WORDSTAT

Powered by AI since 1998
Content analysis and text mining software for fast and precise processing of large amounts of unstructured information
TEXT MINING SOFTWARE
WordStat is a flexible and easy-to-use text mining software. It can be used by anyone who needs to quickly extract and analyze information from large amounts of documents. The software allows to:
- Quickly extract words, phrases, named entities, themes, trends, patterns.
- Explore content with state of the art topic modeling.
- Relate content to structured information, including numerical and categorical data.
- Import from many sources such as Word, Excel, PDF’s, online surveys, social media, emails, reference management tools, and many more.
- Automatically classify content into categories by building and applying categorization dictionaries or supervised machine learning models.
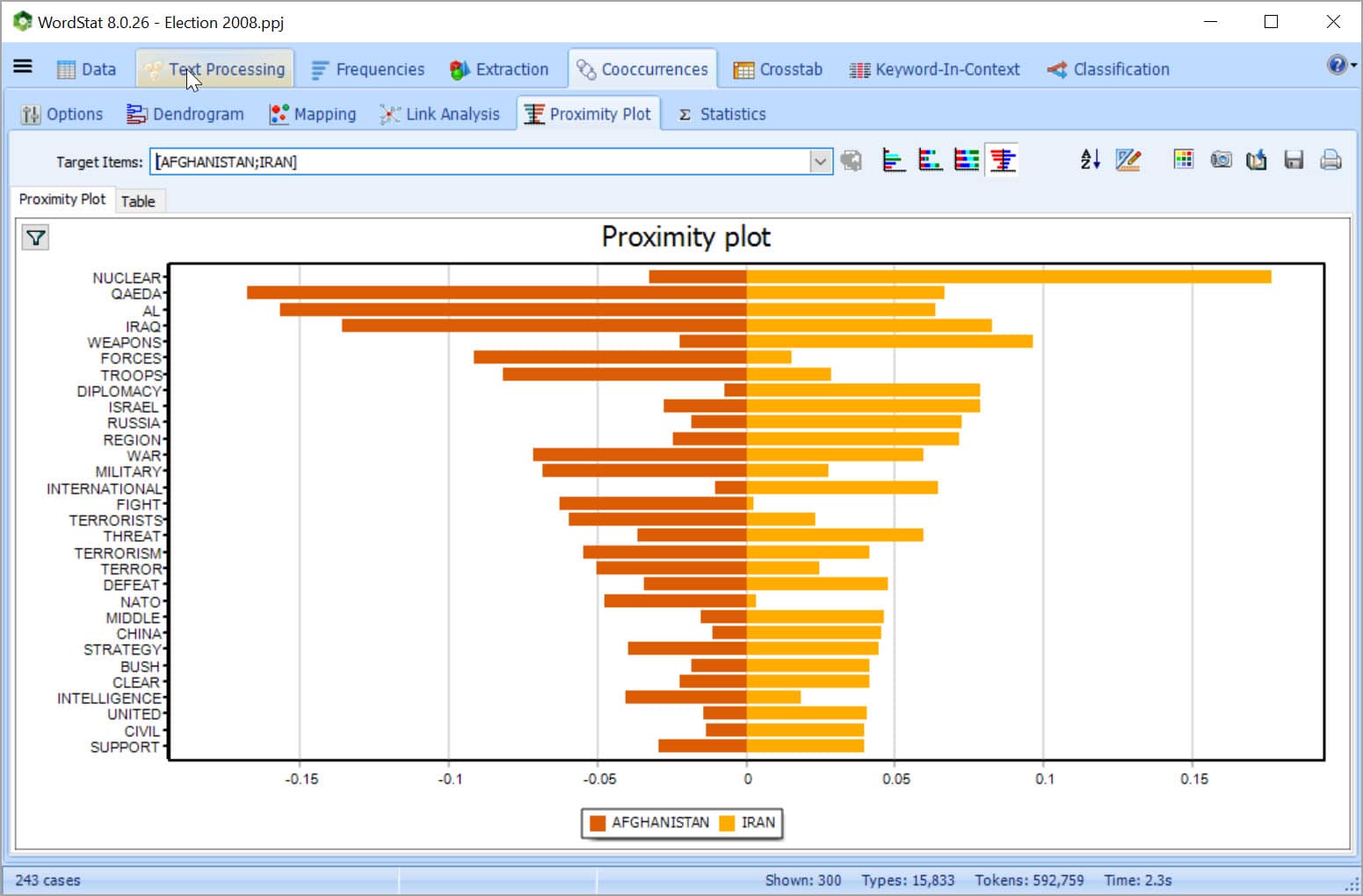
- Use interactive visualization tools: clustering, multidimensional scaling, proximity plots, correspondance analysis plot, and many more.
- Verify or dig deeper into your analysis by going back to the text from almost any feature, chart or graph.
Our text mining software can be used in many applications such as analysis of open-ended responses, social media data, content analysis of news coverage, fraud detection, legal documents, medical records, corporate reports, and more.
WordStat Key Features
EXPLORE DOCUMENT CONTENT USING TEXT MINING
• Analyze large amounts of unstructured information with WordStat. The software can process 25 million words per minute, quickly extract themes and automatically identify patterns using clustering, multidimensional scaling, proximity plots and more.
