
What’s New in Version 4?
The first thing you will notice when running version 4 for the first time will be the new look of QDA Miner. We implemented a more modern-looking interface, with more icons than ever before. If you are already familiar with the menu structure of QDA Miner, you will find that almost everything remains in its original location. But we did split the ANALYZE menu in two in order to group all text- and coding-retrieval functions under a new RETRIEVAL menu, and we kept all the remaining analysis features under the existing ANALYZE menu.,Aside from these cosmetic changes, you will find a lot of powerful and unique new features.
We really take the concept of “computer-assistance” seriously!
QDA Miner has always offered more computer assistance for coding, analysis and report writing than any other qualitative software on the market. For example, QDA Miner 3.2 has not just one, but four different text-search tools: Boolean search, query-by-example, keyword retrieval and section retrieval. The upcoming version 4.0 continues this trend by implementing two truly innovative text-search tools: the cluster extraction and coding tool and the code-similarity search tool. These two new text-search tools based on machine learning and information-retrieval techniques represent very efficient tools for faster and more consistent coding. Make sure you check out the flash demos of these new features.
The missing dimension in geotagging!
We have witnessed the implementation of geo-tagging in other QDA software. We were not totally convinced of the value of such features until we realized that there was one crucial dimension missing: time. Many researchers need to locate events not only in space but also in time. They also need to examine the distribution of events on those two dimensions. QDA Miner 4.0 allows one to attach geographic coordinates and time tags to any coded segment or to an uncoded text segment, and to produce static and dynamic maps in Google Earth, ArcView or similar programs, as well as interactive timelines. We also added two related search tools. One of them, still under development, will allow one to extract sentences and paragraphs with time or space information and to perform autocoding and auto-tagging. We also implemented a link retrieval tool that allows one to extract coded segments specific to a time period or within a specified distance from a geographic location. All these, in addition to the ability to attach custom placemarks, import locations from ESRI shapefiles and perform location searches, make of QDA Miner, one, if not the most powerful geotagging qualitative tools on the market.
Improved visualization, more flexibility, and much more!
We made numerous improvements to existing tools, such as the memo-ing system, the dendrograms, the multidimensional scaling plots and the proximity plots. We also added tag clouds. The importation of PDF files has been greatly improved. Numerous new useful features have been implemented and will be greatly appreciated by current and new users. We even added an automatic backup feature. No matter how often we stress to our users the importance of keeping backup copies of their project and how easy backups can be performed in QDA Miner, many people still fail to back up critical data. So we implemented an automatic backup function that will be set by default to be triggered every month (one can disable this feature or customize it to be performed at shorter or longer intervals). Those are just a few examples of some of the new features of QDA Miner 4.
You will find below more details of the most important changes in QDA Miner 4.0 and 4.1.
CHANGES IN VERSION 4.1
1. PROJECTS ARE NOW STORED IN A SINGLE FILE
QDA Miner project files are now stored in a single file (with a .ppj file extension), providing an easier way to manage projects (delete, rename, move, etc.) and reducing file clutter. It also allows projects to be stored on folders synchronized through a network or in shared online storage such as Dropbox, SkyDrive, or Google Drive. Changes are no longer saved automatically on disk, but now requires the use of new, yet familiar SAVE and SAVE AS commands. QDA Miner 4.1 is backward compatible; older project files (QDA Miner 1.0 to 4.0) will automatically convert to the new single file format, however, users can still export a project into the prior format without any information loss
2. IMPROVED EXPORTATION OF CODE STATISTICS
The EXPORT | CODE STATISTICS dialog box now offers a new export format where code occurrences and frequencies are saved as a single list of code labels, stored in descending order of frequency or in their original codebook order. The dialog box also showcases a new optional panel to preview how data will be exported.
3. IMPROVED IMPORTATION OF DOCUMENTS
Users can now quickly import all documents with specific file extensions located in a folder and its subfolders. Users are also presented with the new option of storing the relative file location in a nominal variable, enabling users to classify documents in folders and generate a variable corresponding to the classification.
