
Content Analysis and Text Mining features Screenshots
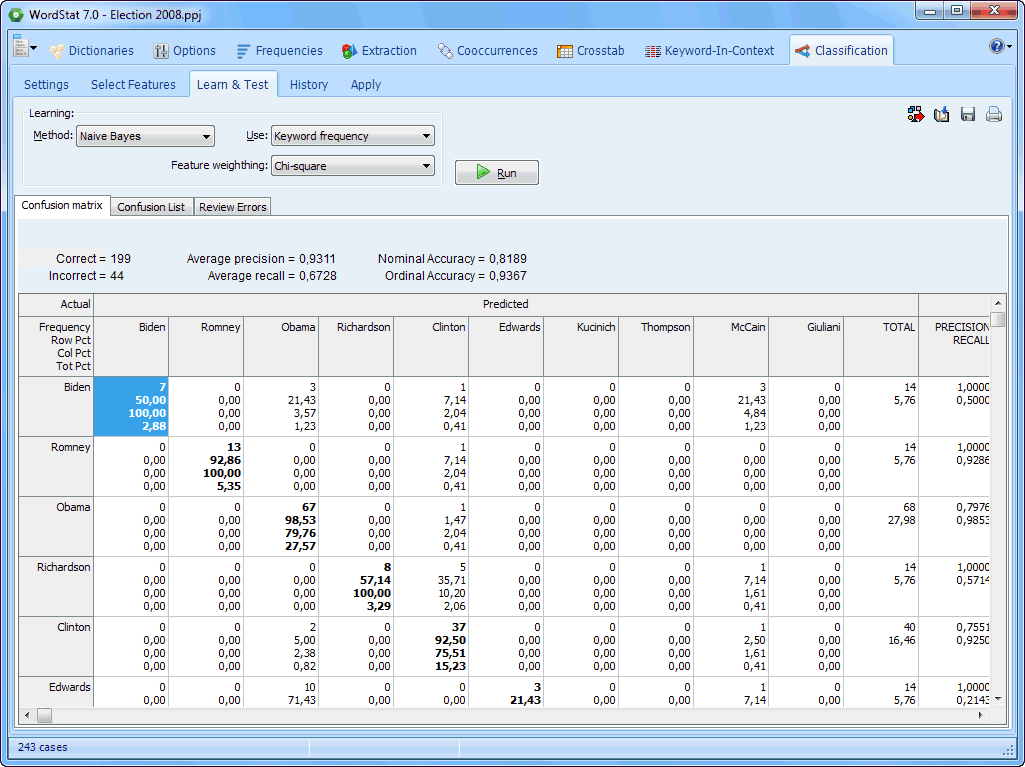 A confusion matrix is a useful tool to assess the performance of an automatic document classifier. |
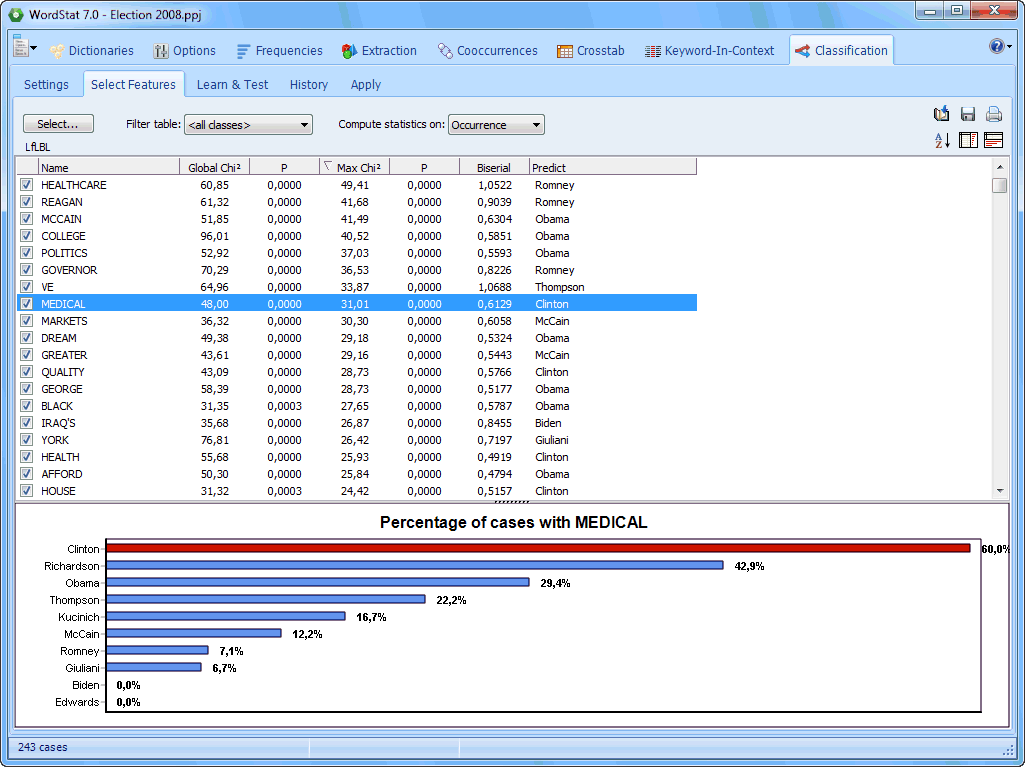 The Feature Selection page of the automatic document classification feature allows one to manually or automatically select keywords |