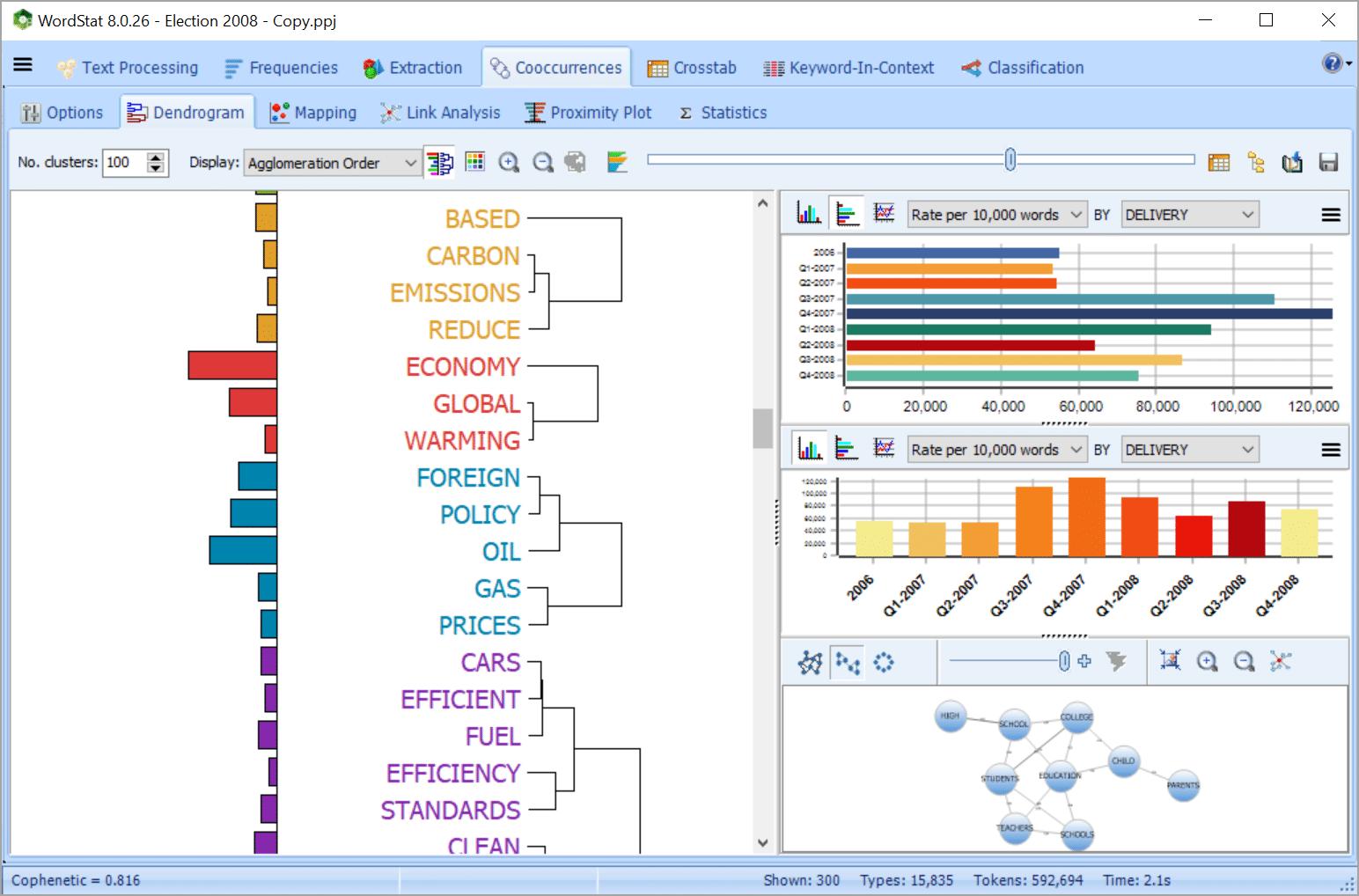
QUICKLY EXTRACT MEANING USING EXPLORER MODE
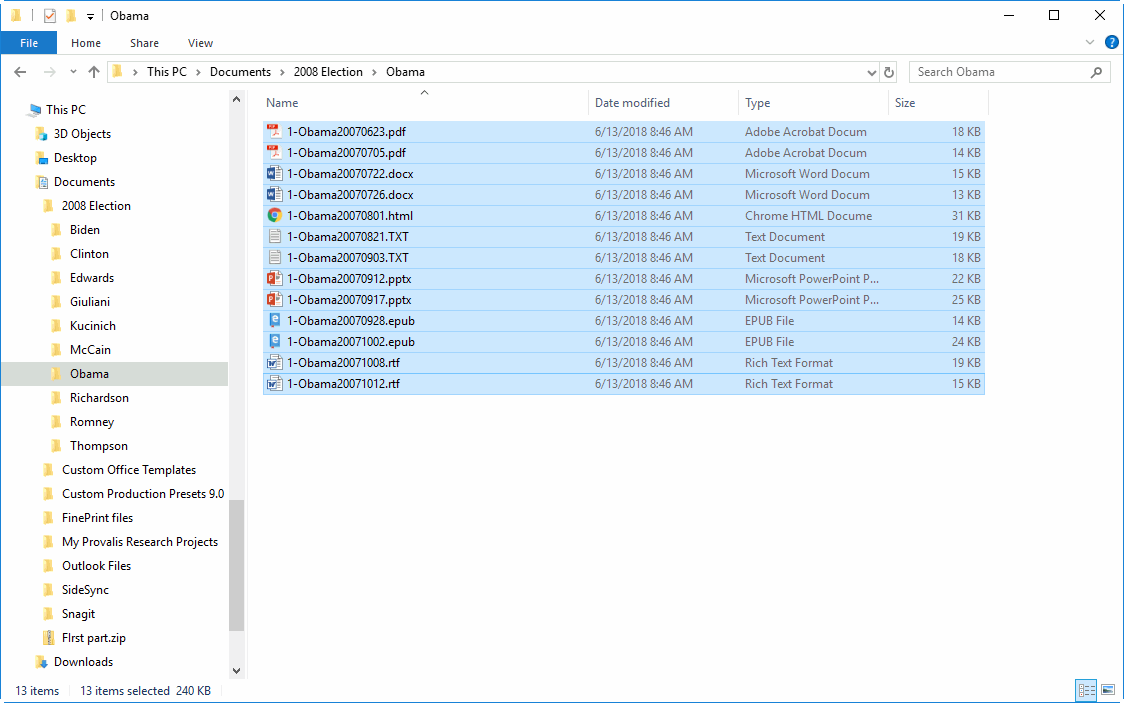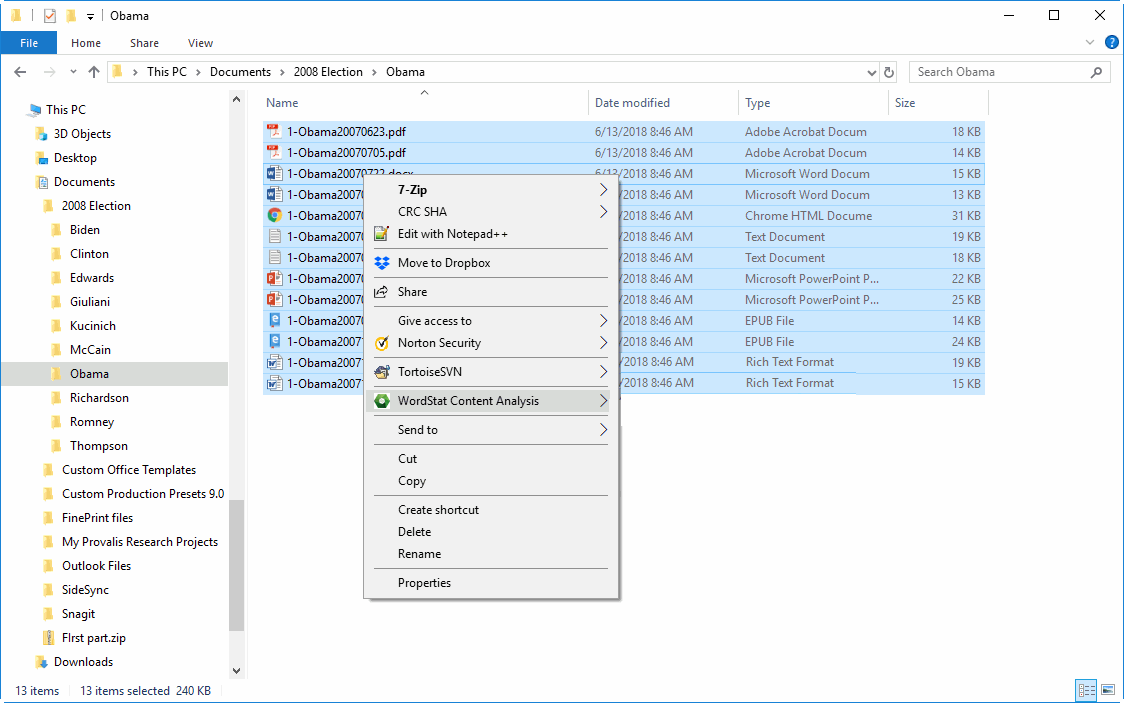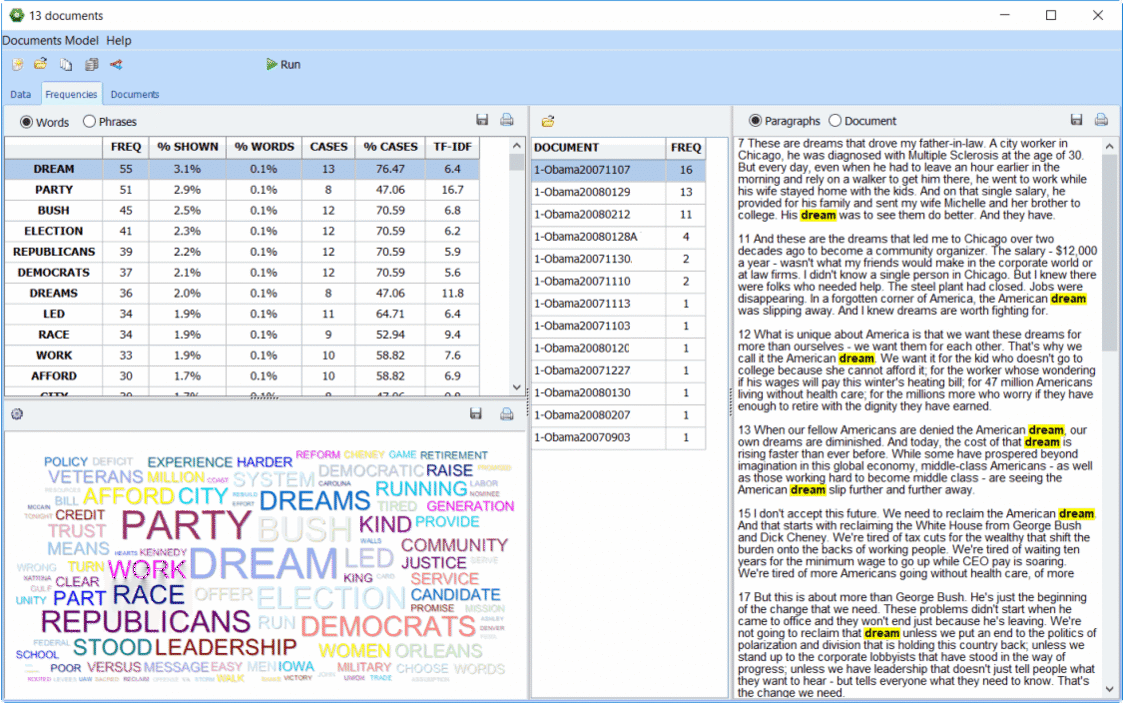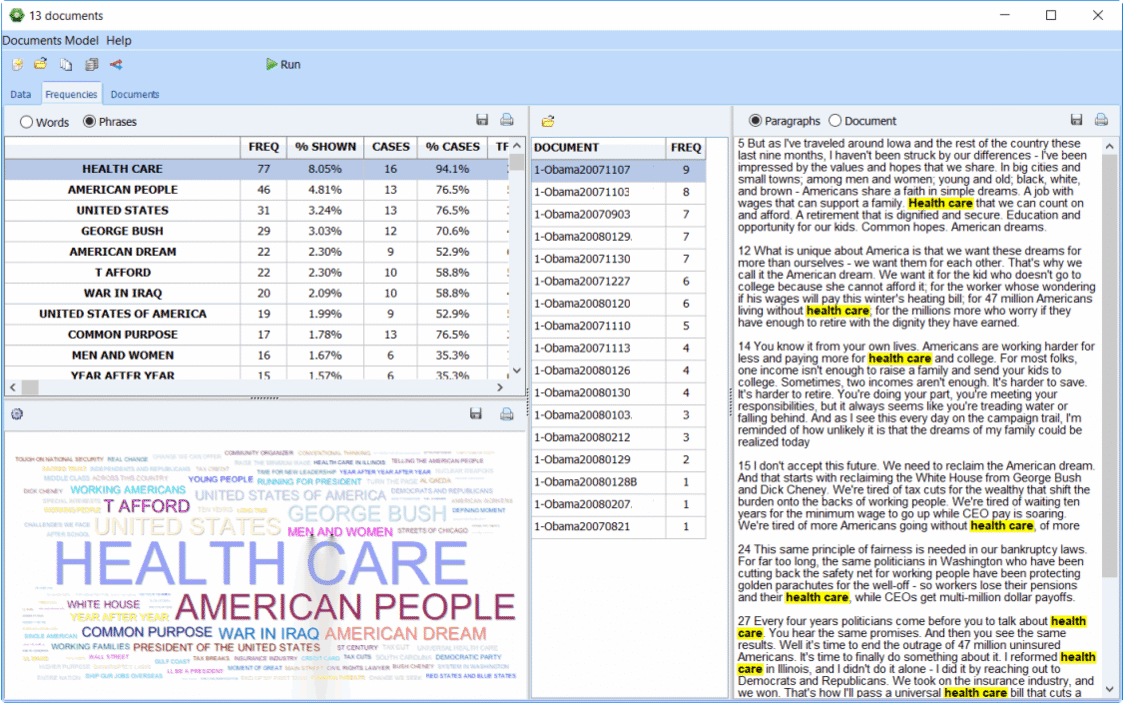
• Quickly and easily extract meaning from large amounts of text data using Explorer mode especially made for those with little text