Are CAQDAS tools appropriate for large datasets? May 9, 2024 - Blogs on Text Analytics

Traditional Computer-Assisted Qualitative Data Analysis Software (CAQDAS) tools were designed for small qualitative research projects. However, the advent of the internet and the trend toward digitalization have significantly increased the amount of data available to qualitative researchers. Social media platforms (Twitter, Facebook, etc.), review sites (TripAdvisor, Yelp, etc.), product reviews (on Amazon and other e-commerce platforms), and online databases overflowing with journal abstracts, full journal articles, news transcripts, legal documents, financial filings, and even public policies in digital form are just a few examples.
In 2008, in a chapter of The SAGE Handbook of Online Research Methods, Grant Blank observed that existing qualitative research tools weren’t evolving to take advantage of this newfound wealth of data. This may partly explain the observation he made that most qualitative researchers continue focusing on detailed analysis of smaller samples of qualitative data, neglecting these large datasets.
However, more than fifteen years later, many CAQDAS tools have implemented natural language processing (NLP) and machine learning techniques like sentiment analysis, automatic theme extraction, opinion mining, techniques specifically designed to analyze large amounts of unstructured text data. One might logically assume these limitations in CAQDAS tools are a thing of the past. A more cautious approach would be to assess the latest versions of these tools to see if they possess the scalability and performance needed to handle larger datasets.
In December 2023, Steve Wright presented results from such an assessment. He attempted to analyze data from a large survey. He put three CAQDAS tools, NVivo, Atlas.ti, and our own software, QDA Miner, as well as Leximancer (which technically falls more into the text mining category, like our WordStat software), to the test. His conclusion was that neither NVivo nor Atlas.ti were fast enough or able to scale up, often crashing when handling large amounts of text data. While he did mention QDA Miner as an exception, able to scale up and offer fast performance on many tasks, he nevertheless concluded that desktop software as a whole may not be capable of handling large amounts of text data, suggesting instead that cloud-based or server-based solutions might be the answer. Considering his observation about our software, such a conclusion may be hasty and potentially misleading. We have always devoted significant programming efforts to ensure QDA Miner could handle very large datasets and perform quickly. Yet, the question remains: how scalable is QDA Miner and how fast is it really when analyzing large amounts of text? How does it compare to other CAQDAS tools?
Comparing performances and scalability of basic qualitative analysis tasks
To answer these questions, and also try to identify some of the factors that may explain differences in performance and scalability, we decided to subject the major CAQDAS desktop tools on the market today to some tests on large datasets.
While we have dealt with QDA Miner projects containing millions of records in the past, we decided to start with a much smaller dataset, yet still relatively large from a qualitative research perspective. The data consisted of 50,425 comments about airline flights scraped from TripAdvisor. We compared the performance of QDA Miner with three of its competitors: MaxQDA, Atlas.ti, and NVivo. All these desktop tools include text mining features similar to those found in our WordStat software, a dedicated text mining and quantitative content analysis software.
We computed the speed of various tasks, including importation, text search, autocoding, coding retrieval, as well as some exploratory techniques such as producing a word cloud and a word frequency table, and extracting n-grams (phrases of 2 to 5 words). We also looked at the time required to perform sentiment analysis, to extract themes, and to export retrieved text segments to Excel and .DOCX files. Since sentiment analysis and theme extraction are not available in QDA Miner but are normally achieved using the WordStat add-on, we reported the timing of those operations in WordStat. All tests were performed on a Windows 11 computer equipped with an Intel Core i9-10900 CPU, 64GB of RAM, and 4TB of disk space (M.2 SSDs). We used the latest versions of each software as available on May 1, 2024.
