PART I: Automatic Machine Learning Document Classification – An Introduction January 11, 2019 - Blogs on Text Analytics
This blog focuses on Automatic Machine Learning Document Classification (AML-DC), which is part of the broader topic of Natural Language Processing (NLP). NLP itself can be described as “the application of computation techniques on language used in the natural form, written text or speech, to analyse and derive certain insights from it” (Arun, 2018).
AML-DC aims to automatically assign ‘a data-point to a predefined class or group according to its predictive characteristics’ (Kabir et. al., 2018).
AML-DC is the essence of text mining as it transects, not with only NLP, but with other text mining techniques (i.e. information extraction, web mining, information retrieval and document clustering – see Figure 1, below).
Figure 1: Inter-relationship among different text mining techniques including document classification (centre of figure) and their core functionalities.
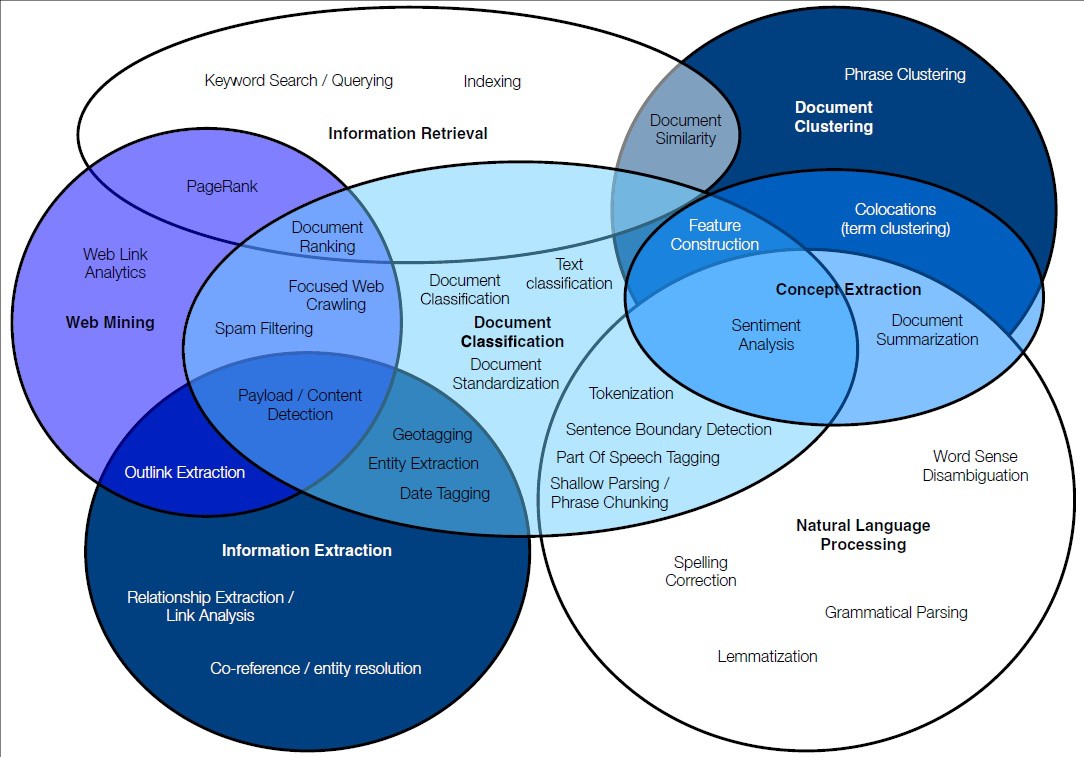
Source: Talib et al. (2016)
AML-DC Categories
Machine learning (ML), used in automatic document classification is divided into:
- Supervised machine learning, where classifications are carried out based on pre-determined categorical classes or labels. Examples of supervised ML methods include:
- Decision Tree Classifiers: Random Forest; Gradient Boosted Trees (XGBoost)
- Linear Classifiers: Generalized Linear Model (GLM); Logistic Regression and Support Vector Machines (SVM); Neural Networks.
- Non-linear Classifiers:
- Probabilistic Classifiers: Naïve Bayes; Bayesian Network; Maximum Entropy
- Non-Parametric Classifiers: k-Nearest Neighbour Classifiers (k-NN): 2‑NN…5-NN.