mining experience. In one click, you can extract the most frequent words, phrases and the most salient topics in your documents.
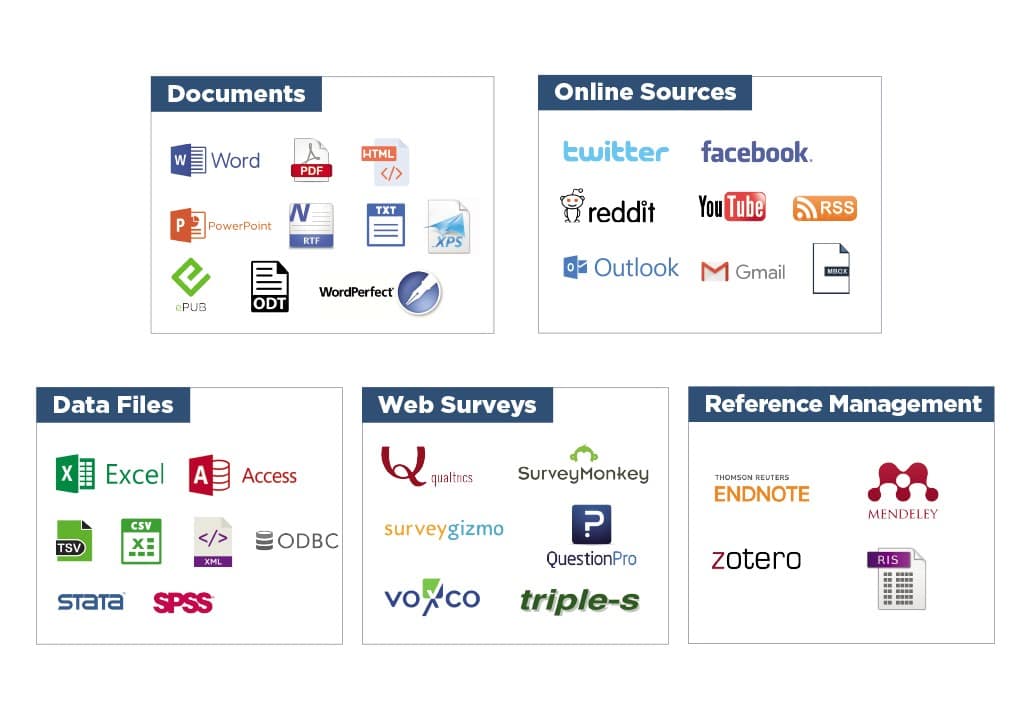
IMPORT FROM MANY SOURCES
• Import Word, Excel, HTML, XML, SPSS, Stata, NVivo, PDFs, as well as images. Connect and directly import from social media, emails, web survey platforms, and reference management tools.
