Exploring Naïve Bayes classifier: Maybe not so naïve after all?! August 10, 2017 - Blogs on Text Analytics
Although relatively simple, Naïve Bayes (NB) is one of the powerful machine learning techniques. It’s not only simple but fast and accurate and has been used in various applications and domains. So, it’s a reliable friend that you can trust on rainy days! In this post, we will see how it works.
Who is NB’s daddy!?
You can trace NB’s roots back to probability theory and the Bayes theorem. Don’t worry if you don’t know them, we will explore them a bit later. The nature of NB is probabilistic as it deals with probabilities and degrees of certainty or uncertainty of an outcome. In simple terms, if you give the model a sample and ask it to predict the outcome, it goes through calculating the probabilities of seeing different outcomes based on the sample and then produces the outcome with the highest probability.
Bayes Theorem? What does it want from me?!
This lovely creature is all about conditional probabilities! It cares about the probability of an event if you know another event has already occurred. For example, what is the probability of it raining if you are in Montreal? Too general?! Okay, let’s put some numbers on the table! Suppose the probability of rain on Saturday is 0.05. You had a wonderful sunny working week and now today is Saturday. What is the probability of rain today?! Easy, let’s do the math. First, what is the probability of Saturday?! Well, we have 7 days in a week, so the probability of Saturday is 1/7 ≈ 0.14. So:
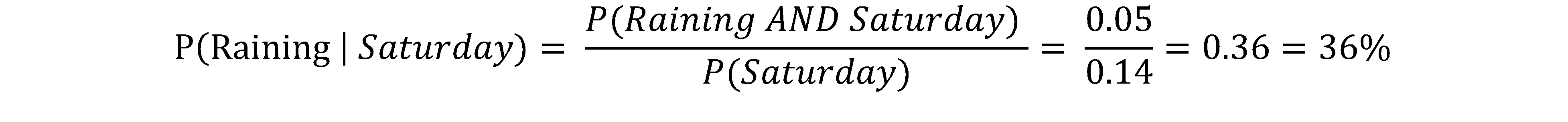
Yeah, I know, it is a disappointingly high probability for a rainy Saturday! But that was just a fake example, Saturdays are always sunny!! 🤥
What is Naïve Bayes then?
Naïve Bayes is a powerful machine learning technique that uses the Bayes theorem in a naïve way! That is, it assumes the predictors to be independent and conditional on the class label. Let’s build on our previous example. Imagine we have labeled the days in a year as “hot” and “cold”, simply by tagging May-to-October as “hot” and November-to-April as “cold”. Let’s consider a day as “windy” if the wind-speed goes over 30km/hour. Now, you want to know if a given day in Montreal is hot or cold. So, you have a binary classification problem with hot and cold as the labels. And wait a minute, you already know the given day is windy! You are a smart guy and you don’t go to a duel without a sword! So, you check the distribution of windy days over months (see table below).Then you may say, since the given day is windy it is more likely that it is a cold day because there are more windy days between November and April! Congratulations, you were successfully converted into a robot and just unconsciously used a Naïve Bayes classifier!
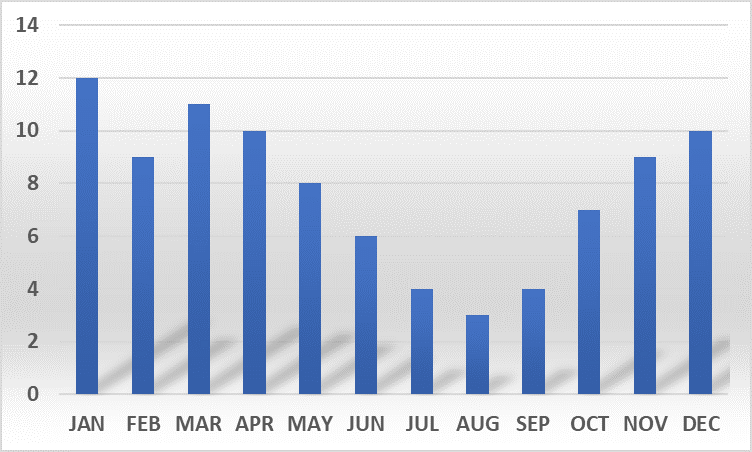
Number of days with wind over 30 km/h in Montreal
Data source: www.theweathernetwork.com
Simple, right? You just calculated the likelihood, based on the figure, 32 days (≈17%) in the “hot” category are windy while the number is almost doubled (61 days, ≈33%) for the “cold” category. You already know that the given day is windy. Having that, the likelihood of the day being cold is: 33% * 50% = 16.5%, and in the same way, the likelihood of the day being hot is: 17% * 50% = 8.5%. You realize that there is half a chance to have cold or hot days as we defined only two categories for our problem, that’s why you see that “50%” in the calculations.
You can have more fun by adding more relative features such as temperature, rainfall, humidity and so on. Then if you are using Naïve Bayes algorithm it makes the naïve assumption and considers all the features equally important and statistically independent. That is, knowing the value of a feature gives no information about another one. Huh, gotchaaa cheater, this assumption is far from being true!! If a day is humid and there is no wind, it is more likely to be a hot day! That’s true, but here is the magic. Although the naïve assumption is not always true, NB has been reported as a successful algorithm in many real-life problems. This may partially imply that everything in this world is not always 100% logical! Whether we like it or not, this “idiot” Bayes works decently, even though the assumptions might look a bit stupid at the first glance.
If you are looking for a fast and easy high-performance algorithm, NB can be your buddy. You can use it in WordStat to do some classification and obtain better conceptual views of your document collections. Here are several examples of applications, you may use NB for identifying spam in your email data set, indexing patient records, or you can train the model and ask it if you’ll like a new book even before reading it!