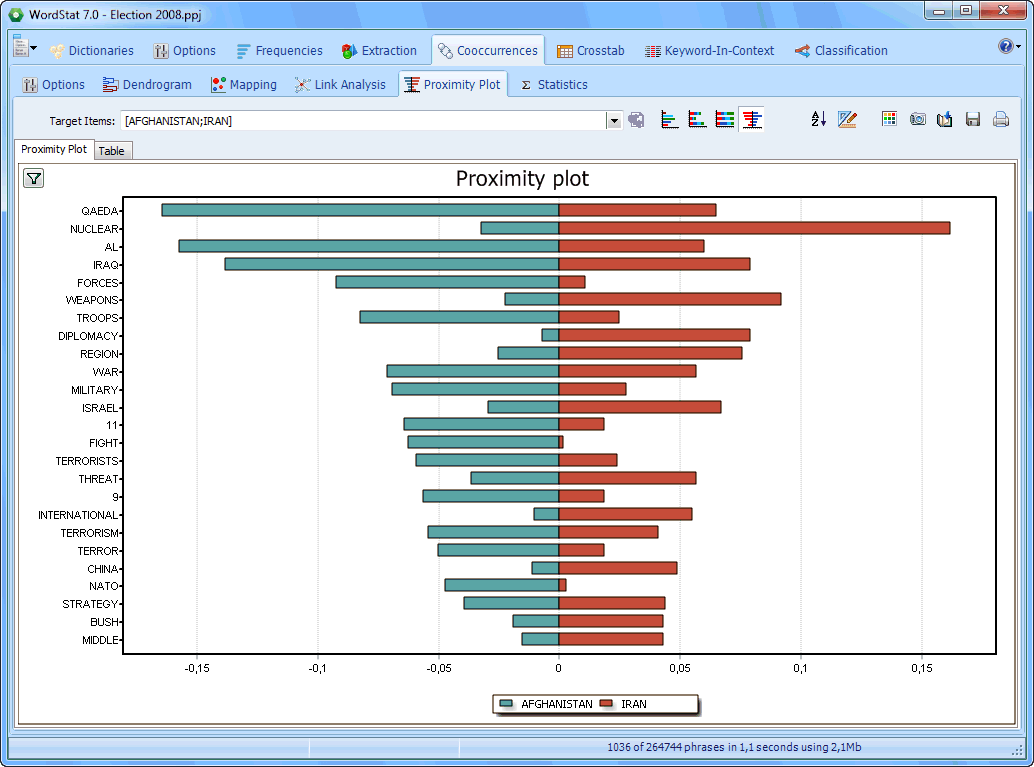 Proximity plots may be used to represent the distance from one or several target keywords to all other words |
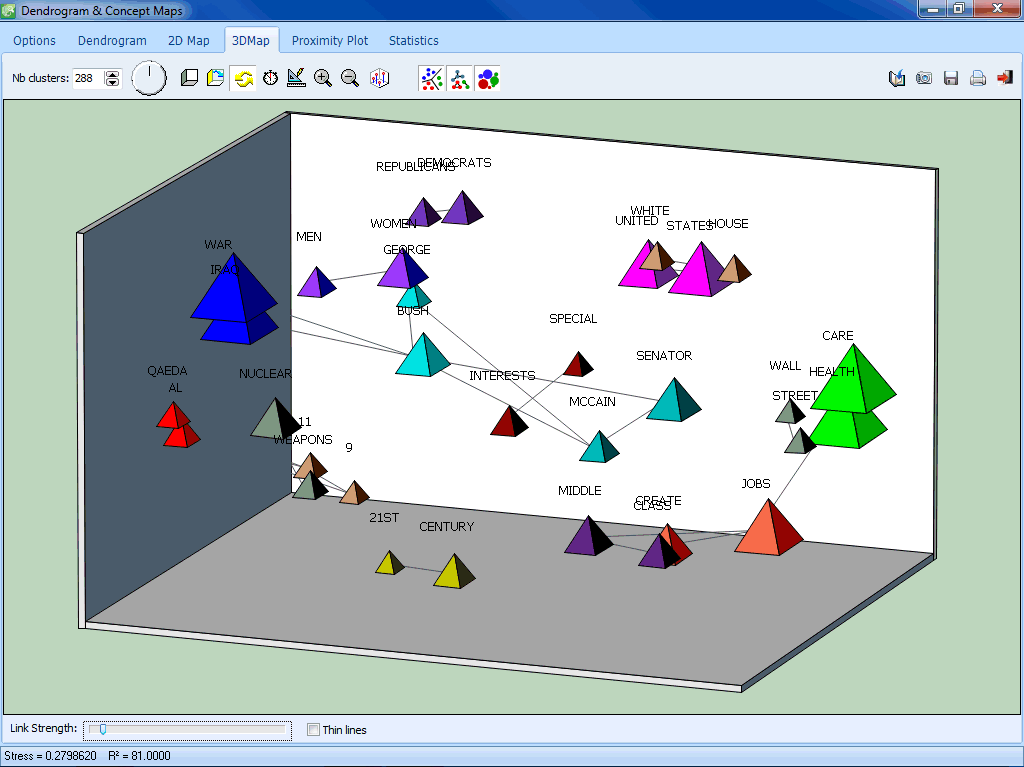 This multidimensional scaling displays lines representing the strength of association between data points. |
