

Powered by AI since 1998
Content analysis and text mining software for fast and precise processing of large amounts of unstructured information
LES NOUVELLES FONCTIONNALITÉS DE WORDSTAT 2026
La version 2026 poursuit l’engagement de WordStat à combiner une analyse textuelle transparente, fondée sur des règles, avec des outils flexibles assistés par l’IA. Cette mise à jour élargit les capacités d’analyse et d’interprétation, améliore les requêtes en langage naturel et renforce la validation des modèles. Elle accroît également l’interopérabilité avec les structures de connaissances existantes grâce à l’importation de fichiers de taxonomies locales aux formats SKOS et Turtle.
La mise à jour introduit aussi plusieurs améliorations qui facilitent la transition entre les tâches qualitatives, textuelles et statistiques, et simplifient l’examen ou l’ajustement des variables associées. Les améliorations apportées aux requêtes linguistiques, aux outils de suggestion et aux options de filtrage soutiennent davantage le développement systématique de systèmes de classification structurés, de taxonomies et de dictionnaires.
1. Nouveaux scripts analytiques pour l’évaluation du discours et du style
Cinq nouveaux scripts d’analyse ont été testés et ajoutés afin de faciliter l’évaluation du discours et du style. Ces scripts mesurent la cohérence, la confiance, la subjectivité, l’émotivité et les préjugés dans les transcriptions de discours ou les documents écrits.
2. Requêtes en langage naturel sur les fréquences
La page Fréquences prend désormais en charge les requêtes formulées en langage naturel. Les utilisateurs peuvent poser directement des questions sur des mots, des catégories de contenu ou même des termes restants, ce qui permet une exploration plus intuitive et plus flexible des données de fréquence.
3. Sélection d’items assistée par IA dans les Suggestions
Dans les onglets Suggestions des pages Fréquences, Modélisation de thèmes et Extraction d’expressions, les utilisateurs peuvent désormais appliquer des critères personnalisés exprimés en langage naturel pour la sélection automatique des items. Cette fonctionnalité simplifie le processus de retenue ou de filtrage des termes en fonction de leur pertinence, aidant ainsi à affiner les vocabulaires ou à identifier des termes représentant des dimensions conceptuelles distinctes.
4. Amélioration des requêtes IA dans la modélisation de thèmes
Les requêtes IA en modélisation de thèmes ont été étendues afin de permettre l’analyse soit du thème sélectionné, soit de l’ensemble des thèmes simultanément. Les requêtes peuvent également être limitées à des sous-ensembles de mots — tels que les mots affichés, les termes les plus fréquents ou les phrases suggérées — offrant ainsi un moyen plus ciblé d’examiner la manière dont les thèmes et les catégories sont définis dans le corpus.
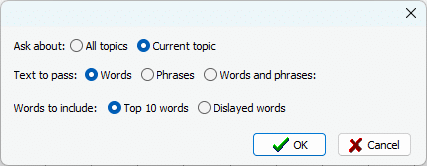
5. Validation élargie des items basée sur des invites
S’appuyant sur la fonctionnalité introduite en 2025 qui identifiait automatiquement les phrases pertinentes et non pertinentes associées à un thème ou à une phrase donnée, la version 2026 ajoute une invite Expliquer la relation afin d’identifier la logique sous-jacente pour chaque item sélectionné. Cette étape supplémentaire agit à la fois comme un mécanisme de sécurité — en détectant les items incorrectement sélectionnés par le modèle — et comme une source d’information, aidant les analystes à comprendre des liens propres au domaine qu’ils ne connaissent pas forcément.
6. Suggestions étendues basées sur les embeddings dans la page des Fréquences
L’onglet Suggestions de la page Fréquences a été amélioré. Auparavant, il affichait uniquement les mots associés — notamment les synonymes, antonymes et termes sémantiquement liés dérivés des embeddings lexicaux. Il présente désormais aussi des phrases associées sémantiquement, organisées en deux groupes : 1) les phrases contenant le mot cible, et 2) les phrases sémantiquement liées mais ne le contenant pas.
Cette vue élargie offre un contexte plus riche pour explorer les associations conceptuelles et identifier des schémas de phrases pertinents.
7. Suggestions étendues dans la page d’extraction de phrases
L’onglet Suggestions de la page Extraction de phrases inclut désormais les mots individuels qui sont sémantiquement associés ou fréquemment cooccurrents avec la phrase cible. Cela permet aux utilisateurs d’identifier des termes équivalents ou complémentaires, ainsi que des acronymes, et d’obtenir un aperçu des associations conceptuelles pouvant éclairer le développement ou le raffinement des catégories.
8. Éditeur de feuilles de calcul intégré pour les Variables
Un nouvel éditeur de feuille de calcul a été ajouté pour permettre la manipulation directe des variables numériques, catégorielles, logiques et de date. Il prend en charge les opérations standards du presse-papiers, facilitant l’attribution ou la modification rapide de valeurs sur un grand nombre de cas. Cela offre une manière plus efficace de consulter et d’éditer les variables d’un projet.
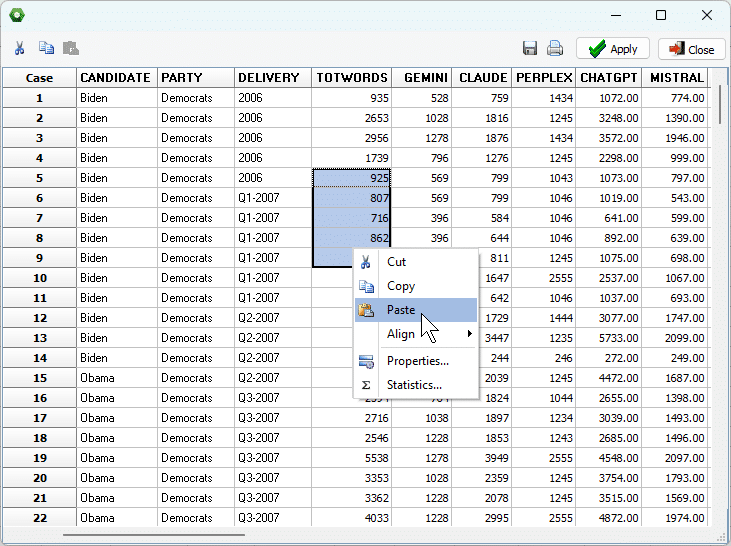
9. Accès intégré à SimStat pour l’analyse statistique
WordStat peut désormais lancer SimStat directement depuis un projet ouvert, permettant aux utilisateurs de réaliser des analyses statistiques sur des variables numériques ou catégorielles sans avoir à changer manuellement d’application. Le processus est entièrement intégré : la sélection de la nouvelle commande ouvre le projet en cours dans SimStat, et la fermeture de SimStat ramène automatiquement l’utilisateur dans WordStat, sans manipulation supplémentaire des fichiers. Cela simplifie le flux de travail pour les utilisateurs qui s’appuient sur les deux outils pour l’analyse de données issues du texte et les tests statistiques.

10. Prise en charge des fichiers de taxonomies locales SKOS et Turtle
WordStat 2026 permet désormais d’importer des fichiers SKOS et Turtle locaux, facilitant l’intégration de vocabulaires, thésaurus et taxonomies existants dans vos projets. Cela améliore l’interopérabilité avec les standards externes et simplifie la réutilisation de systèmes de classification propres à un secteur ou à un domaine spécifique.
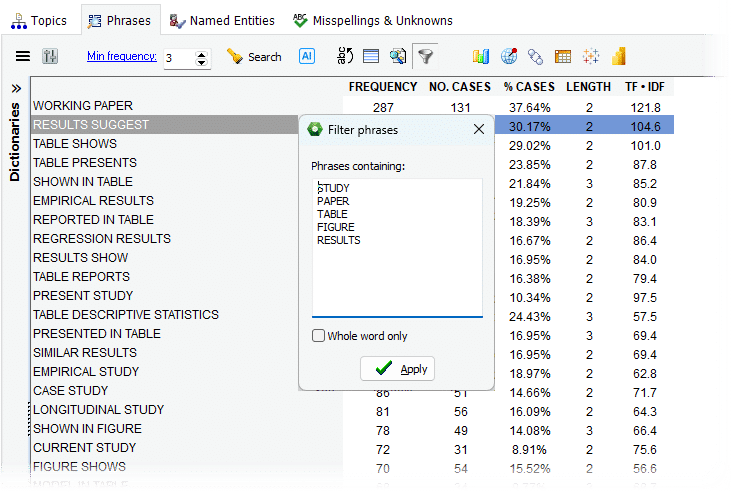
11. Filtrage multiple d’expressions pour les phrases
Le filtre de phrases accepte désormais plusieurs expressions textuelles à correspondance. Par exemple, il est possible de récupérer toutes les phrases contenant l’un quelconque des termes « table », « résultats », « données » ou « figure ». Cette fonctionnalité facilite l’examen et la consolidation des groupes de phrases, améliorant l’efficacité des tâches d’organisation lexicale ou conceptuelle.
12.Liste mémorisée des phrases non informatives
Une nouvelle fonctionnalité permet aux utilisateurs de signaler les phrases non informatives et de les ajouter à une liste d’ignorées propre au projet. Ces phrases seront exclues des étapes d’extraction et de suggestion futures. La liste est mémorisée entre les sessions et peut être modifiée ou vidée à tout moment, contribuant à maintenir des suggestions claires, pertinentes et ciblées.
Fonctionnalités inclut dans WordStat 2025 : analyse de texte optimisée par l’IA
L’IA générative a révolutionné l’analyse de texte, mais elle fait encore face à des défis sur des tâches plus complexes. Elle a également une évolutivité limitée, des biais potentiels et un coût élevé, ainsi qu’un manque de transparence. WordStat 2025 comble cette lacune en intégrant de manière transparente l’IA générative avec les techniques avancées existantes d’exploration de texte, de traitement du langage naturel et d’apprentissage automatique, offrant aux chercheurs un contrôle complet. Choisissez parmi les moteurs d’IA de pointe, personnalisez les invites et créez même les vôtres pour une analyse sur mesure.
Cette version apporte également des améliorations majeures aux fonctionnalités existantes et introduit un outil révolutionnaire pour explorer les différences dans les co-occurrences, offrant des insights plus profonds avec précision et facilité.
Un PDF documentant les nouvelles fonctionnalités peut être téléchargé en cliquant ici.
1. Choix de plusieurs moteurs et modèles d’IA
WordStat 2025 offre la possibilité d’effectuer une analyse et une transformation de texte en utilisant le moteur de votre choix parmi six options en ligne (OpenAI, Gemini, Claude, Mistral, Perplexity ou DeepSeek) et une option hors ligne (Ollama). Les utilisateurs peuvent également choisir le modèle qui leur fournit les performances dont ils ont besoin à un prix qui correspond à leur budget.

2. Nouvelles routines d’analyse et de transformation de texte alimentées par l’IA
Nous avons évalué plusieurs fonctionnalités pilotées par l’IA et intégré celles qui ont démontré de solides performances, dans certains cas surpassant les capacités existantes de WordStat, bien qu’avec des compromis en termes de vitesse de traitement et de coût. Parmi les implémentations les plus efficaces se trouvent l’analyse de sentiment, l’extraction des avantages et inconvénients, la correction orthographique et la traduction automatique, toutes offrant des résultats très précis sur la plupart des moteurs d’IA. De plus, nous avons introduit le scoring de lisibilité assisté par IA, la lemmatisation, la segmentation des langues asiatiques (chinois, japonais, thaï, etc.), ainsi que le regroupement des tokens monosyllabiques vietnamiens.
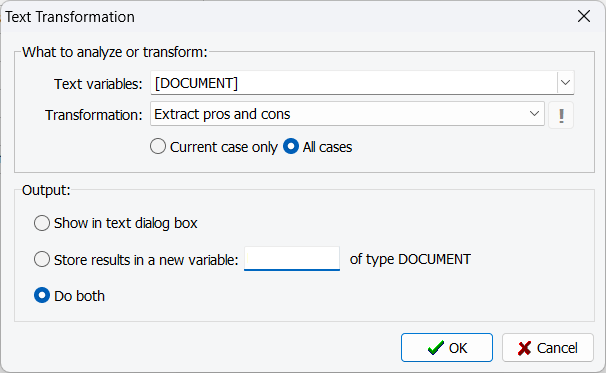
3. Extraction et résumé de texte par IA
La performance de nombreuses tâches d’IA générative tend à décliner avec de très longs documents. Une solution efficace consiste à diviser ces documents en sous-documents plus courts et axés sur des sujets en extrayant tous les segments pertinents à un thème spécifique. La fonctionnalité EXTRACTION/RÉSUMÉ IA dans WordStat permet aux utilisateurs d’effectuer de telles extractions sur tous les cas d’un projet, sauvegardant les résultats dans une nouvelle variable de document.
Au-delà de la simple extraction, cette fonctionnalité permet également aux utilisateurs de générer soit un résumé général du document complet, soit un résumé thématique basé sur un thème défini par l’utilisateur. En réduisant la portée de l’analyse à des questions spécifiques, ces segments ciblés peuvent ensuite être utilisés pour des requêtes de suivi plus précises et significatives, améliorant considérablement la pertinence et la précision des réponses GenAI.
4. Dénomination des modèles de sujets assistée par l’IA
Bien que les moteurs d’IA générative ne soient toujours pas capables d’effectuer la modélisation de sujets sur de grands ensembles de données, ils excellent à fournir des noms pertinents aux sujets extraits. Alors que WordStat fournissait déjà des noms de sujets, il est maintenant possible d’obtenir des noms générés par IA plus descriptifs.
5. Regroupement de sujets généré par IA
Un nouveau script IA peut être utilisé pour identifier automatiquement les catégories de regroupement pour les sujets extraits, puis ajouter le descripteur de thème à la table des sujets. Sauvegarder les sujets dans un dictionnaire aboutit à un dictionnaire hiérarchique avec des thèmes au premier niveau, des sujets au deuxième niveau, et des mots et des expressions au troisième niveau.
