de variables sur la troisième dimension (la profondeur) peuvent maintenant être représenté par un gradient de couleur, aussi bien sur le graphe de correspondance en 2D que 3D. Jusqu’à quatre couleurs peuvent être choisies pour créer ces gradients.

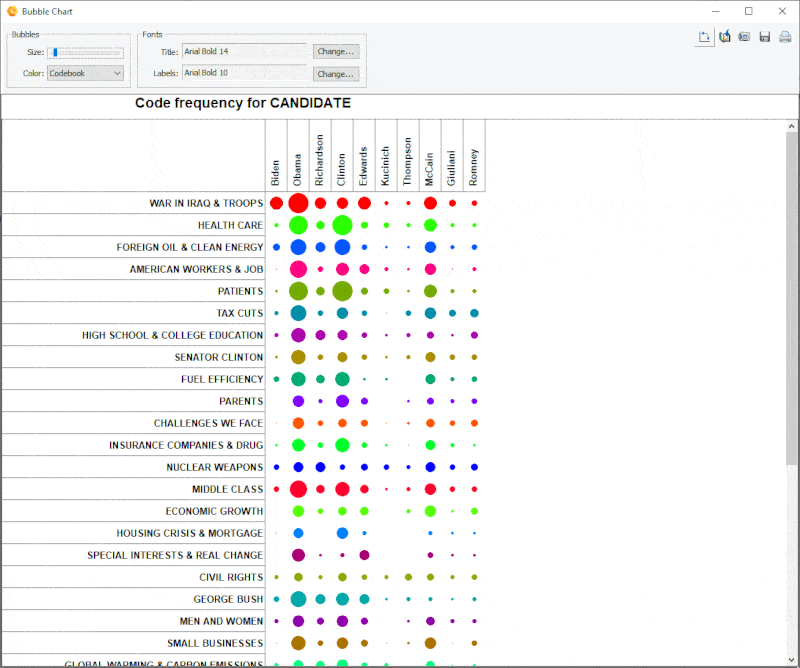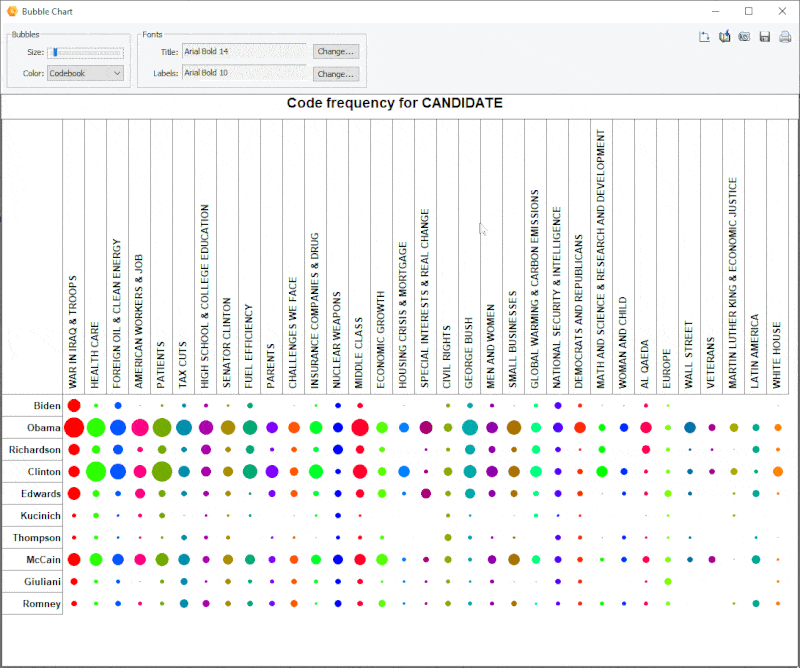
18. Diagramme à bulles amélioré
Il est désormais possible de transposer les lignes et les colonnes des diagrammes à bulles et d’ajuster avec précision la taille des bulles.
