The Power of Words: Content Analysis for Political Science November 29, 2016 - Blogs on Text Analytics
Words matter in political science. Politics, political theory and political change are often expressed through the spoken and written word and political science is influenced by many other disciplines including: economics, history, law, sociology, philosophy and psychology.
Political analysis involves researching news articles, magazines, advertisements, speeches, press releases, social media and much more. The volume of available text has exploded in the digital age. This explosion is partly due to the rapid move to store and distribute documents in electronic text databases. The easiest way to acquire text in this form is from online databases. Lexis Nexis and ProQuest, for example, facilitate batch downloads of files. More sources are being added all the time; The U.S. House of Representatives recently launched a new Web site dedicated to the distribution of all current House Resolutions under study. Text data stored on Web sites can also be extracted with automated scraping methods that make acquiring data easier (Jackman 2006). The most difficult to acquire are texts found in archives or yet-to-be scanned books. But preparing these texts for analysis can be straightforward—using a high quality scanner or Optical Character Recognition software, it is possible to convert archival materials into computer readable texts (see the data collection process in Eggers and Hainmueller 2009).
However, it is extremely time consuming, expensive and in many cases impossible to read each and every document related to ones research. Provalis Research text analytics software (QDA Miner and WordStat) makes it possible to systematically import and analyze very large volumes of text documents without spending vast sums on hiring coders. The software gives researchers the flexibility of manual and advanced computer assisted qualitative coding of documents and images. It can dramatically assist you in your research by identifying keywords, key phrases, themes, topics, images, speakers and sentiment.
As stated in Grimmer & Stewart, 2013 Automated content analysis methods have demonstrated performance across a variety of substantive problems and rather than replace humans computers amplify human abilities and that the most productive line of inquiry is to identify the best way to use both human and automated methods for analyzing text.
We agree and this is why Provalis Research QDA Miner allows you to perform manual and computer assisted coding and WordStat is a fully automated text mining tool.
Perform content analysis with QDA Miner and WordStat
Political scientists have applied automated content analysis across a diverse set of texts. This includes archives of media data (Young and Soroka, 2011); floor speeches in legislatures from across the world (Quinn et al. 2010); presidential, legislator, and party statements (Grimmer 2010); proposed legislation and bills (Adler and Wilkerson 2011); committee hearings (Jones, Wilkerson, and Baumgartner 2009); treaties (Spirling 2012); newspapers and Twitter feeds (Conway, Kenski, Wang 2015); political science papers; and many other political texts.
Exploring large amounts of text data and assigning text to categories is the most common use of text analysis software in political science.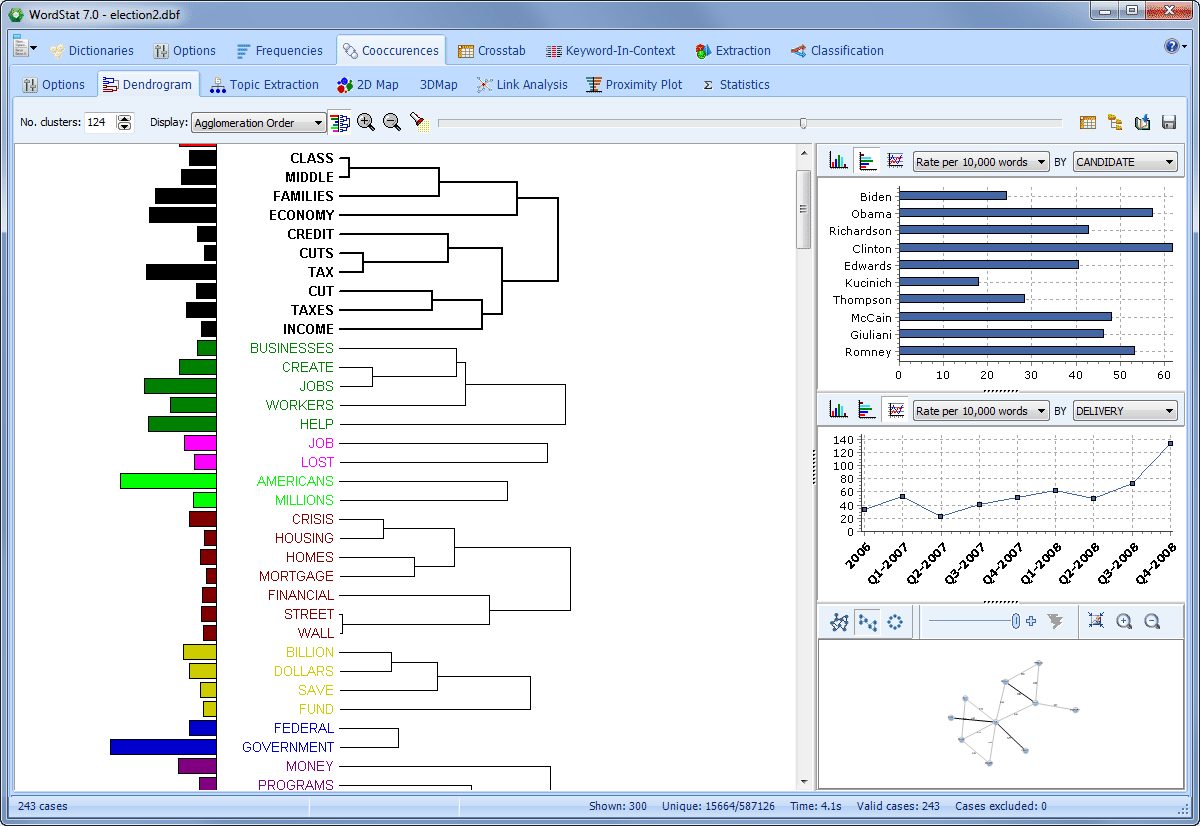
For example, WordStat’s text mining abilities such as topic modeling and cluster extraction can automatically identify relevant topics across different speakers and compare topic frequency between politicians or political discourse. When we compared topics mentioned during the 2008 US presidential campaign, we saw instantly that “health care” was more frequently mentioned by Democrat candidates than Republican candidates. A crosstab and correspondence analysis plot can be used to compare words and phrases between different candidates and identify words, phrases or topics that are more frequently mentioned by a specific politician in comparison to other politicians.