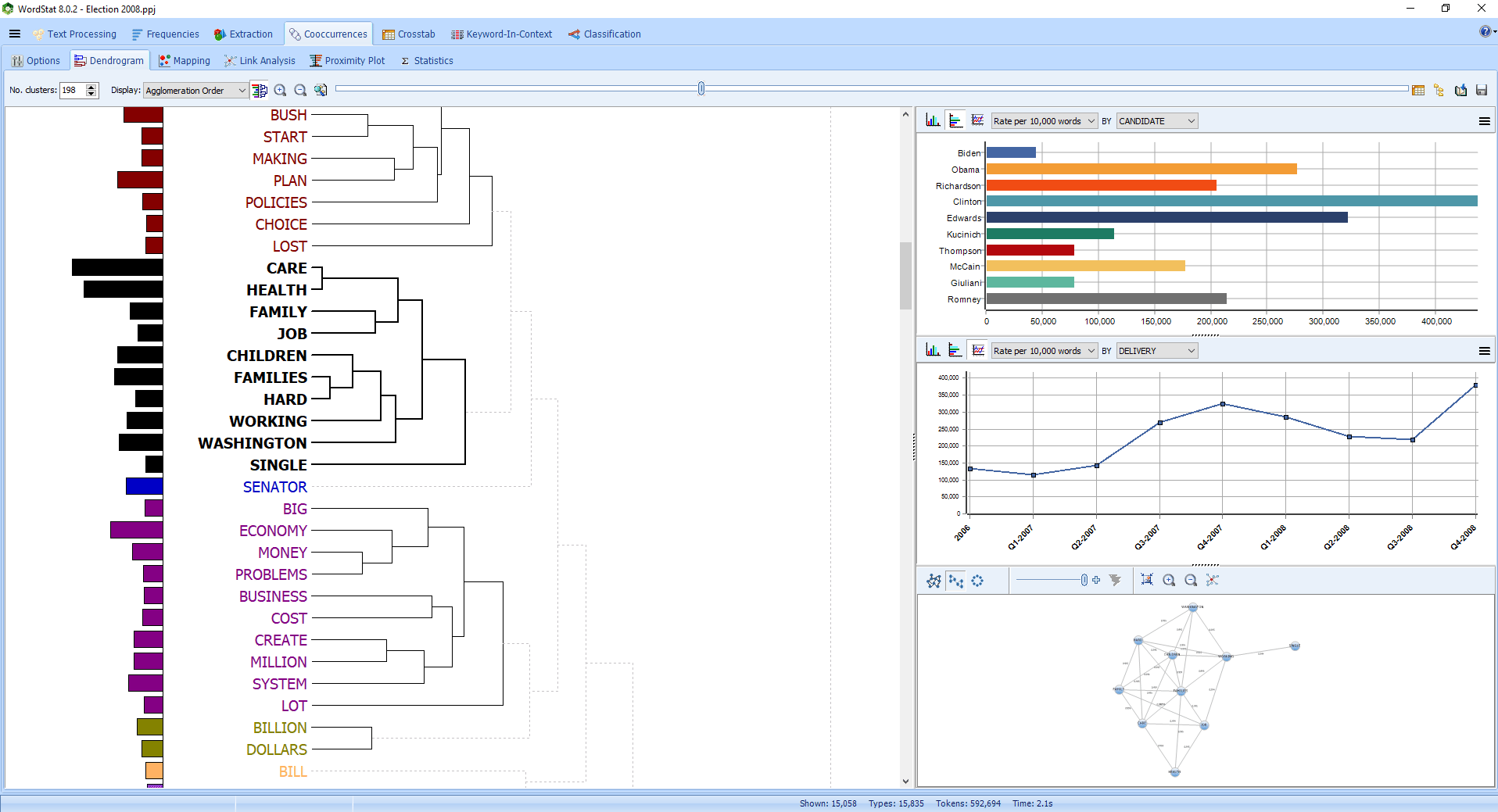 Hierarchical clustering is a useful exploratory tool to quickly identify themes or groupings of documents. |
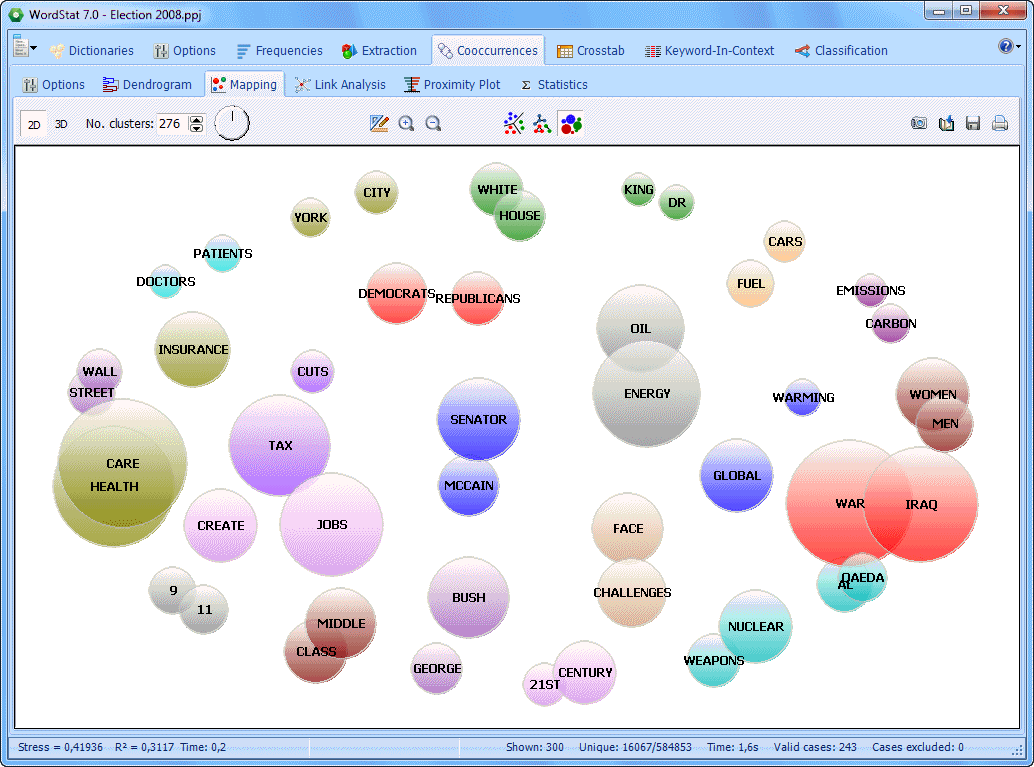 Multidimensional scaling maps may be used to represent the co-occurrence of keywords or similarity of documents |
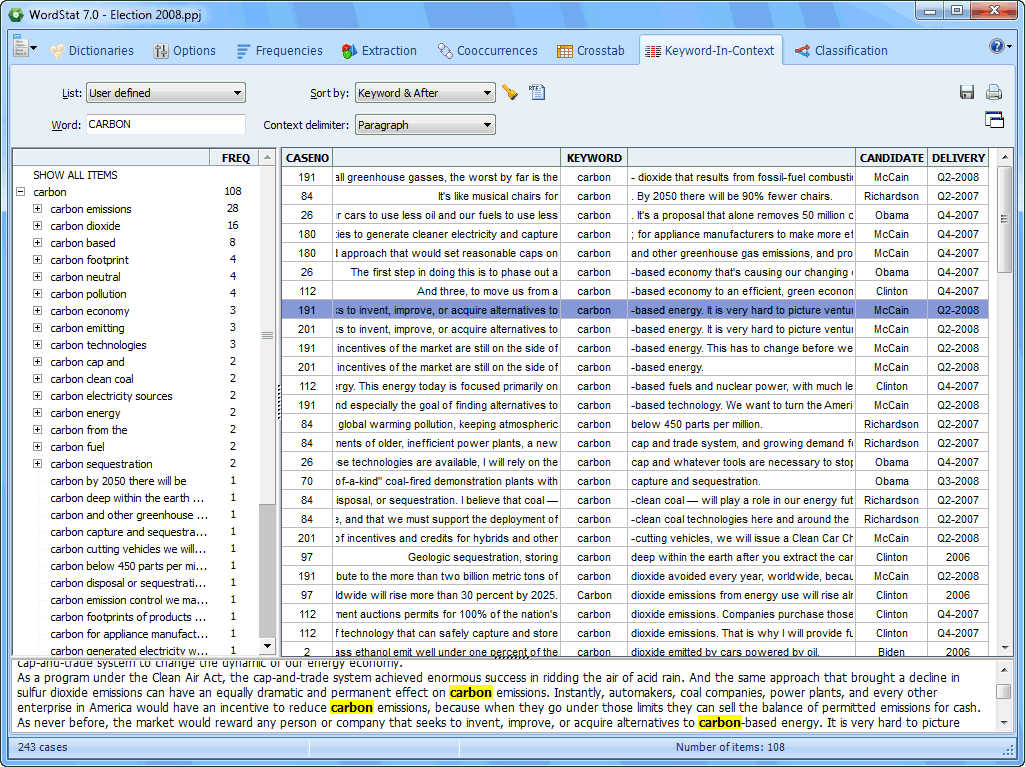 The Keyword-In-Context (or KWIC) page allows one to