How to extract news transcripts from LexisNexis documents May 26, 2016 - Blogs on Text Analytics

LexisNexis is one of the world’s largest online databases. It contains thousands of publications in areas of law, business, finance, news, government, medicine, and many other subjects. It is a key point of reference for any researcher. The following is an overview of how to import LexisNexis documents into QDA Miner.
QDA Miner can split a document into several cases and automatically extract numerical, strings, or date variables from each case. Some examples of those structured documents are outputs from journal databases such as Proquest, EndNote, Reference Manager, etc; LexisNexis outputs of news transcripts; legal documents as well as XML data files.
In this example, we will demonstrate how to extract news articles from LexisNexis documents using the Document Conversion Wizard.
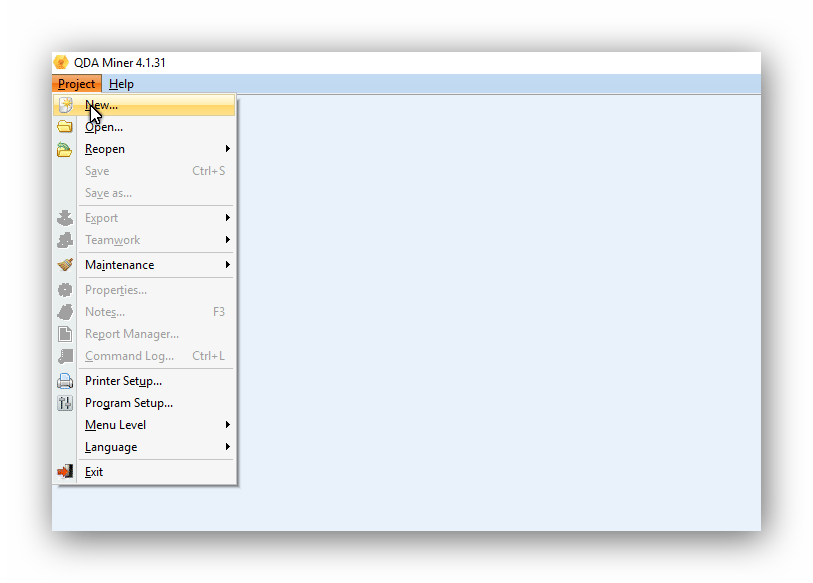
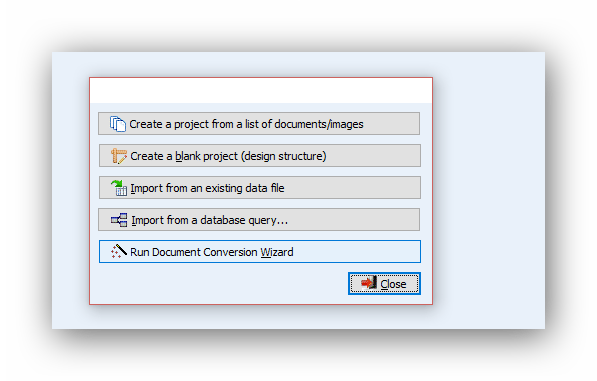
To call the Document Conversion Wizard, select the New command from the Project menu. Click the Run Document Conversion Wizard button.