4. IMPORTATION OF DATA FROM XML DATABASES
A new importation dialog box has been created to import data stored in XML databases.
5. EXTRACTION OF DOCUMENTS FROM FILE NAMES
The new variable transformation feature allows users to extract file names stored in a string variable and import the associated documents into a separate variable.
6. IMPROVED SECTION RETRIEVAL
The SECTION RETRIEVAL feature now supports retrieval of segments delineated by the beginning or the end of the document. This allows users to automatically tag sections appearing at the top of documents with no starting delimiter, or sections appearing at the bottom of a document without an end delimiter.
7. SEARCH IN TABLES
Many of our results tables now provide a toolbar to search for and highlight a text search term or expression, allowing users to easily locate specific rows in larger output tables.
8. SAVING OF CODEBOOKS TO DISK
Codebooks can now be saved on disk in separate files, allowing users to build libraries of codebooks, import codebooks into existing projects, or easily share codebooks with others.
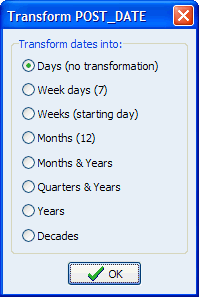
9. IMPROVED STATISTICS ON DATE VARIABLES
The VARIABLES | STATISTICS command now provides a choice of automatic date recoding to obtain statistics by days, week days, weeks, months, quarter, years or decades.
10. CREATE BAR CHART FROM 2D CORRESPONDENCE PLOTS
A new PLOT command in the 2D correspondence plot allows users to quickly obtain a bar chart to examine the distribution of a specific code across the classes of the categorical variable.
11. IMPROVED 3D BAR CHART
In the CODING BY VARIABLE and the VARIABLES | STATISTICS commands, users can now choose between two types of 3D bar charts: a 3D clustered or 3D columns bar chart.
12. IMPROVED COMBINE FEATURE
The CODES | COMBINE command now offers a search box for searching or filtering codes allowing users to easily locate specific codes in large codebooks.
13. FASTER RENDERING OF CODE MARKS
Code marks are now displayed more quickly, resulting in faster and smoother scrolling within large, densely coded documents.
14. NEW BOTTOM AXIS LABELS DISPLAY FORMATS
Labels on the bottom axis of charts may now be printed at a 45-degree angle, vertically, or horizontally, on a single line or on two lines.
15. IMPROVED IMPORTATION OF EXCEL AND ASCII FILES
Importation of data from MS Excel and text files is now up to five times faster. The compatibility with comma separated value file format and UNICODE text files has also been improved.
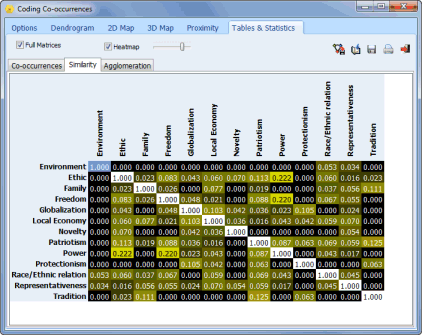
16. HEATMAPS OF CODE CO-OCCURRENCE AND CASE SIMILARITY
A new heatmap option with adjustable contrast has been added to code co-occurrence and case similarity matrices, allowing users to more easily identify cells with the highest values.