display the context of specific words, word patterns or phrases. |
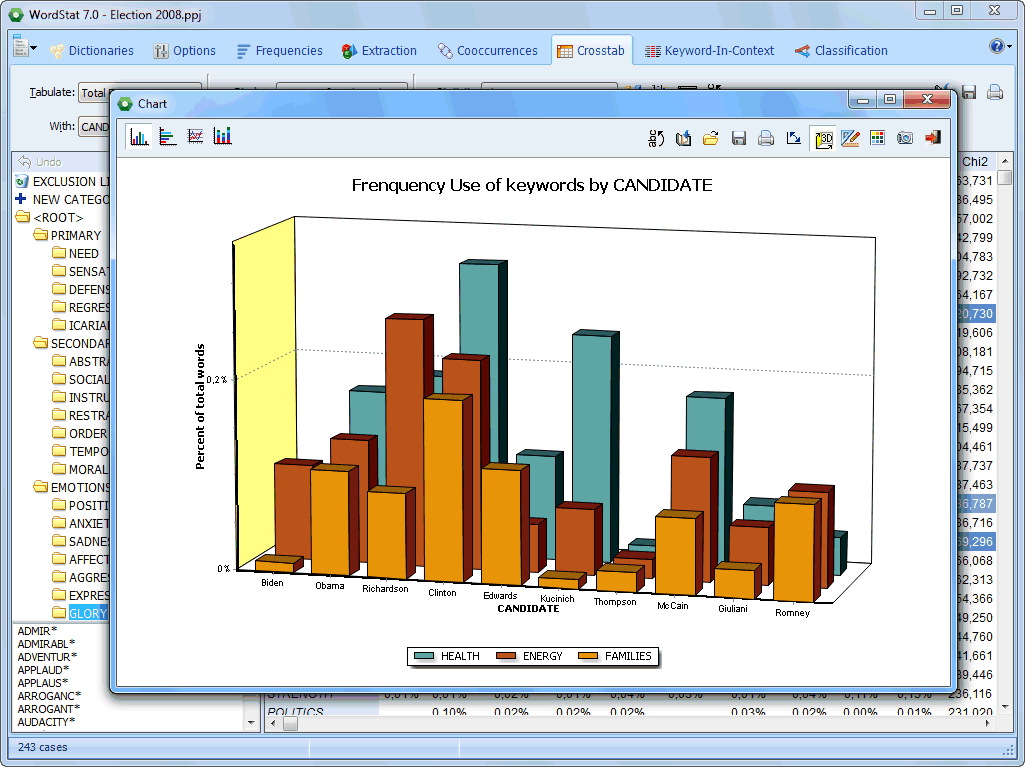 Bar charts can be used to represent codes frequencies |
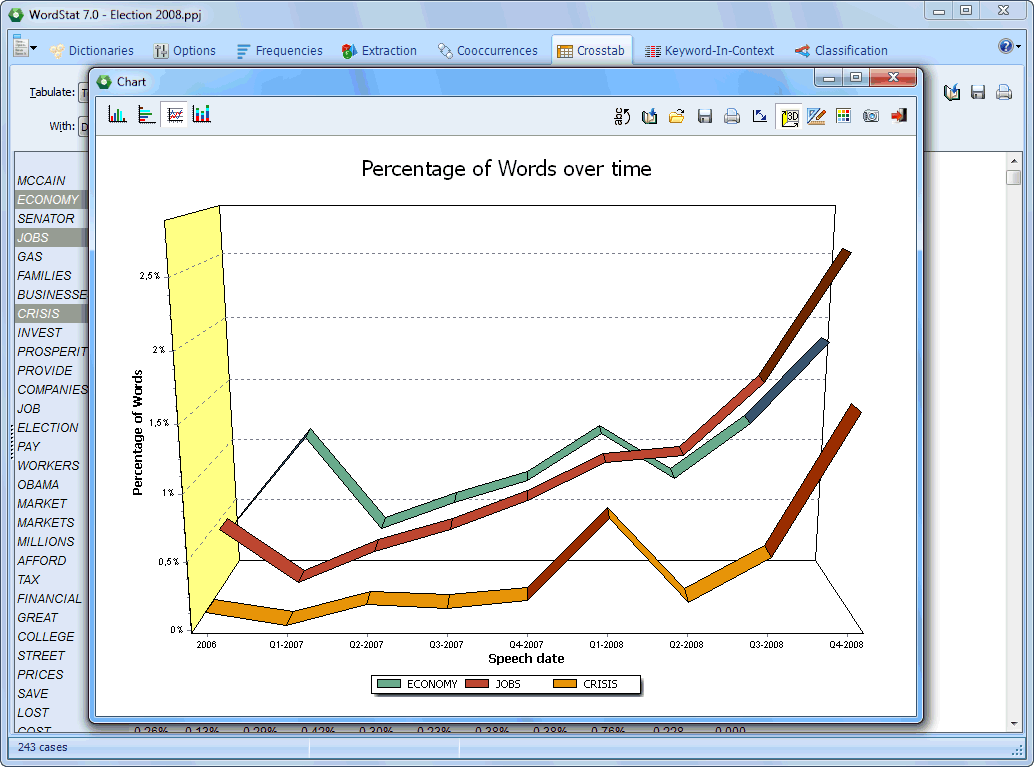 Temporal trends of content categories overtime may be plotted using line charts. |
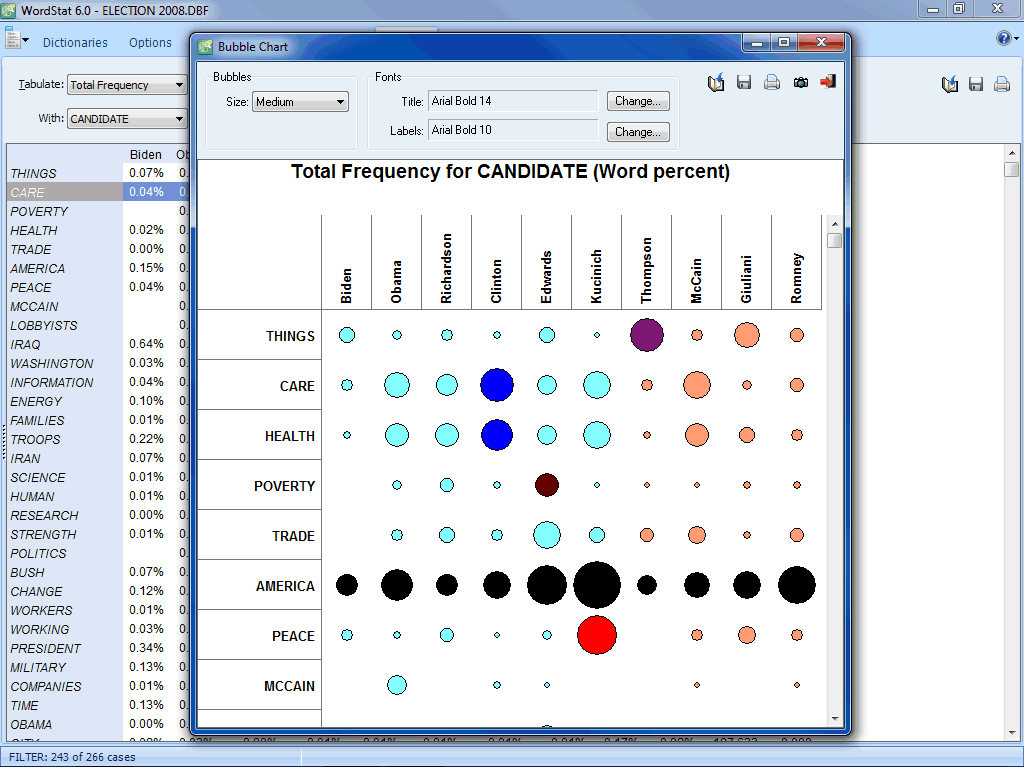 Bubble charts are graphic