Table 1 presents the performance obtained on these tasks. Right from the start, one can see the significant difference in performance when importing the data from an Excel spreadsheet. While QDA Miner imported the test dataset in about 17 seconds, the import time in the other tools ranged from 1 hour 23 minutes for Atlas.ti to 2 hours and 23 minutes for NVivo (without theme and sentiment coding). MaxQDA crashed after an hour and a half, but nonetheless successfully imported the file, allowing us to continue testing the software. An important observation was that for the three competing CAQDAS tools, the importation speed significantly degraded as the number of imported records increased. For reasons that should be obvious, we decided not to submit those tools to larger datasets.
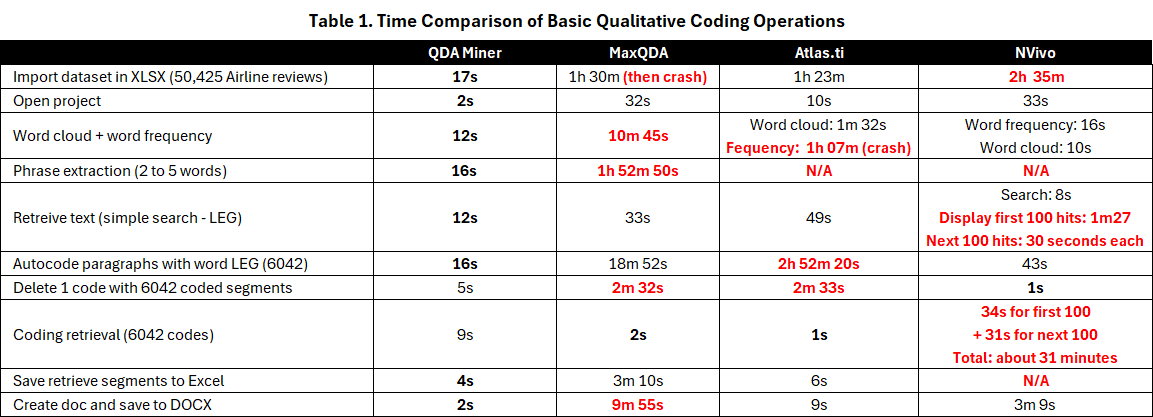
The remaining results on all the other tasks in Table 1 clearly demonstrate the substantial performance gap between QDA Miner and the other tools. QDA Miner completed all tasks in seconds. The most time-consuming procedures were n-gram extraction (2 to 5 words) and autocoding 6,049 paragraphs, both of which took only 16 seconds. In comparison, many of these tasks took several minutes, or even an hour or more, for the other three software programs. Search and retrieval operations were where the competing tools showed their best performance, while the worst performances were observed in autocoding operations when attempting to apply codes to text segments (autocoding). Autocoding in Atlas.ti was especially problematic, often filling the entire computer’s 64GB memory and then crashing. The same consequence (filling memory and crashing) occurred when attempting to produce a simple word frequency table in Atlas.ti.
Of the three other CAQDAS tools, NVivo seemed the most consistent in performance, besides its very low performance for the importation of the dataset. It’s important to note, however, that while NVivo achieved the best result on a simple text search at 8 seconds, it took 1 minute and 36 seconds to display the first 100 hits and an additional 30 seconds for each subsequent 100 hits. In contrast, QDA Miner searched and retrieved all 6,045 segments in 12 seconds, followed by MaxQDA (33 seconds) and Atlas.ti (49 seconds). This also may not reflect the performance of other operations. For example, we had to interrupt a matrix coding query in Nvivo that we estimated would have taken more than 16 days to complete, an operation that could be achieved in a few seconds in MaxQDA or QDA Miner.
Comparing Performances and Scalability of Text Mining Tasks
Generally speaking, WordStat was the fastest on text mining tasks (see Table 2), but comparisons are not as straightforward as what we have seen above. Each tool differs greatly in the way they perform sentiment analysis. Nvivo analyzes and autocodes responses on sentiment in a single operation, doing so in a little bit more than 14 minutes. Atlas.ti and MaxQDA compute sentiment first, then allow the user to autocode the comments in a second operation. While the analysis part is performed quickly in less than a minute for both of them, the autocode was rather slow for MaxQDA, taking more than 28 minutes while Atlas.ti crashed after more than six hours of processing. WordStat was the fastest at applying sentiment analysis, taking only 11 seconds. However, while all other tools are classifying responses into mutually exclusive categories, WordStat computes two independent scores for positivity and negativity. Three additional operations were thus required to obtain a categorization: 1) saving the two sentiment scores into numerical variables, 2) computing the differences between those two variables and 3) recoding the obtained values in three classes (positive, negative and neutral). The manipulation could, however, be done in less than a minute with a cumulative processing time of 22 seconds.