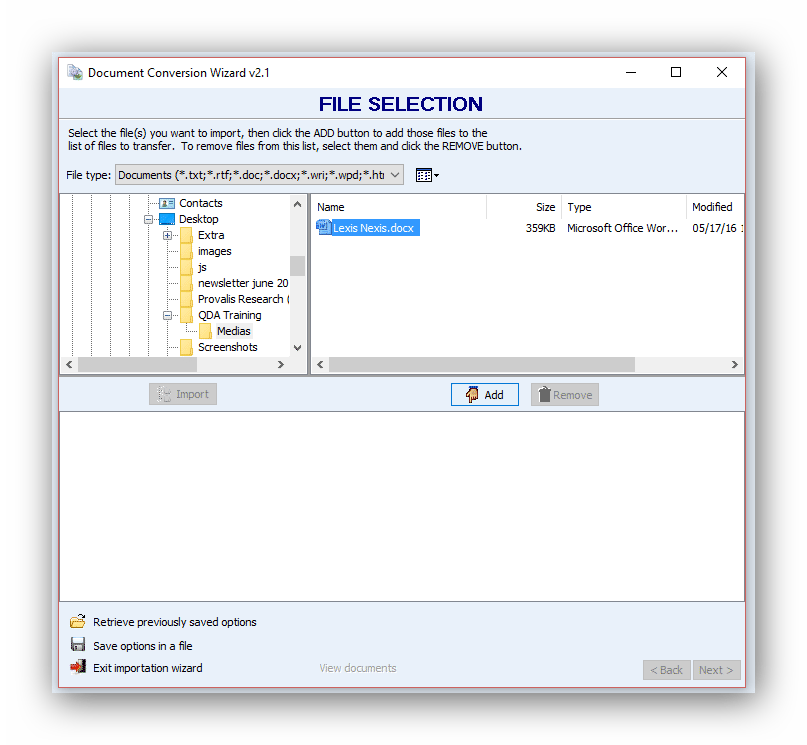
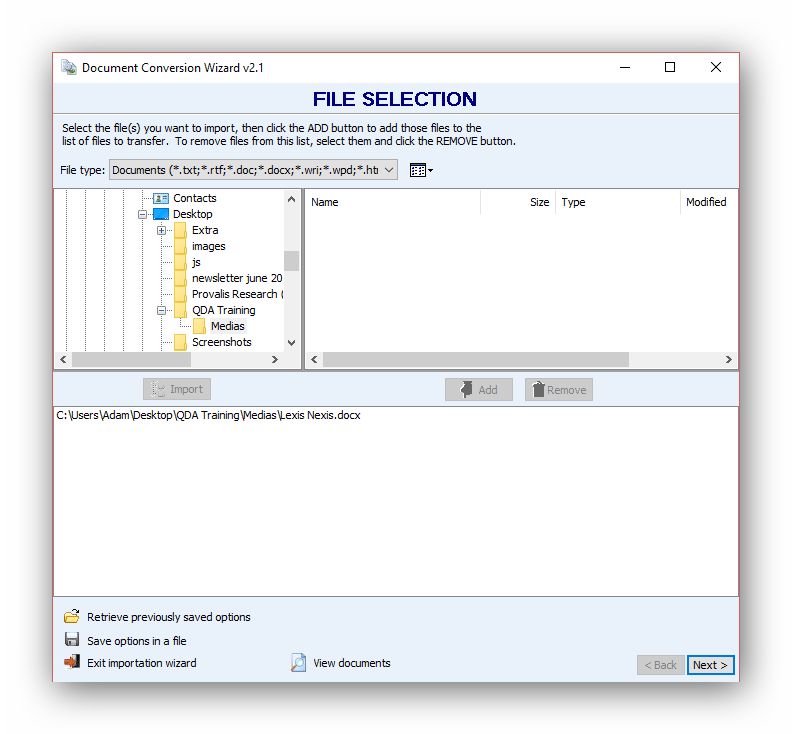
The wizard consists of 4 pages. The first page is used to select files to be imported. The LexisNexis document is stored in the Media folder and we can select it.
Once the document is selected, click Next to move to the next page.