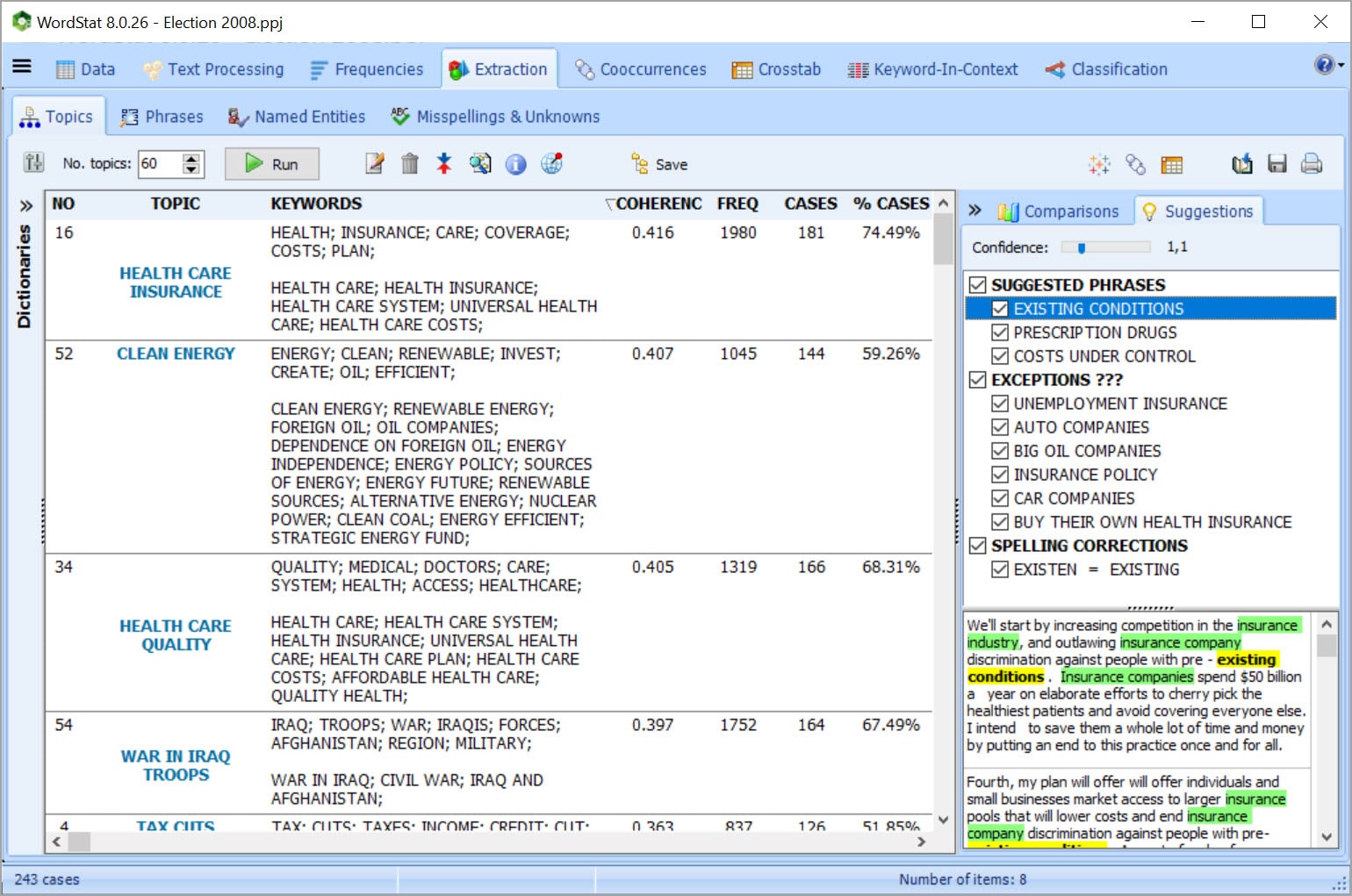
EXTRACT THE MOST SALIENT TOPICS USING TOPIC MODELING
•Get a quick overview of the most salient topics from very large text collections using state-of-the-art automatic topic extraction based on words, phrases and related words (including misspellings).
EXPLORE CONNECTIONS
•Explore relationships among words or concepts and retrieve text segments associated with specific connections.
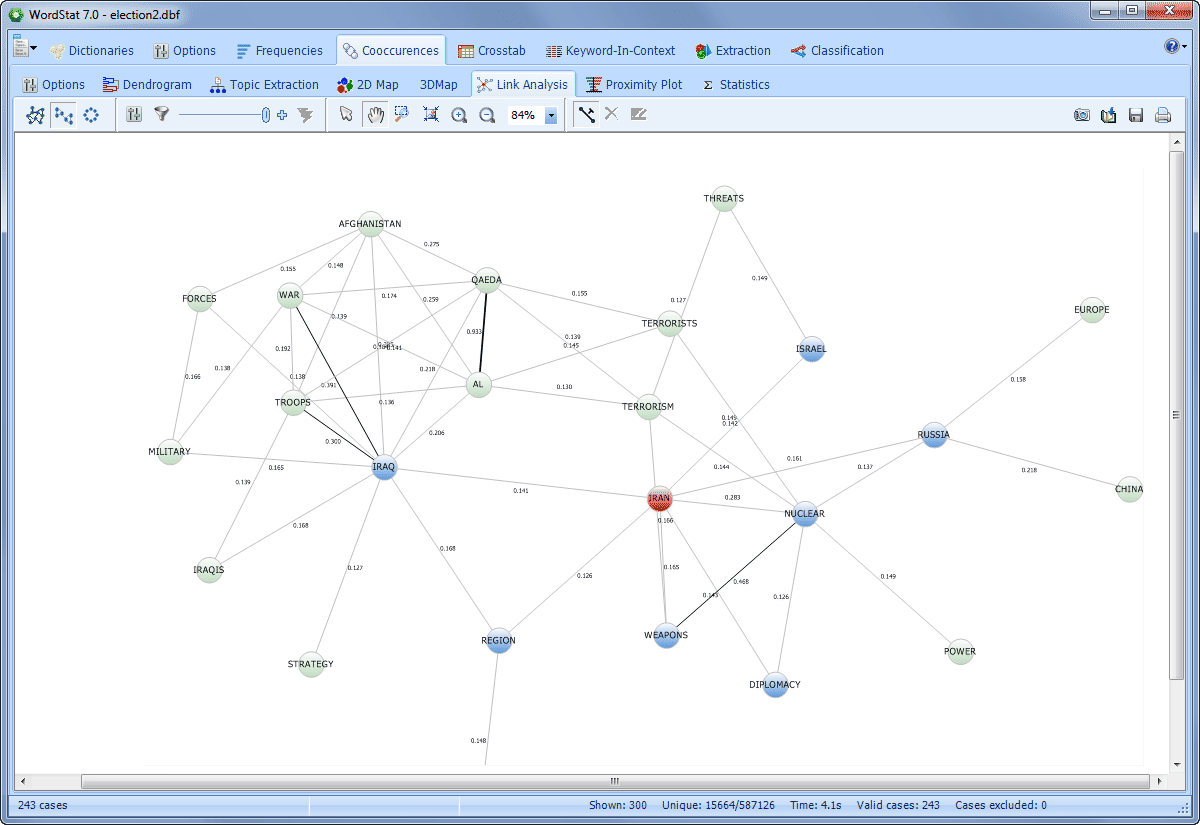
RELATE TEXT WITH STRUCTURED DATA
• Explore relationships between unstructured text and structured data such as dates, numbers or categorical data for identifying temporal trends or differences between subgroups or for assessing relationships with rating or other kinds of categorical or numerical data with statistical and graphical tools (correspondence analysis, heatmaps, bubble charts, etc.).