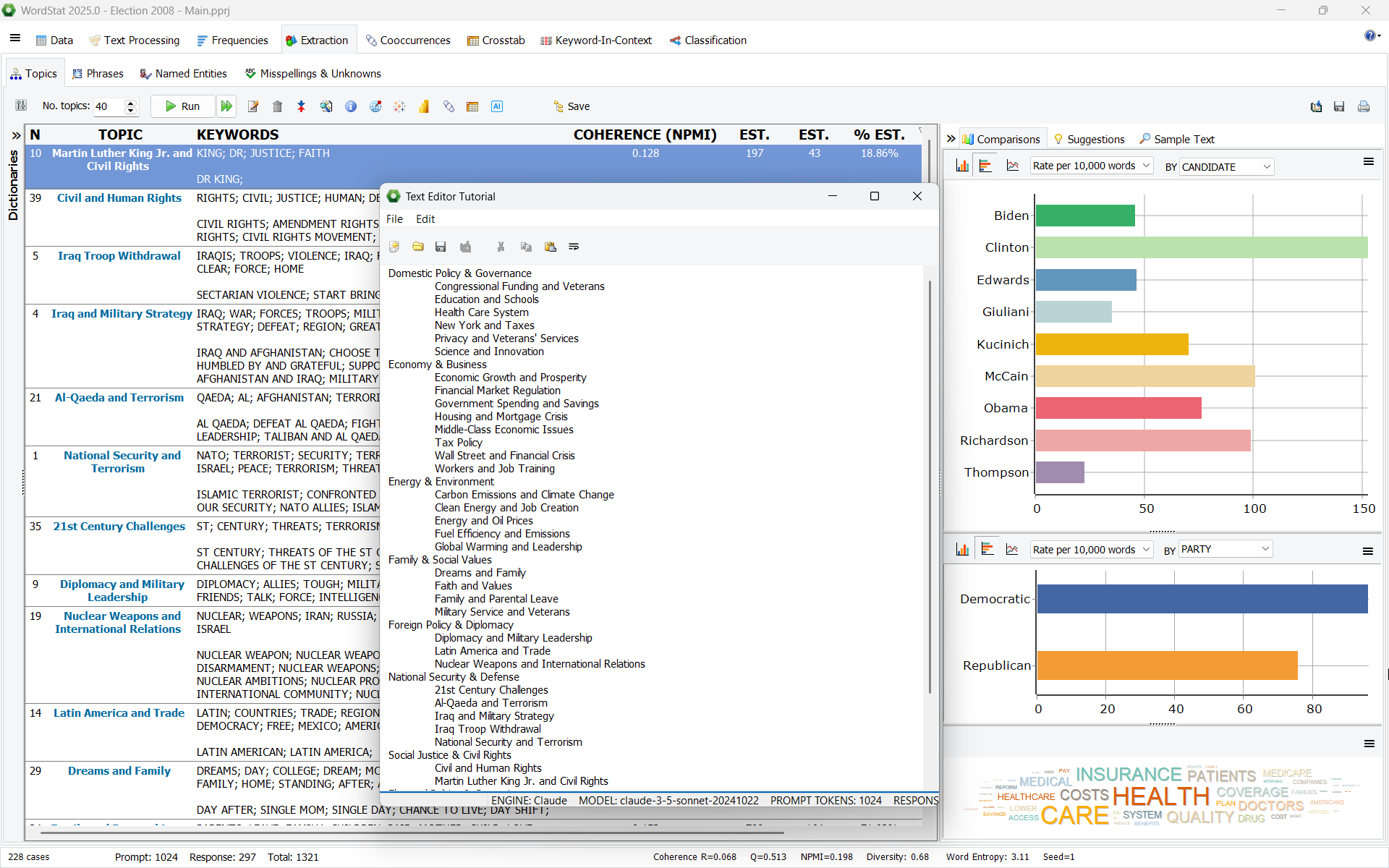
6. Classification syntaxique des expressions par IA
WordStat 2025 améliore sa routine d’extraction des expressions en offrant la possibilité d’utiliser l’IA pour classifier les expressions extraites selon leur catégorie syntaxique. Une fois les expressions extraites, l’IA peut être utilisée pour les assigner à des classes grammaticales telles que les syntagmes nominaux, les syntagmes verbaux, les syntagmes adjectivaux, les syntagmes prépositionnels, etc. Cette catégorisation offre une analyse plus structurée, permettant aux utilisateurs de se concentrer sur des thèmes ou sujets spécifiques, des comportements, des processus, des émotions, ou d’autres éléments associés aux différents types d’expressions syntaxiques.
7. Classification d’entités nommées basée sur l’IA
La reconnaissance d’entités nommées traditionnelle a du mal avec les termes ambigus et les significations dépendantes du contexte. WordStat 2025 introduit la classification d’entités alimentée par l’IA qui tient compte du contexte environnant pour catégoriser avec précision les noms, organisations, lieux, et plus encore, réduisant les erreurs et améliorant la précision dans la classification d’entités.
8. Scripts IA personnalisés pour le post-traitement et l’analyse
WordStat 2025 permet aux utilisateurs de créer des scripts personnalisés pour le post-traitement des sorties de table, pour appliquer l’analyse de texte ou la transformation de données sur l’ensemble de données textuelles. Avec cette flexibilité, vous pouvez adapter le logiciel pour répondre à vos besoins spécifiques en automatisant les tâches répétitives, en appliquant des opérations de prétraitement personnalisées, ou en intégrant des routines externes.
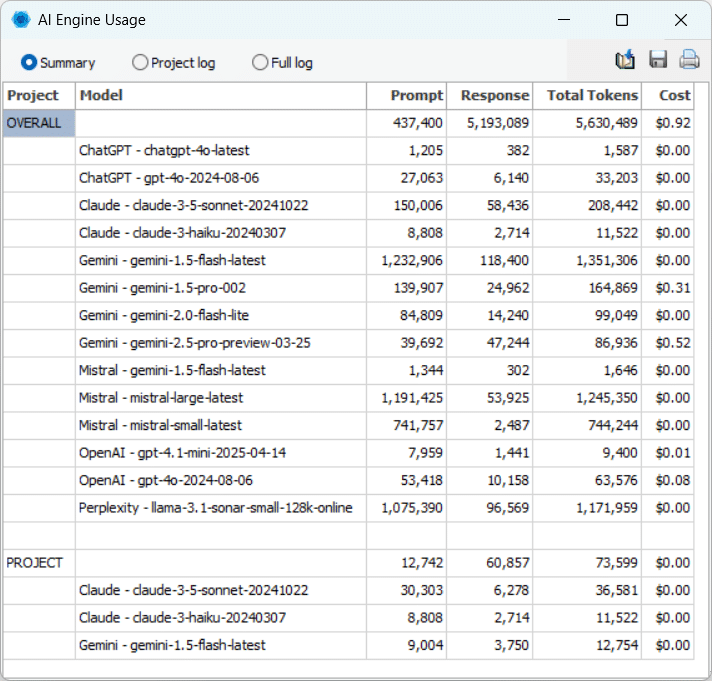
9. Surveiller la consommation de tokens IA
Avant d’exécuter toute invite, WordStat affiche une estimation détaillée des coûts basée sur le modèle sélectionné et la longueur de l’entrée. Les utilisateurs peuvent voir à la fois une quantité estimée de tokens d’entrée et le coût associé, ainsi que le coût correspondant par million pour les tokens de sortie (puisqu’il est impossible d’estimer la longueur de la sortie). Cela facilite la comparaison de l’efficacité et des prix des différents moteurs et modèles, aidant les utilisateurs à prendre des décisions éclairées et à éviter les opérations coûteuses, surtout lors du traitement de grands ensembles de données ou de l’exécution d’analyses par lots.
Pour soutenir davantage la gestion budgétaire, WordStat suit l’utilisation cumulative des tokens et les coûts par modèles, moteurs et projets. Cette surveillance complète vous permet d’allouer les ressources plus efficacement, d’éviter les dépassements inattendus et de maintenir une transparence totale sur vos dépenses liées à l’IA.
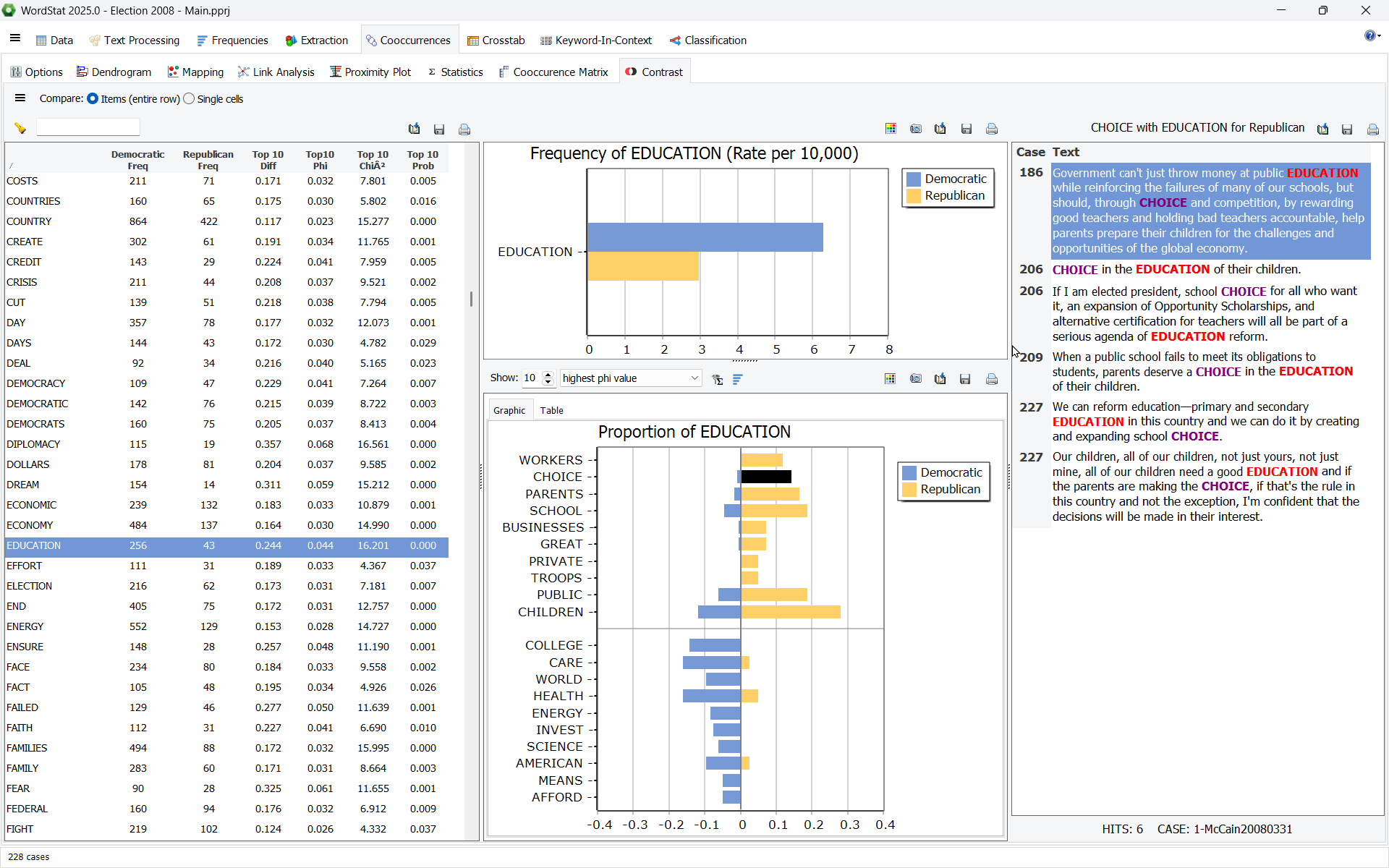
10. Explore Co-Occurrence Comparison Across Groups
WordStat 2025 introduit une fonctionnalité puissante pour comparer les modèles de co-occurrence entre groupes, révélant des différences subtiles que les méthodes traditionnelles basées sur la fréquence peuvent manquer. Alors que l’analyse de fréquence met en évidence les tendances générales, elle néglige comment les mots ou sujets peuvent être associés de manières uniques au sein de chaque groupe. Cet outil aide à identifier les variations contextuelles, comme comment le même terme peut être lié à différents concepts, préoccupations, problèmes ou solutions proposées. Les comparaisons peuvent être faites au sein de sous-groupes de l’ensemble de données actuel ou en utilisant des matrices de co-occurrence précédemment sauvegardées de différents ensembles de données. Nous sommes convaincus que cet outil débloquera de nombreuses nouvelles possibilités et génèrera potentiellement une richesse de découvertes intéressantes pour les chercheurs et analystes de données.
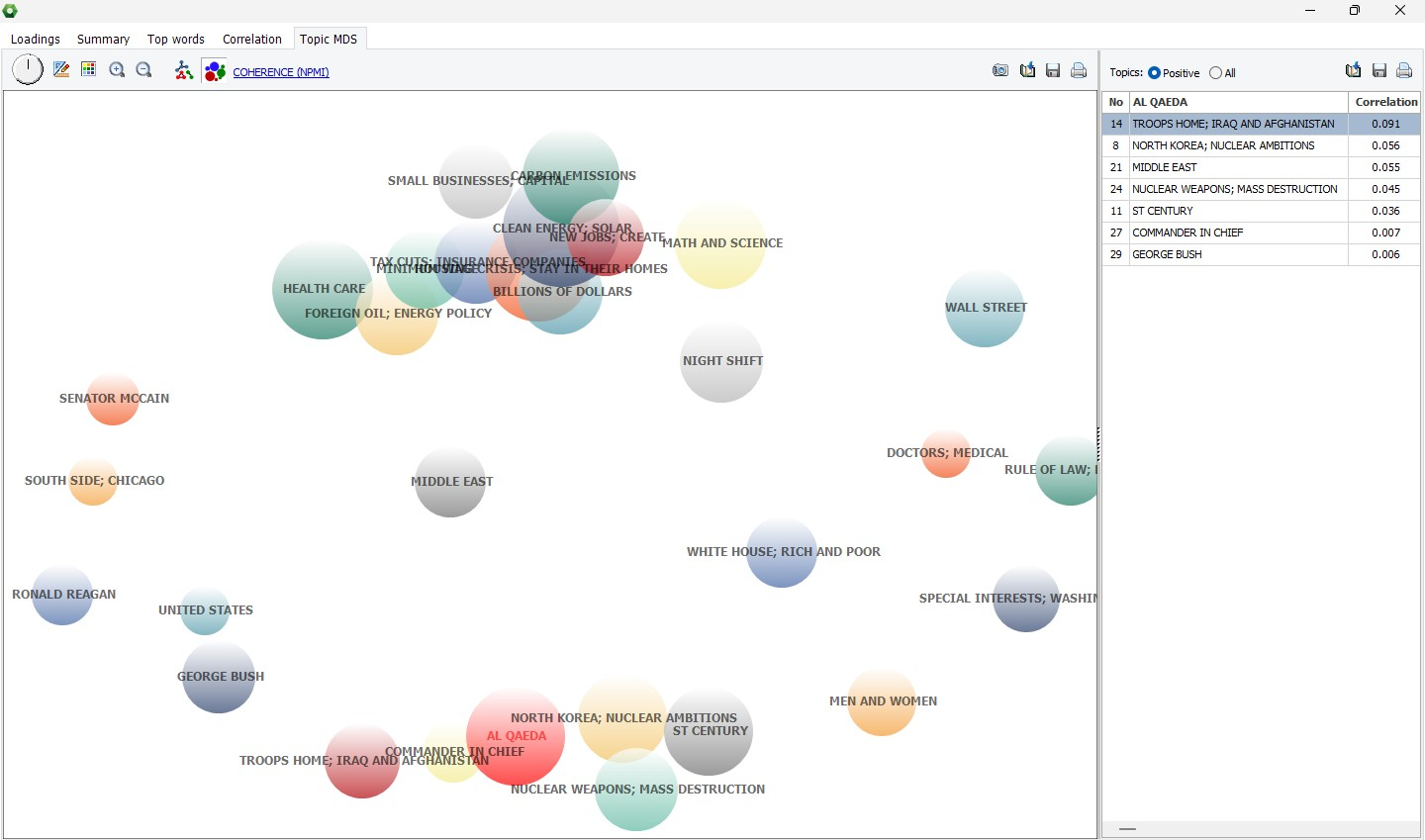
11. Explorer les relations entre sujets avec un graphique MDS interactif
WordStat 2025 introduit un graphique MDS interactif qui visualise les corrélations de sujets dans une carte bidimensionnelle. Les sujets sont représentés comme des points ou des bulles de différentes tailles représentant les fréquences ou la cohérence mesurée, avec la distance indiquant la force de corrélation. Les sujets placés près les uns des autres sont hautement corrélés, tandis que ceux plus éloignés montrent des corrélations plus faibles ou négatives. Cliquer sur un sujet révèle une table de corrélation, vous permettant d’explorer les sujets connexes par ordre décroissant de force de corrélation. Cette fonctionnalité offre une façon claire et dynamique de comprendre et d’explorer les relations entre sujets.
12. Nouvelle mesure de diversité des sujets
Les résultats de modélisation de sujets incluent une nouvelle mesure pour évaluer la diversité des sujets. Cette mesure aide à évaluer à quel point les sujets sont variés au sein d’un modèle, fournissant une compréhension plus claire de la gamme et de l’unicité des sujets découverts.
13. Panneau d’assistance au dictionnaire amélioré
Le panneau d’assistance au dictionnaire utilisé pour évaluer les interactions entre les entrées du dictionnaire et évaluer l’impact des caractères génériques inclut maintenant la possibilité d’afficher la fréquence des mots correspondant au motif sélectionné dans l’ensemble de données actuel. De plus, les entrées du panneau peuvent être filtrées pour ne montrer que les éléments présents dans l’ensemble de données, rationalisant le processus d’analyse.