Split one document into cases
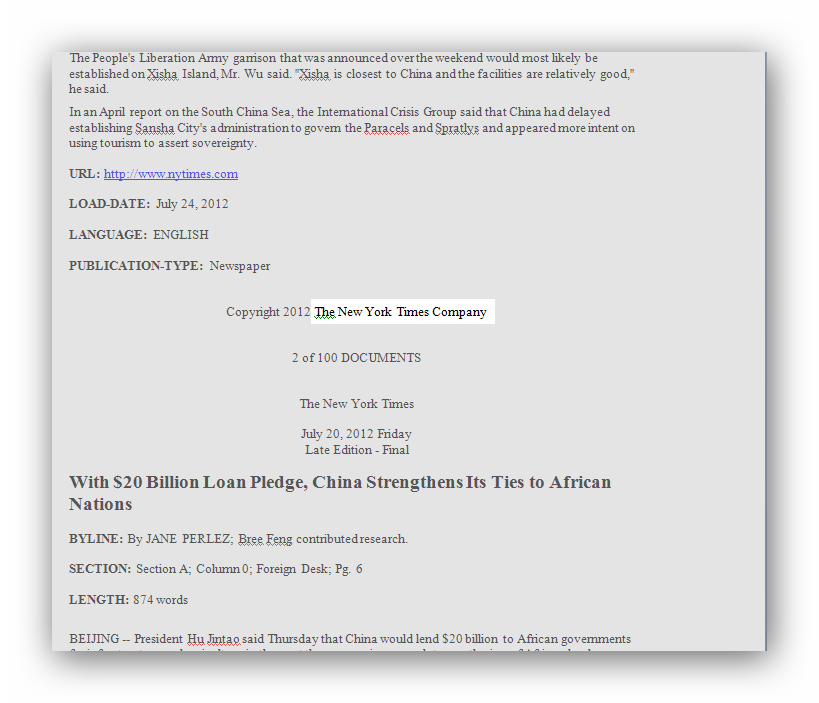
The second page allows us to split long documents into several ones and store each of those into separate cases. It also offers special text processing for importing plain text files, such as removing of extra spaces or hard turns. Our example of a LexisNexis file contains 1000 news articles from the New York Times, each one having a similar header and additional structured information at the end of the article. To split one document into several cases, we need to identify delimiters for each news article. We can use the string ‘’The New York Times Company’’ appearing at the end of each article. We can insert a hard return character at the end of the string just in case such a phrase appears in an article.
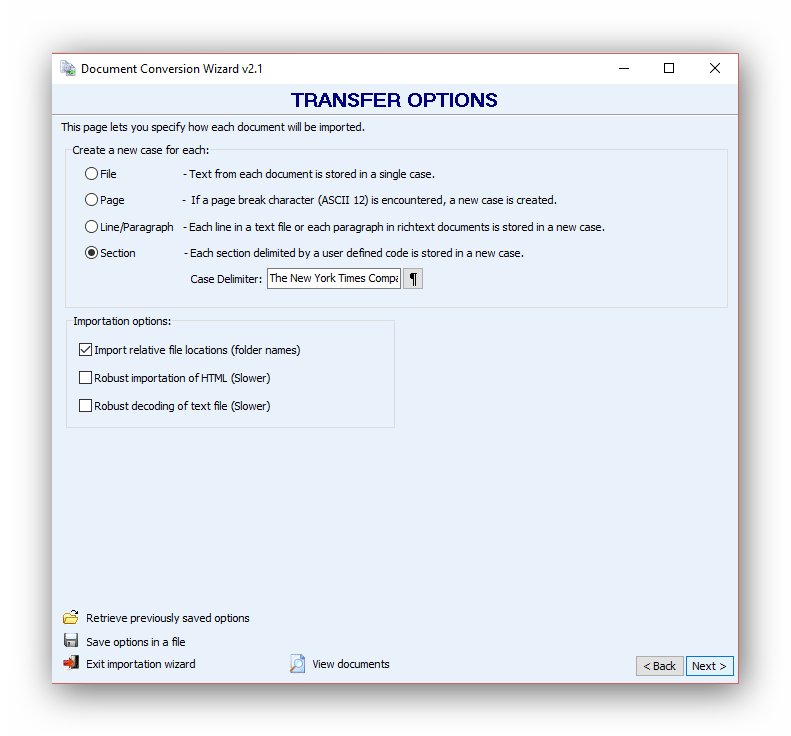
Extract dates
We want to extract the dates. However, there is no prefix or tag immediately before them. Two lines above a date we can read a text string: ‘’The New York Times’’. This is true for all news articles in this file, so we can use it as the date delimiter. When importing dates, the date format should be specified. In our example, the date format is Month – Day – Year or MDY. We will insert two carriage-return characters to specify that the date to be extracted is two lines below the delimiter. The wizard will search anywhere on this line for a Month-Day-Year string pattern expressed in numbers, words, or abbreviations, ignoring all remaining text.