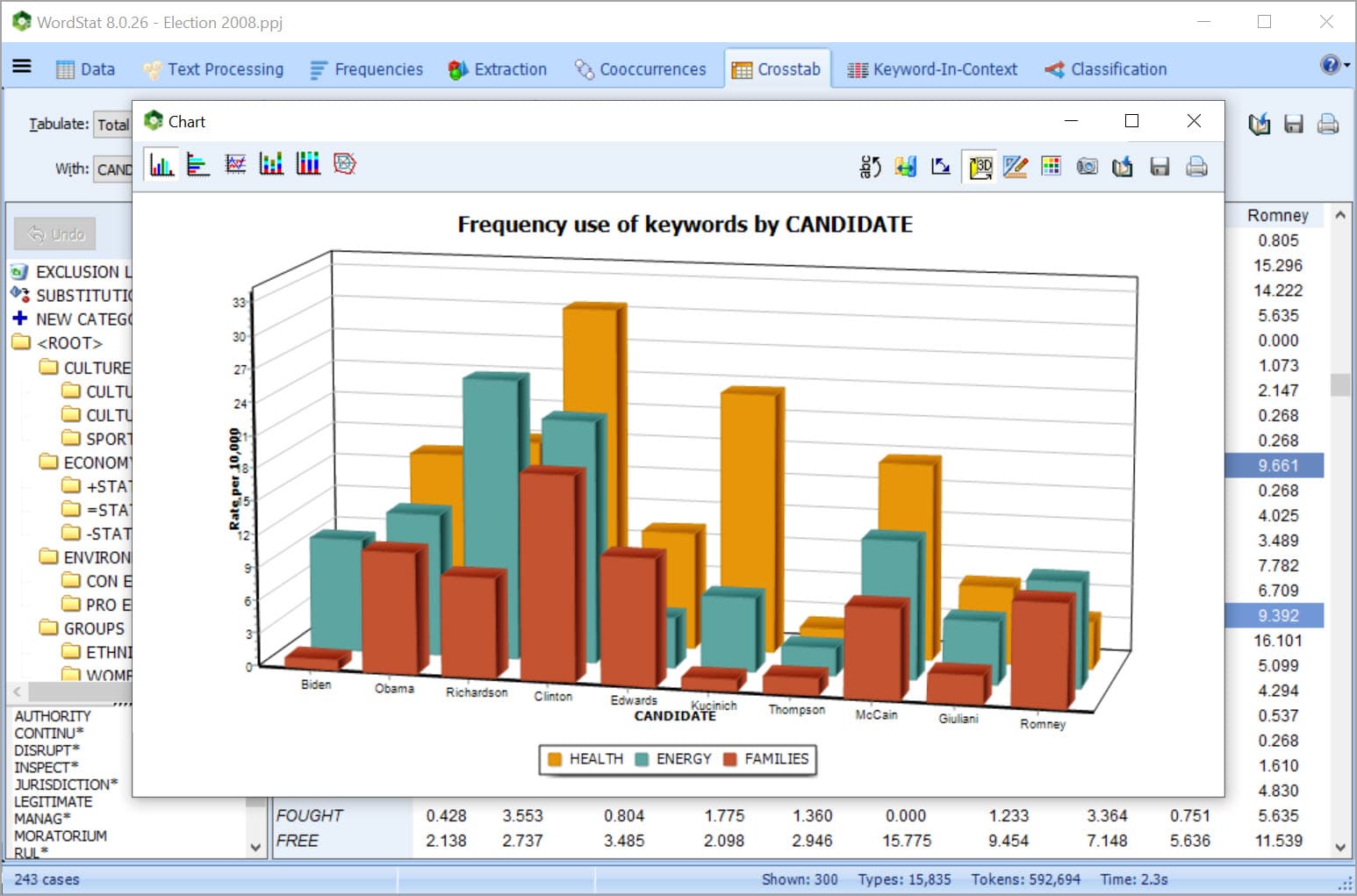
AUTOMATICALLY EXTRACT NAMED ENTITIES
• Automatically extract named entities that can be added to the categorization dictionary using an easy drag-and-drop-operation.
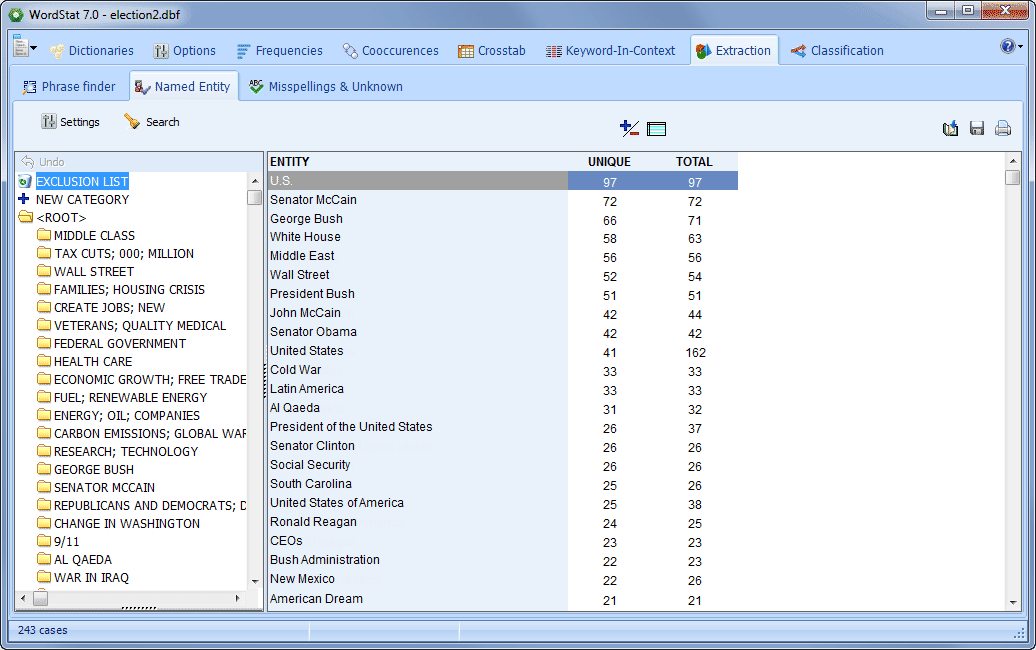
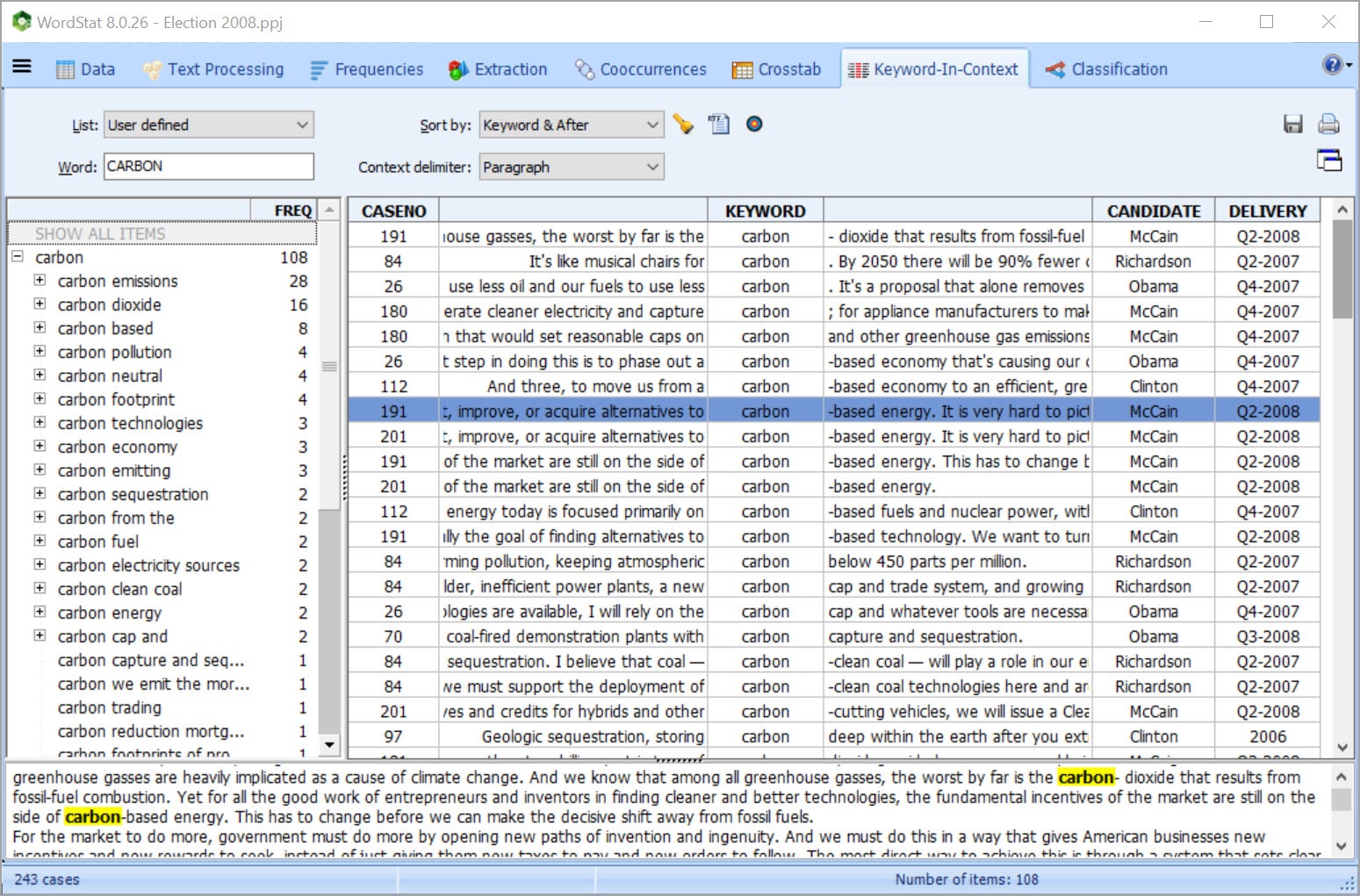
RETURN TO SOURCE DOCUMENT IN ONE CLICK
• Verify or dig deeper into your analysis by going back to the text from almost any feature, chart or graph. You can use the Keyword Retrieval or Keyword-in-Context features to retrieve sentences, paragraphs