Introduit dans la version 2024
Nous sommes ravis d’annoncer la sortie de WordStat 2024. Cette nouvelle version inclut d’importantes optimisations de vitesse ainsi que plusieurs fonctionnalités utiles pour explorer de manière plus détaillée et plus ciblée de grandes collections de textes. Voici quelques fonctionnalités nouvelles et améliorées :
1. Traitement initial du texte optimisé
Dans la version 2024, WordStat a considérablement amélioré l’efficacité de la lecture et du traitement initial des fichiers de données, résultant en des résultats accélérés. Cette amélioration est particulièrement prononcée pour les projets comprenant un grand nombre de petits documents, la première opération se terminant maintenant jusqu’à trois fois plus rapidement que dans les versions précédentes.
2. Appliquer des modèles de classification automatique de documents aux données de projet
WordStat 2024 permet maintenant l’application de modèles de classification automatique de documents pour la transformation de données. Trouvée sur la page Données, cette nouvelle fonctionnalité facilite le stockage des classes prédites dans une variable. Les utilisateurs peuvent également choisir de stocker la probabilité de la classe prédite ou les probabilités de toutes les classes.
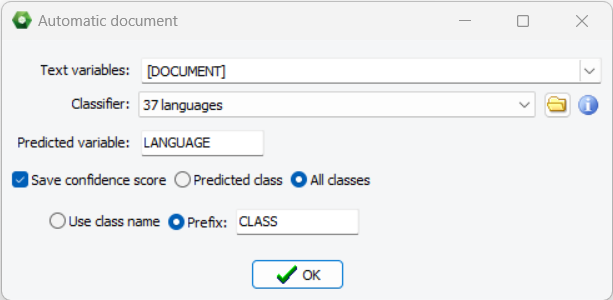
3. Détection de langue améliorée
WordStat 2024 introduit un nouveau modèle de classification d’identification de langue qui peut identifier 68 langues avec précision. Sa précision mesurée est supérieure à 95 % sur de très petits segments de texte (six mots ou moins) et supérieure à 98 % sur des documents plus longs. Le modèle de classification peut être appliqué pour créer une variable de langue dans un projet multilingue, permettant de filtrer et d’analyser différentes langues séparément.
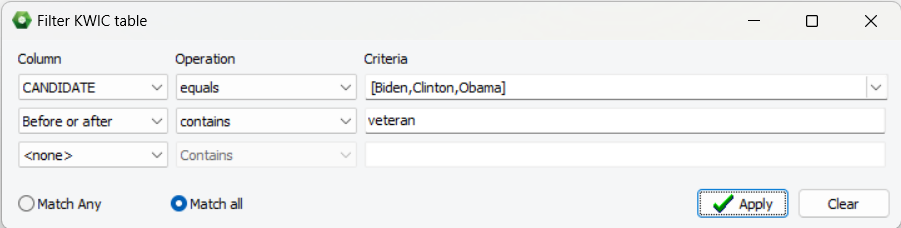
4. Filtrer les tables KWIC sur jusqu’à trois critères
Une nouvelle option de filtre sur la page Mot-clé-en-contexte peut maintenant être utilisée pour filtrer les résultats de la table KWIC sur toutes variables indépendantes sélectionnées ou sur des mots ou des expressions apparaissant avant ou après l’élément clé.
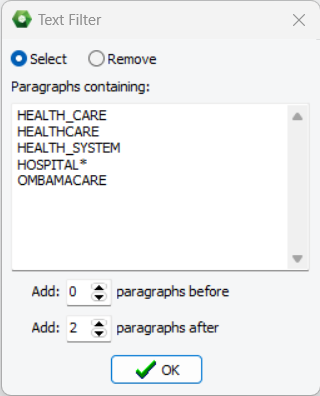
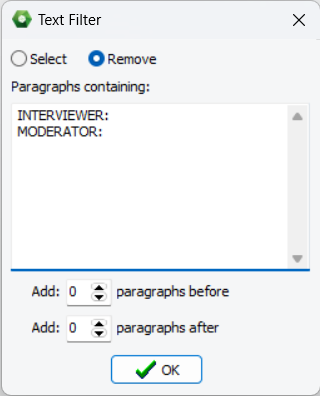
5. Sélectionner ou exclure des paragraphes à l’aide de filtres de texte
Une fonctionnalité de prétraitement avancée permet aux utilisateurs de filtrer ou d’exclure des paragraphes contenant des mots ou des expressions spécifiques. Plusieurs éléments peuvent être spécifiés et peuvent être précédés ou terminés par un astérisque pour représenter zéro, un ou plusieurs caractères supplémentaires. On peut également sélectionner des nombres spécifiques de paragraphes avant ou après le paragraphe correspondant afin d’inclure ou d’exclure le contexte environnant. Cette fonctionnalité est particulièrement utile pour se concentrer rapidement sur des sujets spécifiques dans de grands ensembles de données sans avoir besoin de créer un nouvel ensemble de données. Lors de l’analyse de transcriptions d’interviews ou de groupes de discussion, elle peut également être utilisée pour supprimer les questions de l’intervieweur ou les interventions du modérateur si leurs interventions sont clairement indiquées par des chaînes de caractères spécifiques.
6. Sauvegarder les résultats de récupération de texte vers un nouveau fichier de projet
Lors de l’utilisation de la fonction de récupération de mots-clés, un nouveau bouton permet maintenant de sauvegarder la table obtenue comme un nouveau fichier de projet. Cela inclut la préservation des options du projet actuel, telles que les paramètres de pré- et post-traitement, et le lien vers le modèle de catégorisation. Cette fonctionnalité s’avère particulièrement pratique pour l’analyse approfondie de segments de texte sur un sujet spécifique ou répondant à des conditions spécifiques.
7. Copier les données graphiques vers le presse-papiers en format texte
Il est maintenant possible de sauvegarder les données utilisées pour créer divers graphiques vers le presse-papiers en format délimité par des tabulations. On peut alors coller de manière transparente les données dans une autre application pour générer des tables ou des graphiques personnalisés.
8. Plus de façons d’ajouter des éléments au dictionnaire de catégorisation
Un clic droit sur les éléments d’un graphique de correspondance 2D ou d’une table de déviation permet maintenant d’ajouter ces éléments à une catégorie existante ou nouvelle. Cette option est désactivée ou cachée lorsque l’élément sélectionné est déjà présent dans le modèle de catégorisation actuel ou se réfère à une catégorie de contenu.
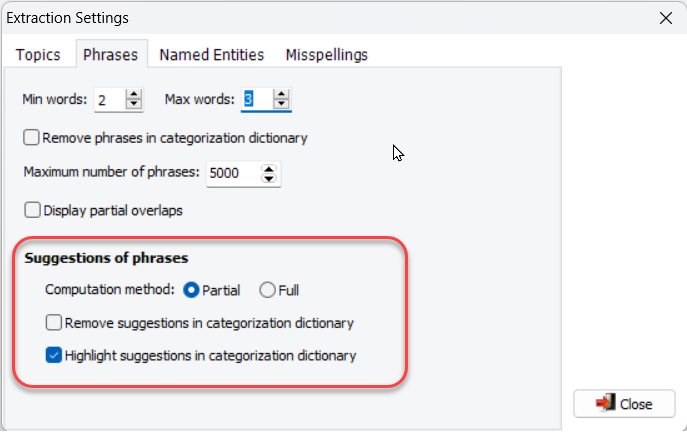
9. Filtrage et mise en évidence des expressions suggérées
De nouvelles options d’extraction des expressions ont été ajoutées pour supprimer ou mettre en évidence (gras + italique) les expressions déjà présentes dans le dictionnaire de catégorisation actuel. De plus, un mécanisme de filtrage a été introduit, permettant aux utilisateurs de définir une fréquence minimale pour réduire le nombre d’expressions suggérées.
Introduit dans la version 2023
1. Enrichissement de sujets amélioré
WordStat ajoute maintenant plus d’expressions pertinentes aux sujets extraits, tout en offrant également des suggestions améliorées pour des expressions supplémentaires. De plus, il présente maintenant une plus grande précision dans l’identification des expressions faux positifs, ou exceptions, qui peuvent être incorporées dans le modèle de sujets pour aider à désambiguïser les mots associés à des contextes non liés aux sujets extraits.
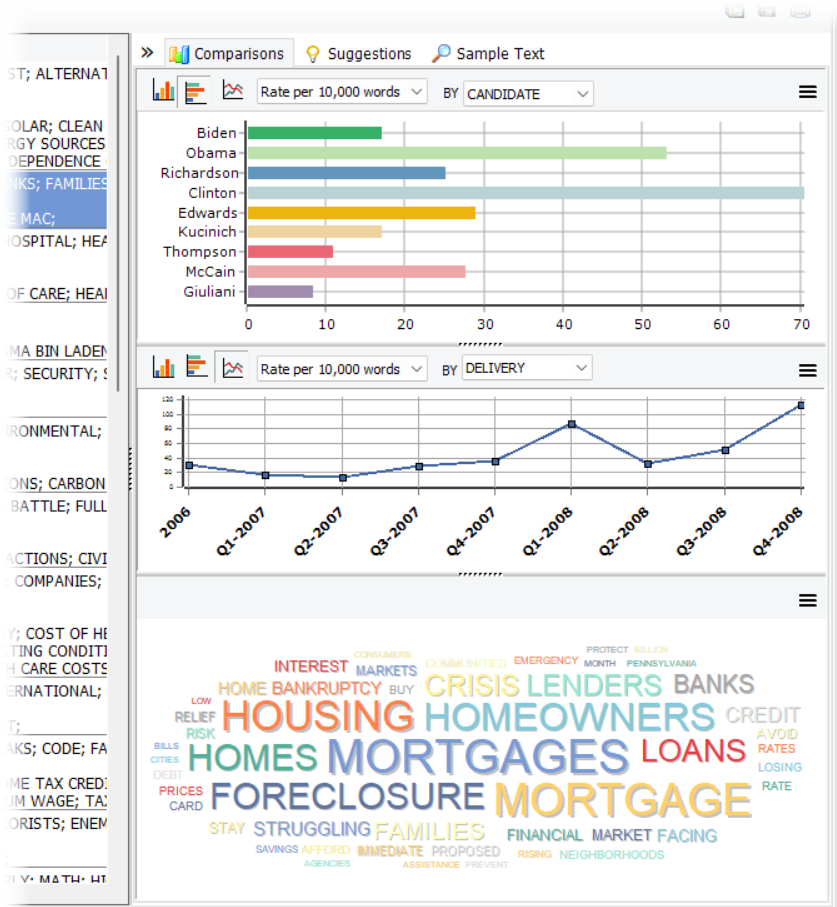
2. Nuage de mots de modélisation de sujets
Le panneau de comparaison sur le côté droit de la table du modèle de sujets présente maintenant un nuage de mots nouvellement ajouté qui représente visuellement l’importance relative des mots principaux au sein du sujet sélectionné. Ce nuage de mots peut être personnalisé, copié vers le presse-papiers, ou sauvegardé sur disque dans des formats graphiques standard comme BMP, PNG ou JPEG.
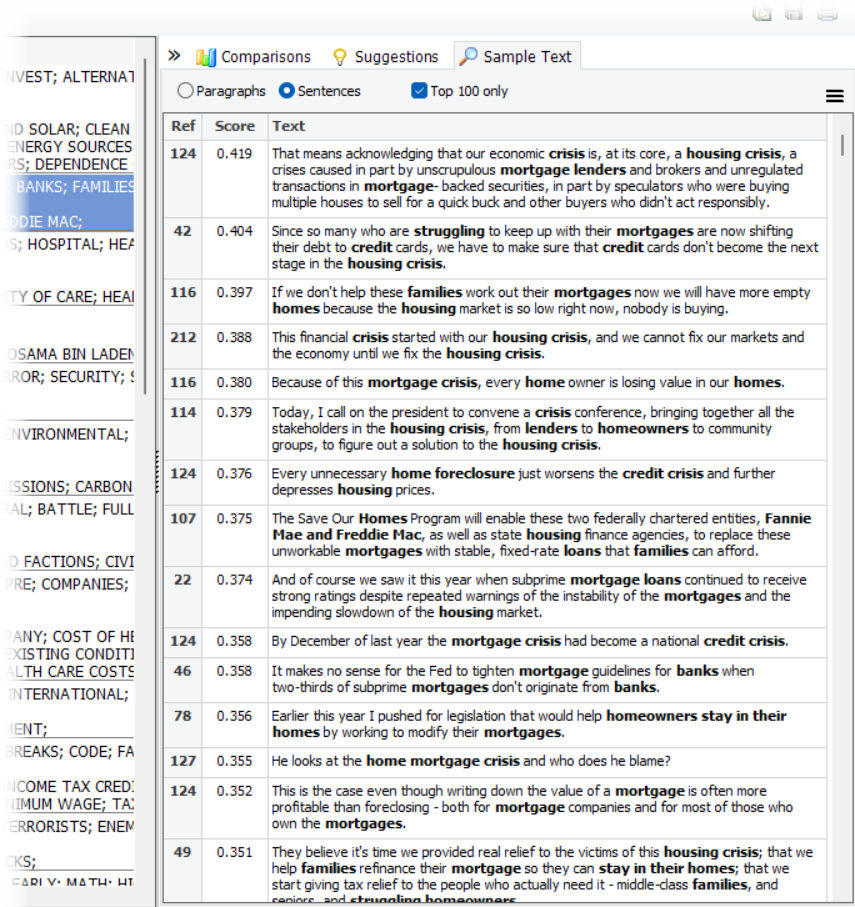
3. Nouvelle fonctionnalité intégrée de récupération de texte
Un nouveau panneau d’échantillon Texte pratique sur le côté droit de la grille de sujets peut être activé pour afficher automatiquement les expressions ou paragraphes qui correspondent au sujet sélectionné. Ces segments de texte sont présentés par ordre décroissant de pertinence, avec les mots du sujet affichés en gras, facilitant la compréhension de l’essence de chaque sujet et l’identification d’exemples clés qui peuvent être utilisés pour l’illustrer. Cet outil puissant fournit aux utilisateurs une compréhension plus profonde de leurs données et facilite une communication plus efficace de leurs découvertes.
4. Vitesse d’enrichissement des sujets améliorée
Grâce à des efforts d’optimisation significatifs, le processus d’enrichissement des sujets a été considérablement accéléré, résultant en des gains de performance jusqu’à 10 à 20 fois plus rapides que les versions précédentes.
5. Extraction des expressions instantanée
Tirant parti de la puissance du traitement multicœur, l’extraction des expressions est maintenant intégrée de manière transparente avec le traitement principal du texte, permettant aux utilisateurs d’accéder aux résultats presque instantanément. Par exemple, sur un ensemble de données de plus de 50 000 avis clients, l’extraction des 5000 expressions les plus fréquentes peut maintenant être complétée en seulement 0,4 seconde, comparé aux 14 secondes requises par la version précédente.