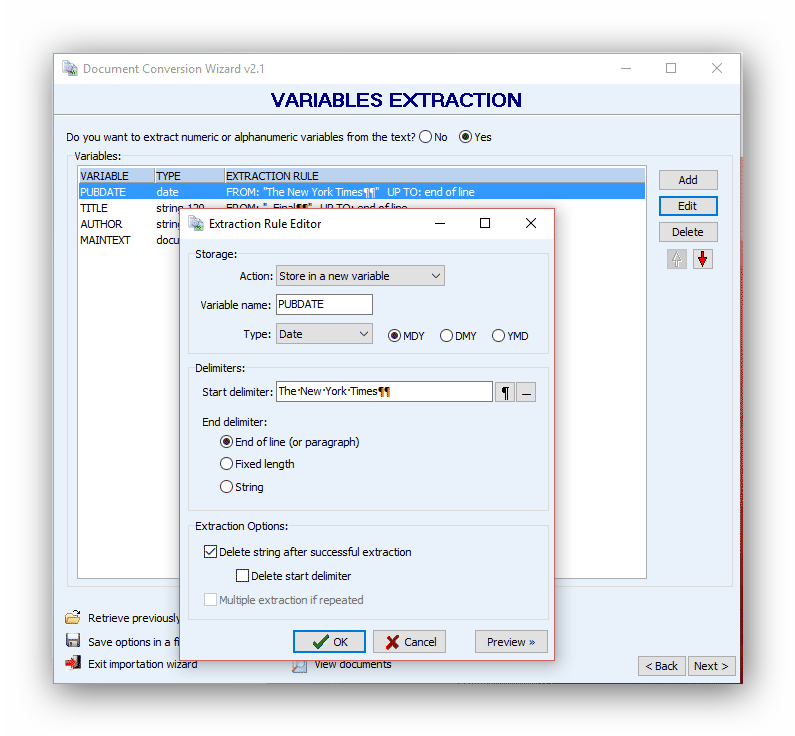
Import the title
We will now import the title. In our example, the string ‘’-Final’’ always appears before article titles. We will use it as a delimiter.

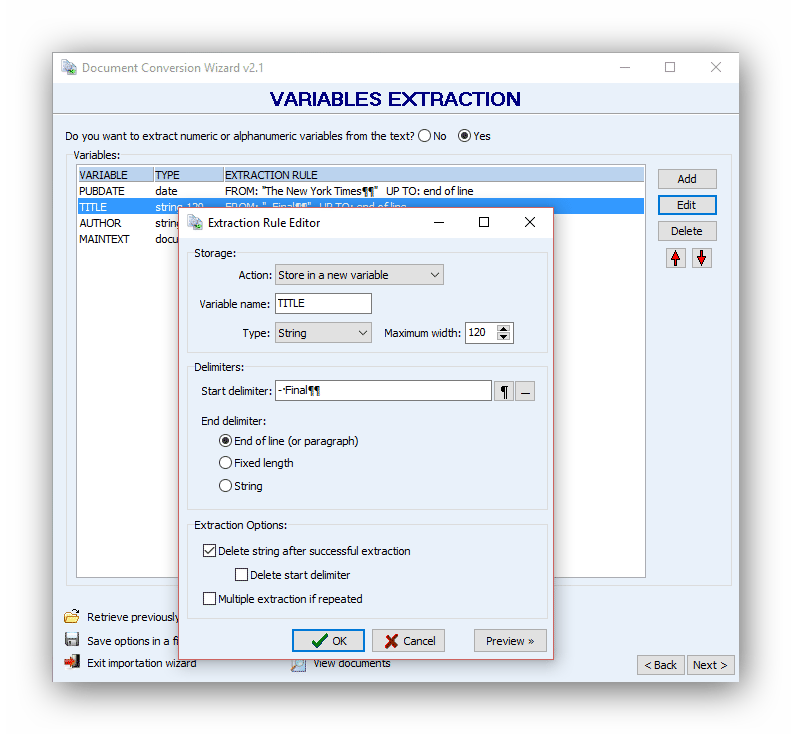