The content analysis capabilities of WordStat are also frequently used by political researchers. Dictionary methods rely on the use of hierarchical content analysis dictionaries or taxonomies 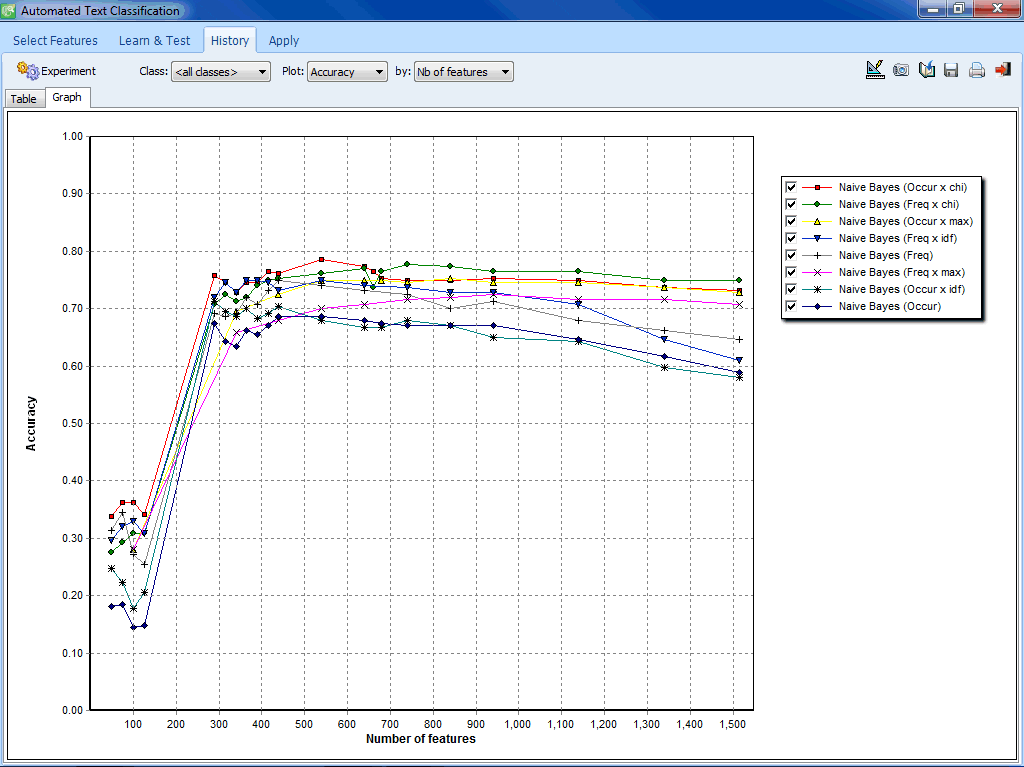 composed of words, word patterns, phrases as well as proximity rules to measure the presence of each concept in the texts. Supervised learning methods replicate the familiar manual coding task, but with a computer. First, human coders are used to classify a subset of documents into a predetermined categorization scheme. Then, this training set is used to train an automated method, which then classifies the remaining documents.
composed of words, word patterns, phrases as well as proximity rules to measure the presence of each concept in the texts. Supervised learning methods replicate the familiar manual coding task, but with a computer. First, human coders are used to classify a subset of documents into a predetermined categorization scheme. Then, this training set is used to train an automated method, which then classifies the remaining documents.
In their paper (Affective News: The Automated Coding of Sentiment in Political Text , 2012) Young and Soroka make the point that the tone of a political text may be just as important as the content. The reliable and valid analysis of sentiment is, in short, a critical component of a burgeoning field of research in political communication, and political science more broadly. In the paper they point out advantages for computer automation for text analysis using dictionaries. You can read more about their Lexicoder Sentiment Dictionary (LSD) by reading their paper or our white paper on Sentiment Analysis with WordStat. https://provalisresearch.com/uploads/WP_SentimentAnalysis_LR.pdf
Many political scientists have used QDA Miner and WordStat in their research. To see a sampling of those studies please go to https://provalisresearch.com/Documents/SomeStudies.pdf