Tools also differ greatly in the method they use to extract topics or themes and while the obtained results are quite different, the objective remains the same: providing a quick description of the content of a large quantity of unstructured text. When applying those techniques on a dataset of 243 speeches, which roughly represents about 1,100 pages of text, we can see that WordStat achieve such an operation in 3 seconds only. All other applications took between one and two minutes and a half. In our opinion, such performances remain quite reasonable considering the large quantity of text being analyzed. For this reason, the most important aspect that should be considered is the quality of the obtained results and their usefulness at identifying what those documents are about, something we will cover later.
Memory Consumption Comparison
Documenting the memory consumption of these CAQDAS tools during the experiment provided valuable insights, potentially explaining some of the stability issues (crashes) and performance differences we encountered. The results presented in Table 3 surprised us. The initial measurement looked at the amount of memory each software used when first launched but before opening any data file. Memory consumption ranged from 246MB for Atlas.ti to 325MB for MaxQDA, with NVivo falling in the middle at 305MB. In comparison, QDA Miner used a tiny fraction of this at only 8.5MB. This discrepancy increased after loading the test dataset, with memory consumption rising from 594MB for NVivo to a substantial 1.4GB for Atlas.ti. On the other hand, QDA Miner’s memory consumption only increased to 14MB. Notably, the project size didn’t significantly affect QDA Miner’s memory usage. We loaded a much larger version of the airline dataset consisting of over one million records, and the memory usage remained unchanged at 14MB.

Discussion
We can only speculate on the reasons behind such high memory usage and slow performance observed in the other CAQDAS tools. The programming language and platform choices (.NET and QT) might be one factor. However, we can’t rule out the possibility of inefficient algorithms, data structures, and a lack of performance optimization efforts or memory management strategies. Since their primary market has always been qualitative researchers analyzing relatively small projects, there may not have been a pressing need for these optimizations. On the other hand, QDA Miner was originally designed as a qualitative software that could also be used as the base module for our text mining software WordStat, so handling large datasets was not an afterthought but an initial requirement.
This last point emphasizes that the above comparison doesn’t necessarily reflect the suitability of these tools for typical qualitative research. If one’s needs involve analyzing a few dozen interview transcripts or a few hundred survey responses, then any of these tools would likely handle such projects effortlessly. However, if the dataset consists of thousands of pages or tens of thousands, or even hundreds of thousands of open-ended responses or customer feedback, the comparison clearly suggests that QDA Miner is the only one among these four CAQDAS tools that offers the scalability and performance needed to handle such large datasets effectively. The necessity to provide coding assistance to users with large projects is also the reason why QDA Miner offers several coding assistance features relying on supervised and unsupervised machine learning (cf. query-by-example, code similarity search, cluster coding).
This blog post focused on the speed and memory requirements of different CAQDAS tools. The question of the usefulness and accuracy of the text analytics features available in those tools remain unanswered. This will be the topic of the next blog post (see Is Sentiment Analysis in Qualitative Analysis Software Accurate?)
References:
Blank, G. (2008). Online research methods and social theory. In N. Fielding, R. Lee, & G. Blank (Eds.), The SAGE Handbook of Online Methods (pp. 537–549). London: Sage.
Wright, S. (December 2023). Transparency in Qualitative Analysis using Machine Learning: Making Informed Choices and Explaining Insights [Video Presentation]. Presented at the Symposium on A.I. in Qualitative Analysis. CAQDAS Networking Project.