representations of contingency tables where relative frequencies are represented by circles of different diameters. |
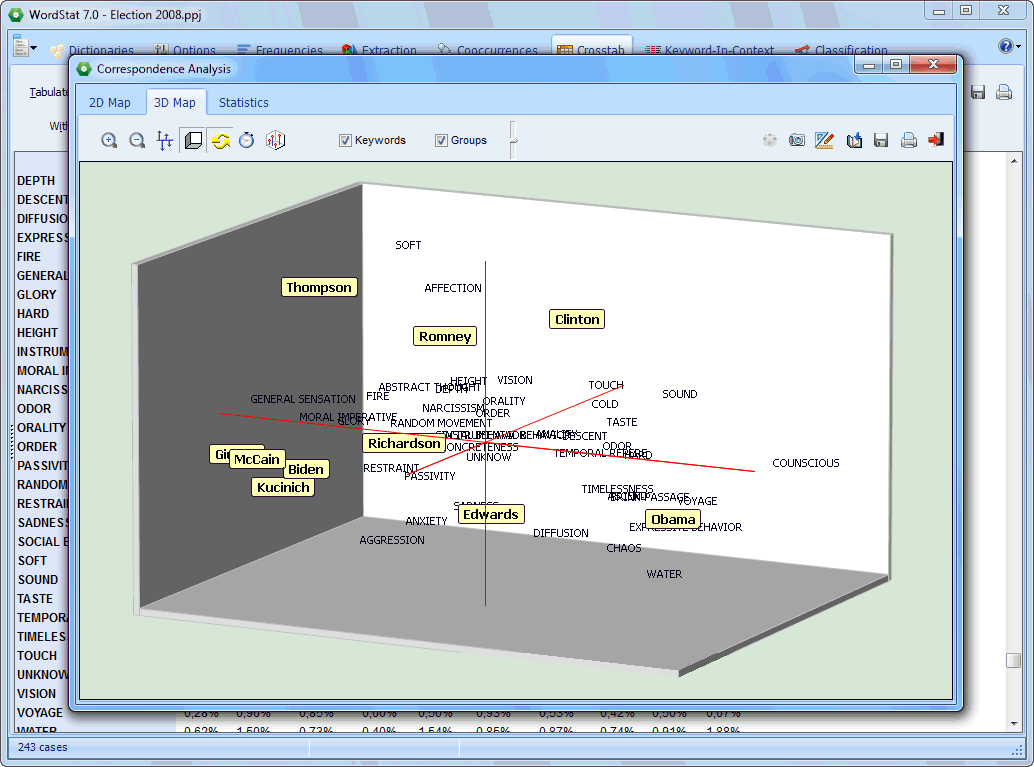 Correspondence analysis is a powerful exploratory technique to identify relationships between keywords and categorical or ordinal variables. |
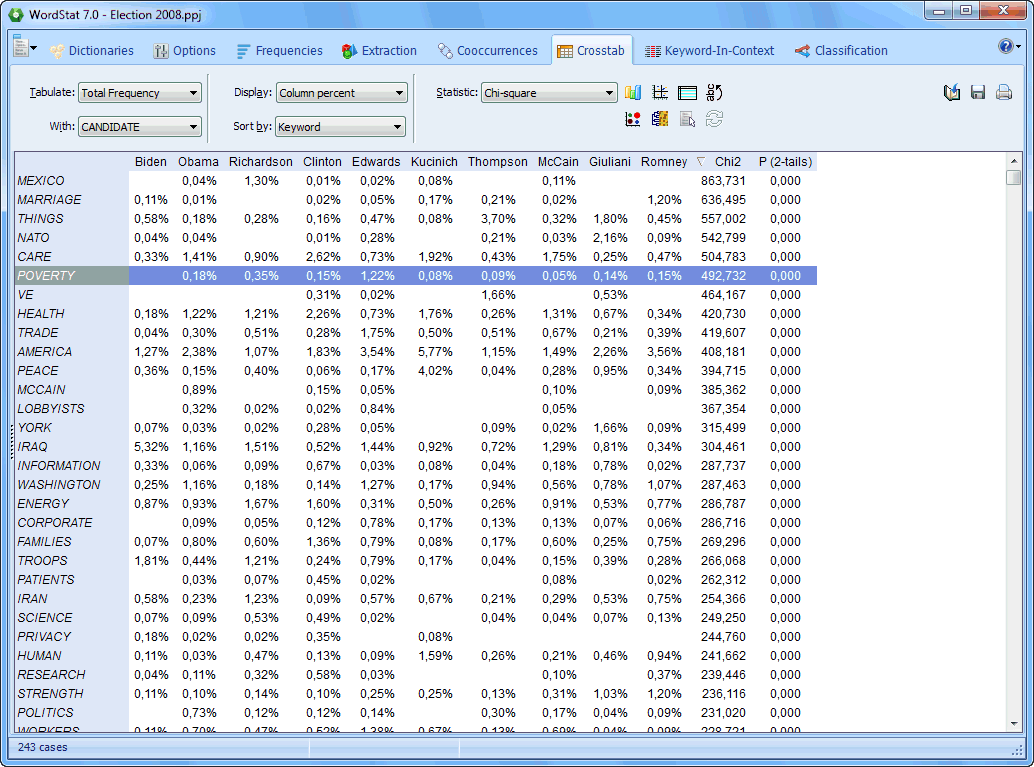 The Crosstab page