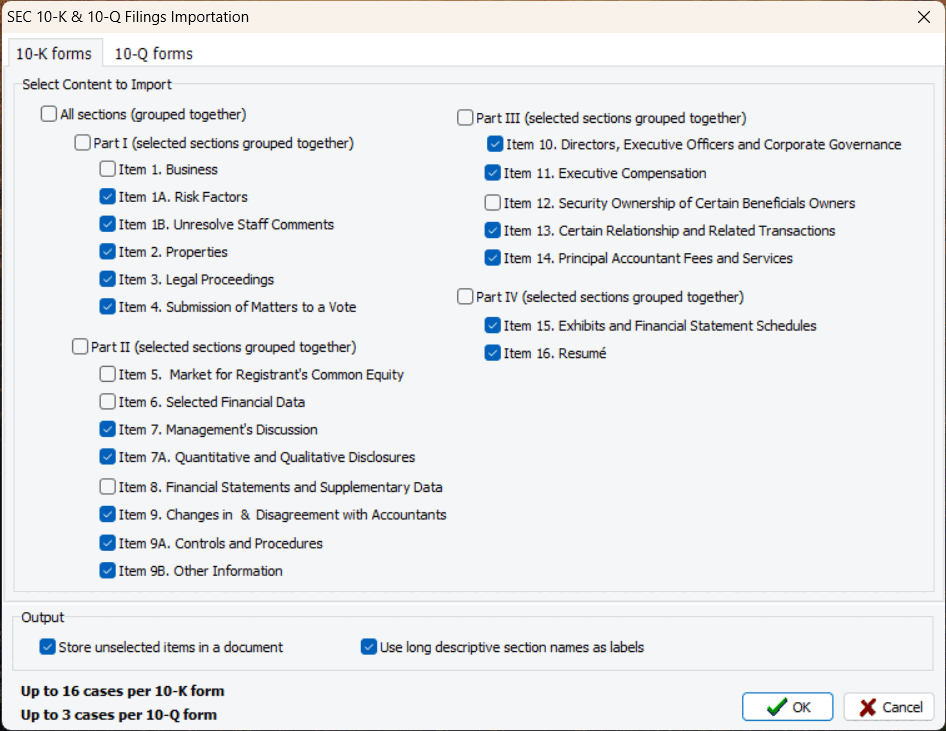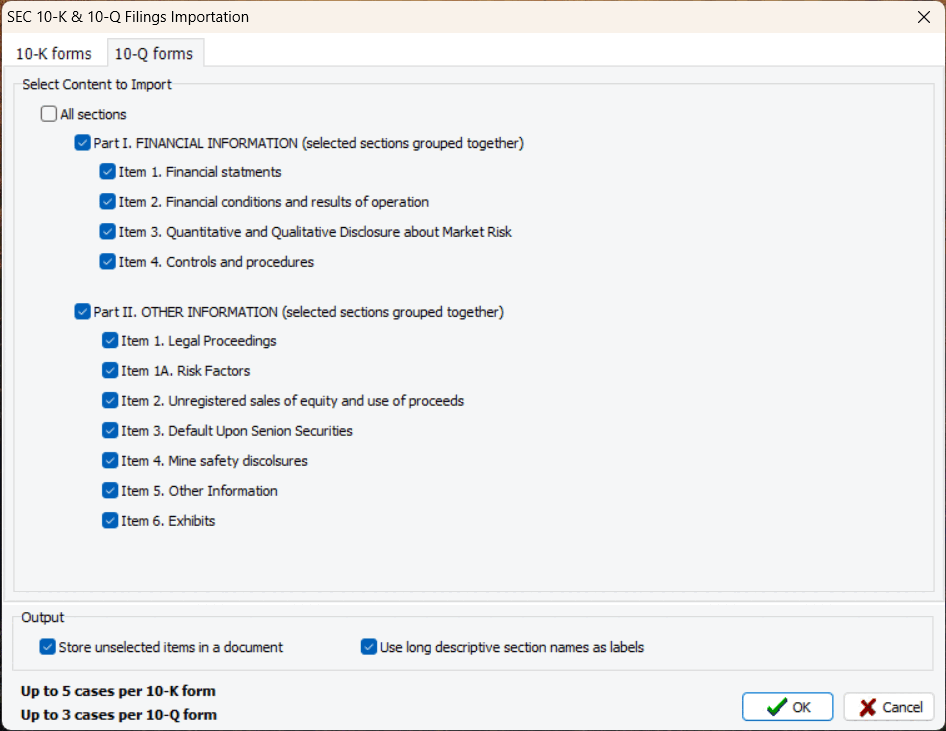
6. Importation des dépôts financiers 10-K et 10-Q (version 2023.1)
Une nouvelle routine d’importation permet aux utilisateurs d’importer des sections spécifiques des dépôts financiers 10-K et 10-Q, et de les stocker séparément ou de les fusionner en documents uniques. La routine d’extraction reconnaît automatiquement le nom de l’entreprise, la période temporelle (trimestre et année), et les stocke comme variables pour une analyse facile.
7. Exporter les résultats d’analyse de texte vers Power BI (version 2023.1)
WordStat offre maintenant une intégration transparente avec Microsoft Power BI, permettant aux utilisateurs d’exporter les résultats d’analyse de texte et les métadonnées vers Power BI Desktop pour des tableaux de bord et rapports interactifs. En exportant les résultats d’analyse de texte et les métadonnées vers Power BI Desktop, les utilisateurs peuvent créer des visualisations convaincantes, obtenir des insights plus profonds de leurs données, et partager facilement leurs découvertes avec d’autres.

8. Pousser les données de co-occurrence vers Gephi ou NetDraw (version 2023.1)
Avec la nouvelle option disponible depuis la page Dendrogramme, les utilisateurs peuvent maintenant exporter les données de co-occurrence, ainsi que des informations supplémentaires telles que la fréquence et le numéro de cluster, vers des logiciels d’analyse de réseaux sociaux comme Gephi et NetDraw. Ces outils fournissent des visualisations puissantes qui aident les utilisateurs à identifier des modèles et des relations au sein de leurs données. Gephi offre des algorithmes de disposition et des fonctionnalités interactives pour l’exploration en temps réel, tandis que NetDraw fournit des options de visualisation pour les graphiques de réseau.
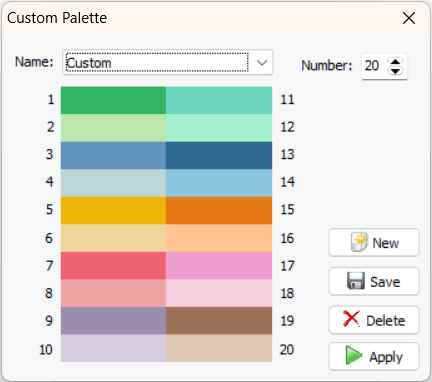
9. Palettes de graphiques personnalisées (version 2023.1)
WordStat 2023 introduit une nouvelle fonctionnalité qui permet aux utilisateurs de créer des palettes de couleurs personnalisées. Cette fonctionnalité fournit un plus grand contrôle sur les couleurs utilisées pour les graphiques, les nuages de mots, le clustering et autres visualisations, permettant aux utilisateurs de personnaliser leur sortie pour répondre à leurs besoins spécifiques.
10. Dendrogrammes circulaires (version 2023.2)
Les nouveaux dendrogrammes circulaires utilisent l’espace plus efficacement que les verticaux. Dans un dendrogramme vertical, la hauteur du dendrogramme peut devenir assez grande, nécessitant plus d’espace vertical pour l’affichage. Les dendrogrammes circulaires, d’autre part, arrangent les branches en cercle, utilisant l’espace de manière plus efficace. Les dendrogrammes circulaires peuvent être plus esthétiquement plaisants et peuvent être plus visuellement attrayants dans les présentations et publications.
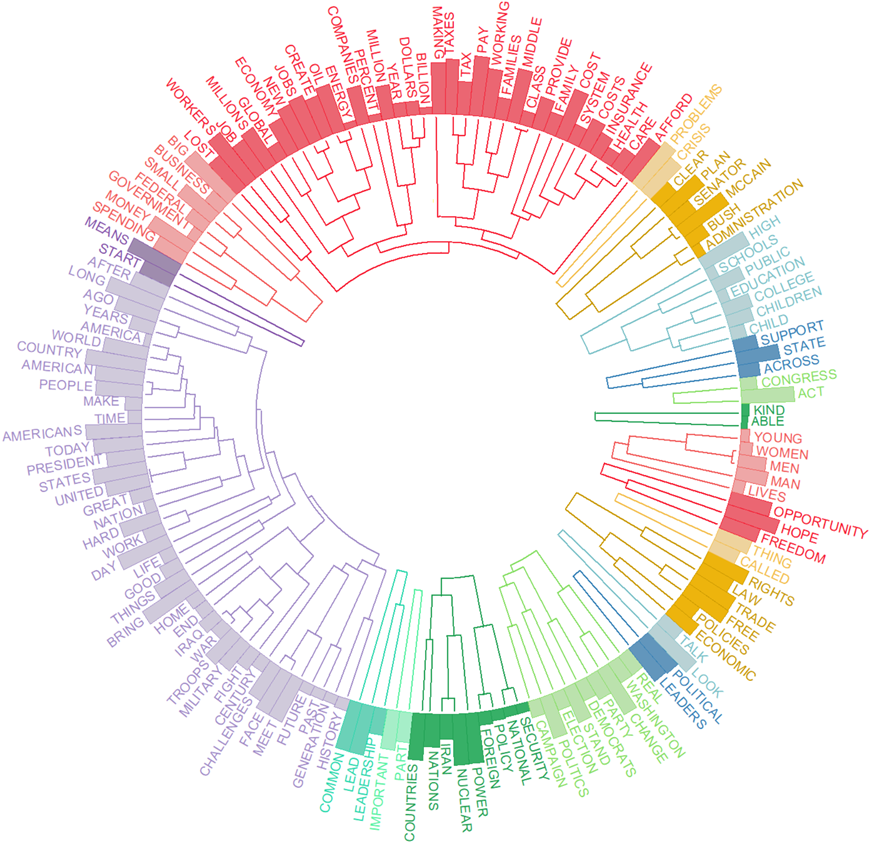
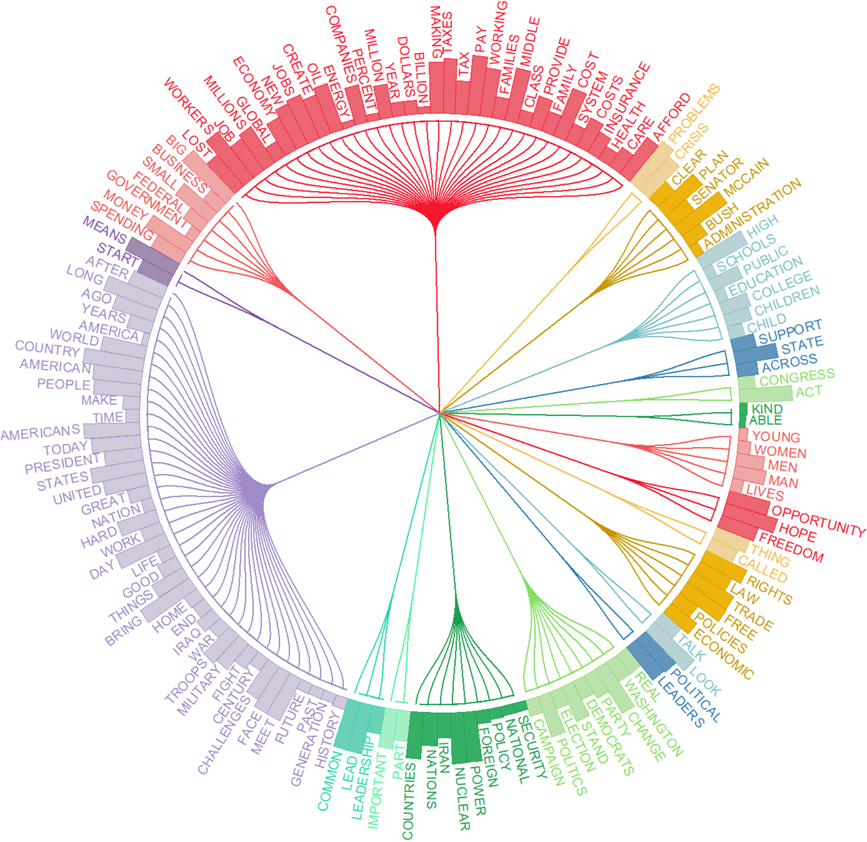
11. Clustering de sujets et informations de similarité inter-sujets (version 2023.2)
Une nouvelle option de modélisation de sujets permet d’effectuer une analyse de cluster sur une solution de sujets. Une colonne supplémentaire affichera les 3 sujets les plus similaires. Elle ordonnera également les sujets de sorte que les sujets similaires tendent à être proches les uns des autres.
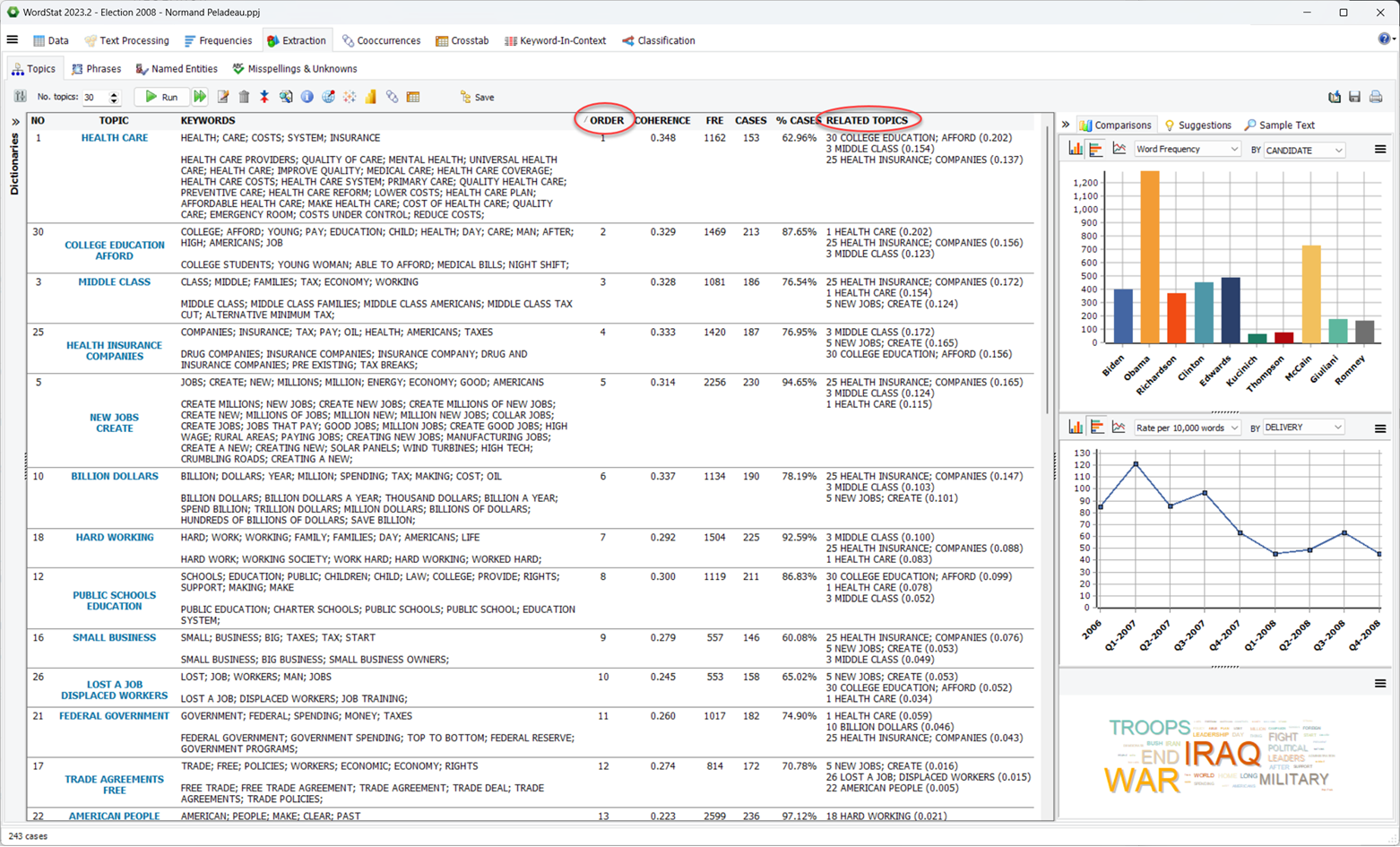
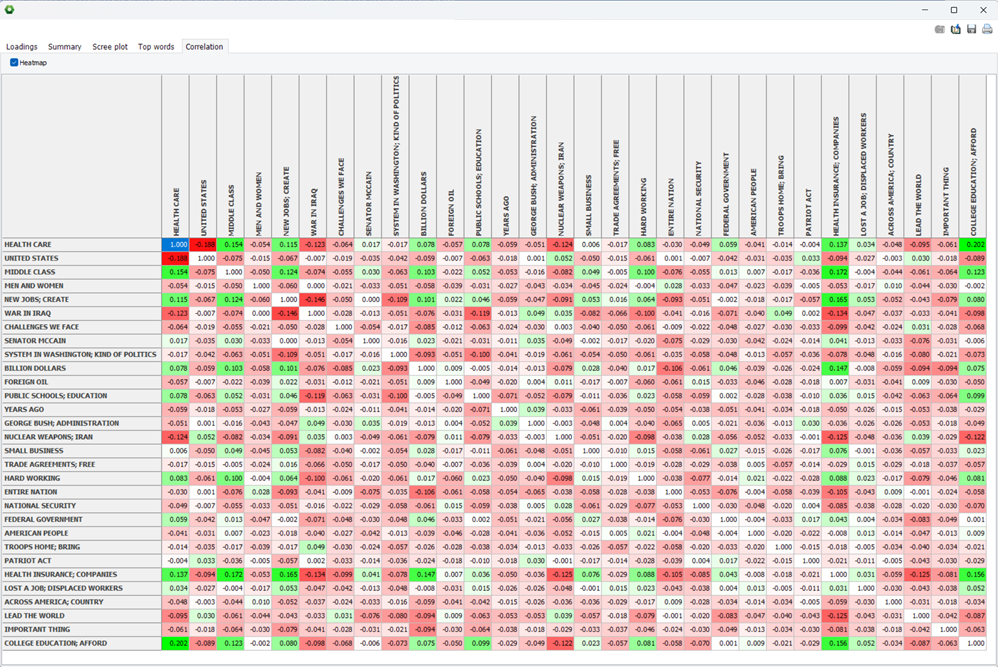
12. Table de corrélation de sujets (version 2023.2)
La boîte de dialogue des statistiques de sujets inclut maintenant une table de corrélation sujet-sujet permettant d’évaluer la similarité entre sujets. Les colonnes peuvent être triées pour ordonner les sujets par ordre croissant ou décroissant de similarité et une carte de chaleur optionnelle peut mettre en évidence les éléments connexes en nuances de vert (positivement corrélés) ou rouge (négativement liés).