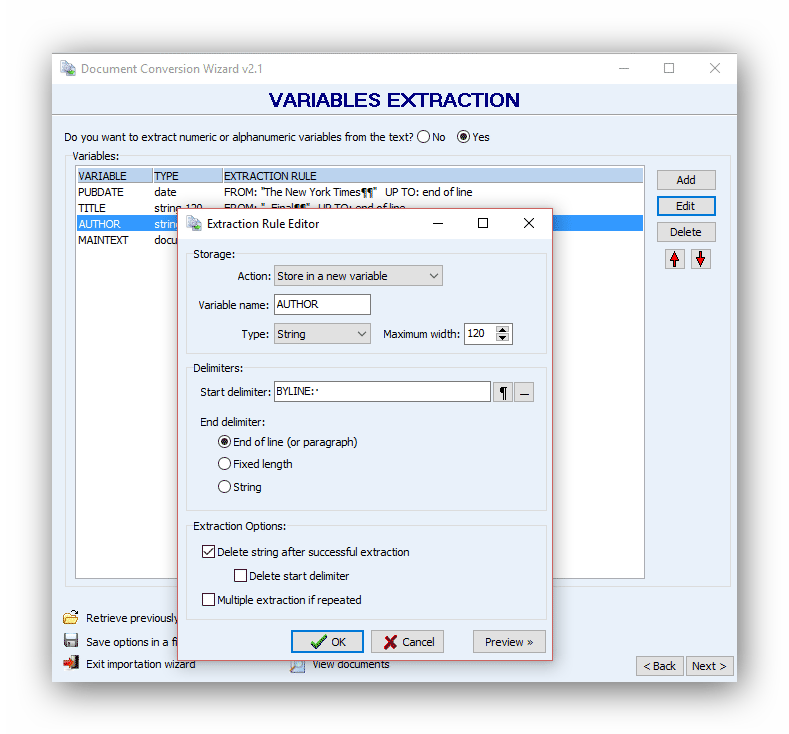
Extract the author
The author’s name is located to the right of ‘’BYLINE’’. We will use it as a delimiter.

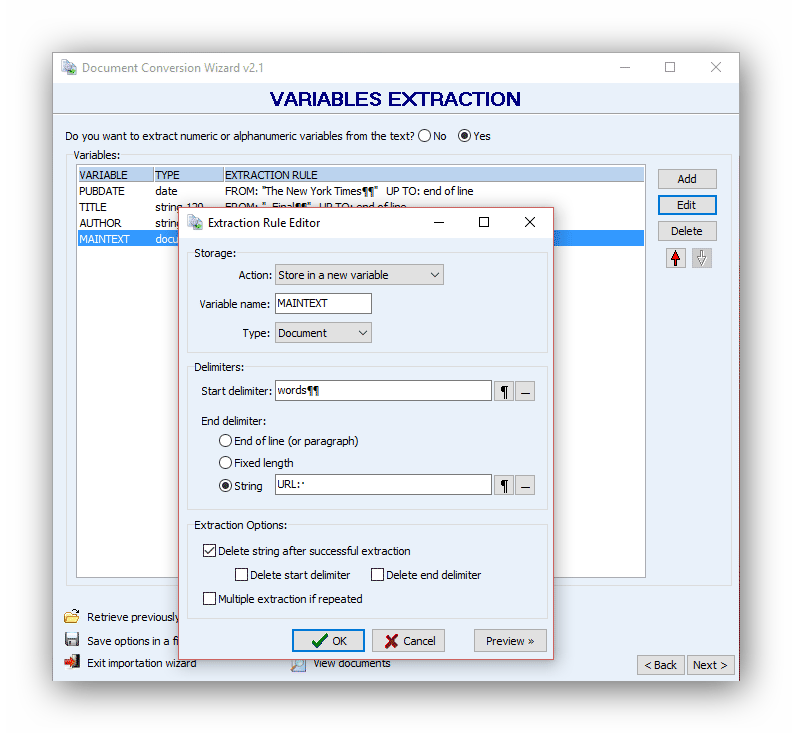
Extract the body of information