CHANGES IN VERSION 4.0
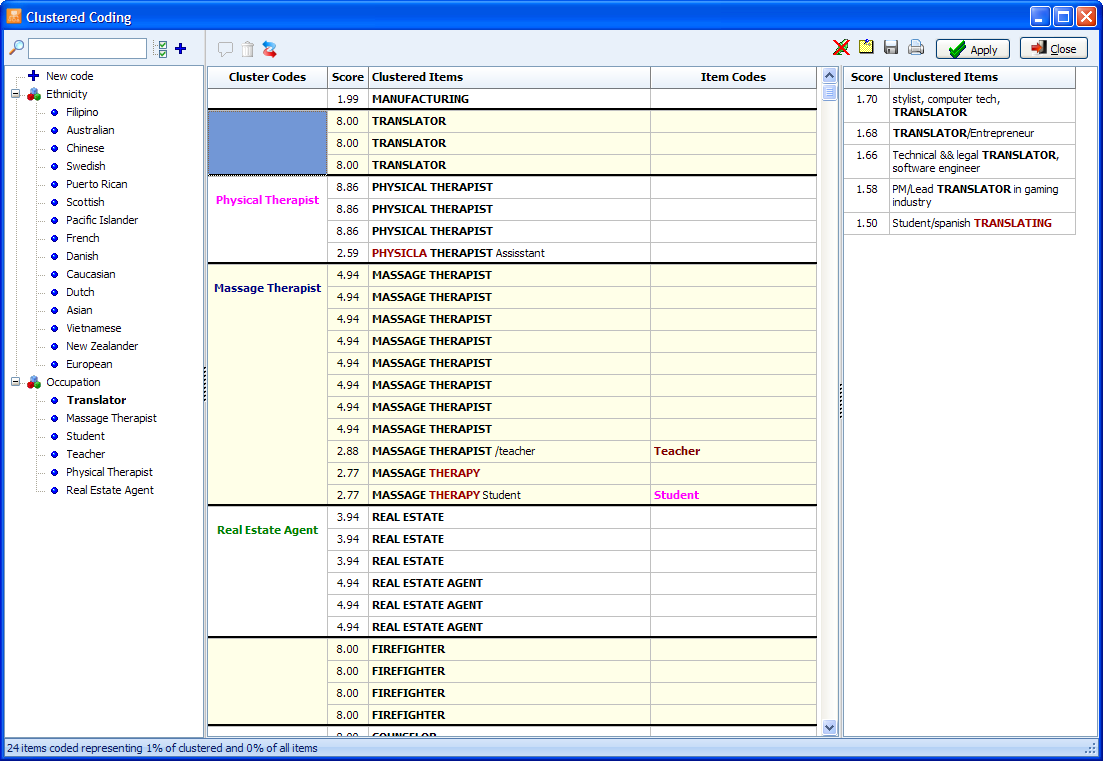
1. CLUSTER EXTRACTION AND CODING
A powerful cluster extraction and coding tool allows one to group similar sentences or paragraphs into clusters and to code those using a flexible drag-and-drop editor. This feature is very useful to quickly code large amounts of short text items such as open-ended responses, Twitter feeds and customer feedback. This feature relies on a unique patent-pending algorithm that can increase the manual coding threefold and up to more than 100 times faster than it would take one to code similar unclustered text data.
2. CODE SIMILARITY ANALYSIS
A new code-similarity retrieval tool allows one to quickly identify text segments similar to items that have been previously coded either in the current project or in another project. This feature could be used to speed up the coding of new text data or to identify items that you may have missed, increasing the reliability of your coding.
3. FLEXIBLE HYPERLINKING
Hyperlinks can now be attached to any text selection or coded segment, allowing one to move to a web page, a file, another case in your project, or other coded or uncoded text segments. One may also link a text selection or coded segment, or geographic and time coordinates (see next feature).