Introduit dans la version 2022
1. Modélisation de sujets hautement optimisée avec analyse factorielle
Dans WordStat 2022, nous avons implémenté une nouvelle routine d’analyse factorielle multi-threadée qui est jusqu’à 65 fois plus rapide que les versions précédentes. Cela signifie que de gros problèmes qui auraient pris une heure à calculer peuvent maintenant être obtenus en moins d’une minute. Nous avons également pu augmenter la capacité d’analyse factorielle à 10 000 mots (contre 3 000 dans les versions précédentes).
Nos propres efforts de recherche ont montré que la modélisation thématique utilisant l’analyse factorielle produit des solutions thématiques qui sont plus cohérentes ainsi que plus diversifiées que les techniques de modélisation thématique reposant sur LDA et les techniques de réseaux de neurones (Peladeau & Davoodi, 2018; Peladeau, 2022). Elle a également l’avantage supplémentaire d’être stable, produisant des résultats identiques à chaque fois. Cependant, son principal inconvénient a toujours été sa vitesse et sa capacité. Cela nous a amenés à implémenter dans WordStat 8, une routine spéciale d’extraction thématique utilisant la factorisation matricielle non négative (ou NMF). Cette technique produit beaucoup plus rapidement des résultats qui sont assez similaires à ceux obtenus en utilisant l’analyse factorielle. Cependant, son implémentation probabiliste cause des résultats qui diffèrent légèrement d’une exécution à l’autre, ce que certains chercheurs trouvent quelque peu perturbant. Il est important de noter que presque toutes les autres techniques populaires de modélisation thématique en informatique produisent des solutions thématiques qui sont encore plus instables que notre implémentation personnalisée de NMF. La vitesse et la capacité grandement améliorées de la nouvelle routine de modélisation thématique par analyse factorielle seront probablement appréciées par ceux qui recherchent des solutions thématiques optimales et stables.
2.Suggestions améliorées sur la page Fréquences
Le panneau Suggestions dans les versions précédentes de WordStat affichait des synonymes, antonymes et mots apparentés pour les langues pour lesquelles un thésaurus était disponible. Il présentait également des mots commençant par les mêmes lettres initiales, permettant d’identifier certaines fautes d’orthographe ainsi que des mots apparentés. Une nouvelle section Mots associés récupère maintenant du corpus textuel d’autres mots sémantiquement, syntaxiquement et statistiquement liés au(x) mot(s) sélectionné(s) dans le tableau de fréquences. Cette nouvelle fonctionnalité devrait fonctionner dans n’importe quelle langue. Les entrées seront listées, par défaut, dans l’ordre décroissant de pertinence. Les synonymes, antonymes et mots apparentés seront également triés dans l’ordre décroissant de pertinence, facilitant l’identification de suggestions appropriées. Il est toujours possible de trier ces entrées alphabétiquement ou dans l’ordre décroissant de fréquence. De plus, une nouvelle option de filtrage par fréquence permet de filtrer les suggestions de faible fréquence, permettant de se concentrer sur les suggestions plus fréquentes.
Puisque cette nouvelle façon d’extraire les mots apparentés et d’ordonner les suggestions est indépendante de la langue, elle sera particulièrement utile pour les personnes analysant des langues pour lesquelles il n’existe pas de thésaurus. Cependant, nous avons constaté que même lorsque de telles ressources linguistiques sont disponibles, les suggestions supplémentaires basées sur l’usage contextuel des mots, et le tri des synonymes et mots apparentés existants par pertinence devraient grandement faciliter l’identification d’éléments appropriés.
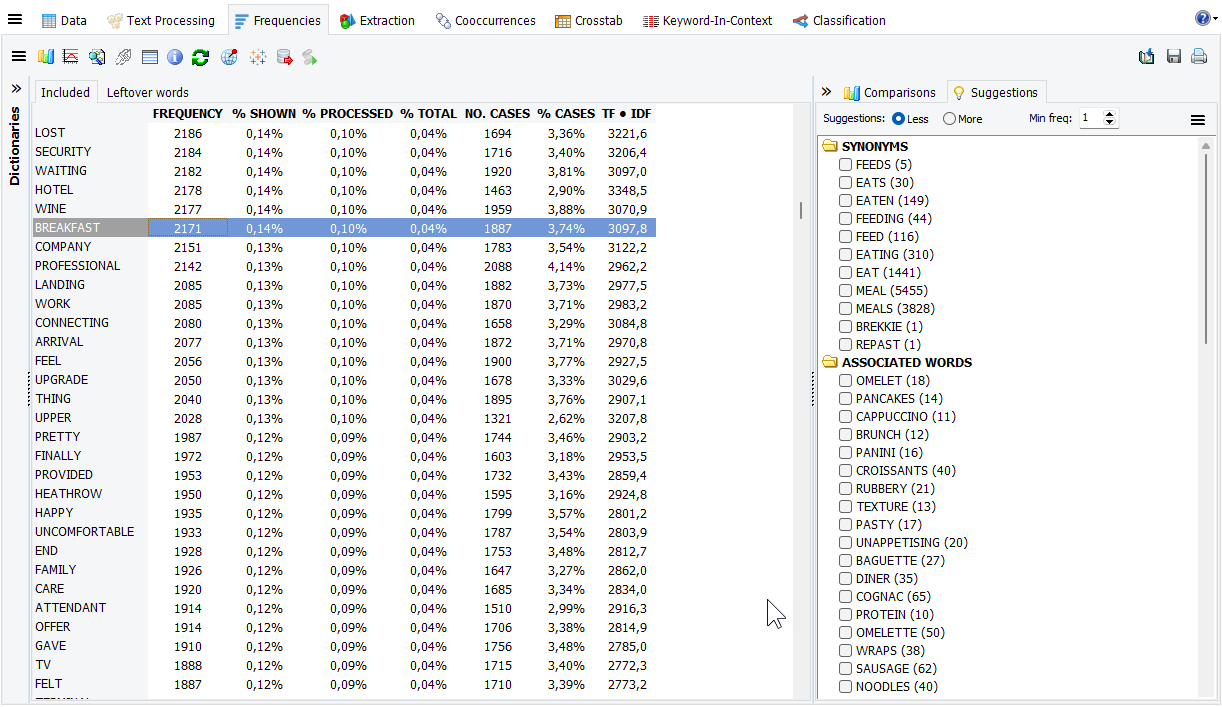
3. Nouvel onglet de suggestions pour la routine d’extraction des expressions
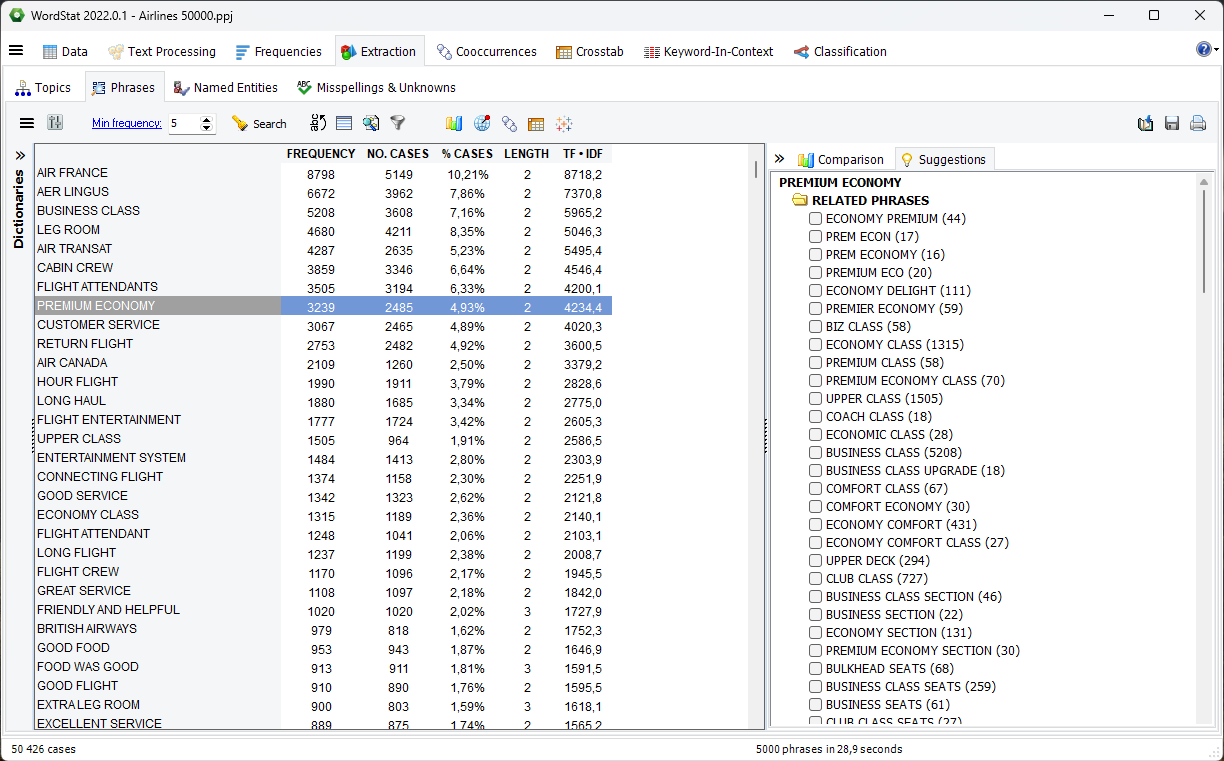
Le panneau Chevauchement a été remplacé par un panneau Suggestions, affichant les expressions sémantiquement, syntaxiquement ou statistiquement liées à la ou aux ligne(s) sélectionnée(s) dans la table de fréquence des expressions, en plus des expressions qui se chevauchent. Cette fonctionnalité est également indépendante de la langue.
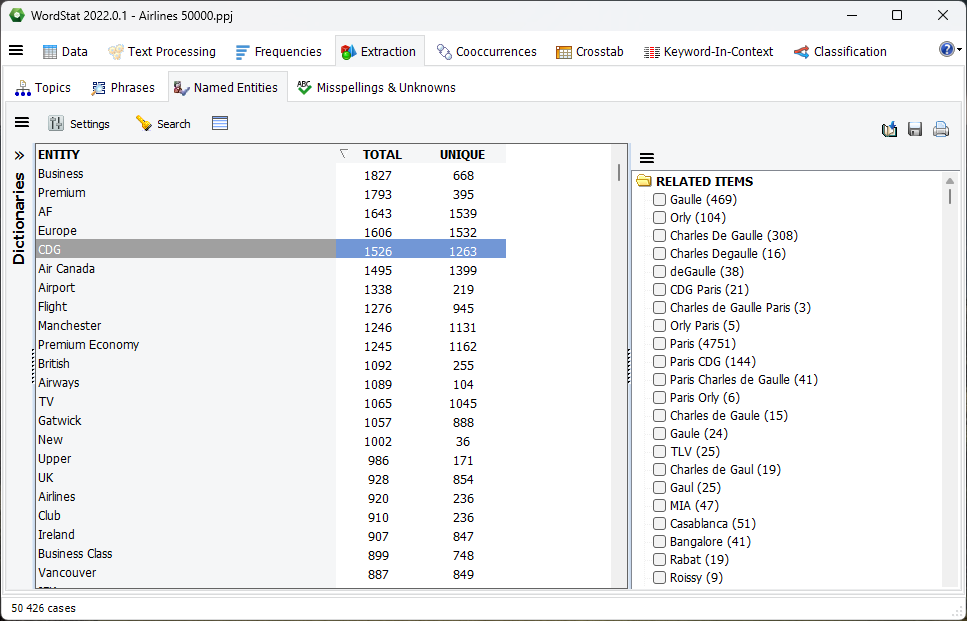
4. Amélioration de la reconnaissance d’entités nommées
Un nouveau panneau Connexes a été ajouté à la page Reconnaissance d’entités nommées. Sélectionner une seule entité nommée apportera des entités nommées connexes, ainsi que celles appartenant à la même classe (personnes, lieu, organisation, etc.). Sélectionner plus d’un exemple d’une classe spécifique (par exemple, plusieurs villes) récupérera également plus d’éléments appartenant à cette classe. Un menu contextuel permet également de déplacer tout élément vers le dictionnaire de catégorisation ou vers la liste d’exclusion. Une recherche de mots-clés en contexte peut également être effectuée sur les suggestions sélectionnées.