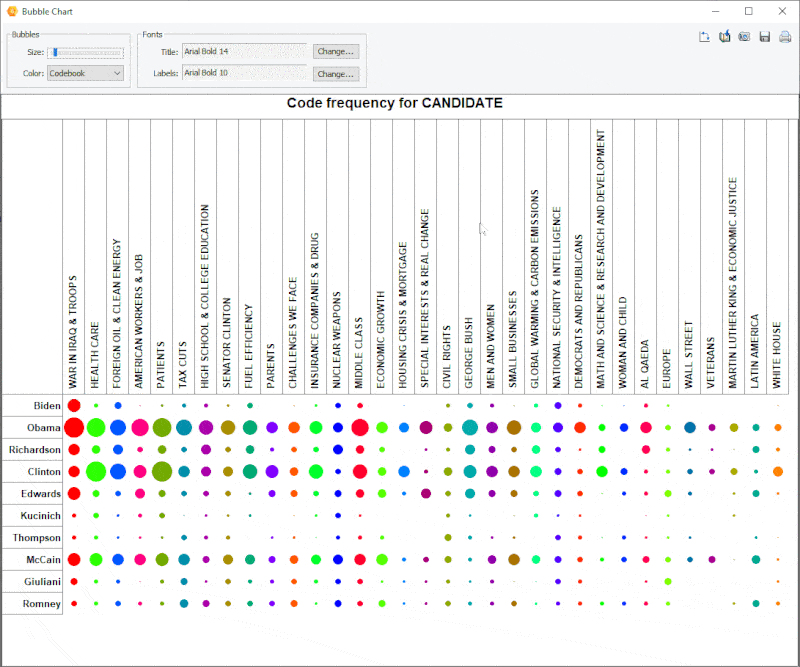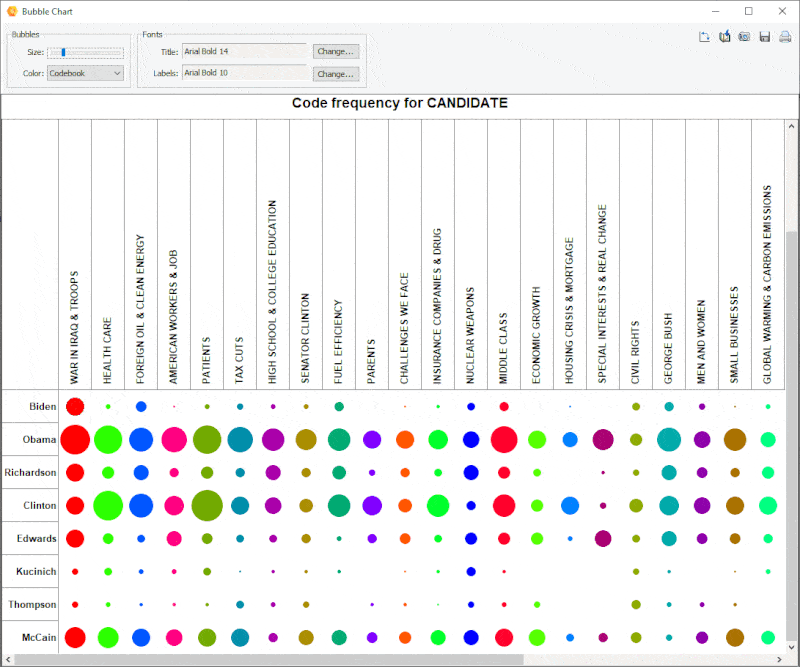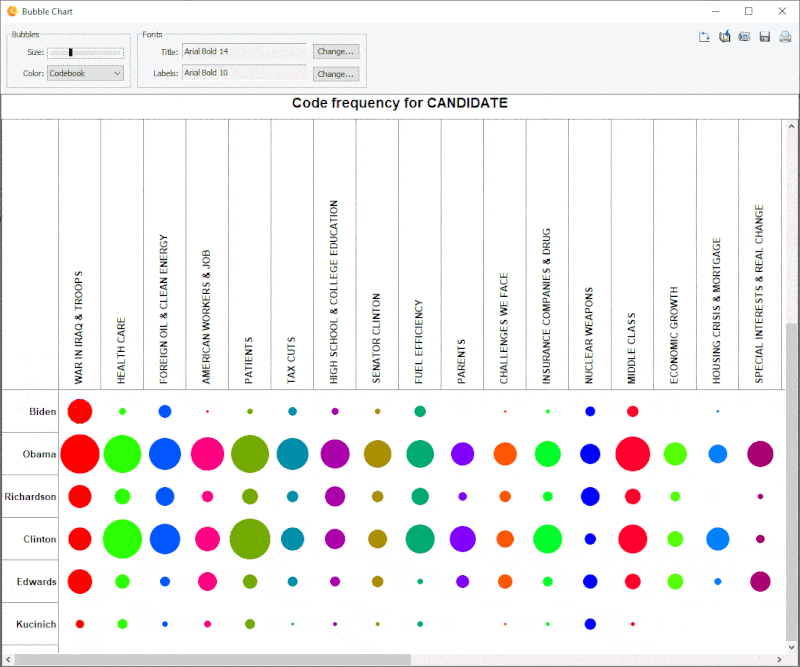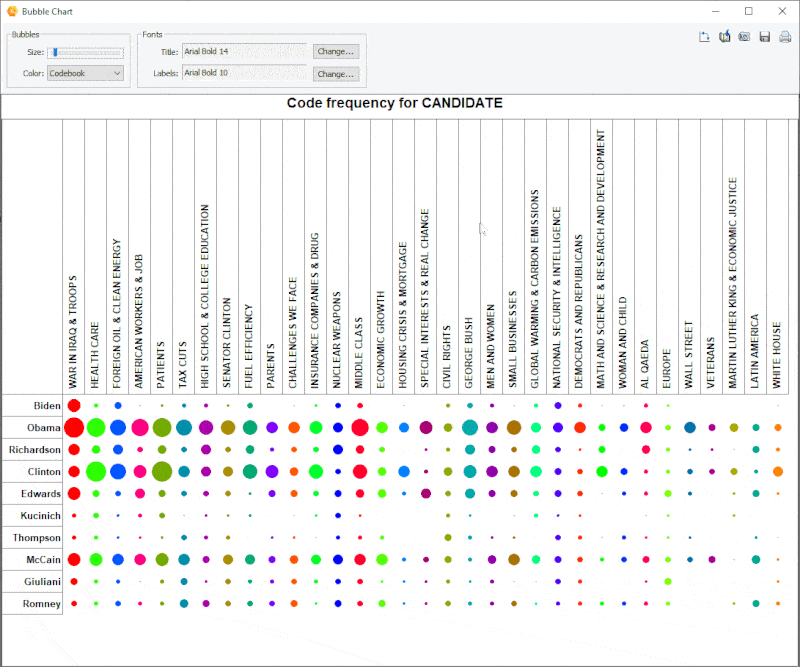
19. Option annuler/refaire de l’analyse des liens
Un mémoire tampon vous permet de revenir à la configuration d’analyse des liens précédente et ensuite de poursuivre.
20. Nouveau format tableau et nouvel éditeur de tableau
Un nouveau format exclusif de tableaux (*.pgrd) a été ajouté pour l’exportation des tableaux sur disque, ce qui permet de modifier et d’annoter facilement les tableaux produits par QDA Miner. Un utilitaire pour visualiser ces tableaux peut également être téléchargé gratuitement sur notre site web, permettant à quiconque de visualiser, d’éditer et d’annoter les tableaux sauvegardés.
21. De nombreuses améliorations notables au niveau des boîtes de dialogue
Plusieurs nouvelles options et des améliorations au niveau de l’interface ont été apportées aux boîtes de dialogue existantes (sélection de la couleur du code, options graphiques, etc.), ainsi qu’aux fonctions de gestion et d’analyse.
Cliquez sur le lien suivant pour connaître les nouvelles fonctionnalités de la version 5