
LES NOUVELLES FONCTIONNALITÉS DE WORDSTAT
Quelles sont les nouveautés de la version 9.0 ?
1. Support complet d’Unicode
Nous essayons toujours de privilégier les techniques d’analyse de texte indépendantes de la langue. Cela a permis aux utilisateurs d’analyser des données textuelles dans plus de 50 langues. Toutefois, pour analyser des langues non prises en charge par leur installation Windows par défaut, l’utilisateur devait modifier certains paramètres Windows. Et bien qu’il ait été possible d’analyser des ensembles de données dans plusieurs langues, certaines combinaisons de langues étaient tout simplement impossibles. La nouvelle version Unicode de WordStat permet d’analyser toutes ces langues sans modifier les paramètres, ainsi que plusieurs nouvelles langues qui n’étaient pas prises en charge auparavant, comme le chinois, le japonais ou le thaï. Des routines de segmentation de mots pour ces trois langues asiatiques ont également été ajoutées.

2. Intégration de scripts de pré et post-traitement R et Python
En 2018, nous avons introduit la possibilité de créer des scripts de prétraitement en Python dans WordStat 8. La version 9.0 étend cette capacité en offrant la possibilité de créer des scripts de prétraitement en R également. Mais surtout, il est maintenant possible de créer des scripts de post-traitement dans ces deux langages de programmation, ce qui permet de pousser encore plus loin la personnalisation des analyses sur les données textuelles originales ou transformées, ou sur les résultats quantifiés obtenus par l’analyse de contenu de ces documents. Une telle fonctionnalité offre des possibilités infinies pour élargir les fonctionnalités de WordStat, comme l’implémentation de nouveaux algorithmes d’apprentissage automatique, de techniques avancées de modélisation statistique ou de transformation personnalisée des données. Des exemples de scripts ont été inclus pour calculer les métriques de lisibilité des textes, détecter les langues, appliquer d’autres techniques de modélisation thématique (LDA ou STM) ou créer des modèles prédictifs utilisant l’apprentissage automatique (SVM, kNN, etc.).
![]()

3. Correction automatique de l’orthographe
Un nouveau engin de vérification orthographique a été écrit de toute pièce afin d’obtenir des corrections orthographiques bien plus précises et beaucoup plus rapides, ce qui permet le déploiement de la correction orthographique automatique avec un impact minimal sur la vitesse de traitement du texte de WordStat. La correction orthographique intelligente permet même de corriger l’orthographe de termes inconnus tels que les vocabulaires techniques, les noms propres, etc. Les résultats peuvent être automatiquement enregistrés dans la liste de substitution pour être revus et rectifiés.
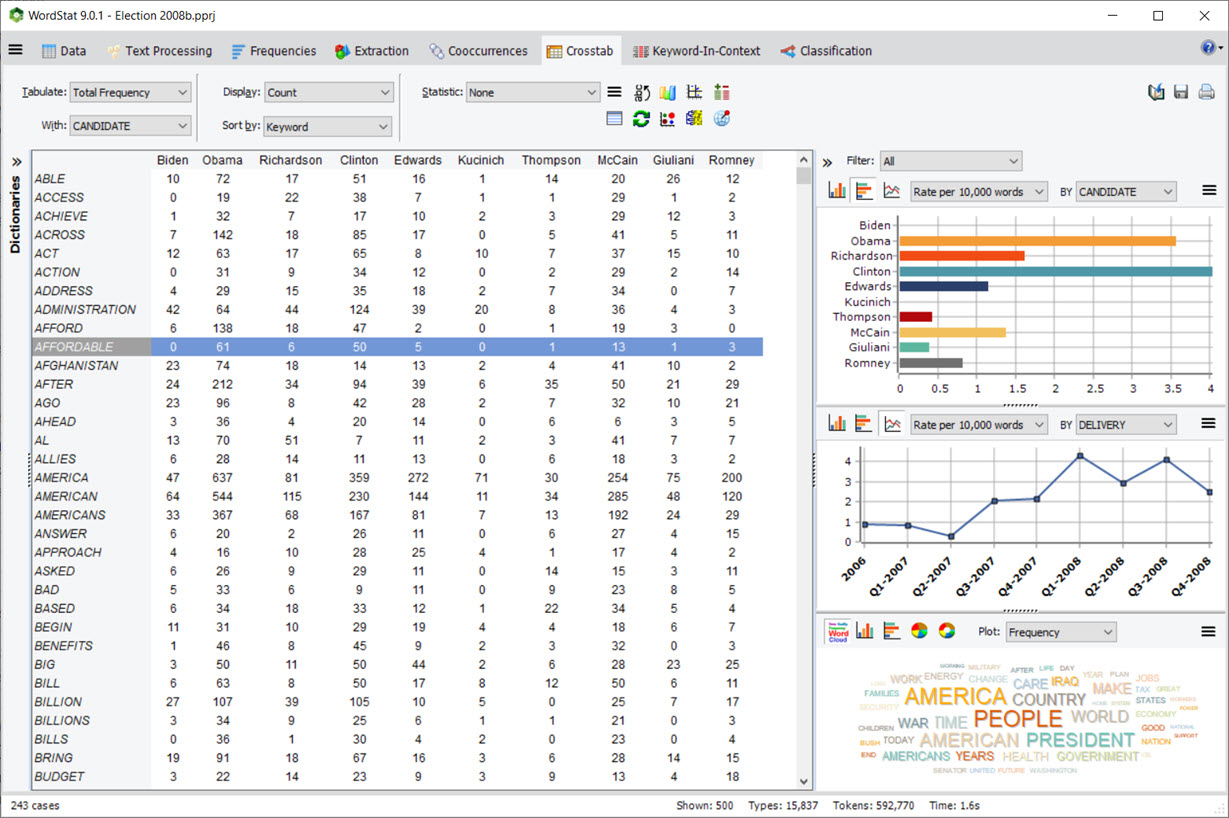
4. Tableau croisé avec panneaux graphiques et un filtre
La page de Tableaux croisé comprend maintenant un panneau graphique permettant de tracer rapidement la distribution des lignes sélectionnées du tableau croisé pour les valeurs de la variable sélectionnée ou de toute autre variable. Une liste de filtrage permet également d’analyser ces distributions pour une seule valeur ou pour un ensemble de valeurs de la variable sélectionnée.