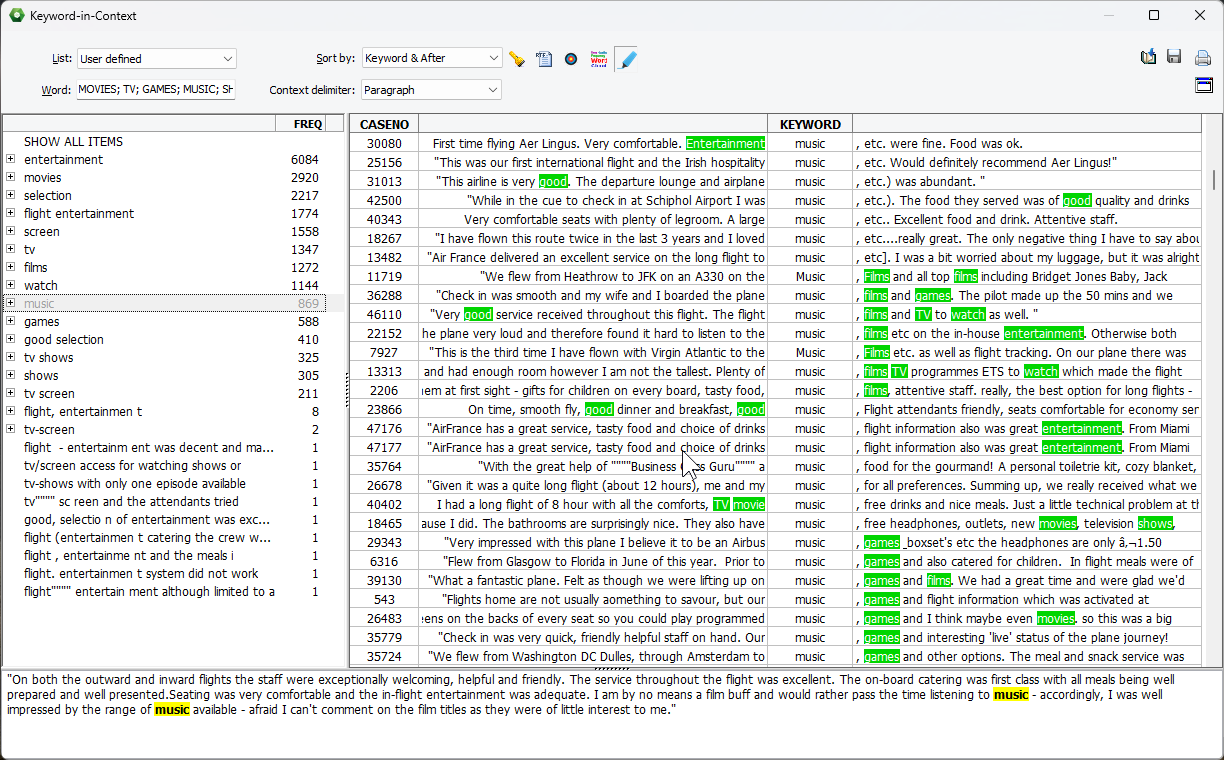
5. Mise en relief des mots contextuels dans les tables mot-clé-en-contexte.
Une nouvelle fonctionnalité de mise en évidence permet de spécifier une liste de mots et d’expressions à rechercher dans le contexte environnant du mot. Cette liste est automatiquement peuplée lorsque la liste KWIC est appelée depuis la modélisation de sujets ou depuis le dendrogramme.
6. Filtrage des éléments dans les graphiques de correspondance sur la fréquence ou la distance de l’origine
Les graphiques d’analyse des correspondances contenant plus de quelques centaines d’éléments peuvent générer une zone sombre d’éléments superposés au centre du graphique (l’origine).
Un nouveau curseur de contrôle a été ajouté pour masquer les éléments qui sont soit moins fréquents, soit proches de cette origine. À moins de vouloir identifier ce qui est commun à toutes les classes d’une variable indépendante, les éléments les plus intéressants sont ceux qui sont éloignés de l’origine, car ce sont eux qui caractérisent les différentes classes. Filtrer ces éléments permet d’identifier plus facilement les éléments différenciateurs.
7. Récupération de mots-clés améliorée
Les résultats d’une recherche par mots-clés sont maintenant triés dans l’ordre décroissant de pertinence, prenant en considération à la fois la fréquence et la variété des éléments correspondants en relation avec la longueur du segment de texte récupéré. Une nouvelle colonne de fréquence peut également être utilisée pour trier uniquement sur les fréquences.
8. Calcul d’une variable chaîne par concaténation
Une nouvelle commande de transformation de données permet de calculer une variable chaîne en concaténant les valeurs de plusieurs variables existantes (nombres, chaînes, dates, etc.) ainsi que du texte saisi. Une telle procédure peut également être utilisée pour initialiser une variable chaîne avec une valeur de chaîne constante.
9. Paramètres de graphique de comparaison persistants
Le type de graphique et les statistiques ainsi que la palette de couleurs de ces graphiques de comparaison sont maintenant liés au nom de la variable et sont stockés dans les paramètres du projet. Ces options devraient rester constantes d’une page à l’autre (fréquences, expressions, modélisation thématique, dendrogramme, etc.) et entre les sessions, réduisant le besoin de réajuster constamment ces options.
Introduit dans la Version 9.0
1. Prise en charge complète Unicode
Nous essayons toujours de sélectionner des techniques d’analyse de texte indépendantes de la langue. Cela a permis aux utilisateurs d’analyser des données textuelles dans plus de 50 langues. Cependant, pour analyser des langues non prises en charge par leur installation Windows par défaut, l’utilisateur devait modifier certains paramètres Windows. Et bien qu’il soit possible d’analyser des jeux de données dans plusieurs langues, certaines combinaisons de langues n’étaient tout simplement pas possibles. La nouvelle version Unicode de WordStat permet d’analyser n’importe laquelle d’entre elles sans aucun changement de paramètres ainsi que de nouvelles langues précédemment non prises en charge telles que le chinois, le japonais ou le thaï. Des routines de segmentation de mots pour les trois langues asiatiques précédentes ont également été ajoutées.

2. Integration of R and Python Pre- and Post-Processing Scripts
En 2018, nous avons introduit la possibilité de créer des scripts de prétraitement Python pour WordStat 8. La version 9.0 étend cette capacité en offrant la possibilité de créer des scripts de prétraitement en R également. Plus important encore, il est maintenant possible de créer des scripts de post-traitement dans ces deux langages de programmation permettant d’effectuer une analyse personnalisée sur les données textuelles originales ou transformées ou sur les résultats quantifiés obtenus grâce à l’analyse de contenu sur ces documents. Une telle fonctionnalité offre des possibilités infinies pour étendre les fonctionnalités de WordStat telles que l’implémentation de nouveaux algorithmes d’apprentissage automatique, des techniques de modélisation statistique avancées, ou une transformation de données personnalisée. Des scripts d’exemple ont été inclus pour calculer les métriques de lisibilité du texte, détecter les langues, appliquer d’autres techniques de modélisation thématique (LDA ou STM) ou créer des modèles prédictifs utilisant l’apprentissage automatique (SVM, kNN, etc.).
![]()

3. Correction orthographique automatique
Un nouveau moteur de vérification orthographique a été écrit à partir de zéro pour obtenir des corrections orthographiques beaucoup plus rapides et plus précises, permettant l’implémentation d’une fonctionnalité de correction orthographique automatique avec un impact minimal sur la vitesse de traitement de texte existante de WordStat. La correction orthographique intelligente peut même corriger l’orthographe de termes inconnus tels que les vocabulaires techniques, les noms propres, etc. Les résultats peuvent être automatiquement sauvegardés dans la liste de substitution pour révision et corrections.
4. Tableaux croisés avec panneaux de graphiques et filtrage
La page de tableaux croisés inclut maintenant un panneau de graphiques permettant de tracer rapidement la distribution des lignes sélectionnées du tableau de tableaux croisés pour les valeurs de la variable actuellement sélectionnée ou de toute autre variable. Une liste de filtrage permet également d’analyser de telles distributions pour une seule valeur ou un ensemble de valeurs de la variable sélectionnée.
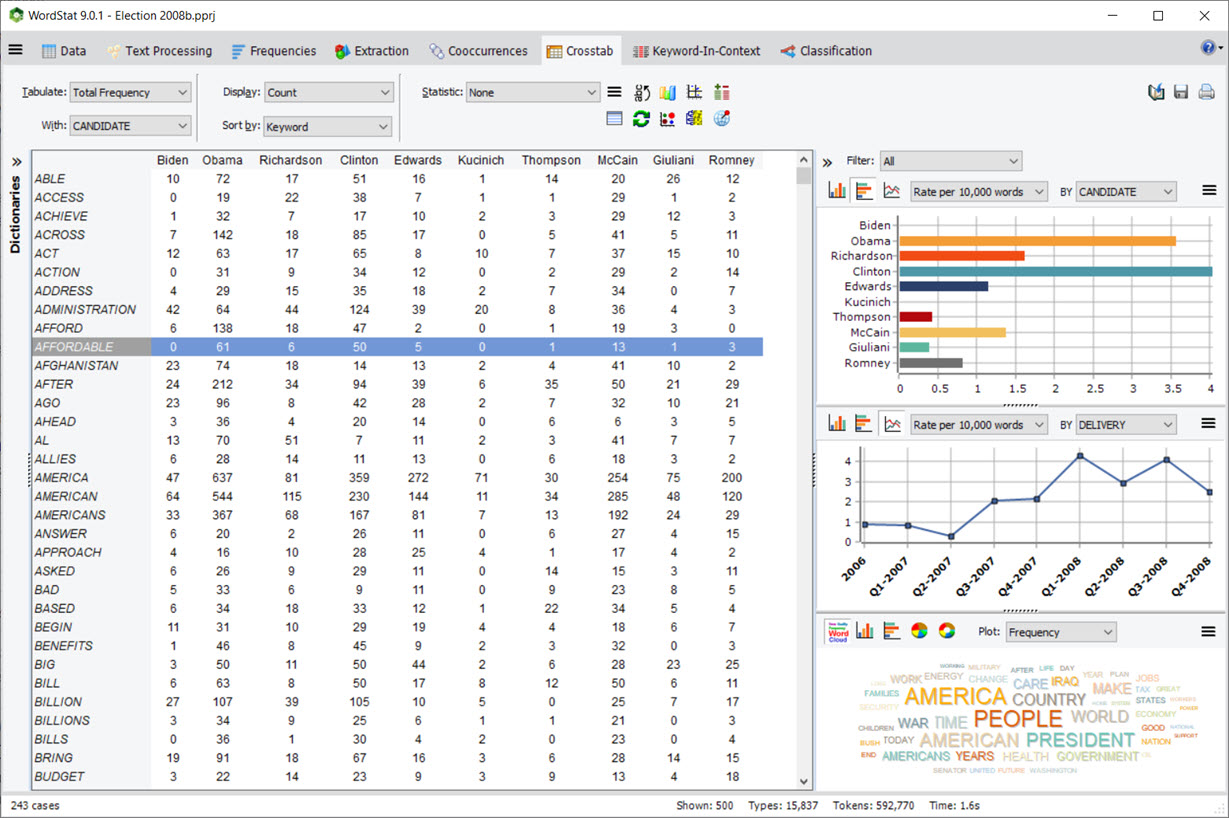
5. Matrice de co-occurrence interactive
Une nouvelle fonctionnalité de matrice interactive a été ajoutée à la page de co-occurrences permettant de se concentrer sur des co-occurrences spécifiques. Les résultats principaux consistent en un tableau affichant un choix parmi diverses statistiques de co-occurrence. Cette matrice est également hautement interactive permettant de transformer des lignes spécifiques en nouvelles colonnes ou vice versa en utilisant de simples opérations de glisser-déposer. Un panneau de graphiques à gauche permet également d’évaluer la distribution d’une co-occurrence spécifique à travers d’autres variables. On peut également obtenir une vue rapide de tous les segments de texte associés à une co-occurrence spécifique. Cette nouvelle fonctionnalité de WordStat peut également être appelée depuis la liste de fréquences en sélectionnant les éléments cibles (mots ou catégories de contenu) qui devraient être affichés comme colonnes, en cliquant avec le bouton droit, et en sélectionnant Matrice de co-occurrence.
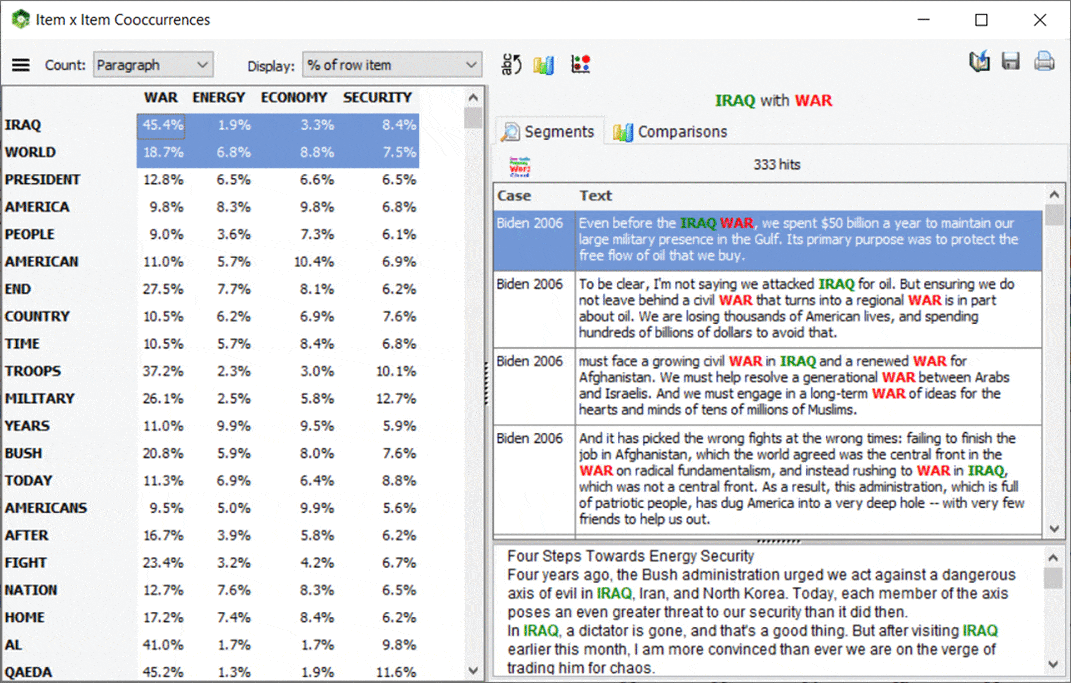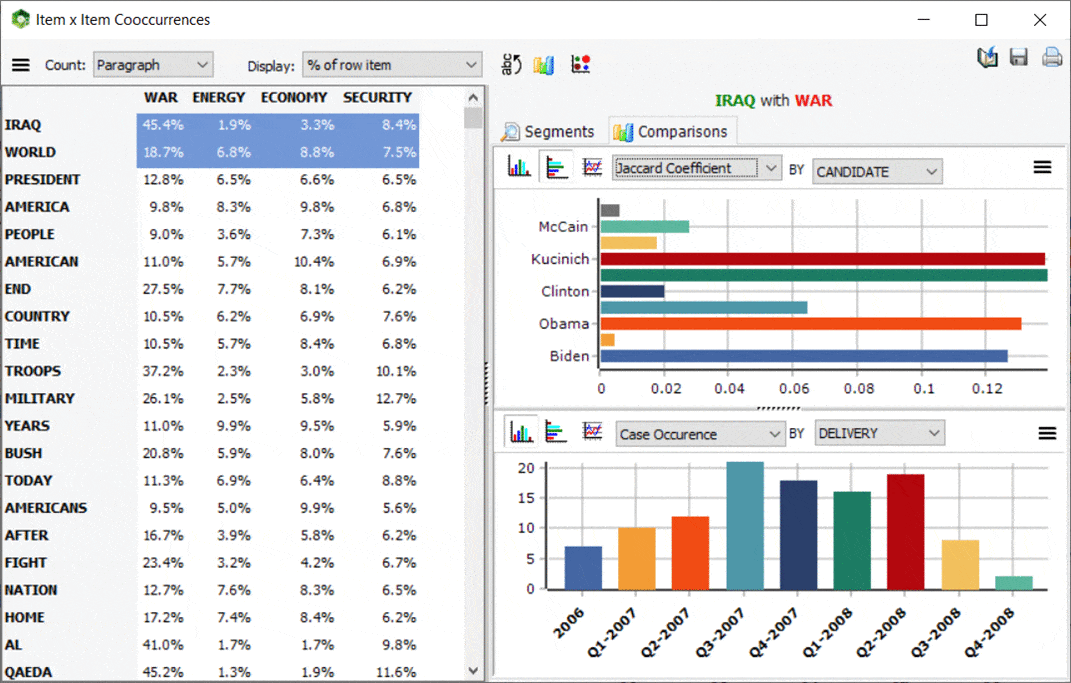
6. Importation de fichiers Nexis UNI et Factiva
Introduite dans QDA Miner 6.0 en 2020, il est maintenant également possible dans WordStat d’importer des transcriptions de nouvelles à partir des fichiers de sortie LexisNexis et Factiva. Après avoir sélectionné un ou plusieurs fichiers .DOCX ou RTF obtenus de ces services, WordStat extraira et stockera dans des variables séparées le titre et le corps de la transcription de nouvelles, sa source, la date de publication, et d’autres informations pertinentes. Une telle fonctionnalité devrait s’avérer utile pour la gestion de réputation, la gestion de marque, la communication de crise, l’analyse de cadrage médiatique, les études médiatiques comparatives, etc.