- Unsupervised machine learning (ML), where classifications are carried without pre-determined classes / category (labels). Examples of unsupervised methods include:
- Dimensionality reduction techniques: latent Dirichlet Analysis (LDA); Principal Component Analysis (PCA) and K-Means; and
- Convolutional Neural Network (CNN) and Recurrent Long Short-Term Memory (LSTM) network.
Figures 2 below, shows some visualizations from using ML classifiers in Python.
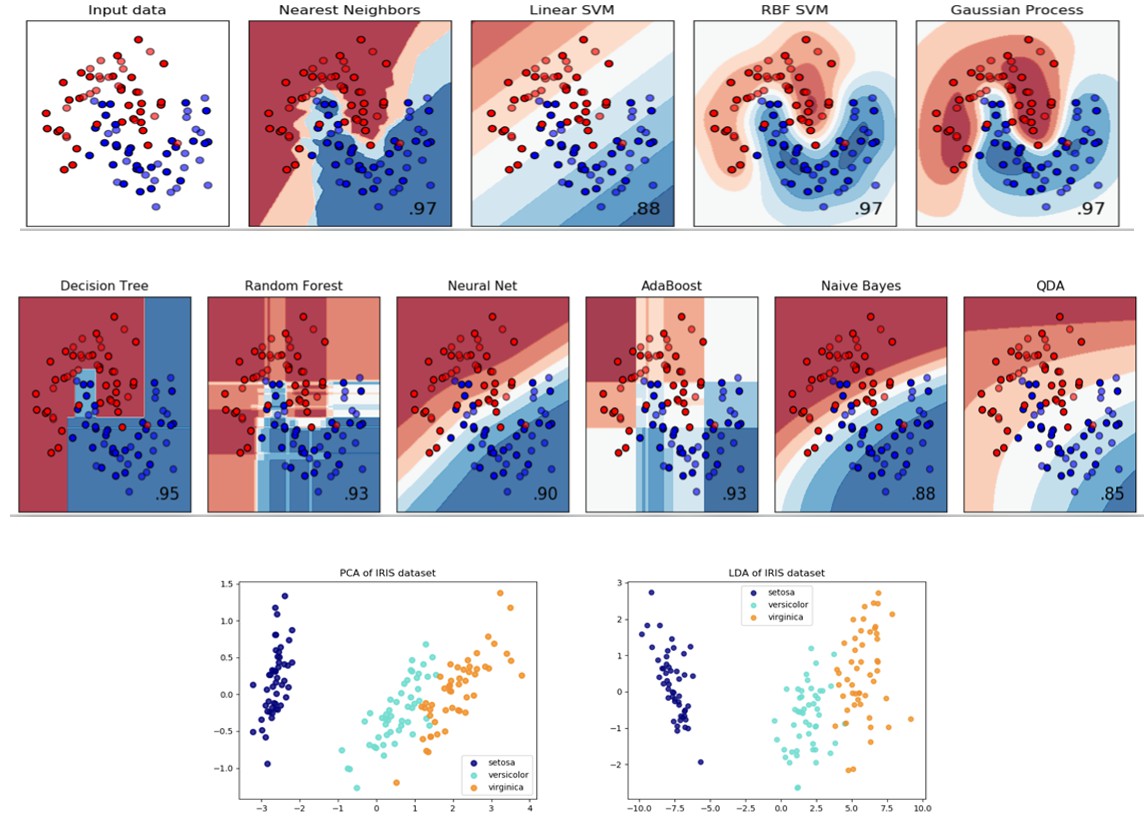
Source: Classifier comparison — scikit-learn 0.20.2 documentation (2018)
Technical details, merits and demerits of ML methods as well as comparisons of ML classifiers, are extensively covered in the literature (Lozano et al., 2010; Amacio et al., 2014; Mikolov et al. 2013; Brummelhuis & Luo, 2017; Kim, 2016; Medhat et al., 2018).
The rest of this blog is mostly on supervised AML-DC. A future, special blog will be devoted on unsupervised AML-DC machine learning.
