

Content analysis and text mining software for fast and precise processing of large amounts of unstructured information
Content analysis and text mining software for fast and precise processing of large amounts of unstructured information
CONTENT ANALYSIS AND TEXT MINING SOFTWARE
WordStat is a flexible and easy-to-use text analysis software – whether you need text mining tools for fast extraction of themes and trends, or careful and precise measurement with state-of-the-art quantitative content analysis tools. WordStat can be used by anyone who needs to quickly extract and analyze information from large amounts of documents. Our content analysis and text mining software can be used in many applications such as analysis of open-ended responses, business intelligence, content analysis of news coverage, fraud detection and more. WordStat‘s seamless integration with SimStat – our statistical data analysis tool – QDA Miner – our qualitative data analysis software – and Stata – the comprehensive statistical software from StataCorp, gives you unprecedented flexibility for analyzing text and relating its content to structured information, including numerical and categorical data.
DOWNLOAD FREE TRIAL REQUEST A WEB DEMO
EXPLORE DOCUMENT CONTENT USING TEXT MINING
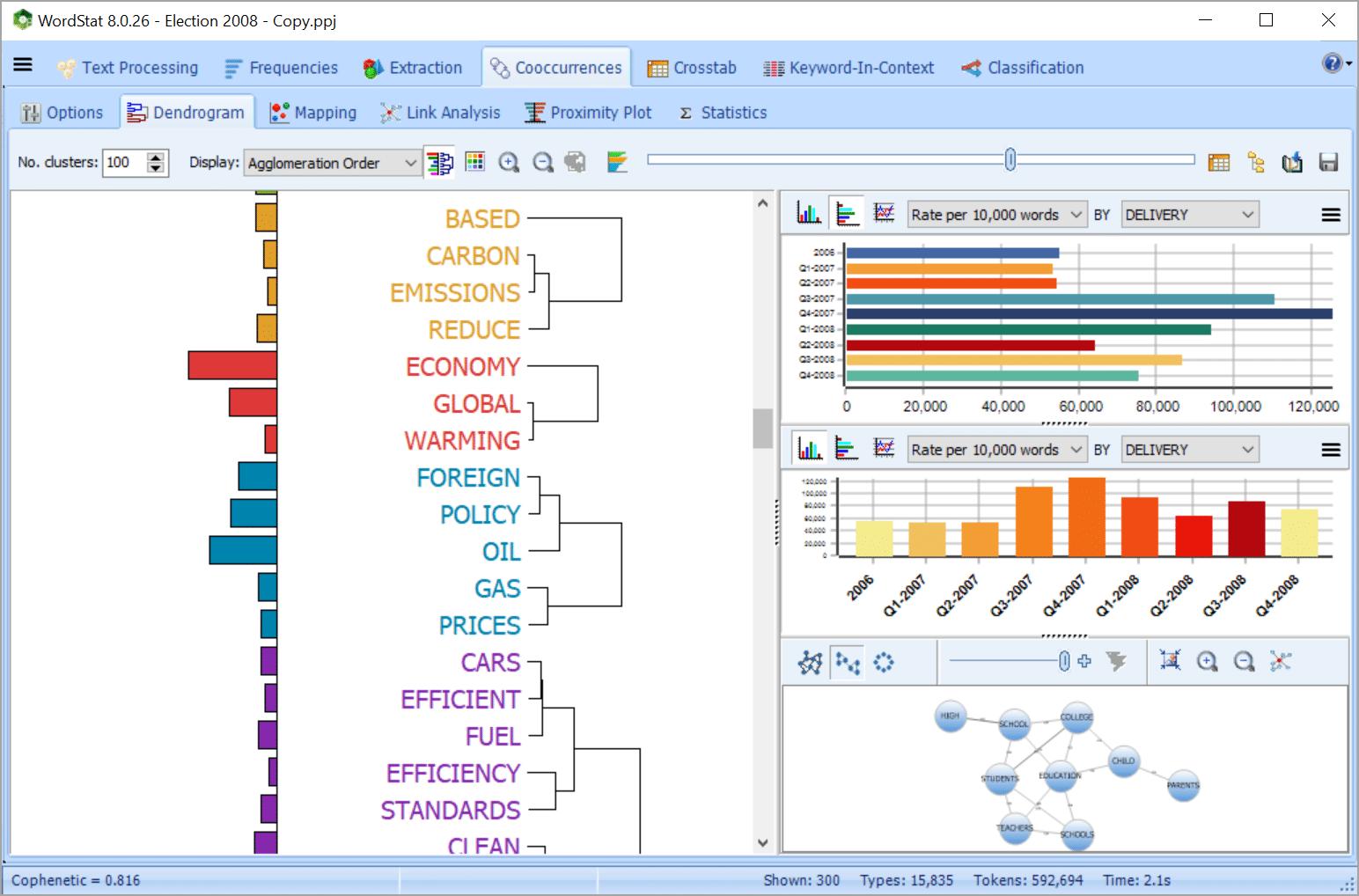
QUICKLY EXTRACT MEANING USING EXPLORER MODE
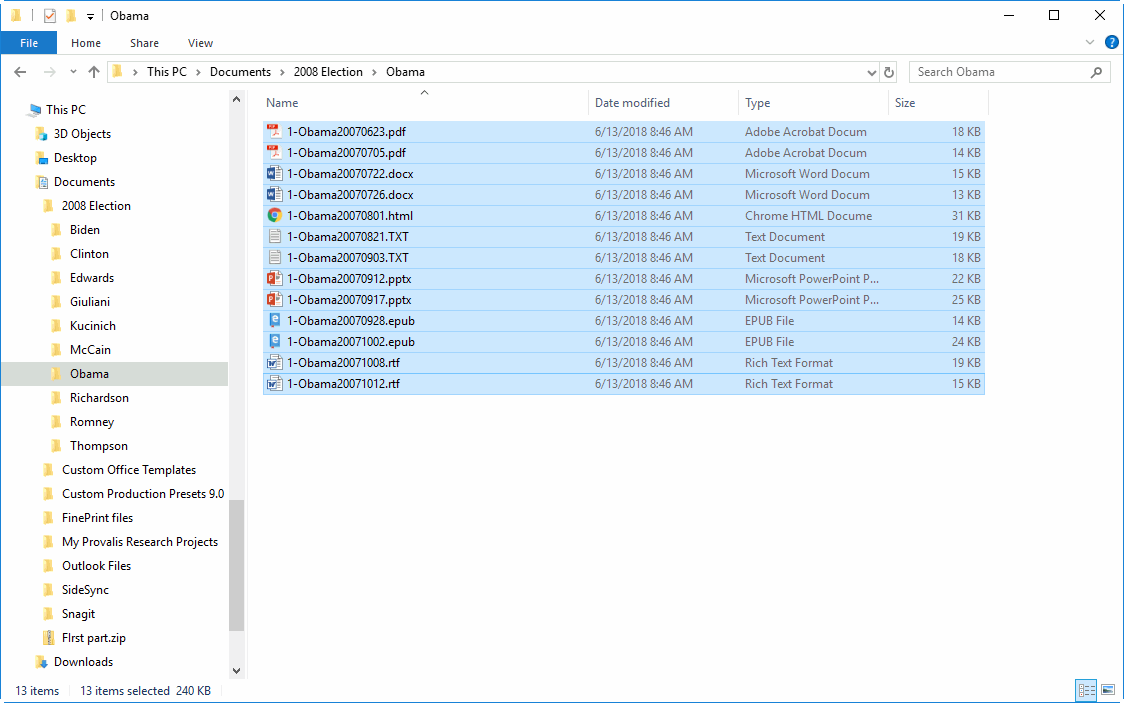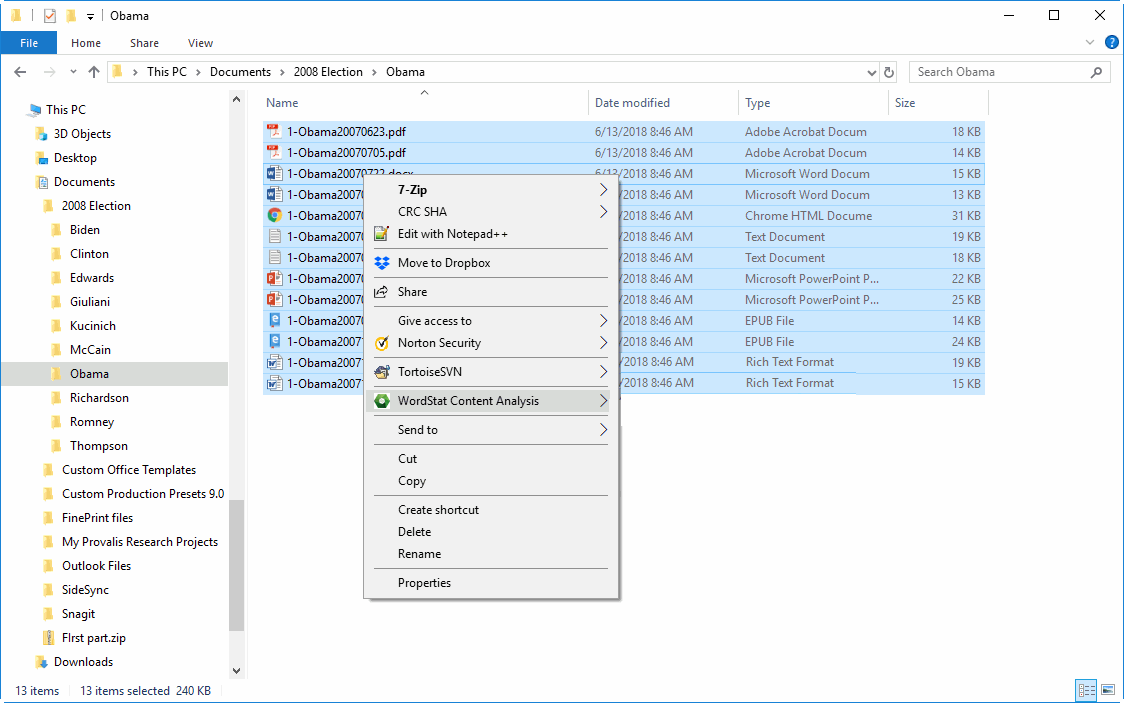