7. Traitement par lots des modèles thématiques
Choisir le nombre de sujets à extraire en utilisant des techniques de modélisation thématique reste une question pour laquelle il n’y a, à notre connaissance, pas de réponse définitive. Nous pouvons même soulever des doutes quant à savoir si un tel nombre optimal existe. En fait, on peut même suggérer que l’information obtenue en utilisant différents paramètres peut bien servir différents objectifs ou révéler différents aspects d’une réalité. Dans un tel contexte d’incertitude, les chercheurs veulent souvent comparer diverses solutions. La nouvelle fonctionnalité de traitement par lots permet de calculer plusieurs modèles thématiques en variant systématiquement le nombre de sujets à extraire, et pour la méthode probabiliste (ex. NNMF), d’effectuer plusieurs exécutions en utilisant les mêmes paramètres afin d’évaluer la stabilité des résultats. Toutes les solutions de modèles thématiques sont temporairement agrégées dans le gestionnaire de rapports permettant de comparer les solutions obtenues dans plusieurs exécutions utilisant différents paramètres.
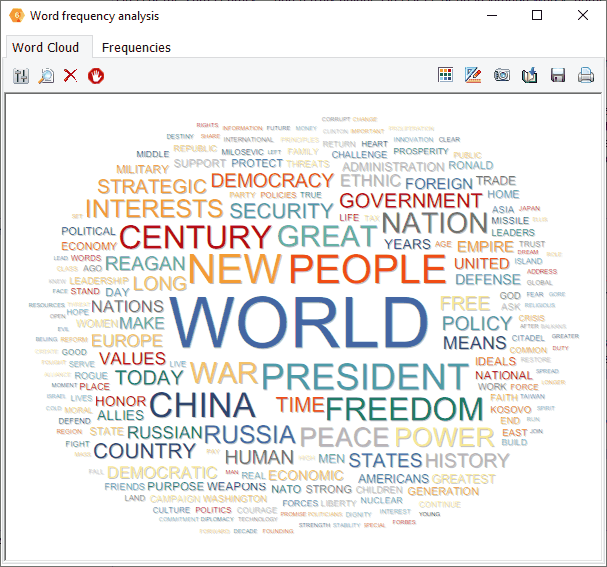
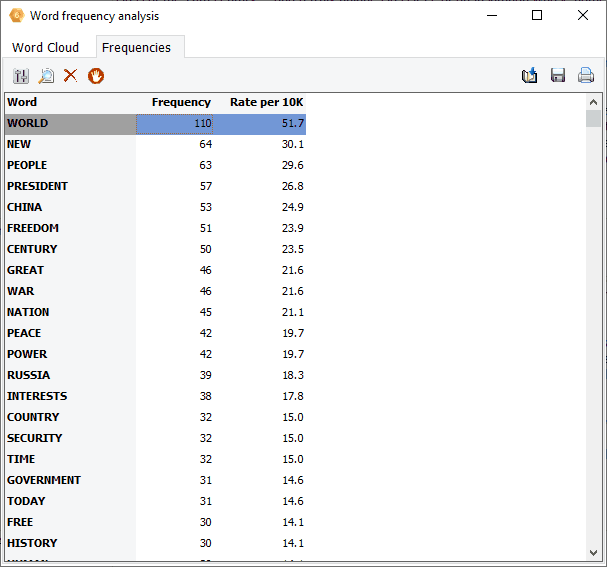
8. Créer des nuages de mots sur les récupérations de mots-clés et les résultats KWIC
Les nuages de mots interactifs et les tableaux de fréquence des mots peuvent maintenant être obtenus directement sur les résultats de récupération de mots-clés et de mots-clés en contexte (KWIC) permettant d’identifier rapidement les mots associés à des catégories de contenu spécifiques, ou ceux apparaissant avant, après un élément cible spécifique.
9. Règles de proximité plus puissantes
Le nombre de conditions dans les règles de proximité a été augmenté de quatre à un maximum de vingt conditions. Si vous croyez que ce n’est pas suffisant, faites-le nous savoir.
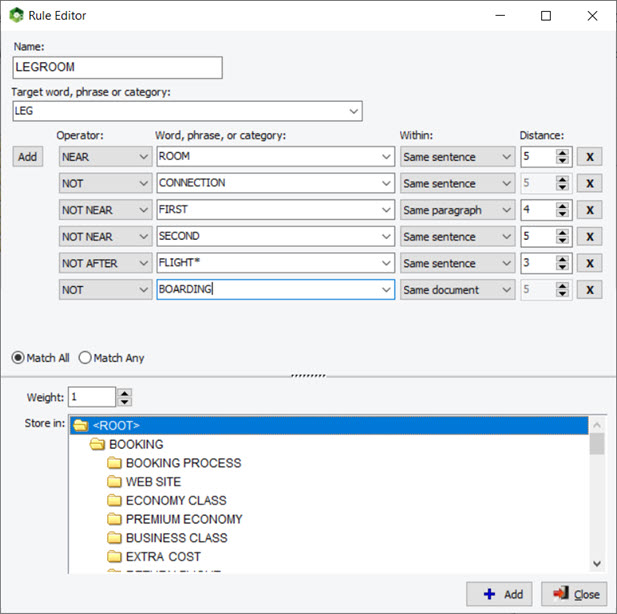
10. Aperçu de l’effet des caractères génériques et des interactions de dictionnaire
L’utilisation de caractères génériques dans un dictionnaire est assez puissante mais potentiellement problématique puisqu’elle pourrait correspondre à des éléments auxquels vous n’avez peut-être pas pensé. Par exemple, une entrée comme TAX* peut vous permettre de correspondre à TAX, TAXES, TAXATION, mais correspondra également à des mots tels que TAXI, TAXONOMY, TAXIDERMY, etc. De plus, les règles de WordStat pour faire correspondre les éléments et empêcher le double comptage peuvent également produire des résultats inattendus causés par d’autres entrées dans votre modèle de catégorisation. Un nouveau panneau à droite des pages d’exclusion et de catégorisation vous permet d’identifier facilement les nouvelles entrées qui correspondraient en utilisant un *caractère générique à la fin d’un mot mais aussi de possibles conflits avec d’autres entrées dans votre dictionnaire.
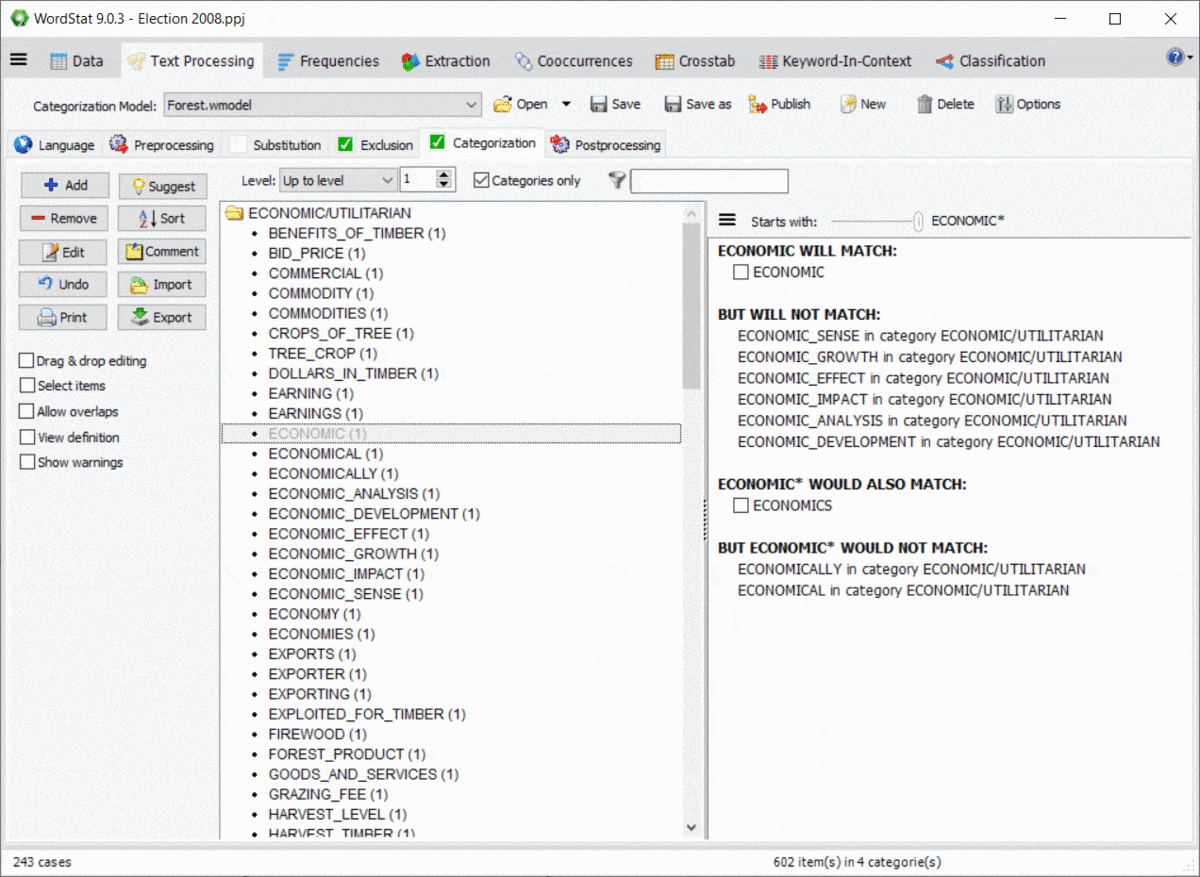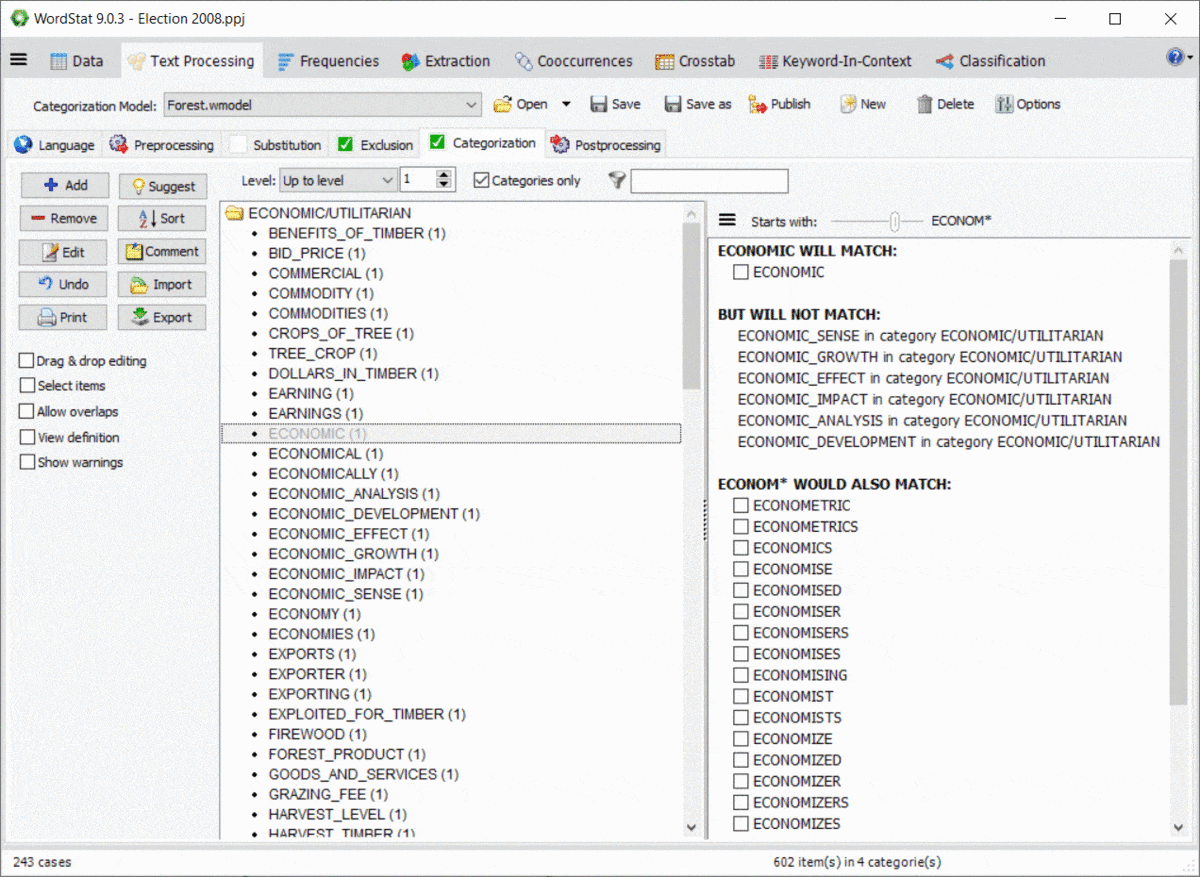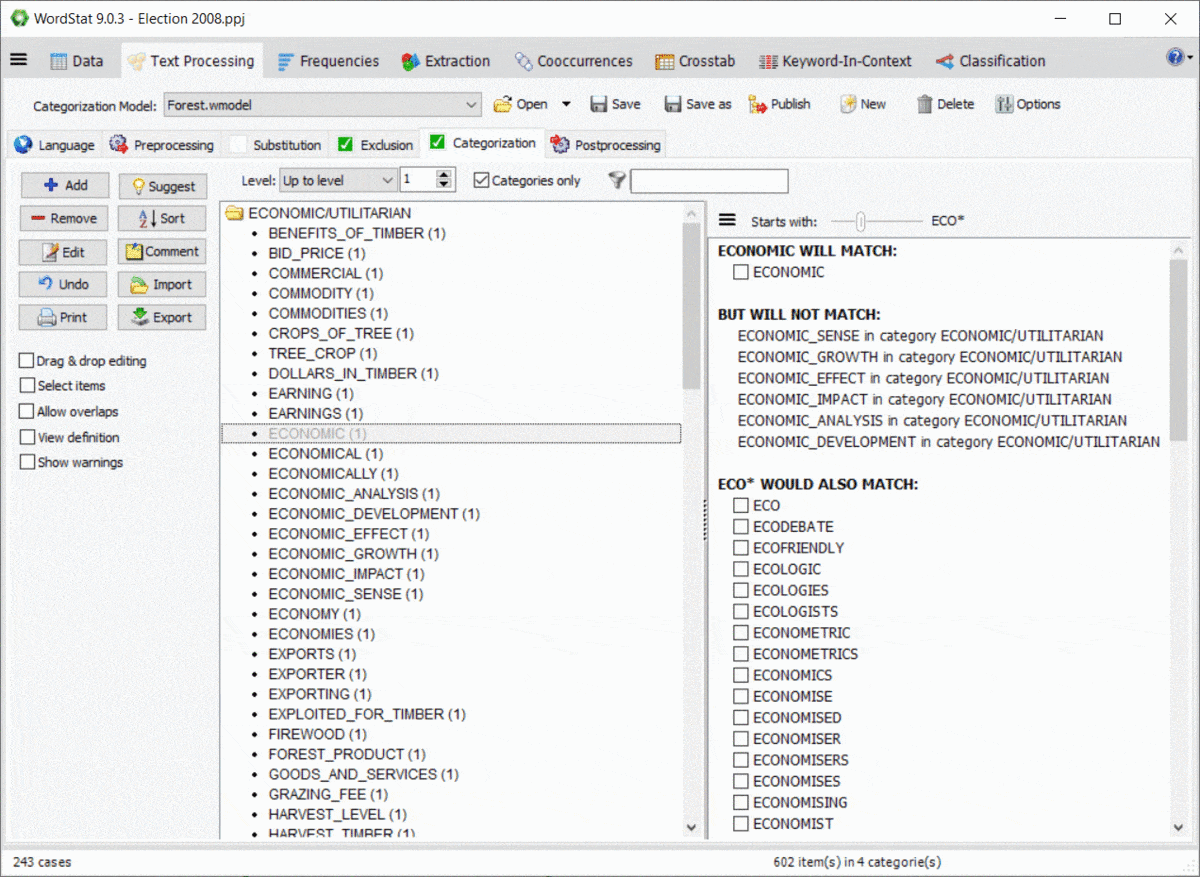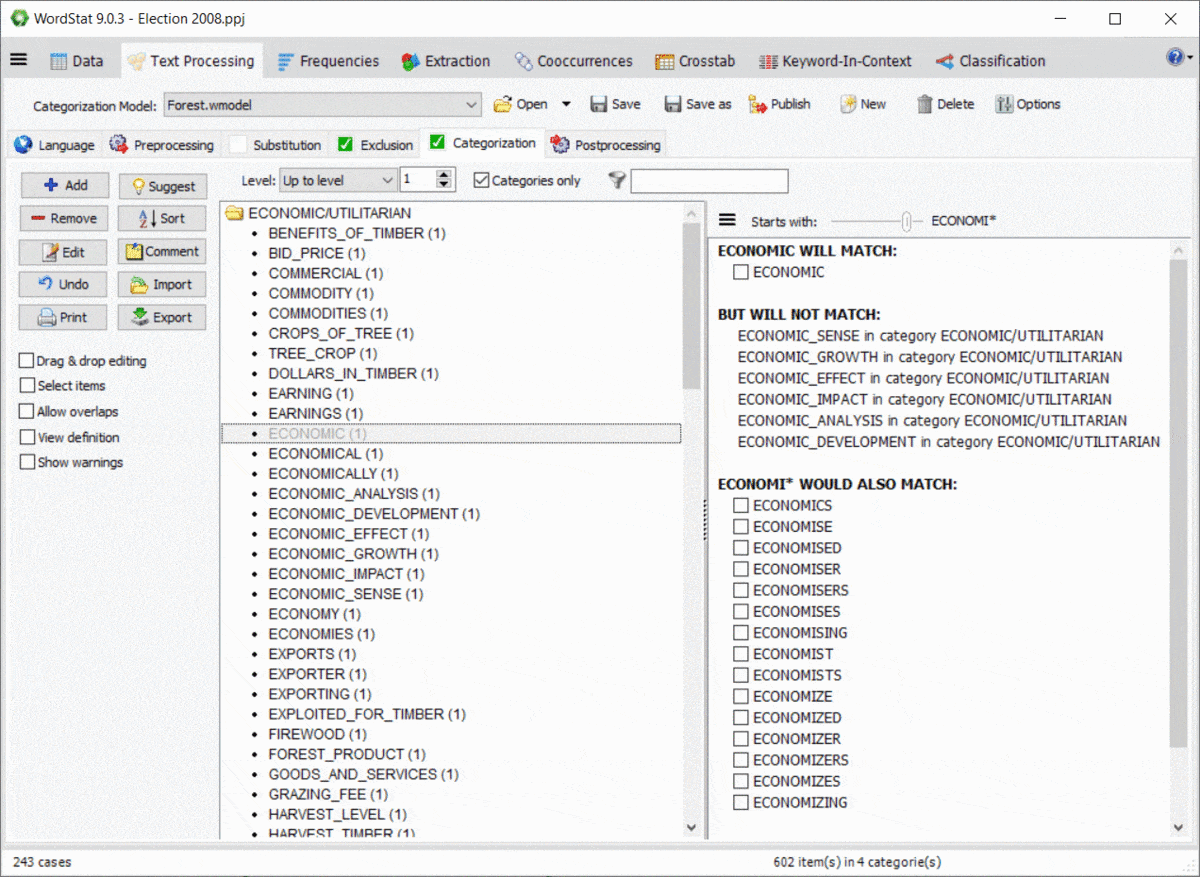
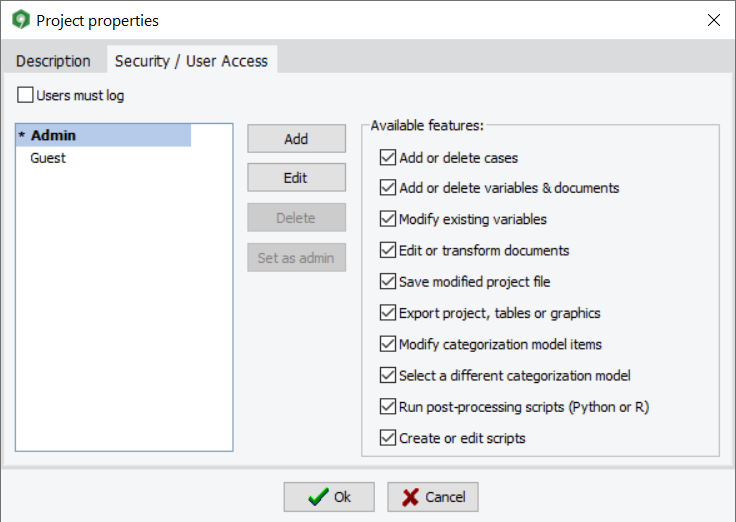
11. Protection par mot de passe des fichiers de projet