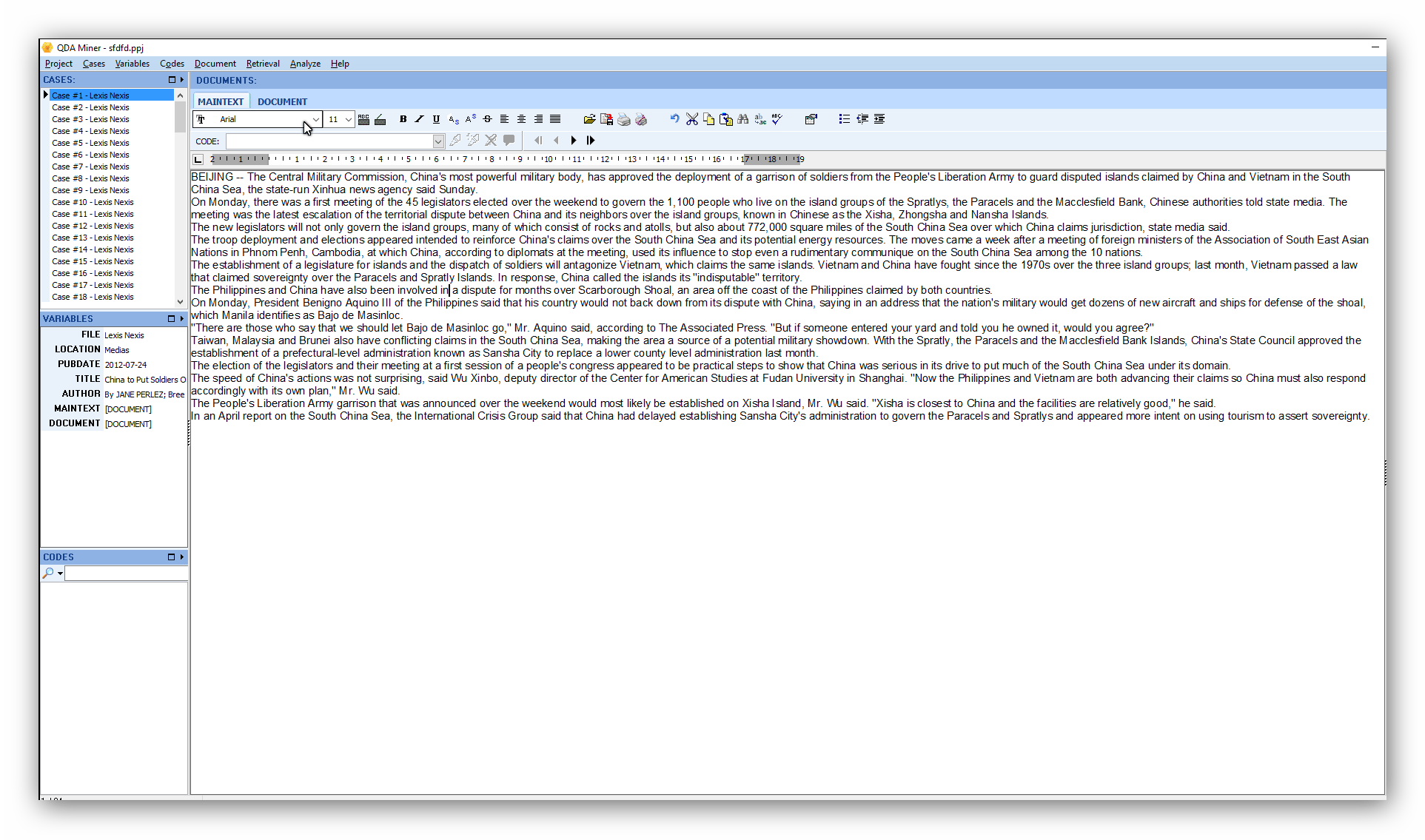
Extracting the body article will require using surrounding information. We will use the ‘’words’’ item at the end of the LENGTH field as the starts delimiter and the ‘’URL:’’ found immediately below every news article.