KEY FEATURES OF SUPERVISED AML-DC MODELS
Examples
Supervised, AML-DC is now widely used commercially to categorise documents (e.g. spam email detection and legal abstracts), categorise severity of medical cases (e.g. tumour morphology of brain and lung cancer); perform sentiment analysis (e.g. on-line surveys, news, product reviews), and in author attribution studies or stylometry (Amacio et al., 2014; Eder et al., 2016; Araque et al., 2017; Brummelhuis & Luo, 2017; Nyakuengama, 2018).
End-users
Key AML-DC users comprise qualitative data scientists, linguists, decision makers and the general public particularly when using the Internet of Things (IoT) devices (i.e. PCs, emails and smart phones).
Strengths
AML- DC is technologically very attractive on account of being automatic, fast, low cost, efficient, repeatable, dimension reducing – through text processing, enables complex data visualization. As such, AML- DC features mitigates against the many challenges of big data namely data volume, velocity, variety and veracity (Bailey and Nunan, 2009; Lozano et al., 2010; Amacio et al., 2014; Talib et al., 2016; Medhat et al., 2018).
Weaknesses
A major weakness in AML- DC methods stems from its reliance on the wide range of skills of the analyst to select appropriate machine learning methods, to construct and optimise the models (though feature selection – see below), to develop smart codes that faithfully describe the studied corpora, to carefully interpret technical results and to properly write up the results (Bazely, 2004; Putten & Nolen, 2010; Amacio et al., 2014; Chenail, 2012; Medhat et al., 2018).
Overview of the supervised AML-DC modeling processes
Modeling steps
Underpinning classification models are supervised AML-DC processes. Models typically have the following stages: training, validation, performance estimation from parameters in the confusion matrix (see Table 1 below), model packaging and deployment (Bazely, 2004; Lozano et al., 2010; Gonalez-Bailon, 2015; Medhat et al., 2018; QDA Miner/WordStat User’s Manual 2018).
Text Processing
Most supervised AMLC-DC methods use the following text normalisation processes which enable similar words to be counted as one:
These normalization processes are discussed in the literature (Schonfelder, 2011; Mikolov et al., 2013, Gonalez-Bailon, 2015; Talib et al., 2016; QDA Miner/WordStat User’s Manual 2018).
FACTORS AFFECTING PERFORMANCE IN SUPERVISED AML-DC MODELS
Model reliability
An overarching objective in AML-DC is to maximize model reliability, as assessed by any of the several performance parameters typically reported in a confusion matrix (see Table 1, below). The choice of the which performance parameter to optimise depends on overall modelling objectives and constraints, such availability of sound data science skills and fast computers.
Table 1: Model performance parameters used in assessing machine learning performance
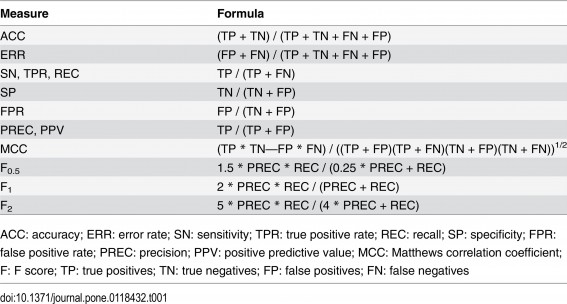
Source: Saito and Rehmsmeier (2015)
Overfitting
Model over-fitting in ML occurs when a model merely describes the random error in the data being modelled, instead of the relationship between data variables. An example of an optimally fitted model is shown in the middle picture of Figure 2a, below.