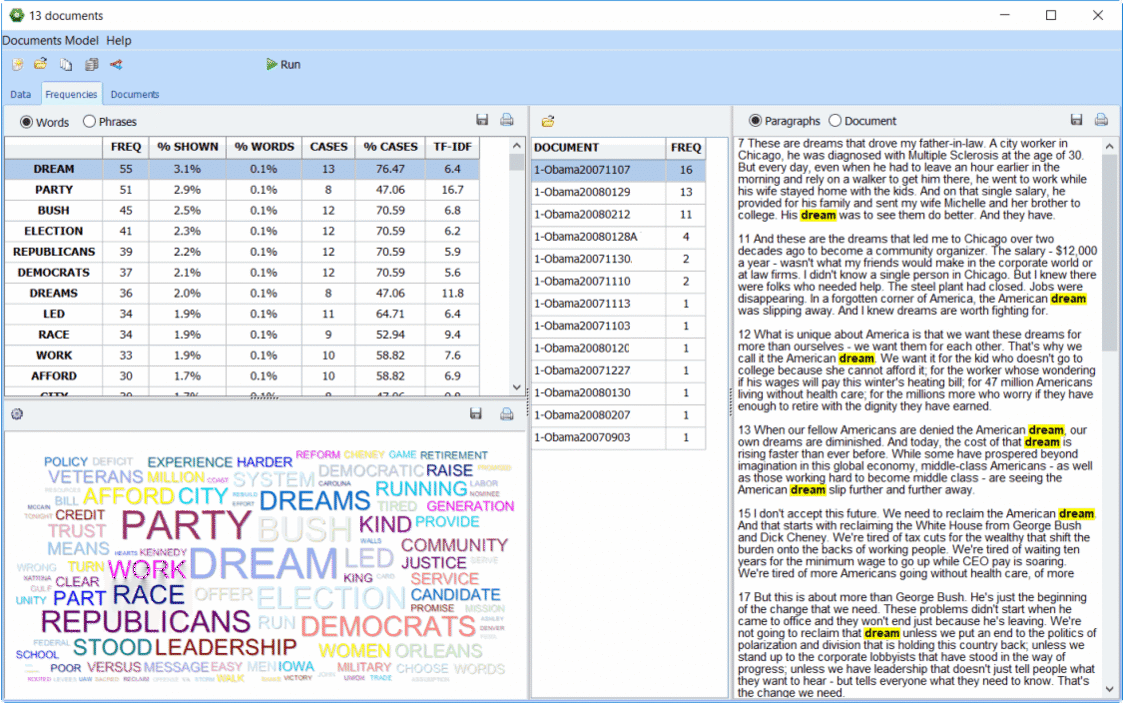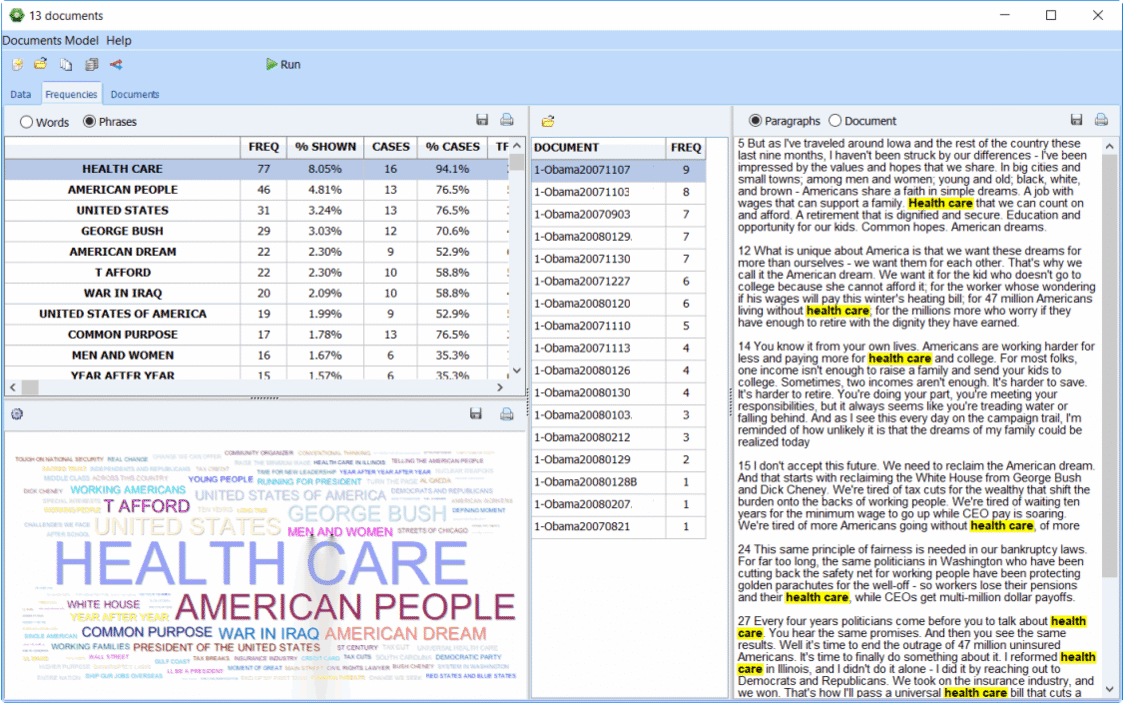
IMPORT FROM MANY SOURCES
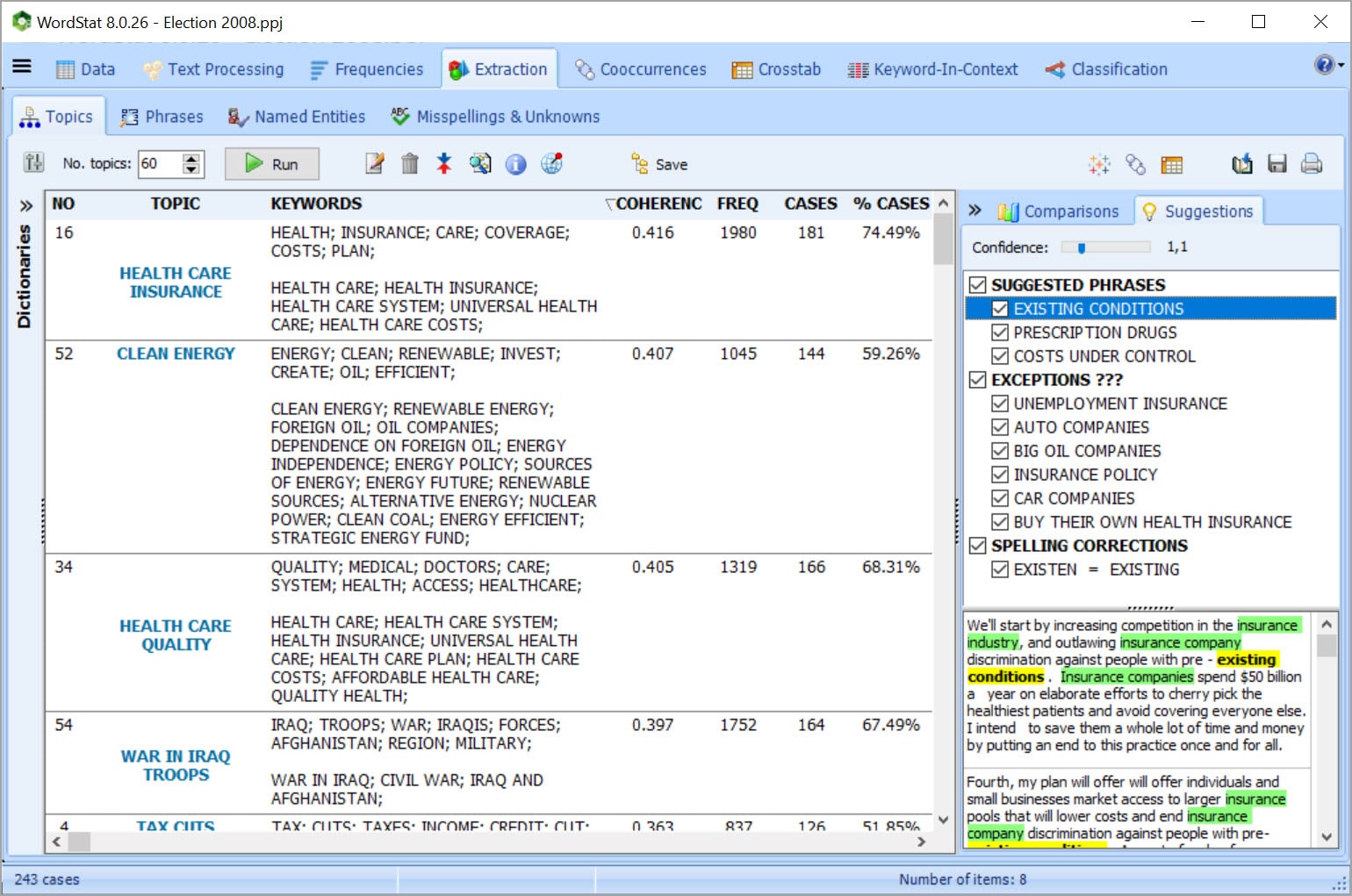
EXTRACT THE MOST SALIENT TOPICS USING TOPIC MODELING
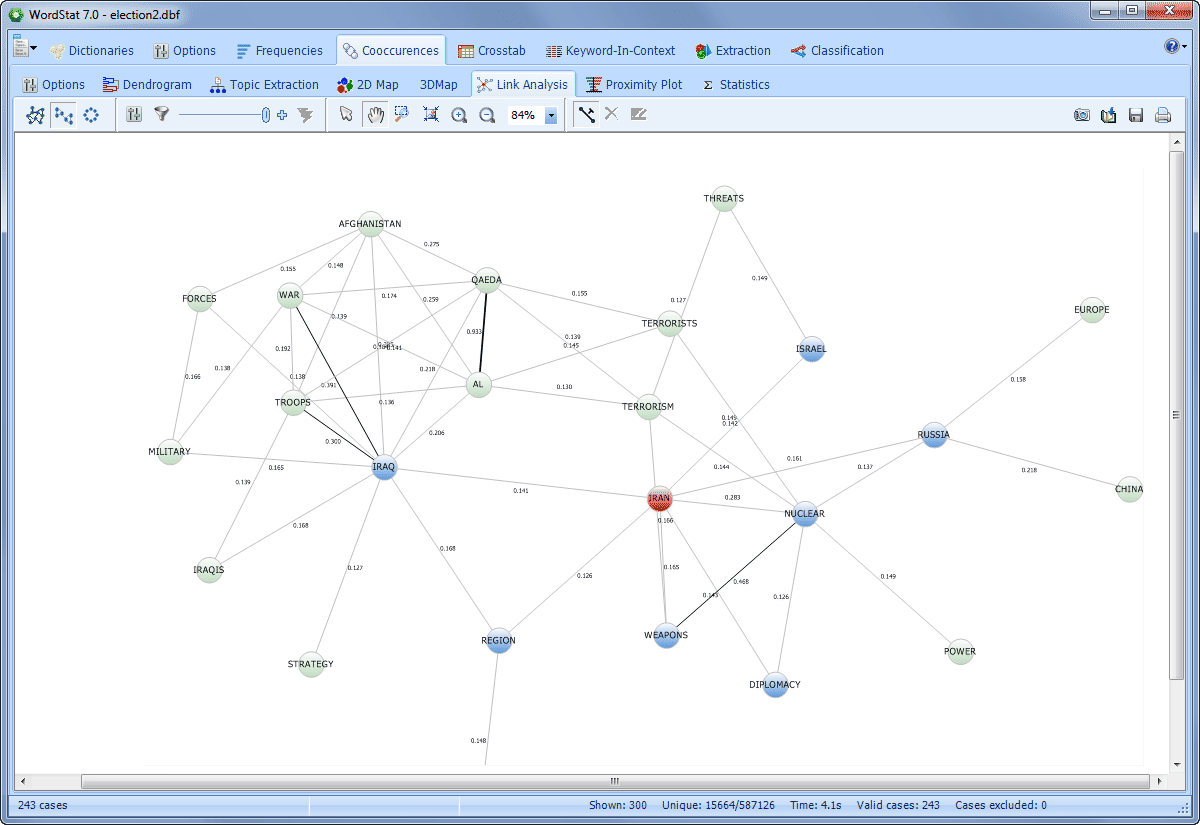
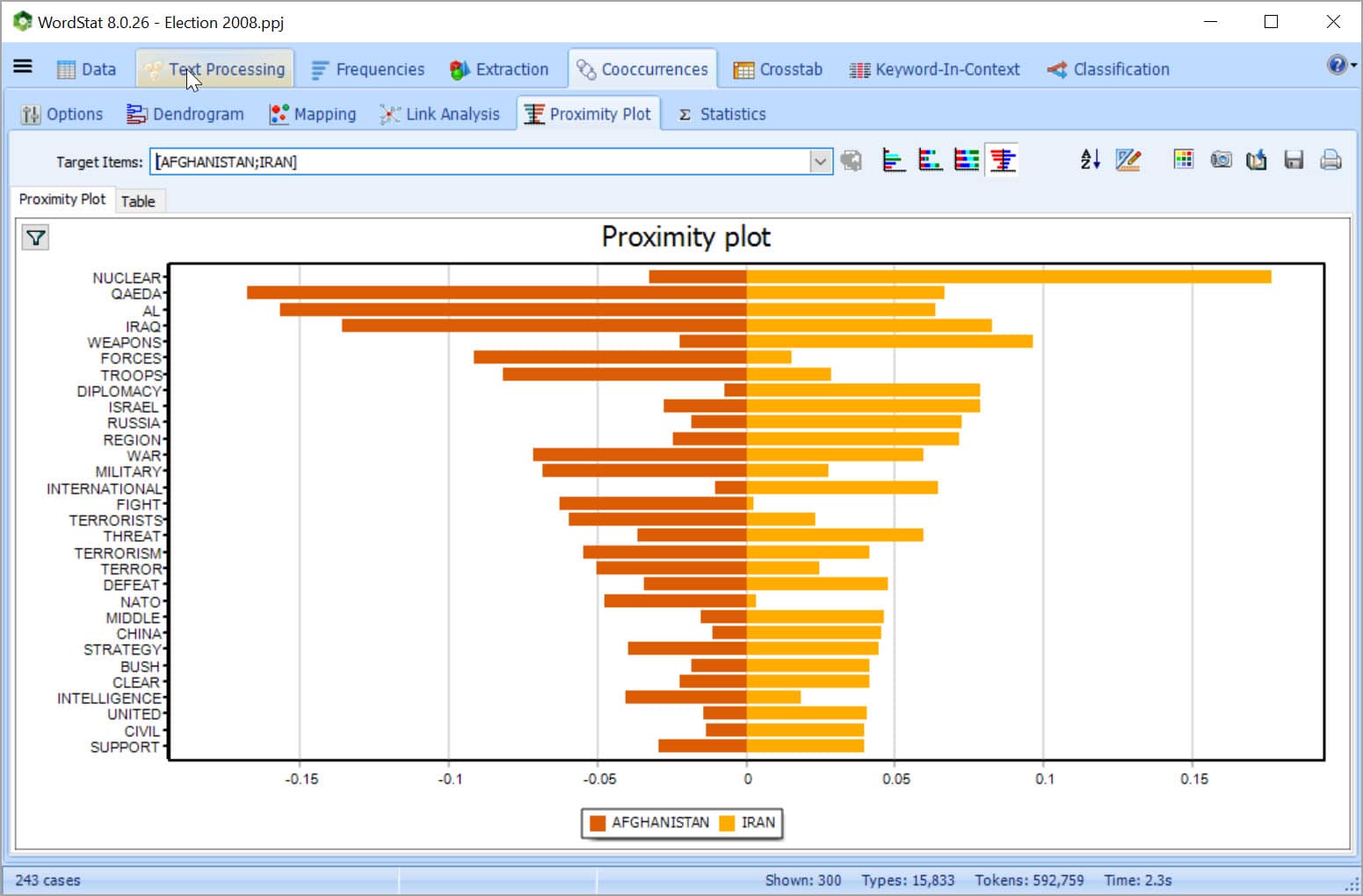
EXPLORE CONNECTIONS
RELATE TEXT WITH STRUCTURED DATA