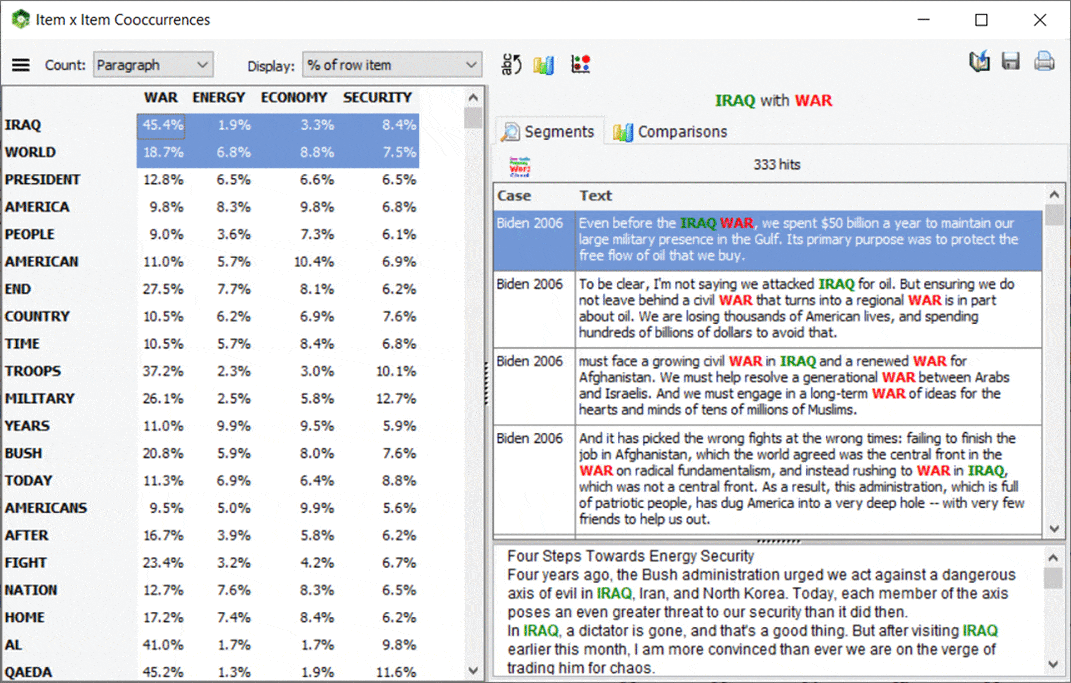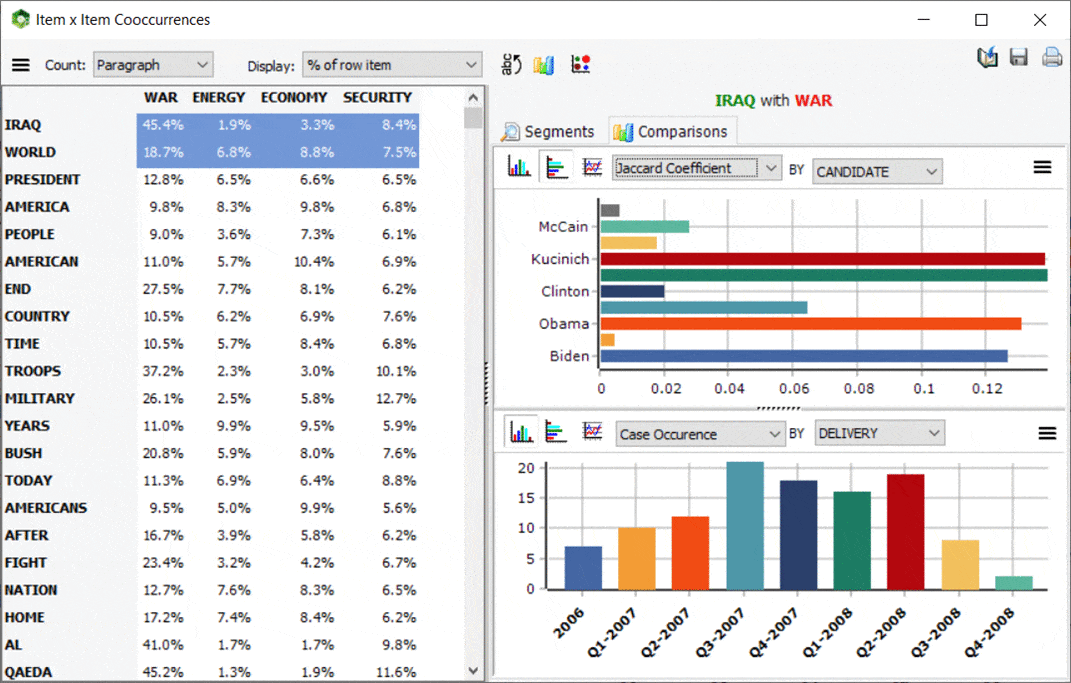
5. Matrice de cooccurrence interactive
Une nouvelle matrice interactive a été ajoutée à la page des cooccurrences, permettant de se concentrer sur des cooccurrences précises. Les principaux résultats consistent en un tableau affichant un choix parmi diverses statistiques de cooccurrence. Cette matrice est également très interactive et permet de transformer des lignes spécifiques en nouvelles colonnes ou vice-versa à l’aide de simples opérations de glisser-déposer. Un panneau graphique sur la gauche permet également d’évaluer la distribution d’une cooccurrence spécifique sur d’autres variables. Vous pouvez aussi obtenir un aperçu de tous les segments de texte associés à une cooccurrence spécifique. Cette nouvelle fonctionnalité de WordStat peut également être appelée à partir de la liste de fréquences en sélectionnant les éléments cibles (mots ou catégories de contenu) qui doivent être affichés en colonnes, en faisant un clic droit et en sélectionnant Co-Occurrence Matrix.
