

Powered by AI since 2007 — now with offline transcription & GenAI document analysis
Qualitative and mixed methods software with unparalleled computer-assisted coding and analysis
FEATURES
QDA Miner is an easy to use qualitative analysis software for organizing, coding, annotating, retrieving, and analyzing collections of documents and images. QDA Miner offers more computer assistance for coding than any other qualitative research software on the market, allowing you to code documents more quickly but also more reliably. The qualitative data analysis software integrates advanced statistical and visualization tools to quickly identify patterns and trends, explore patterns in your coding, as well as describe, compare and test hypotheses. This is one of the reasons why QDA Miner is considered by many to be the first and still only true, mixed methods qualitative software on the market today.
Import from many sources
QDA Miner allows you to directly import content in multi-languages from many sources:
- Import documents: Word, PDF, HTML, PowerPoint, RTF, TXT, XPS, ePUB, ODT, WordPerfect.
- Import data files: Excel, CSV, TSV, Access
- Import from statistical software: Stata, SPSS
- Import from emails: Outlook, Gmail, MBox
- Import from web surveys: Qualtrics, SurveyMonkey, SurveyGizmo, QuestionPro, Voxco, triple-s
- Import from reference management tools: Endnote, Mendeley, Zotero, RIS
- Import news transcripts from the Nexis UNI and Factiva output files as well as RSS feeds
- Import graphics: BMP, WMF, JPG, GIF, PNG. Automatically extract any information associated with those images such as geographic location, title, description, authors, comments, etc. and transform those into variables
- Import from XML databases
- ODBC database connection is available.
- Import projects from qualitative software: NVivo, Atlas.ti, QDPX files
- Import 10-K and 10-Q financial filing files.
- Import and analyze multi-language documents including right-to-left languages
- Monitor a specific folder, and automatically import any documents and images stored in this folder or monitor changes to the original source file or online services.

Organize your data
Several features allow you to easily organize your data in ways that make your coding and analysis process straightforward:
- Quickly group, label, sort, add, delete documents or find duplicates.
- Assign variables to your documents manually or automatically using the Document Conversion Wizard, ie: date, author, or demographic data such as age, gender, or location.
- Easily reorder, add, delete, edit, and, recode variables.
- Filter cases based on variable values or whether a document contains codes or not.
- Transform coded text into variables.
- This is very useful to extract relevant metadata from unstructured documents or transform an unstructured project into a structured one.