or whole documents. This is particularly helpful when building taxonomies or for word-sense disambiguation. You can also attach QDA Miner codes to retrieved segments
TRANSFORM TEXT USING PYTHON SCRIPTS
• Use Python script and its full range of open-source libraries to preprocess or transform text documents for analysis in WordStat.

CATEGORIZE YOUR TEXT DATA USING DICTIONARIES
• Achieve full text analysis automation using existing dictionaries or create your own categorization model with words, phrases, proximity rules and more.
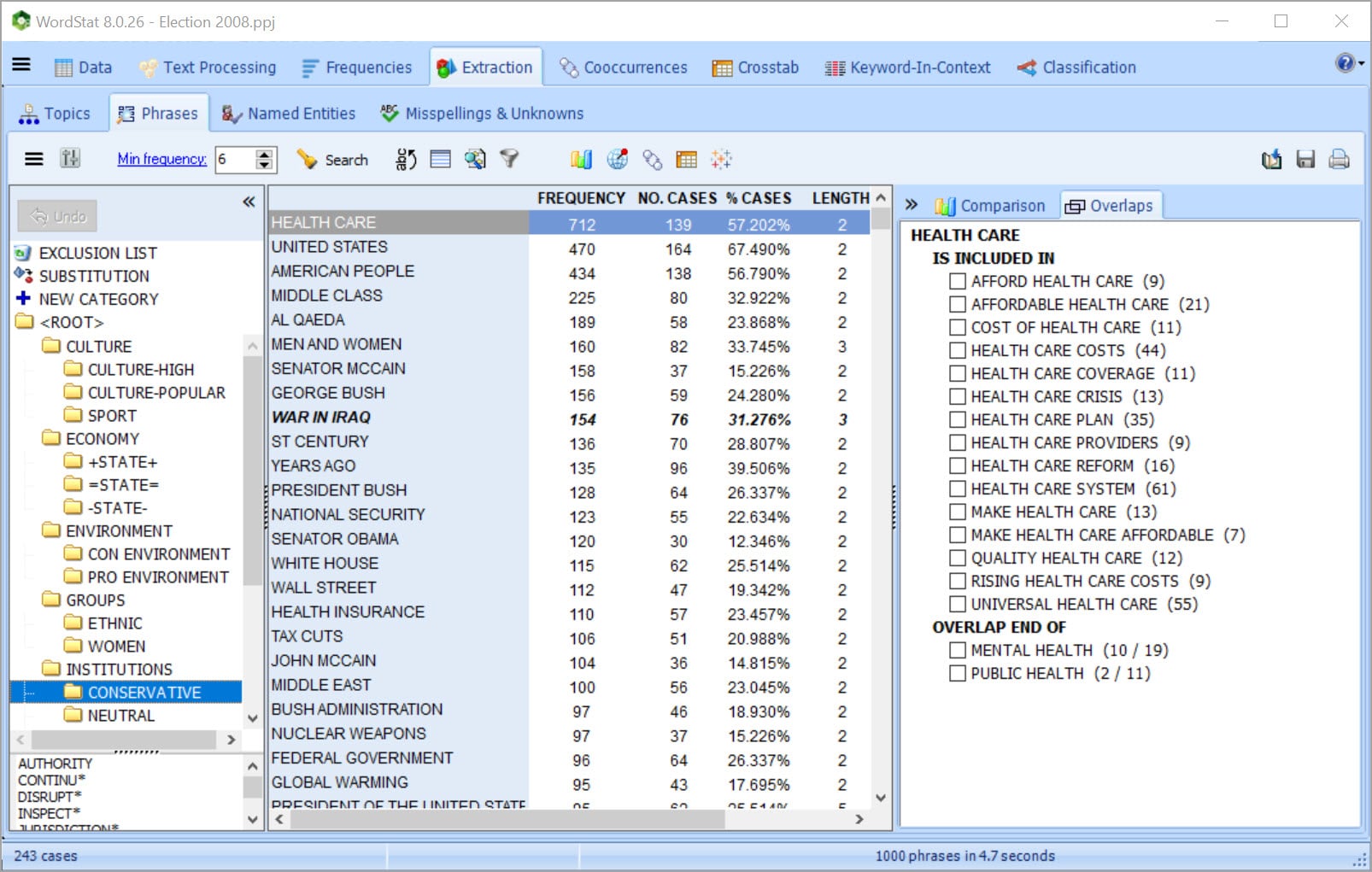
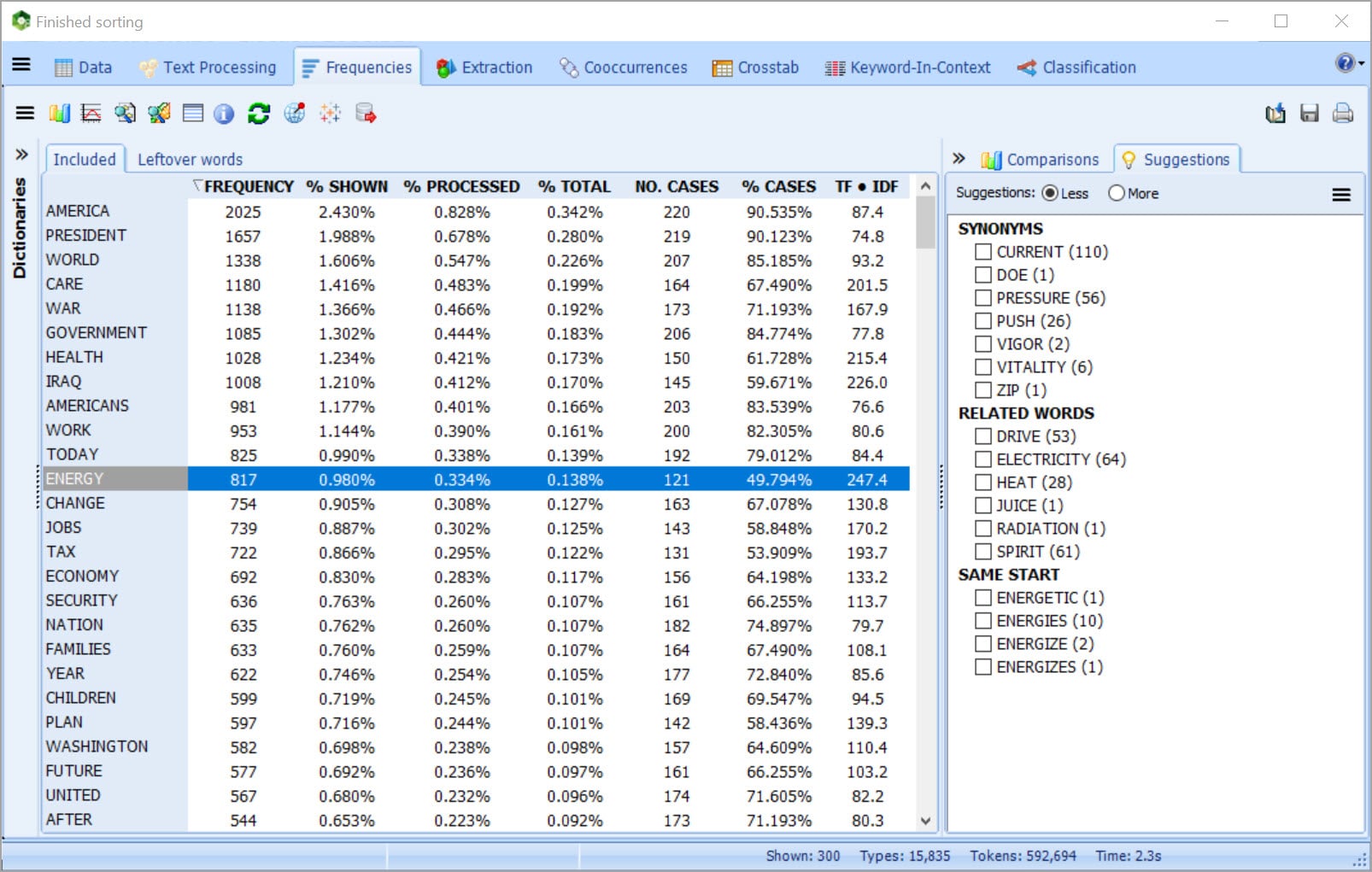
GET UNIQUE ASSISTANCE FOR DICTIONARY BUILDING
• Build your dictionary faster with tools for extracting common phrases and technical terms and for quickly identifying in your text collection misspellings, synonyms, antonyms and related words.
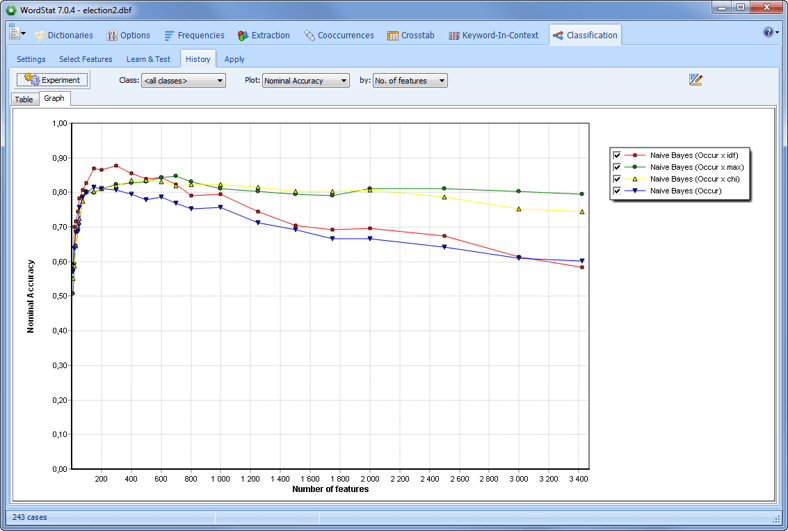
CATEGORIZE YOUR TEXT DATA USING MACHINE LEARNING
• Develop and optimize automatic document classification models using Naïve Bayes and K-Nearest Neighbours.