6. Importation des fichiers Nexis UNI et Factiva
Introduit en 2020 dans QDA Miner 6.0, il est désormais possible dans WordStat d’importer des transcriptions de nouvelles à partir des fichiers de sortie de LexisNexis et Factiva. Après avoir sélectionné un ou plusieurs fichiers .DOCX ou RTF obtenus de ces services, WordStat extrait et stocke dans des variables séparées le titre et le contenu de la transcription, sa source, la date de publication et d’autres informations pertinentes. Cette fonctionnalité se révèle utile pour la gestion de la réputation, la gestion de la marque, la communication en situation de crise, l’analyse du cadrage des médias, les études comparatives des médias, etc.

7. Traitement des modèles thématiques par lot
Le choix du nombre de sujets à extraire à l’aide de techniques de modélisation thématique reste une question pour laquelle il n’existe, à notre connaissance, aucune réponse définitive. On peut même douter de l’existence d’un tel nombre optimal. En fait, on peut aller jusqu’à suggérer que les informations obtenues à l’aide de différents paramètres pourraient bien servir des objectifs différents ou révéler des aspects différents d’une réalité. Dans un tel contexte d’incertitude, les chercheurs souhaitent souvent comparer différentes solutions. La nouvelle fonction de traitement par lots permet de calculer plusieurs modèles thématiques en faisant varier systématiquement le nombre de sujets à extraire et, pour la méthode probabiliste (par exemple, NNMF), d’effectuer plusieurs exécutions en utilisant les mêmes paramètres afin d’évaluer la stabilité des résultats. Toutes les solutions de modélisation thématique sont temporairement agrégées dans le gestionnaire de rapports, ce qui permet de comparer les solutions obtenues lors de plusieurs essais utilisant différents paramètres.
8. Créez des Nuages de Mots sur les récupérations de mots-clés et les résultats KWIC
Il est désormais possible d’obtenir des nuages de mots interactifs et des tableaux de fréquence de mots directement sur les résultats d’extraction de mots-clés et de mots-clés en contexte (KWIC), ce qui permet d’identifier rapidement les mots associés à des catégories de contenu spécifiques, ou les mots apparaissant juste avant ou après un élément cible spécifique.
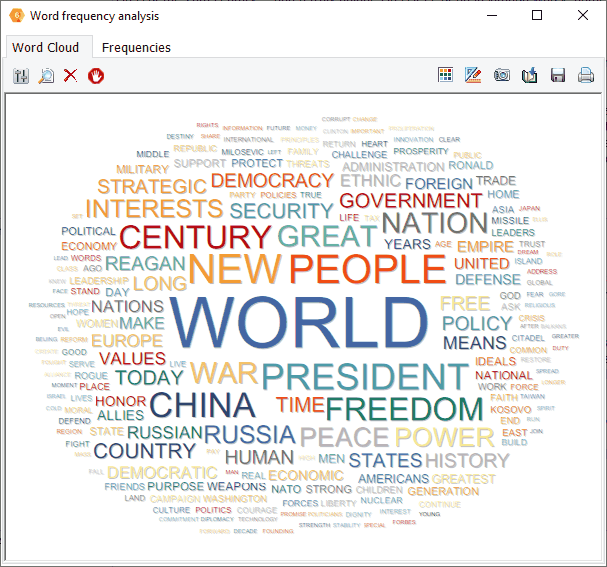
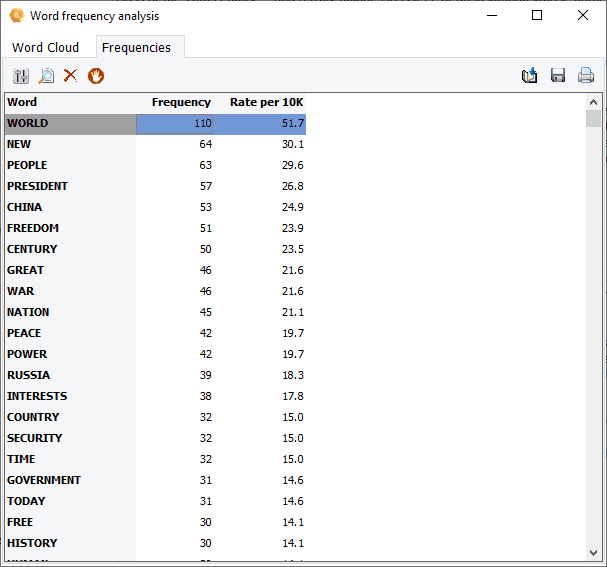
9. Des règles de proximité plus puissantes
Le nombre de conditions dans les règles de proximité a été augmenté de quatre à un maximum de vingt conditions. Si vous pensez que ce n’est pas suffisant, veuillez nous le faire savoir.