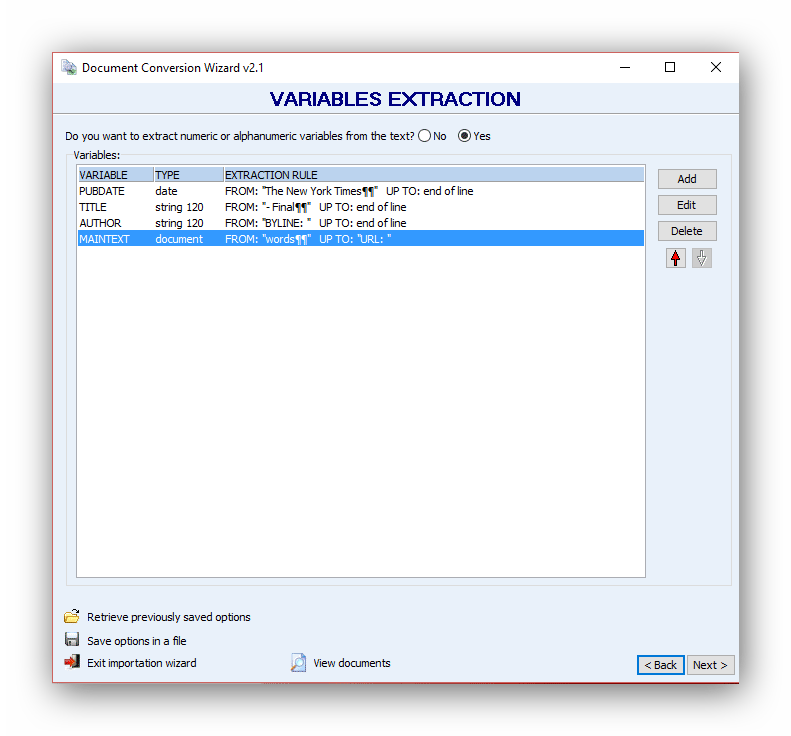
To perform the extraction and store transcripts in a new QDA Miner project, click the Next button.
Create a project
The Preview Table below allows one to view the resulting project file and make sure variables have been extracted properly. Extracting rules for specific types of documents may be saved on the Preview Table and later retrieved with the Retrieve previously saved options button.
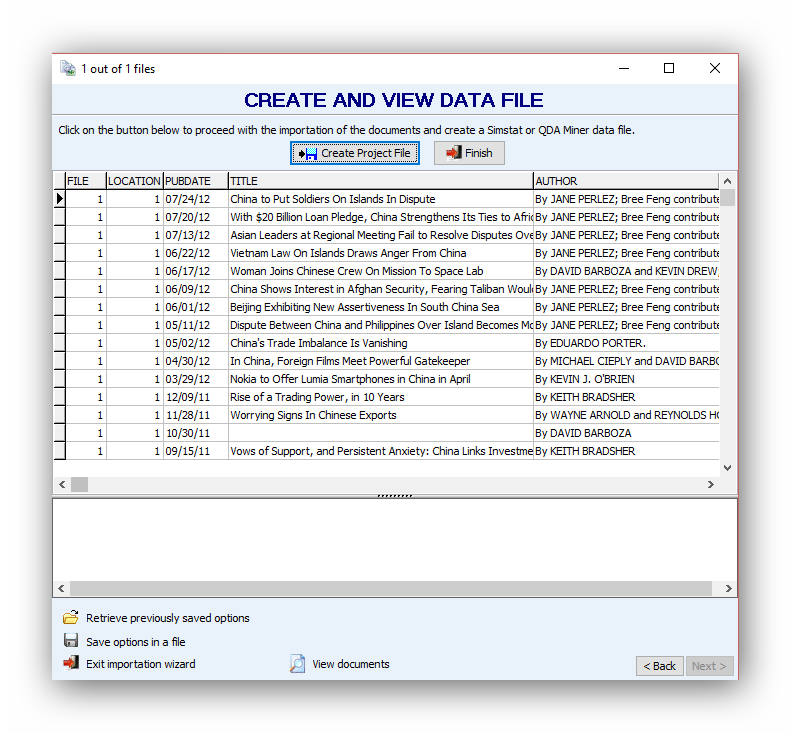
Once all extraction rules have been specified, we can move to the last page to create the project. Click the Create Project File button. If changes in the extraction rules are needed, you can go back to previous pages by clicking the Back button.
To watch the tutorial video on how to import structured documents like LexisNexis documents in QDA Miner, click here