Figure 2a: Over-fitting in ML models
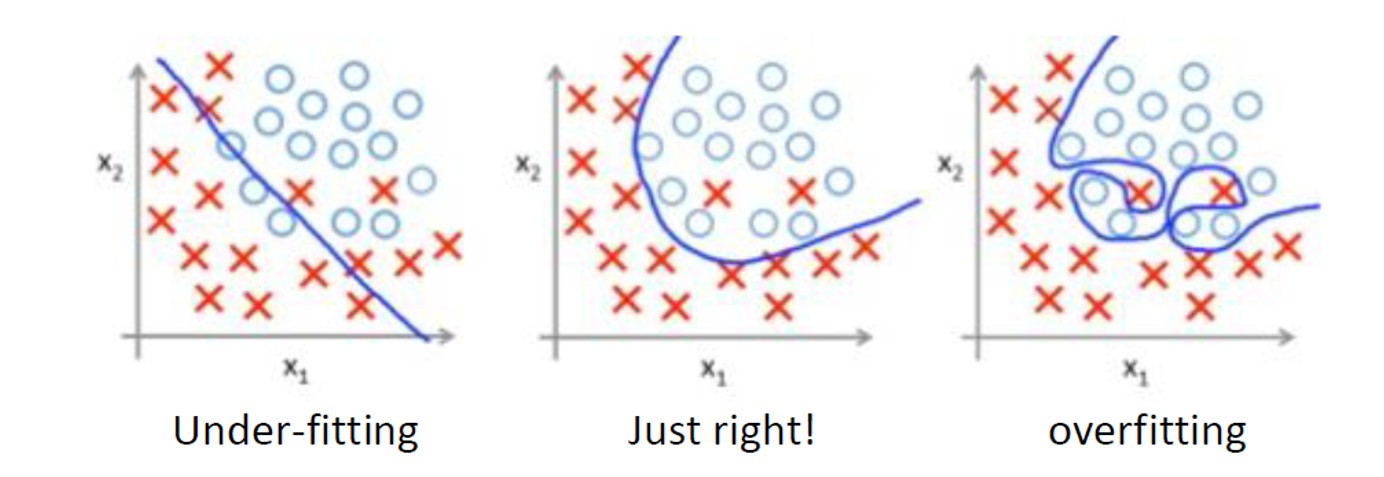
Source: Kim (2016)
Also, the error of prediction is high in overly complex, over-fitted models (see Figure 2b, below). Such models are undesirable as they yield poor predictive results when applied to unknown cases.
Figure 2b: Over-fitting in AML-DC models – model error vs model complexity.
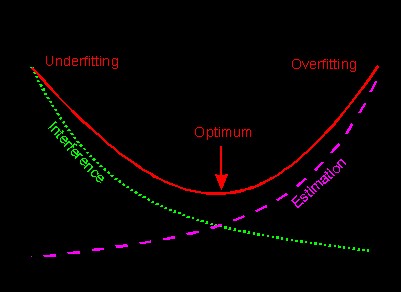
Source: Dieterle (2003)
Modern AML-DC tools employ several sophisticated and automatic statistical methods to minimise over-fitting, including early stopping, leave one-out and K-fold (Lozano et al., 2010; Saito and Rehmsmeier, 2015; Cai et al., 2016; Brummelhuis & Luo, 2017; Medhat et al., 2018 QDA Miner/WordStat User’s Manual 2018).
Feature engineering
AML-DC tools also employ several techniques to create and select words that best represent the vectorized corpora called features. Feature engineering, as its called, strongly impacts on model usefulness and performance. For instance, the presence of unnecessary features impacts on model training speed, the ability to generalise the model during testing, and ultimately, the reliability of classification results. In other words, poor feature engineering can lead to False Negatives (Type II errors) or False Positives (Type errors) – see Table 1, above.
Furthermore, some ML classifiers perform less favourably with small features (e.g. LDA) and others less so with many features (e.g. Naïve Bayes). In contrast, some classifiers perform well with many features (e.g. k-NN and to some degree, SVM).
Automatic feature extraction and availability of computing resources are the linchpin to fast AML-DC. Some commonly used ML feature selection methods involve feature weighting, typically the TF-IDF and include techniques such as Bag of words (BOWs), Chi‑square (χ2), Point-wise Mutual Information (PMI) and Latent Semantic Indexing.
The literature on factors affecting model reliability, particularly feature engineering and weighting, is extensive (e.g. Kohlbacher, 2006; Lozano et al., 2010; Amacio et al., 2014; Araque et al., 2017; Brummelhuis & Luo, 2017; Arun, 2018; Koehrsen, 2018; Medhat et al., 2018; QDA Miner/WordStat User’s Manual, 2018).
Representativeness / case sampling
In designing an AML-DC experiment, mixed method scientists often worry about definitional, paradigmatic and methodological issues, including:
The above topics are well covered in the literature (Bazely, 2004; Kohlbacher, 2006; Lozano et al., 2010; Silver & Lewins, 2010; Talib et al., 2016; Brummelhuis & Luo, 2017; Koehrsen, 2018).