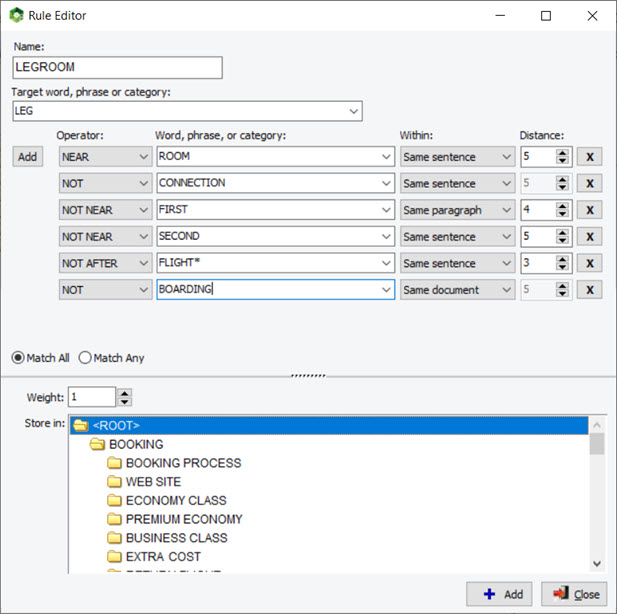
10. Aperçu de l’effet des caractères génériques et des interactions entre dictionnaires
L’utilisation de caractères génériques dans un dictionnaire est assez puissante, mais potentiellement gênante, car elle peut correspondre à des éléments auxquels vous n’avez peut-être pas pensé. Par exemple, une entrée comme TAX* peut vous permettre de faire correspondre TAX, TAXES, TAXATION, mais aussi des mots comme TAXI, TAXONOMIE, TAXIDERMIE, etc. De même, les règles de WordStat pour faire correspondre les éléments et empêcher le double comptage peuvent également produire des résultats