How to Install and Run WordStat for Stata April 26, 2018 - Blogs on Text Analytics
WordStat for Stata gives you the capability to analyze any string variables/text data contained in numerical and categorical files that you are analyzing in Stata. WordStat combines natural language processing, content analysis, and statistical techniques to quickly extract topics, patterns, and relationships in large amounts of text. It can process millions of words in seconds and compare extracted themes across any other numerical, categorical or date variables in the Stata file.
WordStat for Stata is the same software, with the same capabilities, as the version that runs with QDA Miner or SimStat. The only difference is that when you install WordStat for Stata it installs an extension to Stata that permits you to run WordStat as a content analysis module and import files with the Document Conversion Wizard. Therefore, you must always install Stata before installing WordStat for Stata.
Once you have installed Stata and WordStat for Stata, open Stata. Open the file you wish to analyze. Go to the Users button in the toolbar. Click on WordStat in the drop-down menu and Content analysis.
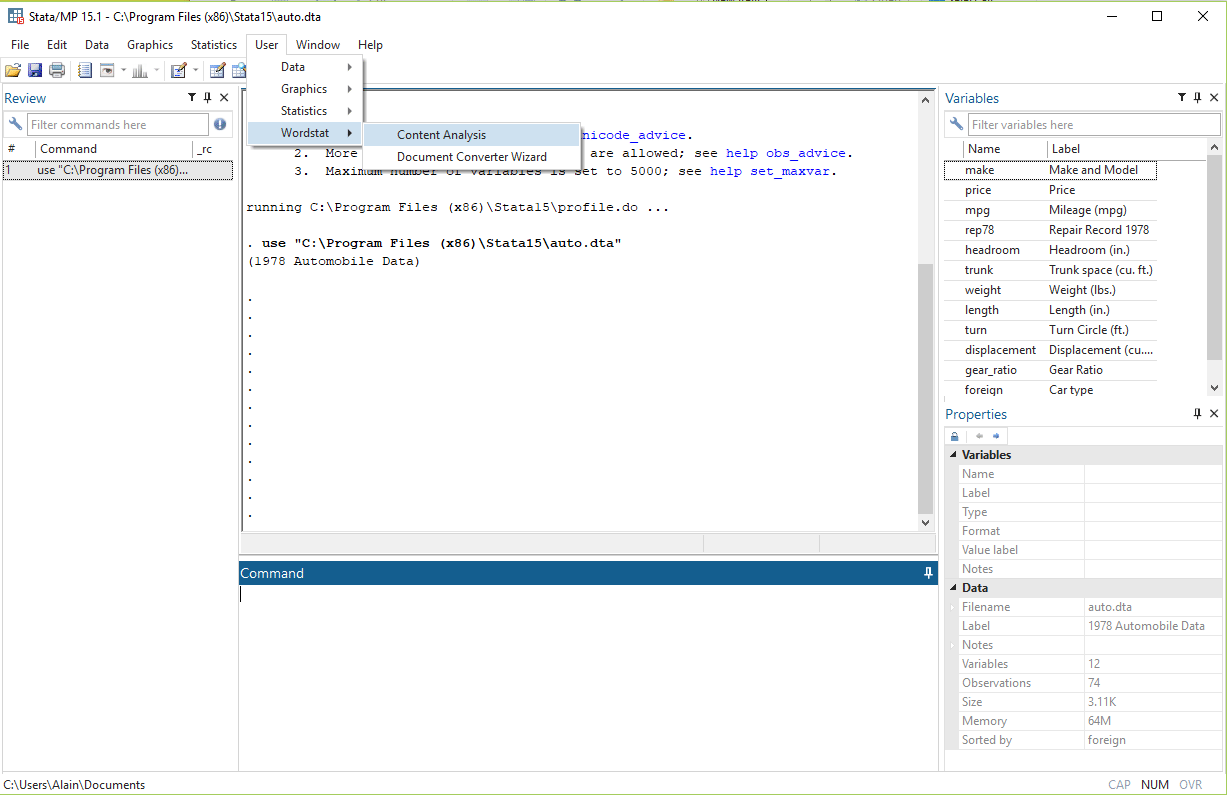
Once you click on Content analysis the screen below will appear prompting you to choose the String variable you wish to analyze.
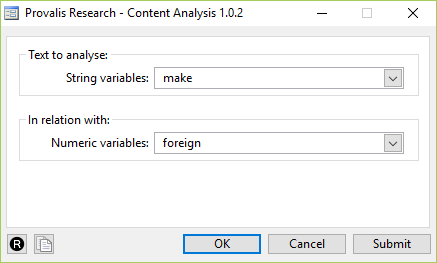
Click on OK and you are ready to use the various features of WordStat for your content analysis. You can see all the features of WordStat by going to our website or by viewing our tutorial videos. In this Blog we show you how to run WordStat for Stata to analyze files that have been imported into Stata. If you want to analyze files and directly import them into WordStat for Stata you can do this by using the Document Conversion Wizard feature. This video shows you how that works Document Conversion Wizard Tutorial Video.
If you have additional questions you can email us at