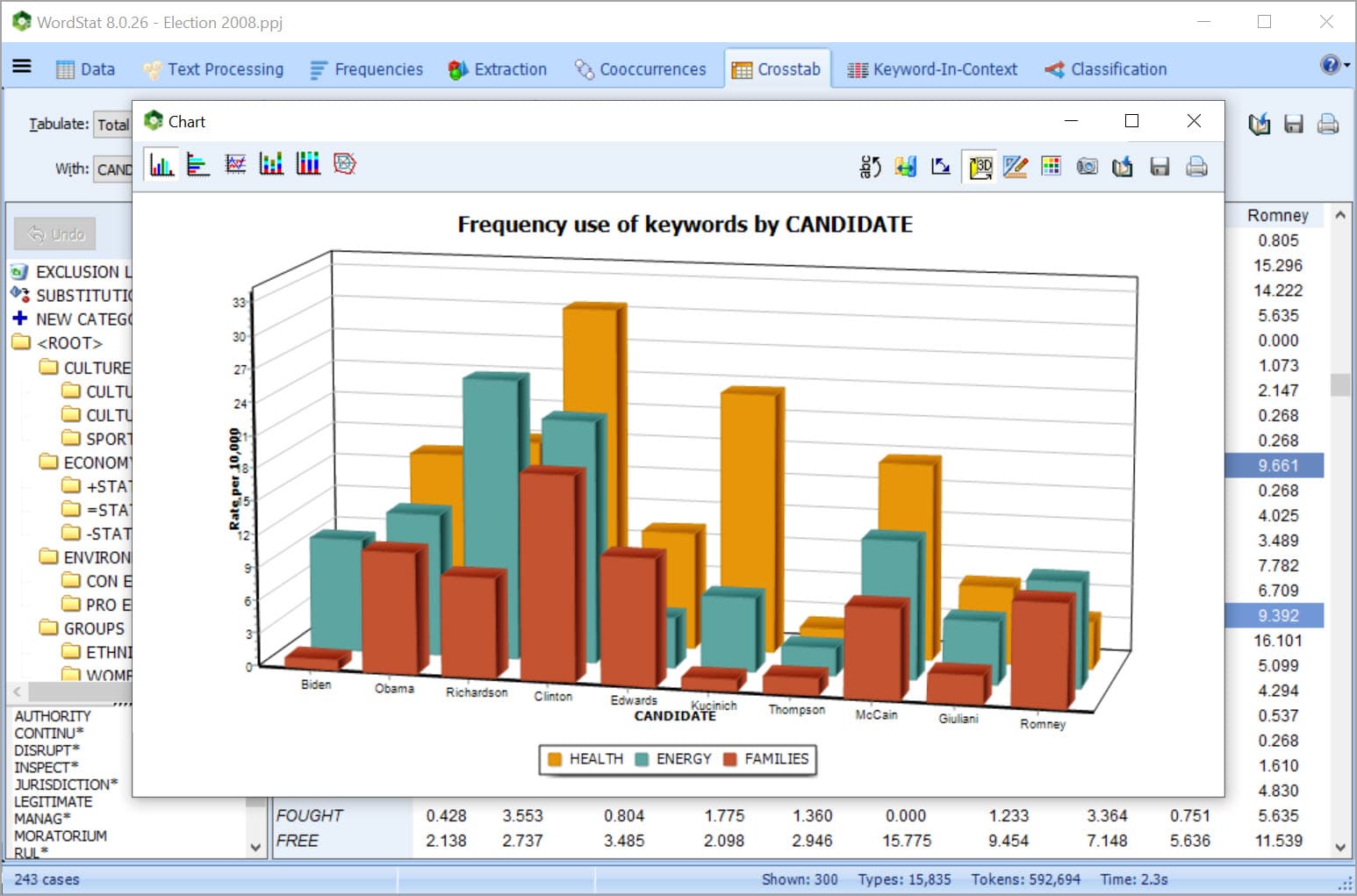
CATEGORIZE YOUR TEXT DATA USING DICTIONARIES
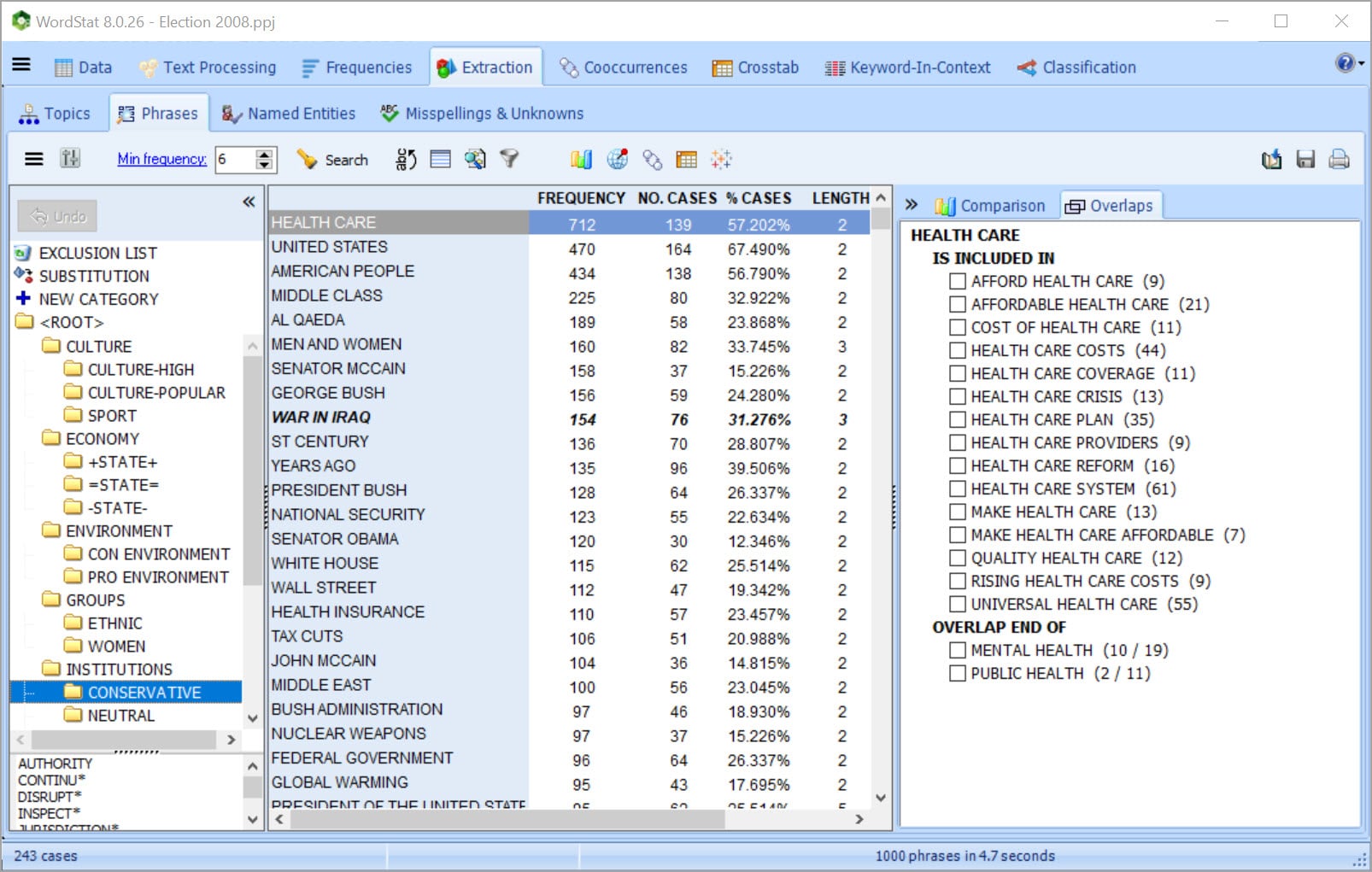
GET UNIQUE ASSISTANCE FOR DICTIONARY BUILDING
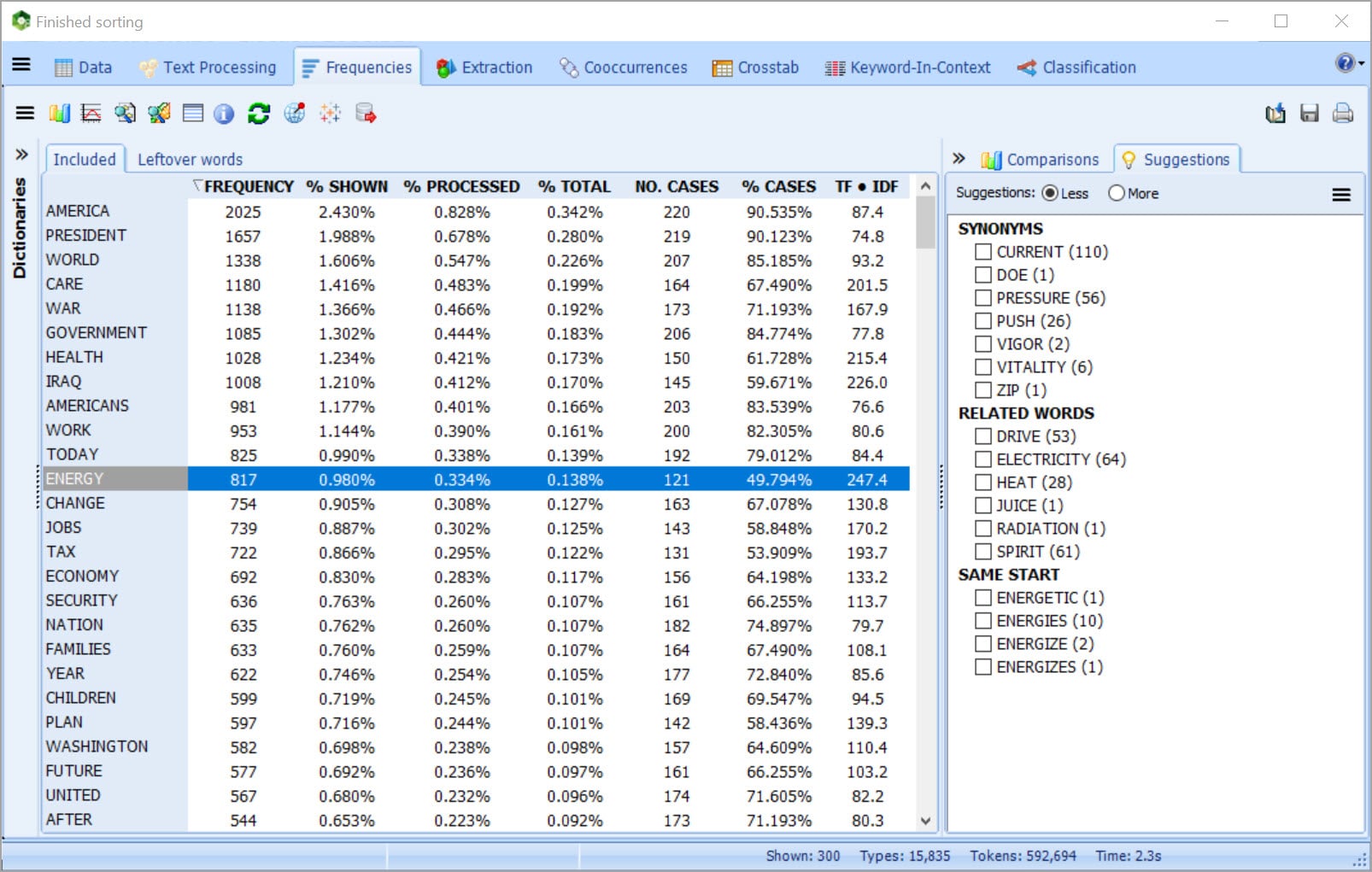
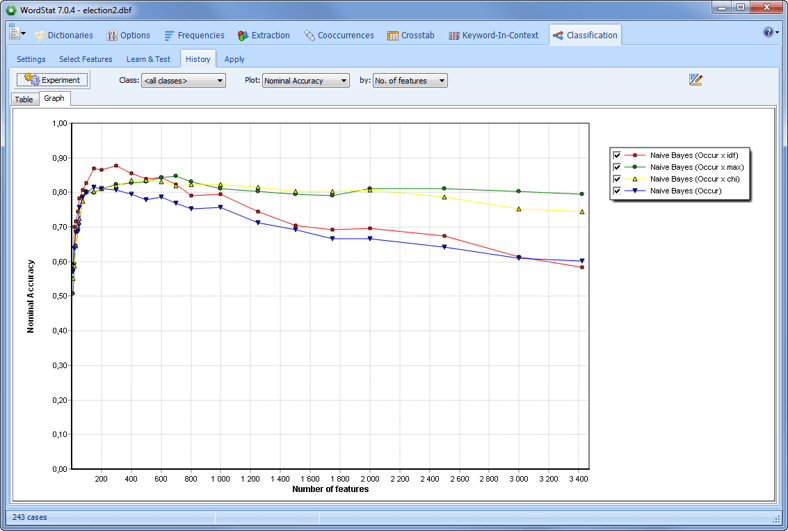
CATEGORIZE YOUR TEXT DATA USING MACHINE LEARNING
RETURN TO SOURCE DOCUMENT IN ONE CLICK
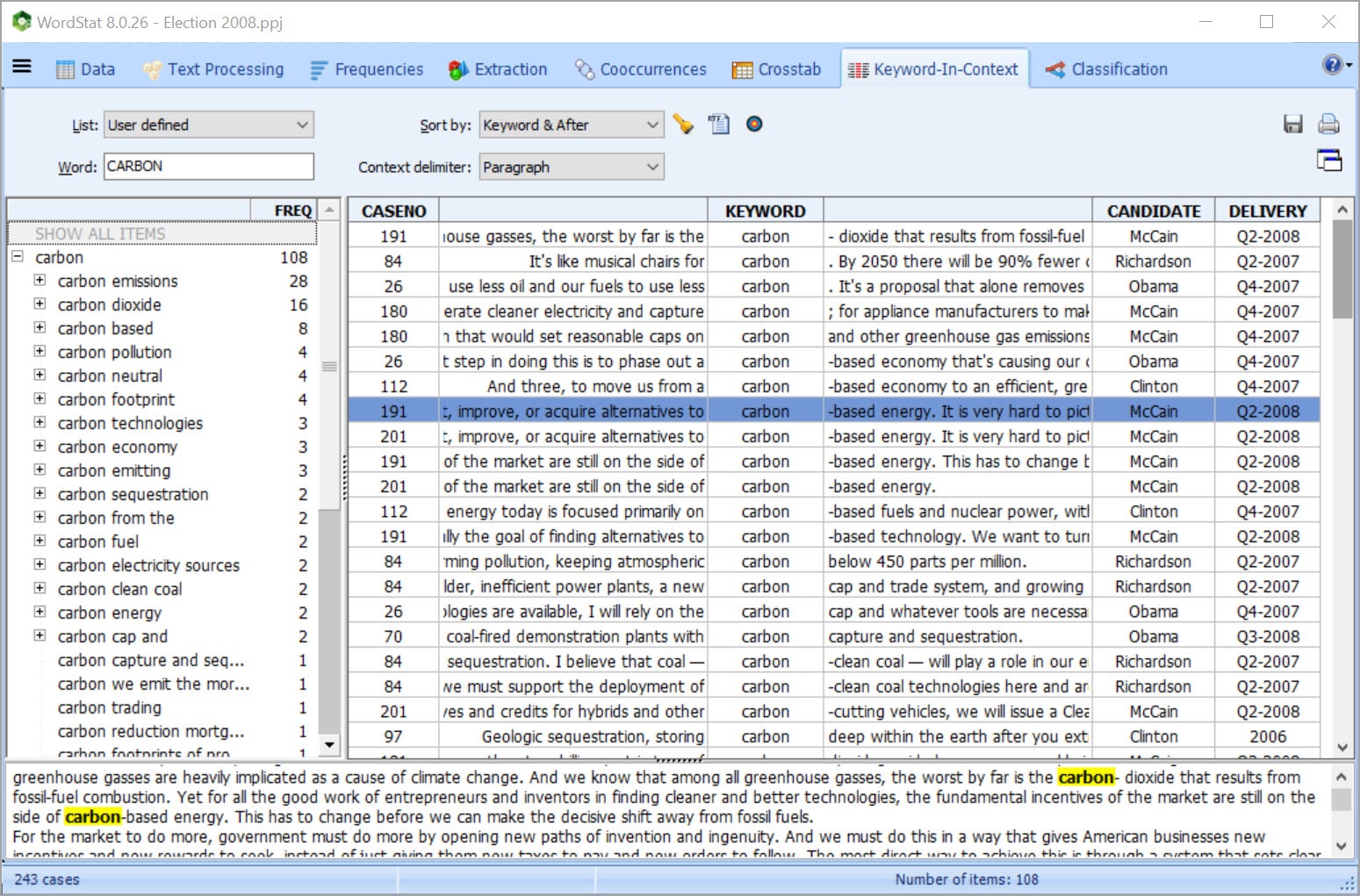