allows one to compare keyword frequencies across values of numerical, categorical or date variables. |
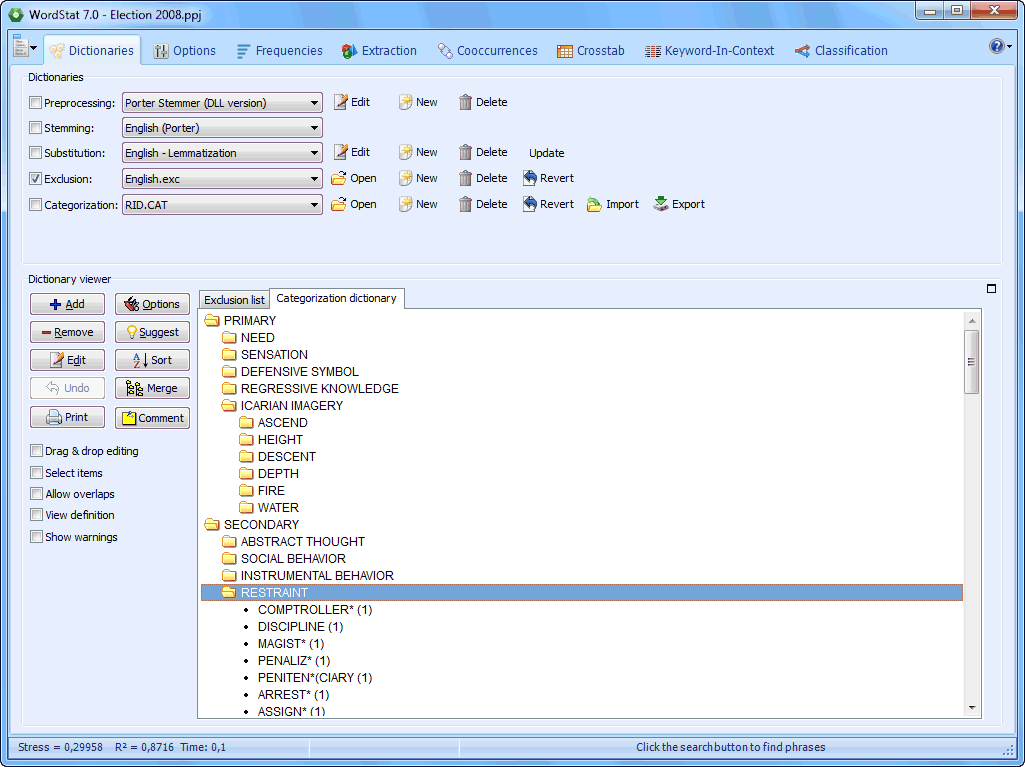 The Dictionary page allows one to adjust various text analysis processes, create and modify dictionaries, exclusion and substitution lists. |
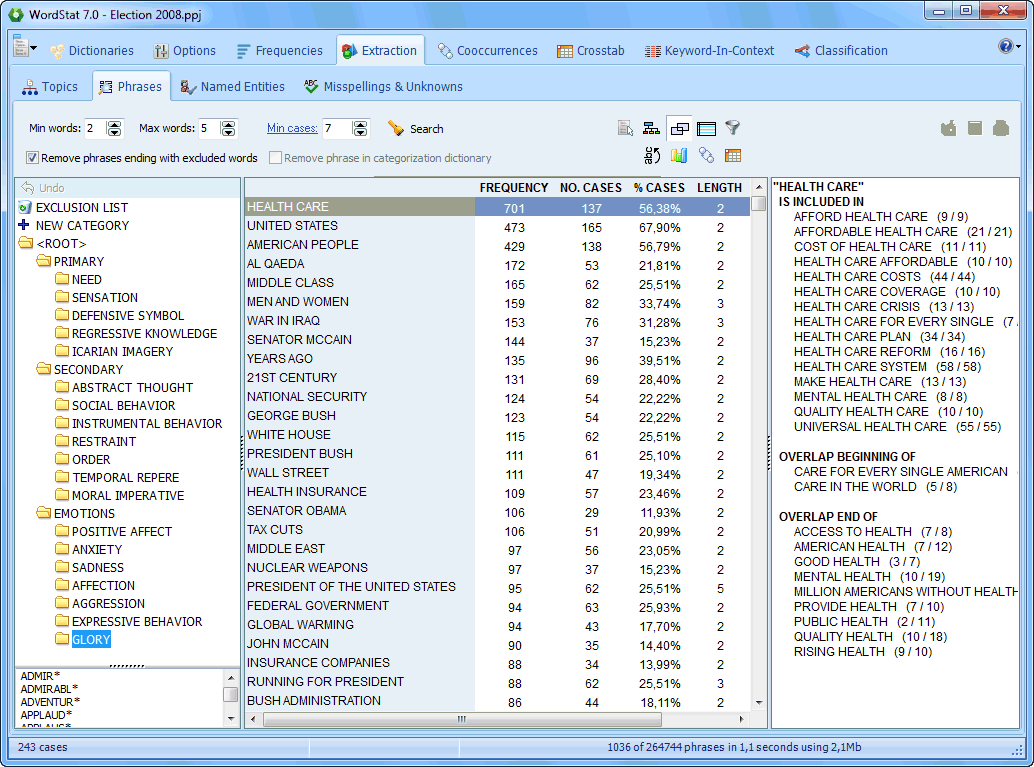 The Phrase Finder feature allows