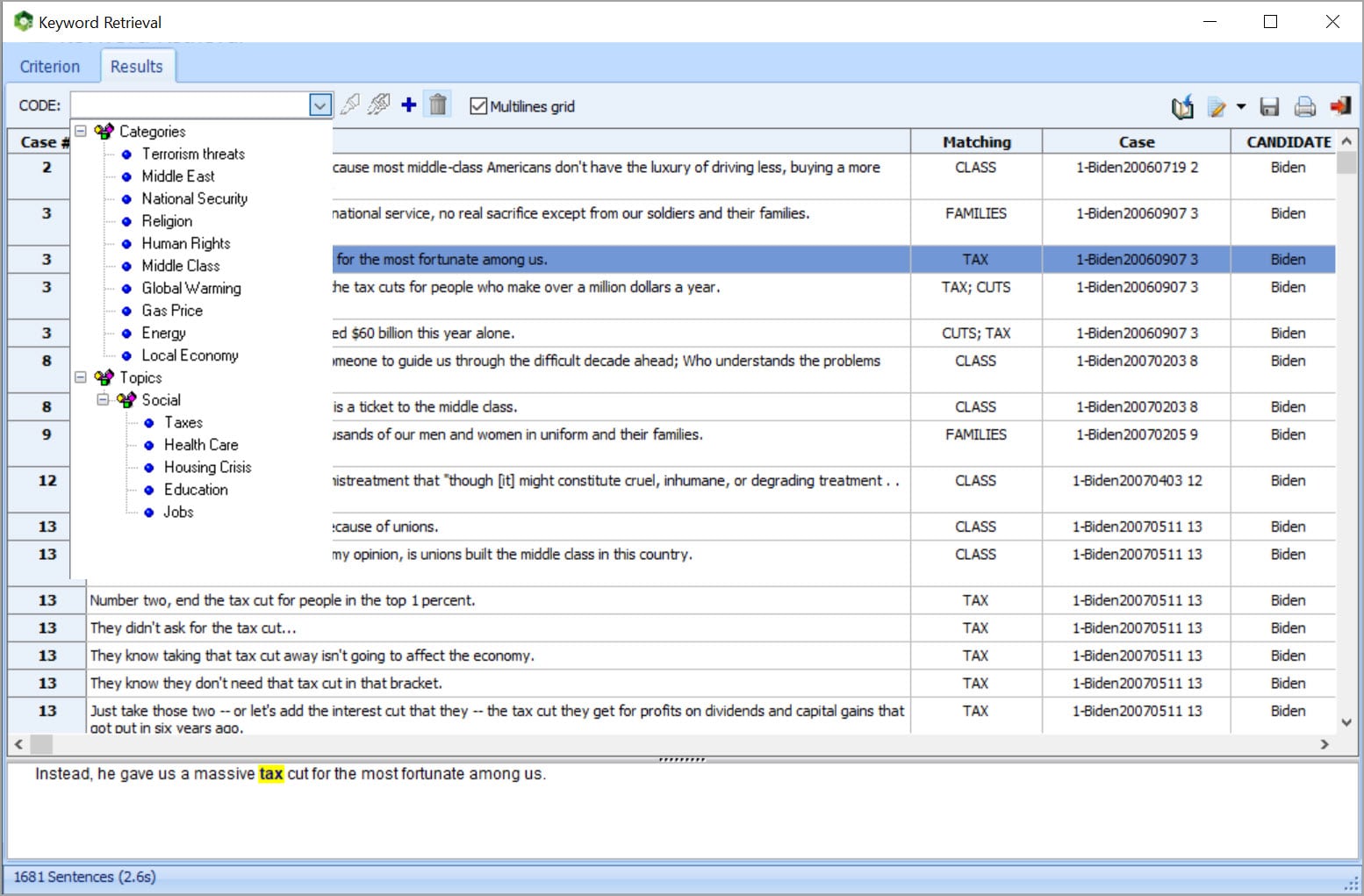
PERFORM QUALITATIVE CODING
• Combine WordStat with a state-of-the-art qualitative coding tool (QDA Miner) for more precise exploration of data or more in-depth analysis of specific documents or extracted text segments when needed.
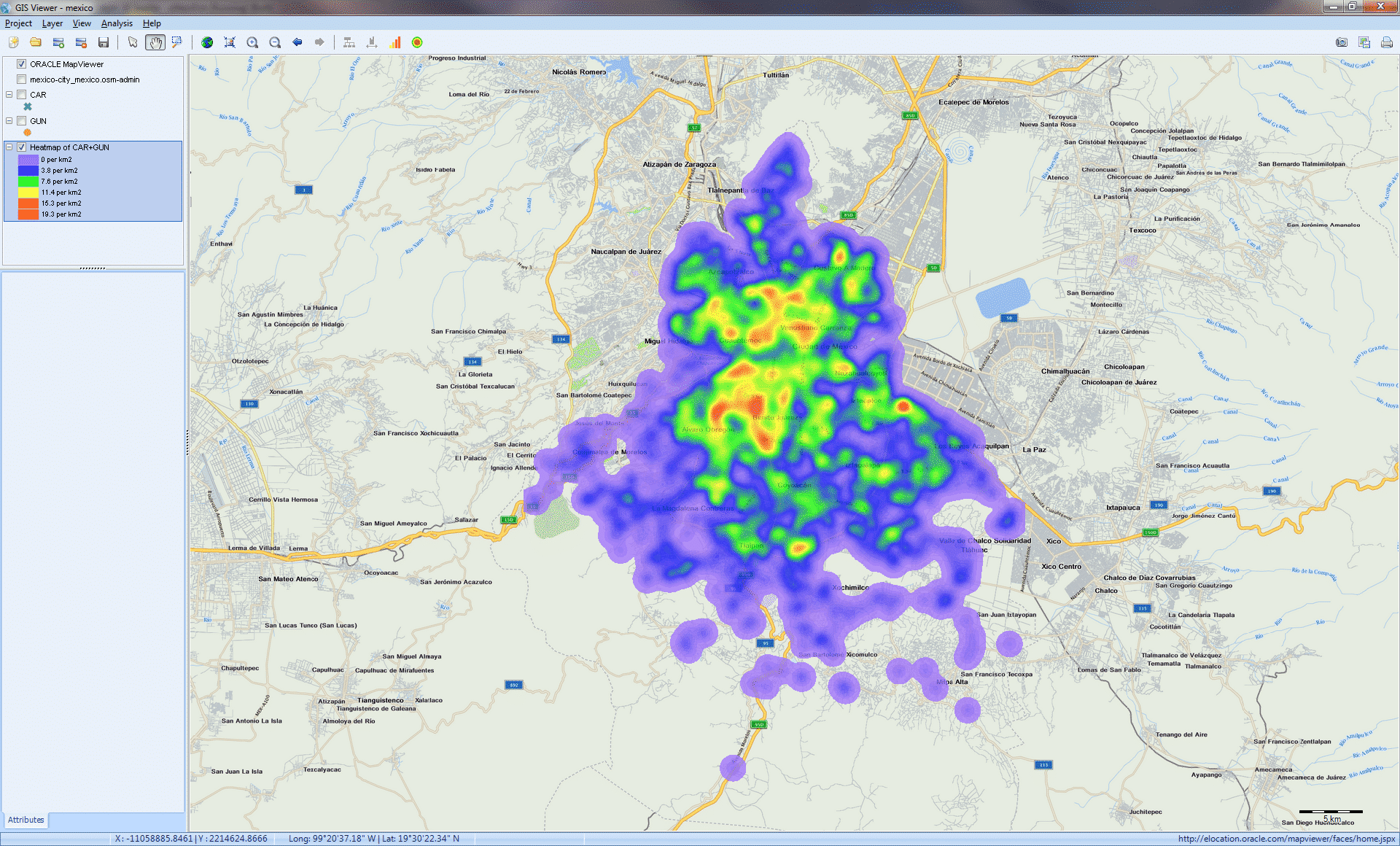
TRANSFORM UNSTRUCTURED TEXT INTO INTERACTIVE MAPS (GIS MAPPING)
• Relate unstructured text data with geographic information and create interactive plots of data points, thematic maps, and heatmaps, along with a geocoding web service for transforming location names, postal codes and IP addresses into latitude and longitudes.
EXPORT RESULTS
• Easily export text analysis results to common industry file formats such as Excel, SPSS, ASCII, HTML, XML, MS Word and graphs such as PNG, BMP and JPEG.