PERFORM QUALITATIVE CODING
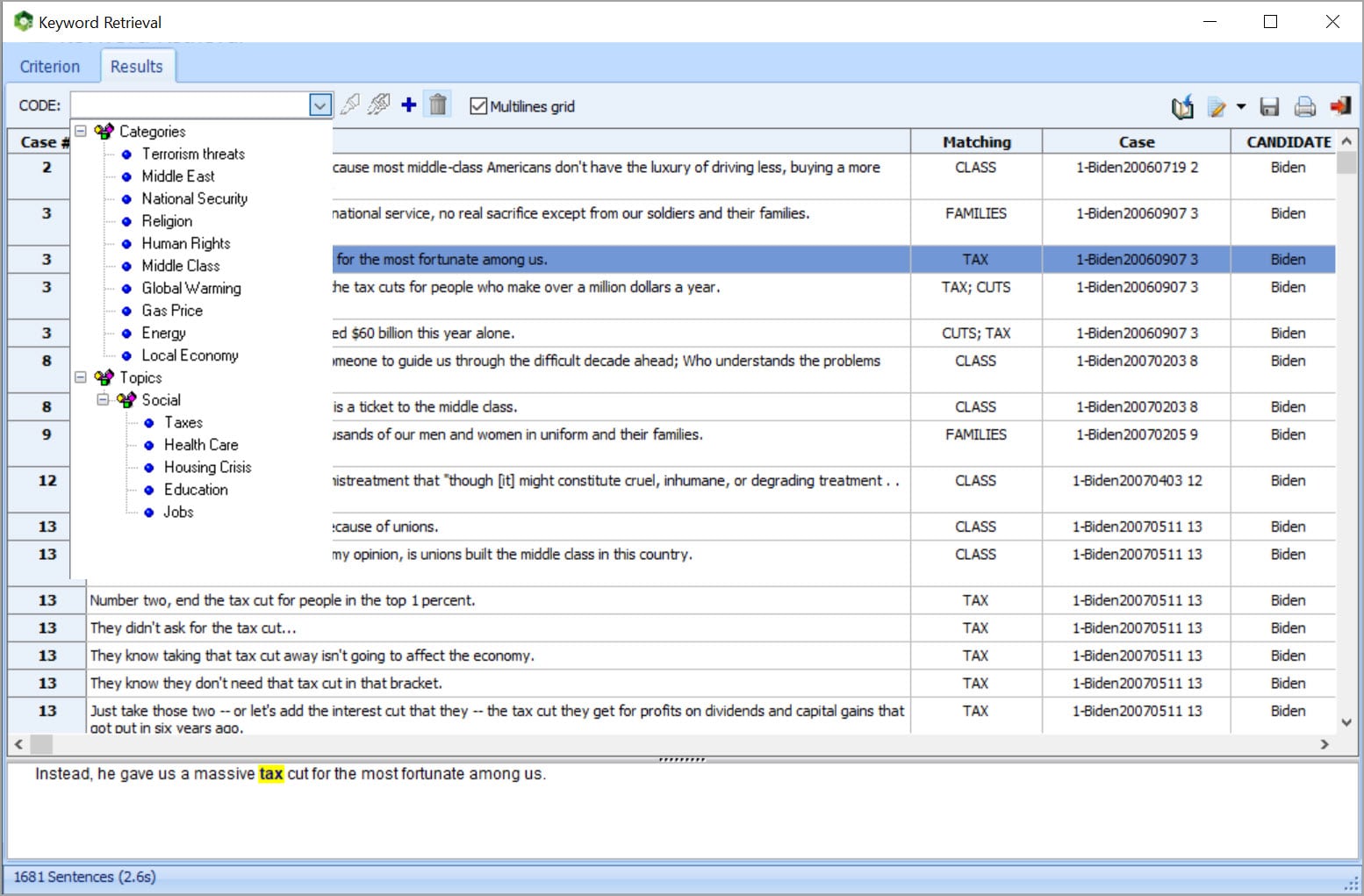
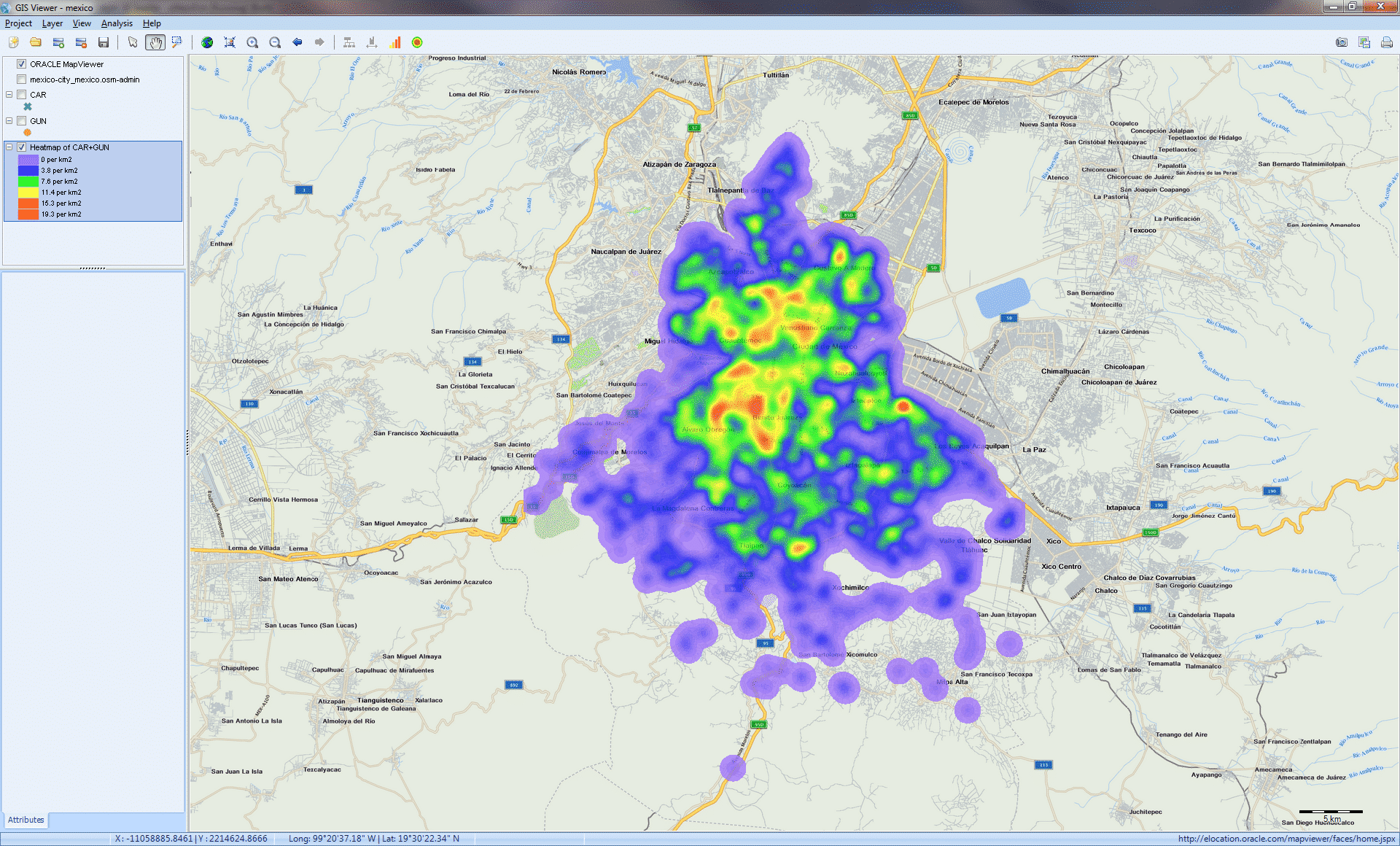
TRANSFORM UNSTRUCTURED TEXT INTO INTERACTIVE MAPS (GIS MAPPING)
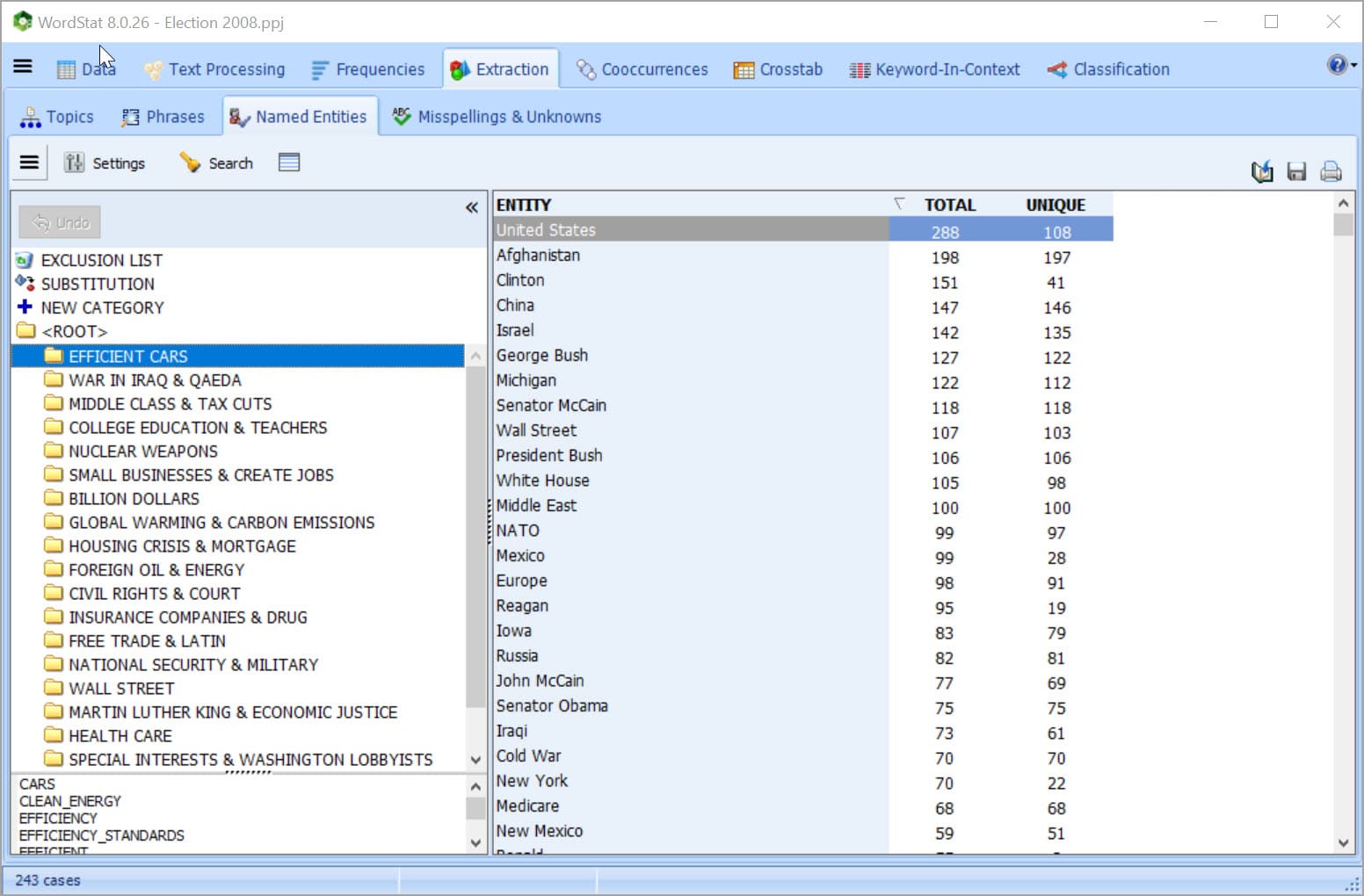
AUTOMATICALLY EXTRACT NAMED ENTITIES
EXPORT RESULTS
TRANSFORM TEXT USING PYTHON SCRIPTS

We have found WordStat to be the most powerful text analytics tool available for business applications.
Dr. John M. Aaron
Professor-Elmhurst College-Master’s Degree Program in Data Science
WordStat can easily do a wide range of text analysis. It has a lot of convenient capabilities that make it much easier to use than other products.
Dr. Grant Blank
Survey Research Fellow, University of Oxford