inattendus causés par d’autres entrées dans votre modèle de catégorisation. Un nouveau panneau à droite des pages d’exclusion et de catégorisation vous permet d’identifier facilement les nouvelles entrées qui seraient mises en correspondance en utilisant un *wildcard à la fin d’un mot, mais aussi les conflits possibles avec d’autres entrées de votre dictionnaire
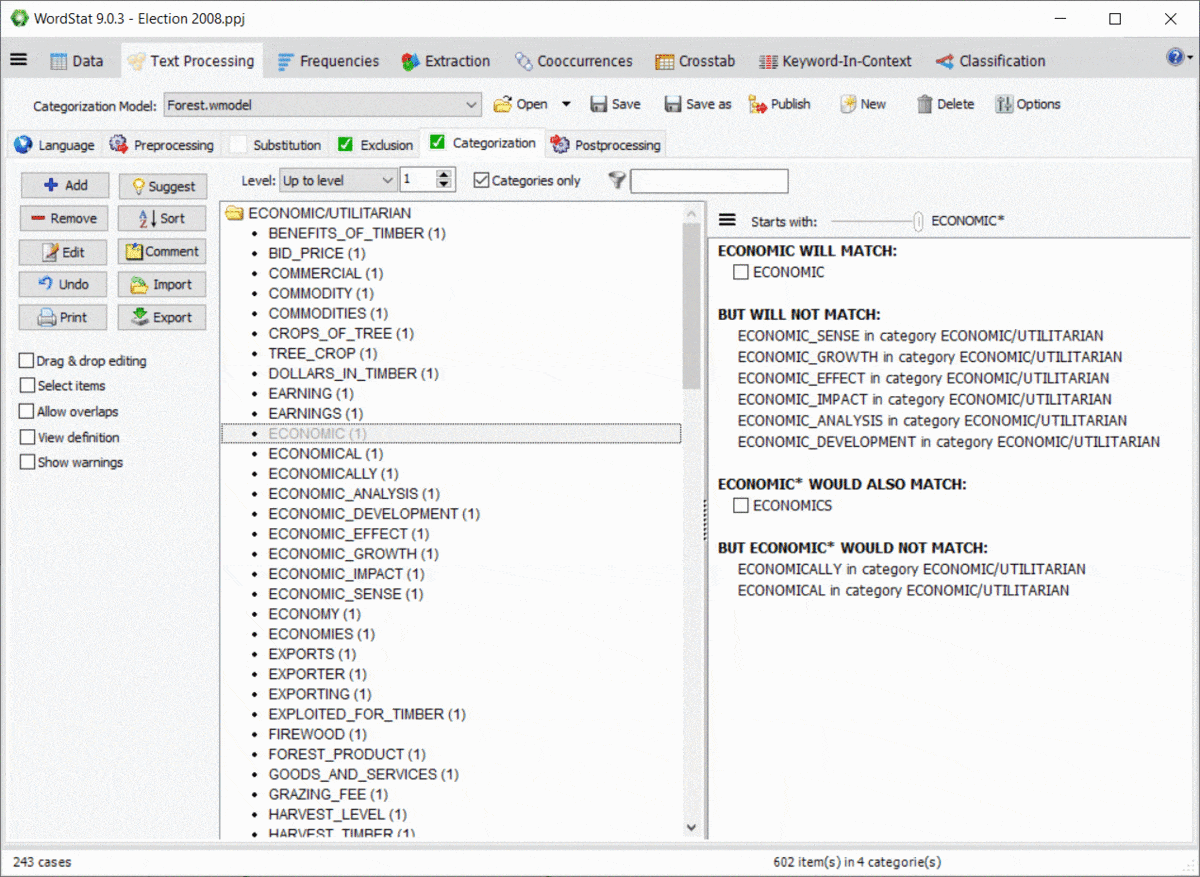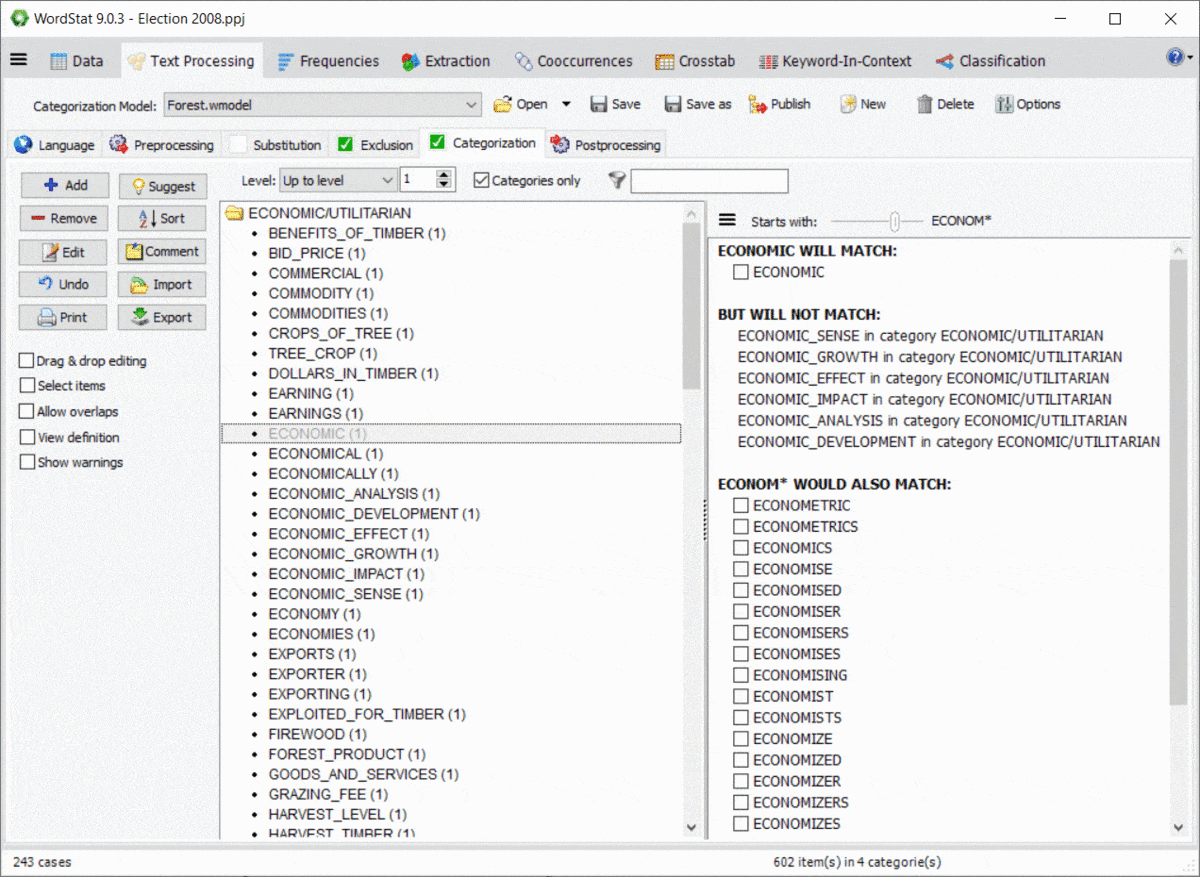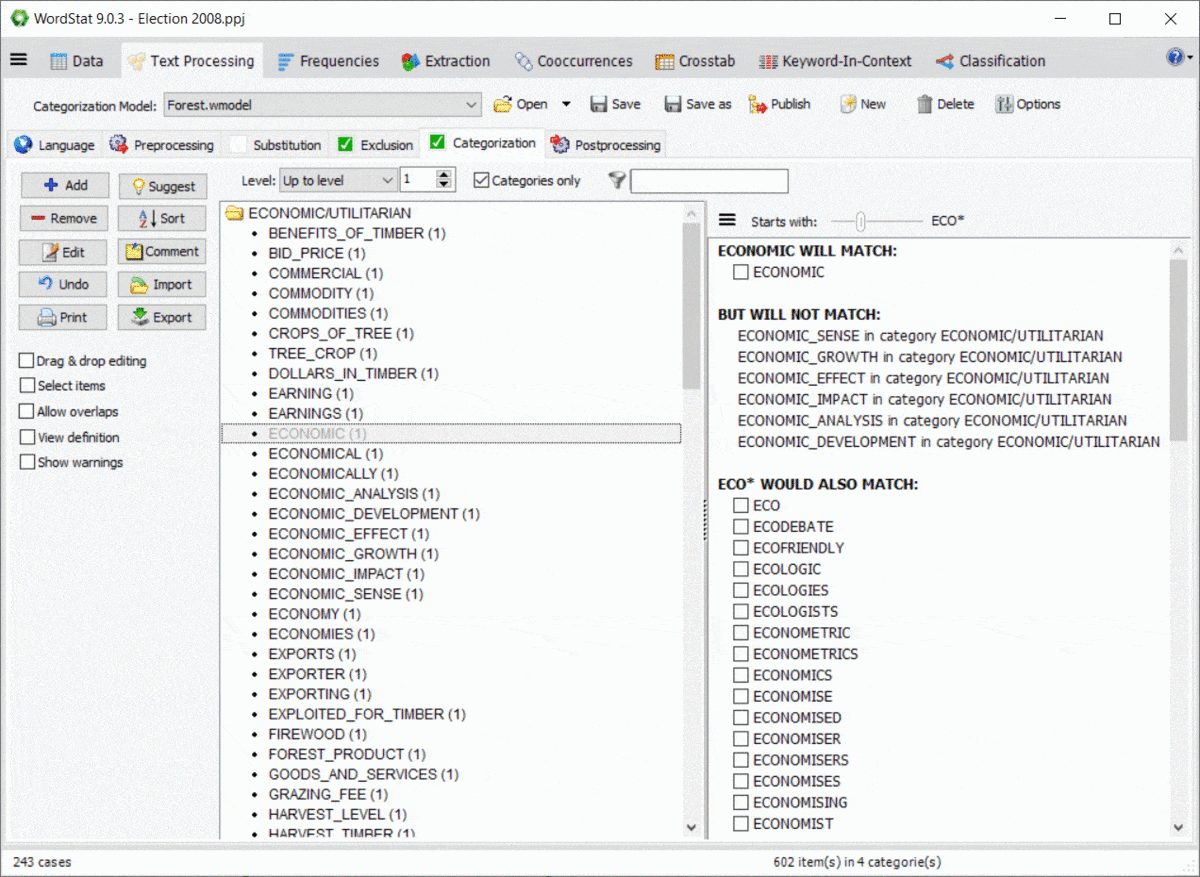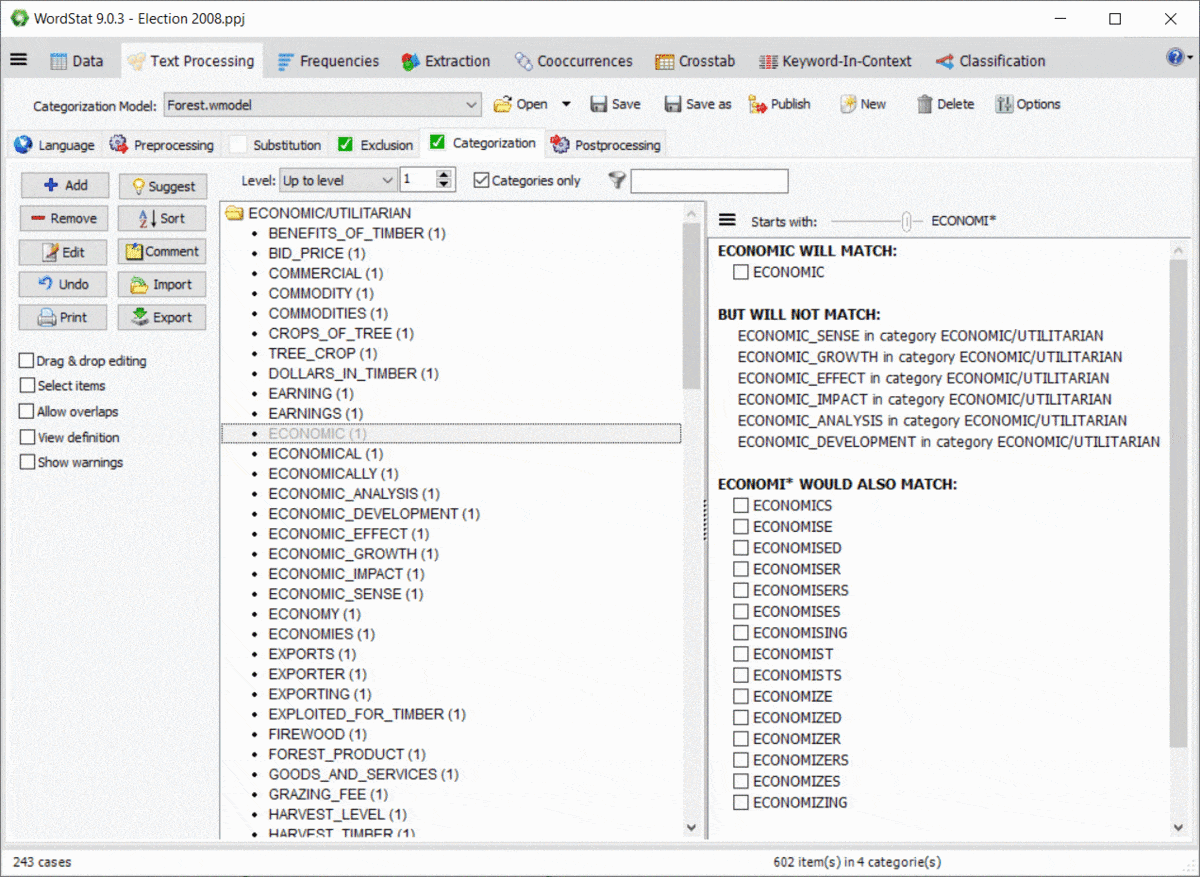
11. Protection par mot de passe des fichiers du projet
WordStat 9.0 offre désormais la possibilité de protéger les fichiers de projet par un mot de passe, limitant ainsi l’accès de certains projets aux utilisateurs autorisés. Une boîte de dialogue permet à l’administrateur du projet de créer de nouveaux comptes utilisateurs et de définir les opérations que chaque utilisateur est autorisé à effectuer. On peut limiter l’édition, l’importation ou la transformation des données, ainsi que l’exportation des données, des tableaux et des graphiques du projet. On peut aussi choisir de laisser les utilisateurs effectuer toutes les transformations qu’ils souhaitent, mais les empêcher d’enregistrer le fichier du projet.