Manage your codebook
Creating a codebook is an important step in a qualitative data analysis project. QDA Miner provides dedicated tools that help you create and manage your codebook in a creative way:
- Easily create and edit a codebook.
- Assign a color and a memo to a code.
- Associate a list of keywords to code to easily retrieve text segments that contain those keywords.
- Dictionaries created using WordStat may be imported into QDA Miner and transformed into codes and categories.
- Save your codebook on disk in a separate file so it can be imported and used for another project.
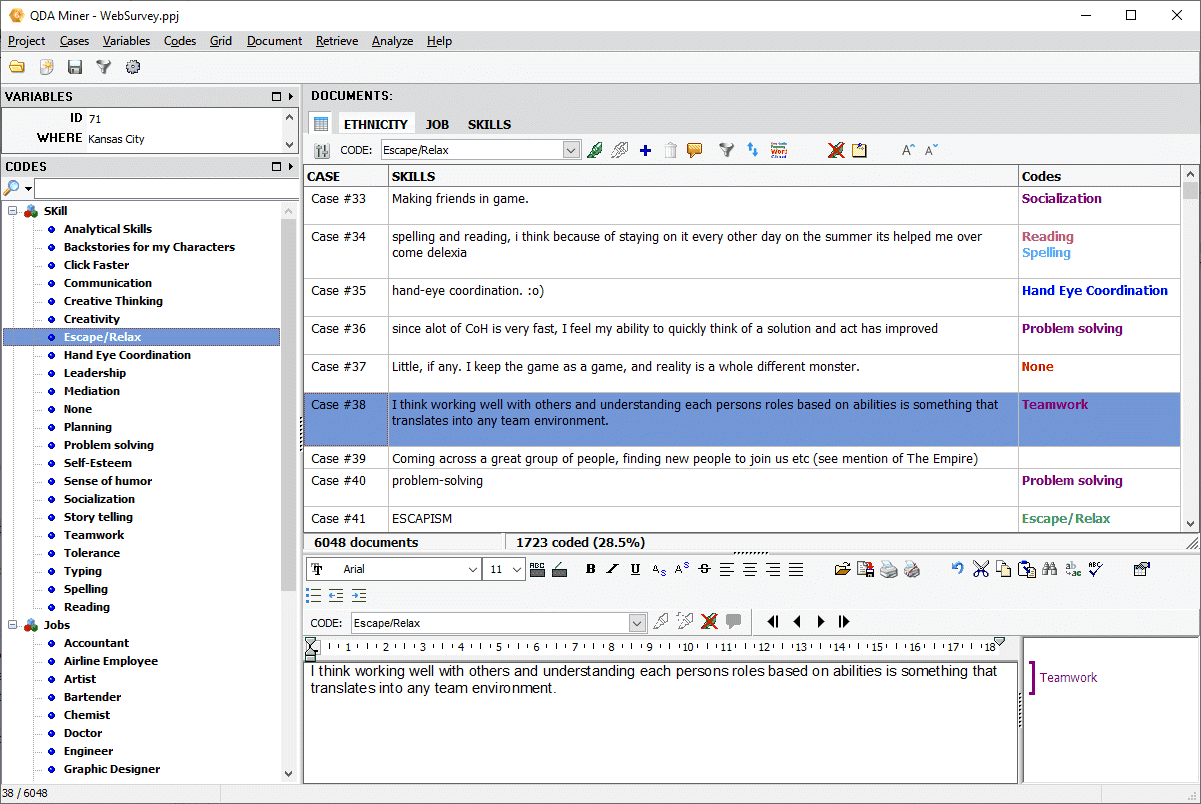
Perform on-screen coding
Code text segments and images with an intuitive qualitative tagging process:
- Use on-screen coding and annotation of texts and images with easy drag and drop assignment of codes to text segments and images.
- Use the grid view mode that provides a convenient and very efficient way to code open-ended questions or short comments.
- Several features offer greater flexibility and ease-of-use, such as code splitting, merging, easy resizing of coded segments, interactive code searching and replacement, or virtual grouping.
- Add hyperlinks to text selection or coded segments so you can move to a web page, file, another case in your project, or other coded or uncoded text segments.
- Display a graphical overview of the coding of your current document to get a quick glimpse of the spatial distribution of the coding.



Speed up your coding
Code your documents more quickly and more reliably with seven text search and retrieval tools:
- The Keyword Retrieval tool can search for hundreds of keywords and key phrases related to the same idea or concept, allowing you to locate all references to a single topic.
- The Section Retrieval tool is ideal to automatically retrieve and code sections in structured documents.
- The Query by Example tool can be trained to retrieve text segments having similar meanings to the examples you feed in.
- The Speaker Segments retrieval tool to automatically identify and code speech turns in interview, focus group or debate transcripts.
- The AI Retrieval tool use natural language queries to search and retrieve text without the need to guess all relevant keywords or key phrases.
- The Cluster Extraction tool will group similar sentences or paragraphs into clusters and allows you to code these using a flexible drag-and-drop editor.
- The Code Similarity search will retrieve all text segments similar to those that have already been coded. One may even search for items similar to codes defined in previous coded projects.
- The Date and Location extraction tool is ideal to quickly locate and tag references to dates or geographic locations.