one to easily extract the most common phrases and idioms. |
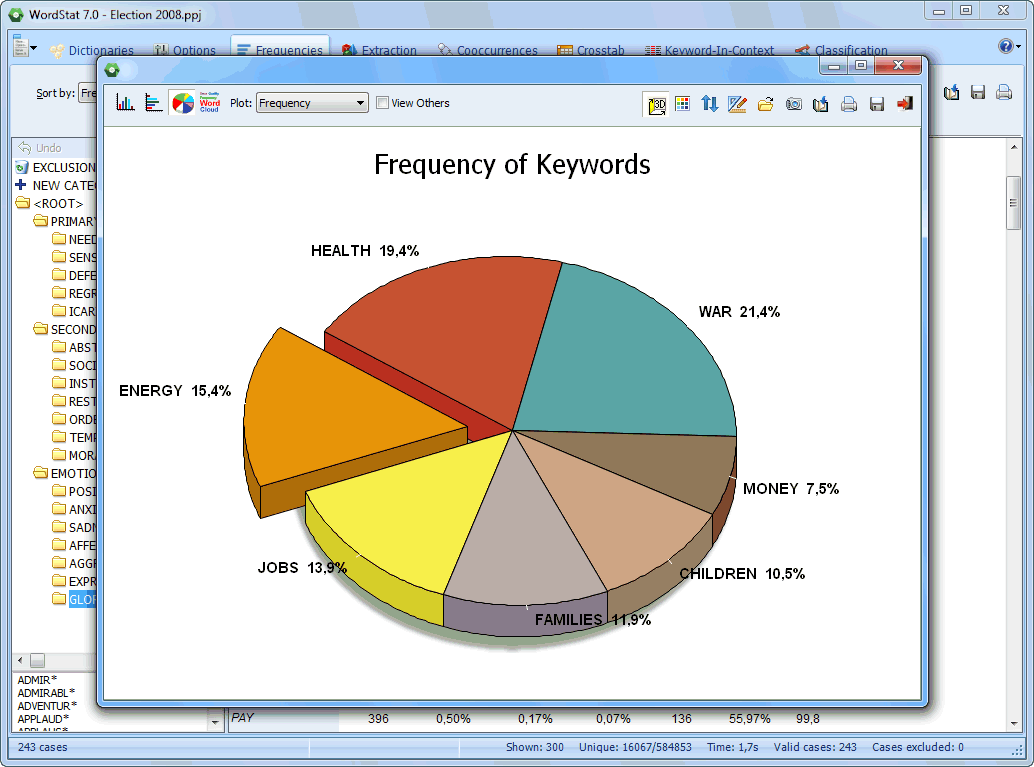 Bar chart, pie charts and word clouds can be easily produced. |
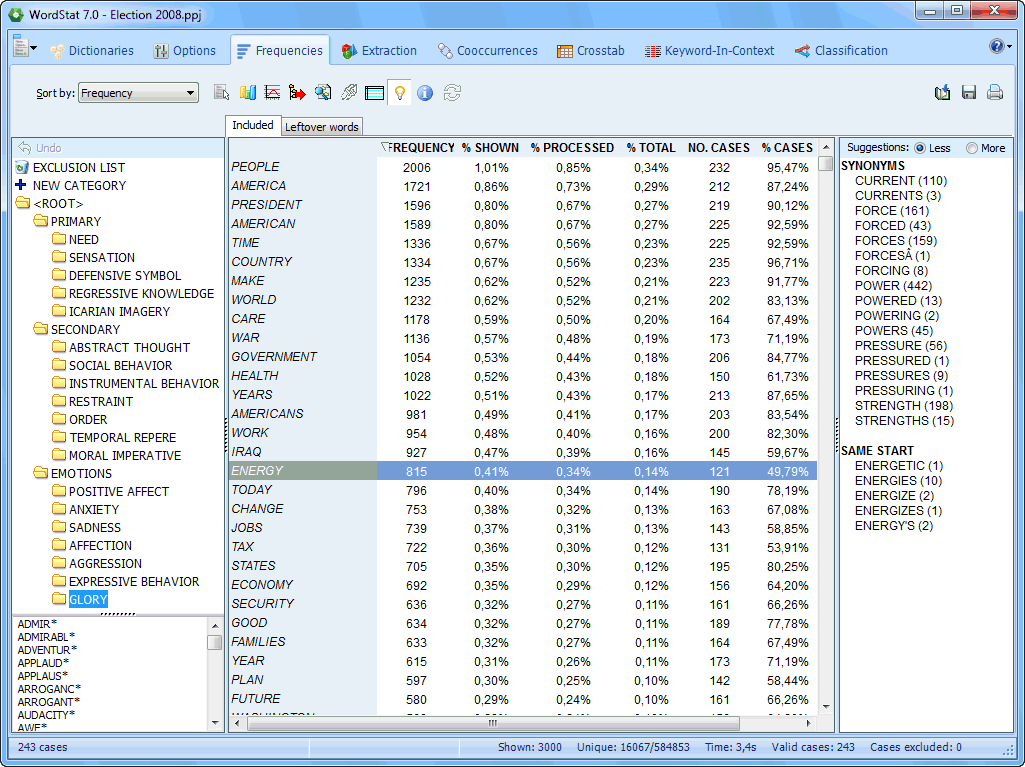 The Frequency page displays a frequency table of keywords or content categories. A suggestion panel on the right suggest synonyms and related words. |