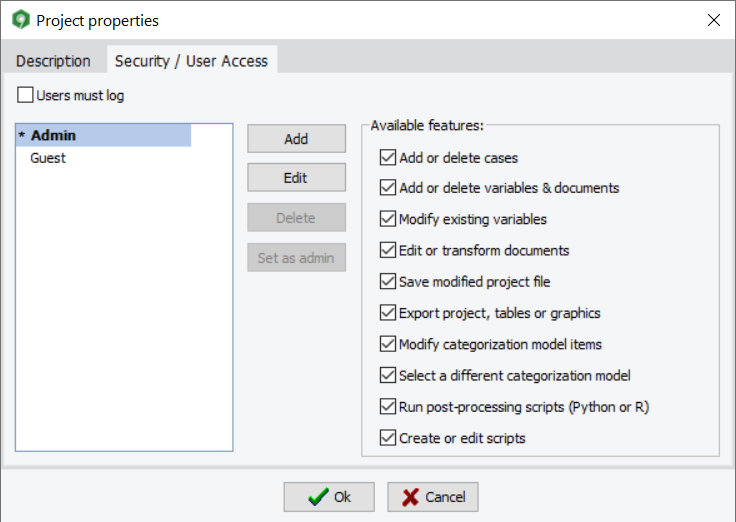
12. De nouvelles options pour le nettoyage des données
La page de prétraitement comprend désormais des options permettant de supprimer automatiquement les URL des messages texte ainsi que les dénominations de locuteurs dans les transcriptions d’actualités et d’interviews.
13. Nouvelles graphiques à aires empilées
La section graphique de la page Tableau croisé offre la possibilité de créer deux types de graphes à aires empilées.
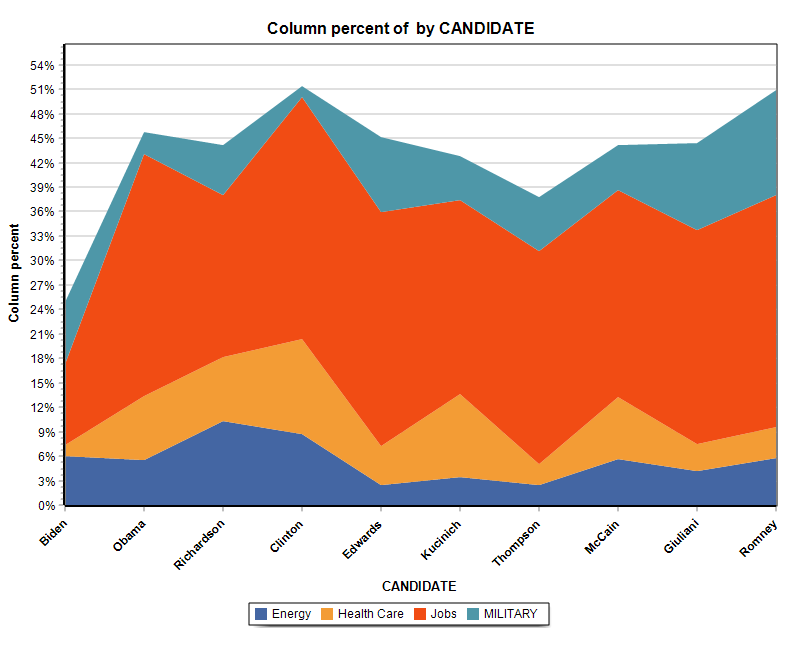
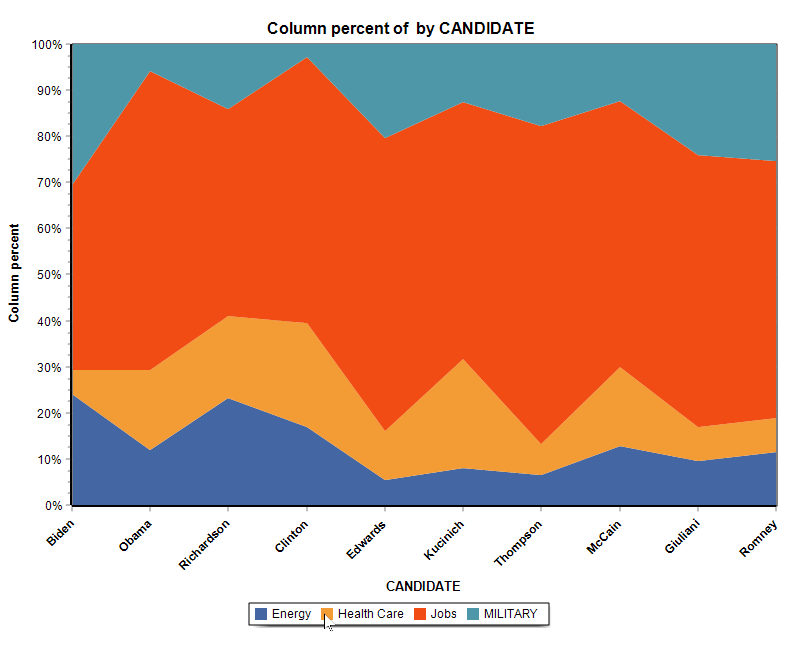
14. Diagramme de correspondance en couleur
Les gradients de couleur peuvent maintenant être utilisés pour représenter la position d’éléments spécifiques ou de classes de variables sur la troisième dimension (profondeur) ou sur le graphique de correspondance 2D et 3D. Jusqu’à quatre couleurs peuvent être choisies pour créer ces gradients.