CONCLUSION
We have surely covered a lot of ground in this introductory blog on AML-DC.
We explored why AML-DC is important, how it is used and who uses it. We also looked at some key concepts in supervised AML-DC such as model reliability, overfitting, feature engineering and issues around representativeness /case sampling.
We have also provided several references on these topics, for the reader who wishes to undertake further research.
FUTURE BLOGS
In Part II of our blog series, we will provide a practical and detailed walk-through using QDA Miner/WordStat. We will use supervised AML-DC approaches to solve a commercial problem in fast, reproducible, reliable and auditable way.
Part III of our blog series will focus on unsupervised AML-DC machine learning, namely latent Dirichlet Analysis (LDA); Principal Component Analysis (PCA) and K-Means.
BIBLIOGRAPHY
Amacio, R.D., Comin, C.H., Cassanova, D., Travieso, G., Bruno, O.M., Rodriguez, F.A., da Fontoura Costa, L. (2014) : A Systematic comparison of supervised classifiers. Plos One. Vol. 9 (4), e94137 pp. 1-14. https://journals.plos.org/plosone/article?id=10.1371/journal.pone.0094137
Araque, O., Corcuera-Platas, I., Sánchez-Rada, J.F., Iglesias, C.A. (2017). Enhancing deep learning sentiment analysis with ensemble techniques in social applications. Expert Systems With Applications, Vol. 77 (2017), pp. 236–246. https://www.semanticscholar.org/paper/Enhancing-deep-learning-sentiment-analysis-with-in-Araque-Corcuera-Platas/36e02631e66e9e2588063ecc35a3eb41b808f643
Arun, V. (2018): Business use case for NLP. A tutorial on predicting the next trend in a fashion e-Commerce context. https://github.com/vinayarun/BUSINESS-USE-CASE-FOR-NLP
Bazely, P (2004). Issues in Mixing Qualitative and Quantitative Approaches to Research. Published in: R. Buber, J. Gadner, & L. Richards (eds) (2004) Applying qualitative methods to marketing management research. UK: Palgrave Macmillan, pp141-156 (PDF) Issues in Mixing Qualitative and Quantitative Approaches to Research. Available from: https://www.researchgate.net/publication/228469056_Issues_in_Mixing_Qualitative_and_Quantitative_Approaches_to_Research [accessed Dec 21 2018].
Bazely, P., Kemp, L. (2012). Mosaic, triangles and DNA: Metaphors for integrated analysis in mixed methods research. Journal of Mixed Methods Research, 6 (1), pp. 55-72. https://www.researchgate.net/publication/258172815_Mosaics_Triangles_and_DNA_Metaphors_for_Integrated_Analysis_in_Mixed_Methods_Research
Brummelhuis, R., Z. Luo, (2017). CDS rate construction methods by machine learning techniques. Université de Reims-Champagne-Ardenne. https://www.researchgate.net/publication/317273929_CDS_Rate_Construction_Methods_by_Machine_Learning_Techniques_Presentation_Slides
Cai, T et al (2016). Natural Language Processing Technology in Radiology Research and Clinical Applications. RadioGraphics 2016 Vol.36, pp. 176-191. https://pubs.rsna.org/doi/10.1148/rg.2016150080
Chenail, R.J., (2012). Conducting Qualitative Data Analysis: Qualitative Data Analysis as a Metaphoric Process. The Qualitative Report Vol. 17, Number 1, January 2012, pp. 248-253. Conducting Qualitative Data Analysis: Qualitative Data Analysis as a Metaphoric Process
Classifier comparison — scikit-learn 0.20.2 documentation (2018). http://scikit-learn.org/stable/auto_examples/classification/plot_classifier_comparison.html
Dieterle, F., (2003). Overfitting, Underfitting and Model Complexity in Ph.D. Multianalyte Quantifications by Means of Integration of Artificial Neural Networks, Genetic Algorithms and Chemometrics for Time-Resolved Analytical Data. http://www.frank-dieterle.de/phd/2_8_1.html