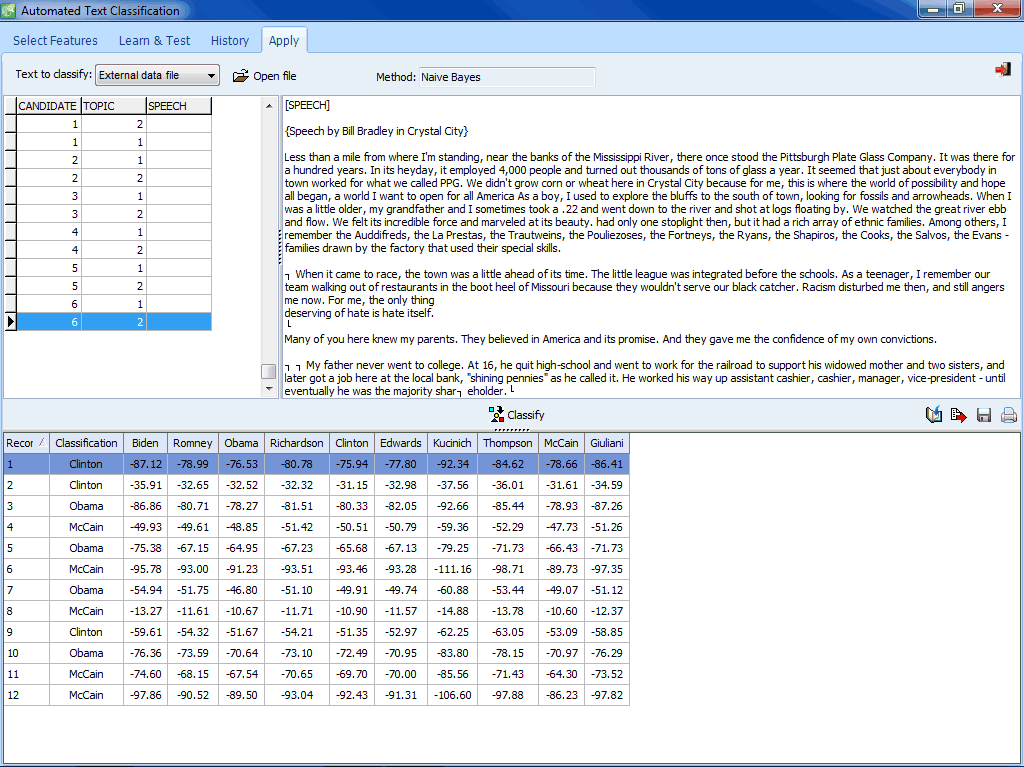 The Apply page allows one to categorize a single document, a list of files, or text variables in the current or an external data file. |
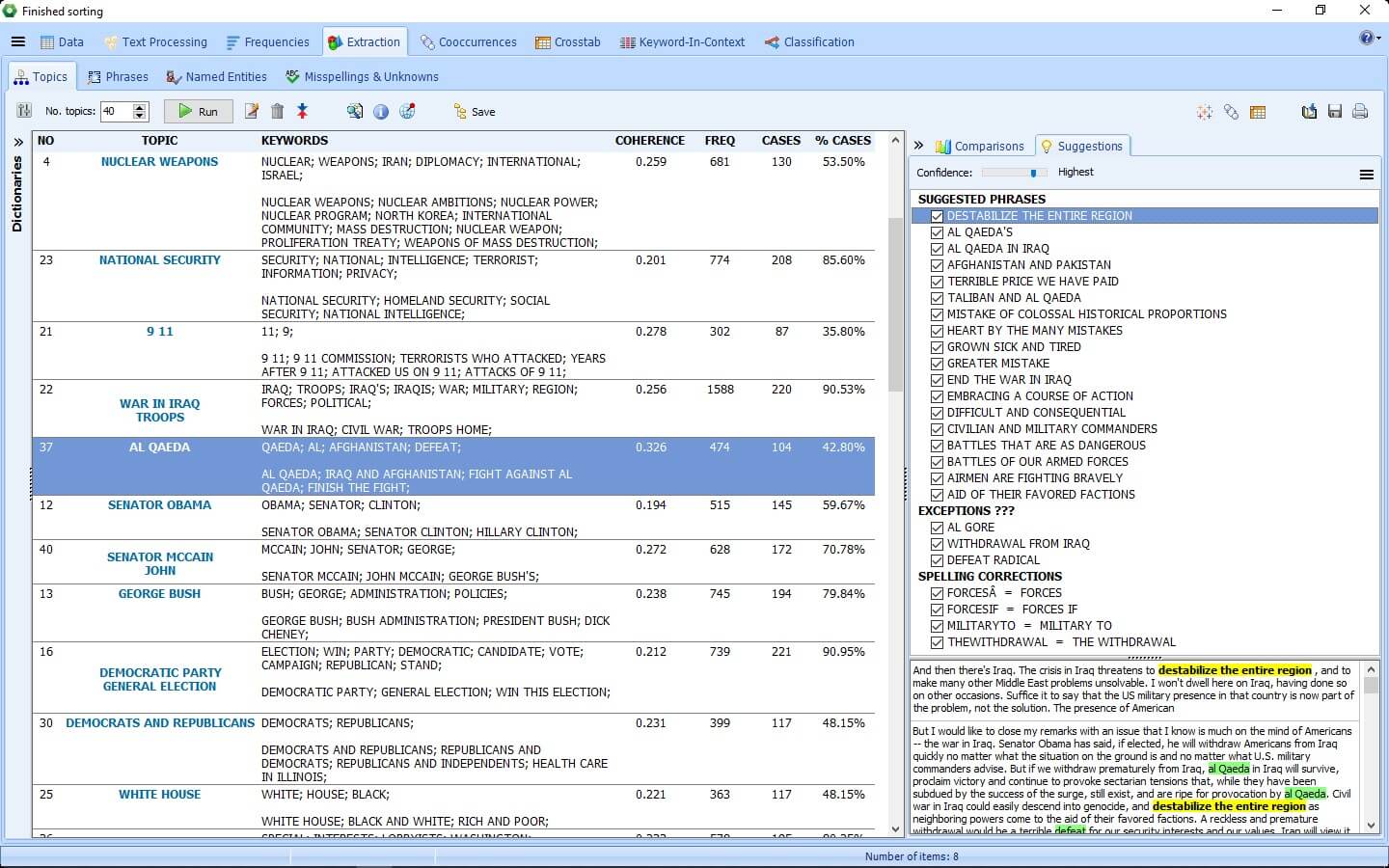 Get a quick overview of the most salient topics from large text collections by using state-of-the-art automatic topic extraction techniques. |