Generative AI integration
- Choice of AI Engines & Models: Select from OpenAI, Gemini, Claude, Mistral, or offline Ollama
- Prompt Transparency & Customization: View, edit, or create your own prompts. No black box
- AI-Assisted Text Analysis: Sentiment analysis, translation, lemmatization, spelling correction, etc.
- Natural Language Retrieval: Search documents using plain-language queries
- Thematic Extraction & Summarization: Extract or summarize relevant segments by topic
- AI-Based Table Filtering: Refine search results with natural language filters
- Follow-Up Queries: Ask custom AI questions on retrieved text segments
- Real-Time Token & Cost Monitoring: Estimate and track processing costs by model and project
- No costly annual subscriptions: Bring your own GenAI engine and pay only for what you use
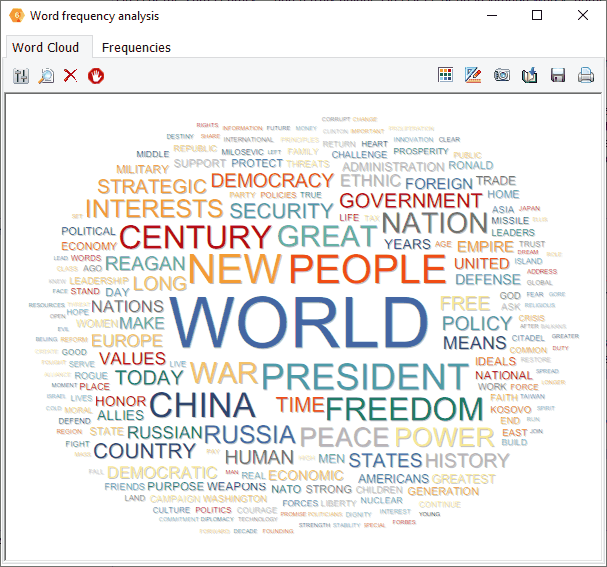
Analyze, visualize, explore
- Use an interactive word or phrase clouds and word or phrase frequency tables to obtain words frequency on any document variable or on results of retrieval operations (text, coding, section or keyword retrieval) as well as for a single document or for text displayed in the grid view.
- Analyze codes frequency, explore connections between codes using Cluster Analysis, Link Analysis, Sequence Analysis or Multidimensional Scaling,
- See the relationship between variable values and codes using Crosstabs, Correspondence Analysis, or Heatmaps.
- Compute statistical tests such as Chi-Square, Pearson Correlation, and so on, to help you identify the strongest relationships. No need to purchase a separate statistical software.
- Create a grid containing all coded text segments and/or comments and get a compact view of coded material using the Quotation Matrix.




Plot events using GIS Mapping and Time Tagging
All these innovative features make QDA Miner the most powerful geotagging qualitative tool on the market:
- Associate geographic and time coordinates to text selection or to any coded text segment or graphic area, allowing one to locate events both in space and time.
- Geographic coordinates can be imported from KML or KMZ files or cut from Google Earth and pasted into QDA Miner. One may then easily jump from a geo-link to Google Earth.
- A flexible link-retrieval tool may be used to filter and select relevant geo-linked or time-tagged events and display them either on a geographic map or a timeline.
- In QDA Miner, users can retrieve coded data, based on time and location, and plot events on timelines and maps.

Use the integrated geocoding service

Get unparalleled teamwork support
QDA Miner supports teamwork in highly effective ways. Dedicated functions make collaboration an easy task:
- Enhanced teamwork support features like a flexible multi-users settings tool allow you to define for each team worker what they can or cannot do.
- Get assistance in duplication and distribution of projects to team members.
- A powerful merge feature bringing together, in any single project, codings, annotations, reports, and log entries of different coders working independently.
- A synchronization feature allows distribution and merging from multiple sources in a single button click.
- A unique inter-rater agreement assessment module may be used to ensure the coding reliability of multiple coders.


Track changes

Export and share results
In QDA Miner, you can easily create presentation-quality graphics such as bar charts, pie charts, bubble charts, and concept maps, and save them as an image (png, jpeg or BMP, WMF, EMF). Tables with statistics can also be easily exported to disk in different file formats including Word, Excel, CSV, HTML, XML, and delimited ASCII files, allowing the data to be further analyzed using a statistical program. QDA Miner statistical tables can export statistics directly to SPSS, Stata 8 to 15 or Tableau Software.