WordStat 9.0 offre maintenant la possibilité de protéger par mot de passe les fichiers de projet, restreignant l’accès de projets spécifiques aux utilisateurs autorisés. Une boîte de dialogue permet à l’administrateur du projet de créer de nouveaux comptes d’utilisateur et de spécifier quelle opération chaque utilisateur peut effectuer. On peut limiter l’édition de données, l’importation de données, ou la transformation, ainsi que l’exportation des données de projet, des tableaux et des graphiques. Alternativement, vous pouvez choisir de laisser les utilisateurs effectuer toute transformation qu’ils veulent mais les empêcher de sauvegarder le fichier de projet.
12. Nouvelles options pour nettoyer les données
La page de prétraitement inclut maintenant des options pour supprimer automatiquement les URL des messages texte ainsi que les désignations des intervenants dans les transcriptions de nouvelles et d’entrevues.
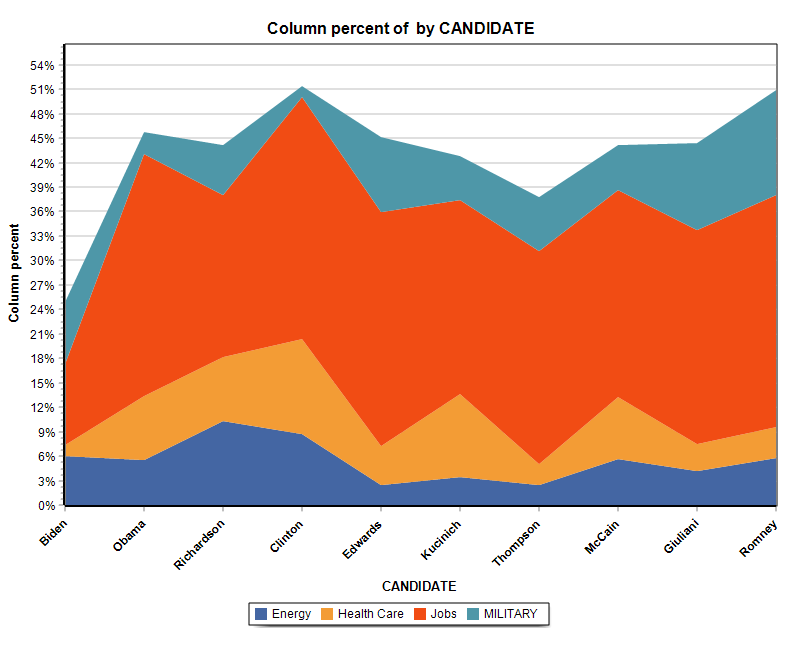
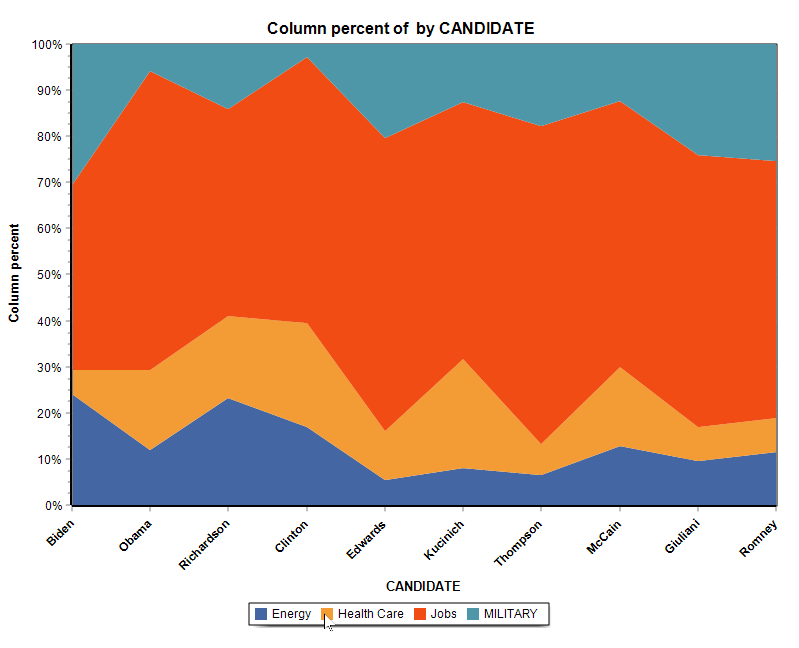
13. Nouveaux graphiques en aires empilées
La fonctionnalité de graphiques de la page Tableaux croisés ajoute la possibilité de créer deux types de graphiques en aires empilées.
14. Éléments colorés dans le graphique de correspondance
Des dégradés de couleurs peuvent maintenant être utilisés pour représenter la position d’éléments spécifiques ou de classes de variables sur la troisième dimension (profondeur) ou le graphique de correspondance 2D et 3D. Jusqu’à quatre couleurs peuvent être choisies pour créer ces dégradés.

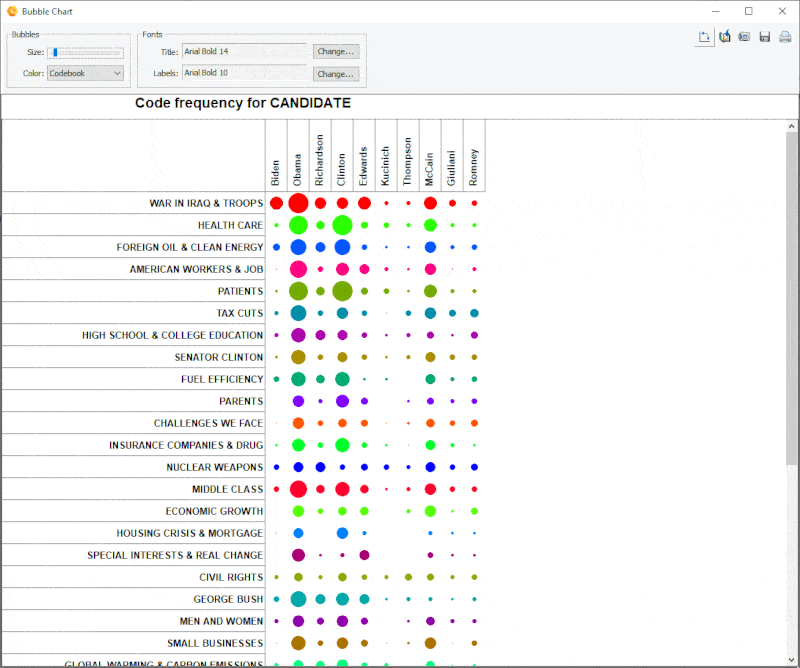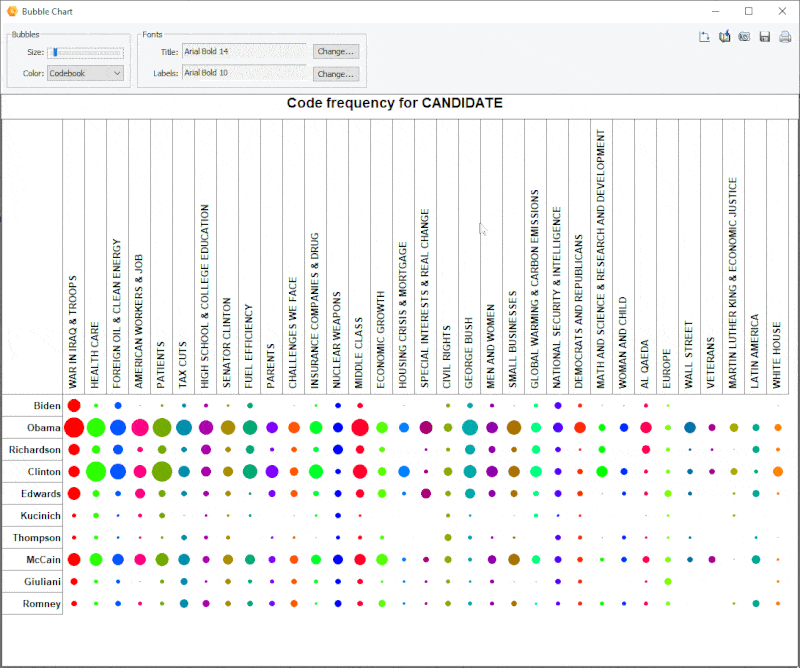
15. Graphique à bulles amélioré
Il est maintenant possible de transposer les lignes et colonnes des graphiques à bulles.
16. Tampon d’analyse de liens
Un tampon d’analyse de liens permet de revenir aux diagrammes de liens précédents puis d’avancer.
17. Enrichissement thématique plus rapide et plus précis
WordStat va au-delà de la modélisation thématique typique, offrant une fonctionnalité unique d’enrichissement thématique qui identifie les expressions associées, les exceptions potentielles et les fautes d’orthographe. Elle génère également automatiquement des noms de sujets pertinents. Avec la version 9, cette fonctionnalité d’enrichissement thématique est maintenant deux fois plus rapide qu’avant et effectue une meilleure désambiguïsation du sens des mots pour une liste plus précise d’exceptions. Elle fournit également de meilleures suggestions pour les corrections orthographiques.
18.Vitesse et précision améliorées des corrections orthographiques existantes
La fonctionnalité de correction orthographique existante est maintenant jusqu’à 30 fois plus rapide, ne nécessitant qu’une seconde ou deux pour suggérer des corrections orthographiques pour des dizaines de milliers de mots inconnus.
19. Nouveau format de fichier .PPRJ
Un nouveau format de fichier avec une nouvelle extension de fichier (.pprj) a été créé, fournissant un support amélioré pour les données Unicode. Cependant, WordStat 9 conserve la compatibilité ascendante avec les versions précédentes de tous nos logiciels et peut ouvrir et analyser les fichiers de projet actuels (.ppj) créés par QDA Miner, SimStat, ou les versions plus anciennes de WordStat.
20. Nombreuses améliorations supplémentaires
Plusieurs options supplémentaires et améliorations d’interface ont été apportées aux boîtes de dialogue existantes, aux graphiques, à la gestion des données et aux fonctionnalités d’analyse des données.
Les fonctionnalités Introduites dans WordStat 8 peuvent être consultées ici.