15. Graphique à bulles amélioré
Il est désormais possible de transposer les lignes et les colonnes des graphiques à bulles.
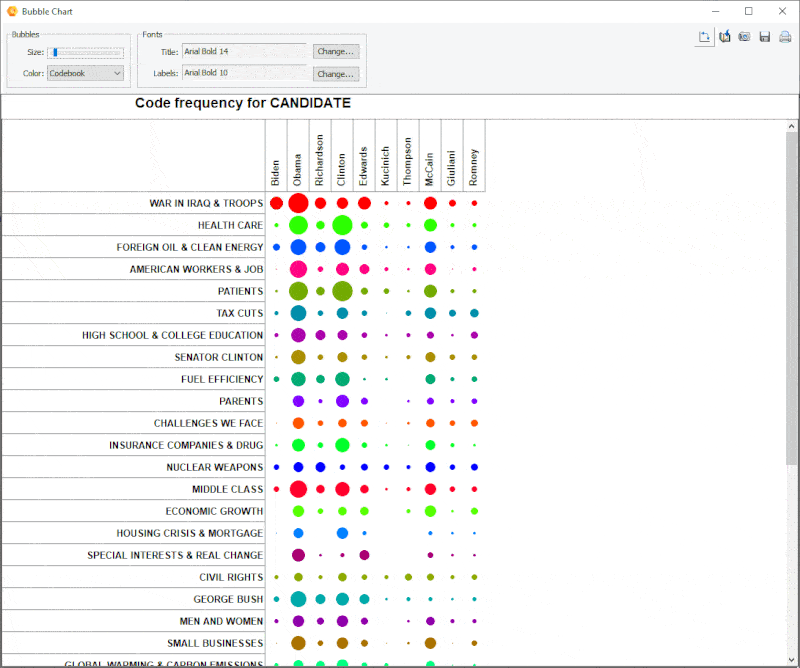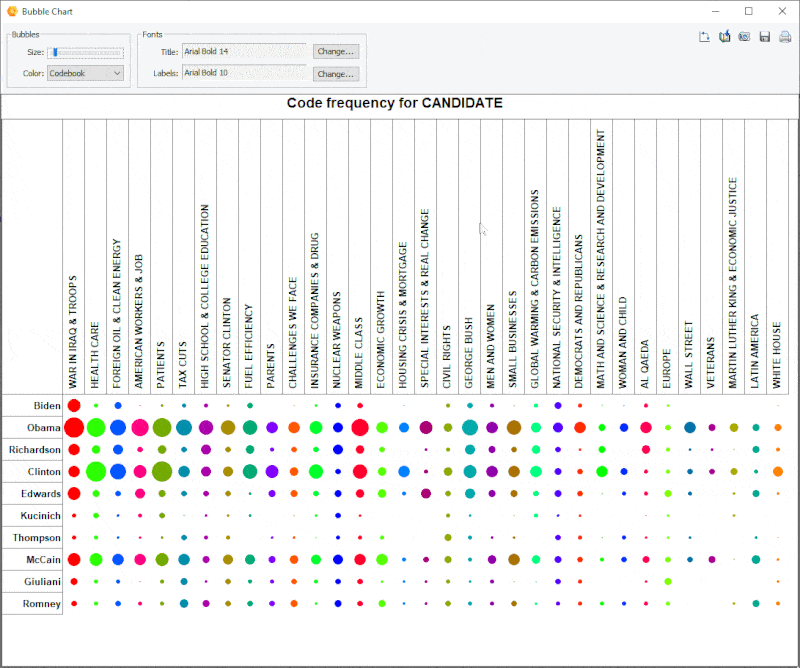
16. Tampon d’analyse des liens
Un tampon d’analyse des liens permet de faire un retour en arrière sur les schémas de liens précédents, puis de revenir en avant.
17. Un enrichissement thématique plus rapide et plus précis
WordStat va au-delà de la modélisation thématique classique en offrant « une fonction unique d’enrichissement du sujet qui identifie les phrases associées, les exceptions potentielles et les fautes d’orthographe. Il génère aussi automatiquement des noms de thèmes pertinents. Avec la version 9, cette fonction d’enrichissement des thèmes est deux fois plus rapide qu’auparavant et effectue une meilleure désambiguïsation du sens des mots pour obtenir une liste plus précise des exceptions. Elle fournit également de meilleures suggestions pour les corrections orthographiques.
18. Vitesse et précision accrues des corrections orthographiques existantes
La fonction de correction orthographique déjà existante est désormais jusqu’à 30 fois plus rapide, ne nécessitant qu’une à deux secondes pour suggérer des corrections pour des dizaines de milliers de mots inconnus.
19. Nouveau format de fichier .PPRJ
Un nouveau format de fichier avec une nouvelle extension de fichier (.pprj) a été créé, offrant un meilleur support pour les données Unicode. Cependant, WordStat 9 conserve une rétrocompatibilité avec les versions antérieures de tous nos logiciels et peut ouvrir et analyser les fichiers de projet actuels (.ppj) créés par QDA Miner, SimStat, ou des versions plus anciennes de WordStat.
20. Nombreuses améliorations supplémentaires
Plusieurs options supplémentaires et améliorations de l’interface ont été apportées aux boîtes de dialogue existantes, aux graphiques, à la gestion des données et aux fonctions d’analyse des données.
Les nouvelles fonctionnalités de WordStat 8 peuvent être consultées ici