Eder, M., Kestemont, M. and Rybicki, J. (2016). Stylometry with R: A package for computational text analysis. R Journal, 16(1). https://journal.r-project.org/archive/2016-1/eder-rybicki-kestemont.pdf
Gonalez-Bailon, S. (2015). Automated content analysis of online political communication. Handbook of Digital Politics. pp. 433-450. University of Pennsylvania. Scholarly Commons. http:/repository.upenn.edu/asc_papers/507
Kabir, M., Shahjahan, Murase, K. (2012). A new hybrid ant colony optimization algorithm for feature selection. Expert Systems with Applications: Vol.39 (3), pp. 3747-3763 https://dl.acm.org/citation.cfm?id=2064487
Kim, M. (2016). Deep learning and Tensorflow implementation – Seoul National University System Health and Risk Management. https://www.slideshare.net/MyungyonKim/deep-learning-and-tensorflow-implementationmyungyon-kimsnushrm
Koehrsen, W. (2018). A Feature Selection Tool for Machine Learning in Python. Medium Blog marketing management research. https://towardsdatascience.com/a-feature-selection-tool-for-machine-learning-in-python-b64dd23710f0
Kohlbacher, F. (2006). The Use of Qualitative Content Analysis in Case Research. Forum: Qualitative Social Research. Vol. 7(1), Art. 21 – January 2006. http://www.qualitative-research.net/index.php/fqs/article/view/75/153
Lozano, J.A., Santafé, G., Inza, I. (2010). Classifier performance evaluation and comparison. International Conference on Machine Learning and Application (ICMLA 2010). December 12-14, 2010. https://www.icmla-conference.org/icmla10/CFP_Tutorial_files/jose.pdf
Medhat, W.; Hassan, A. & Korashy, H. (2014). Sentiment analysis algorithms and applications: A survey. Ain Shams Engineering Journal (Vol. 5, pp. 1093-113). https://www.sciencedirect.com/science/article/pii/S2090447914000550
Mikolov, T., Chen, K., Corrado, G., & Dean, J. (2013). Efficient estimation of word representations in vector space. arXiv preprint arXiv:1301.3781. https://arxiv.org/abs/1301.3781
Nunan, D. & Bailey, K.M. (2009). Exploring second language classroom research. Australia: Heinle Cengage Learning. https://www.amazon.com/Exploring-Second-Language-Classroom-Research/dp/1424027055
Nyakuengama J.G. (2018) Stylometry – Authorship Attribution – Early British Fictionists. https://dat-analytics.net/2018/12/02/stylometry-authorship-attribution-early-british-fictionists/
Putten, J. V., & Nolen, A. L. (2010). Comparing results from constant comparative and computer software methods: A reflection about qualitative data analysis. Journal of Ethnographic & Qualitative Research, Vol. 5, pp. 99–112. http://www.academia.edu/1616295/Qualitative_Data_Analysis_Comparing_Results_From_Constant_Comparative_and_Computer_Software_Methods
QDA Miner/WordStat User’s Manual 2018.
Saito, T. & Rehmsmeier, M. (2015). The Precision-Recall Plot Is More Informative than the ROC Plot When Evaluating Binary Classifiers on Imbalanced Datasets – https://doi.org/10.1371/journal.pone.0118432
Schonfelder, W. (2011). CAQDAS and qualitative syllogism logic – Nvivo 8 and MAXQDA 10 compared. Forum Qualitative Social Research, Vol. 12(1), Art. 21 http://www.qualitative-research.net/index.php/fqs/article/view/1514/3134
Silver, C., & Lewins, A. (2010). Computer assisted qualitative data analysis. In P. Peterson, E. Baker, & B. McGraw (Eds.), International Encyclopedia of Education (Vol. 6, 3 ed., pp. 326-334). Oxford: Elsevier.
Talib, R., Hanif, M.K., Ayesha, S. & Fatima F., (2016) Text Mining: Techniques, Applications and Issues. International Journal of Advanced Computer Science and Applications, Vol. 7 No. 11, pp. 414-418. http://thesai.org/Downloads/Volume7No11/Paper_53-Text_Mining_Techniques_Applications_and_Issues.pdf

Dr Gwin NYAKUENGAMA
DatAnalytics
Email: DatAnalytics@iinet.com.au
Webpage: https://dat-analytics.net/