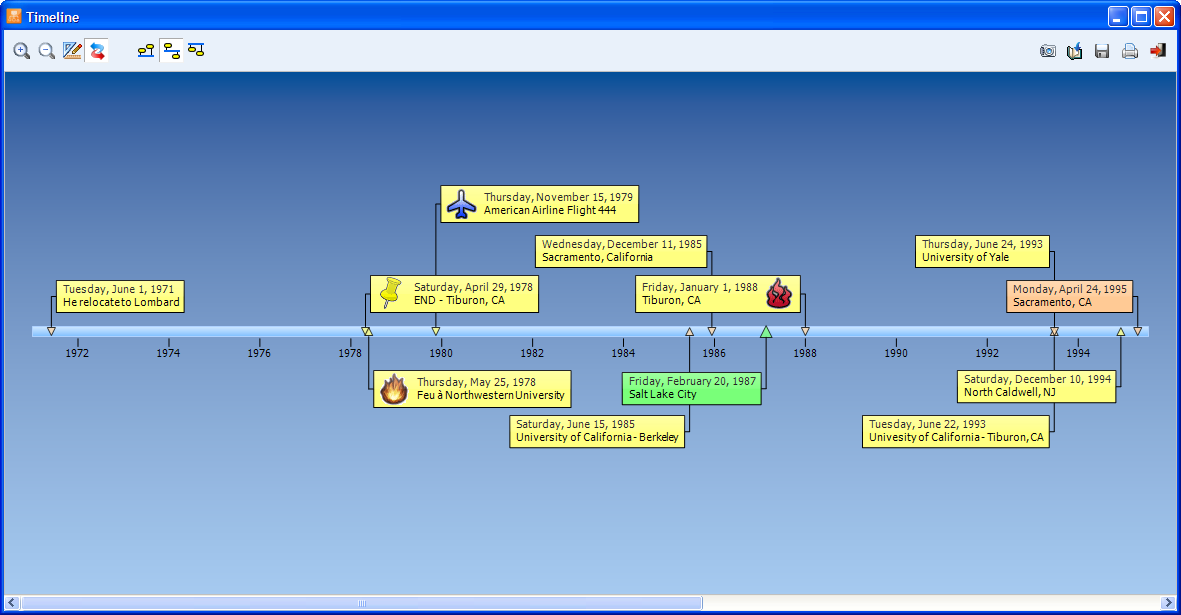
4. GEO-REFERENCING AND TIME-TAGGING TOOLS
QDA Miner now allows one to associate geographic and time coordinates to a text selection or to any coded text segment or graphic area, allowing one to locate events both in space and time. Geographic coordinates can be imported from KML or KMZ files, or cut from Google Earth and pasted into QDA Miner. One may then easily jump from a geo-link to Google Earth. A flexible link-retrieval tool may also be used to filter and select relevant geo-linked or time-tagged events and display them either on a geographic map (with an optional time slider) or a timeline.
5. DATE AND LOCATION RETRIEVAL AND CODING
A new text-search tool allows one to extract paragraphs or sentences containing references to specific dates or specific locations and to automatically attach a code to those retrieved text segments with a corresponding geo- or time-tag.
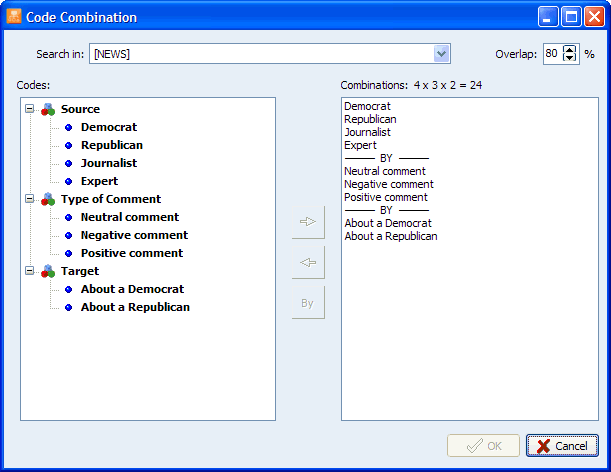
6. CODE COMBINATION FEATURES
A new CODE | COMBINE command allows one to quickly create compound codes based on the co-occurrence of existing codes. This is especially useful when text segments are codes multiple times along several dimensions (for example, speaker x tone x subject) and one needs to compute statistics or retrieve segments associated with combinations of all those dimensions.
7. GRAPHIC HIGHLIGHTING
Coded graphic segments can now be highlighted, faded or masked, allowing one to visually stress specific regions of an image, dim or hide the surrounding context, and anonymize photos. This new function can be accessed through the HIGHLIGHT command in the IMAGE menu. Several highlighting options are offered including grey-scale transformation and luminosity adjustments for either coded regions or surrounding areas.

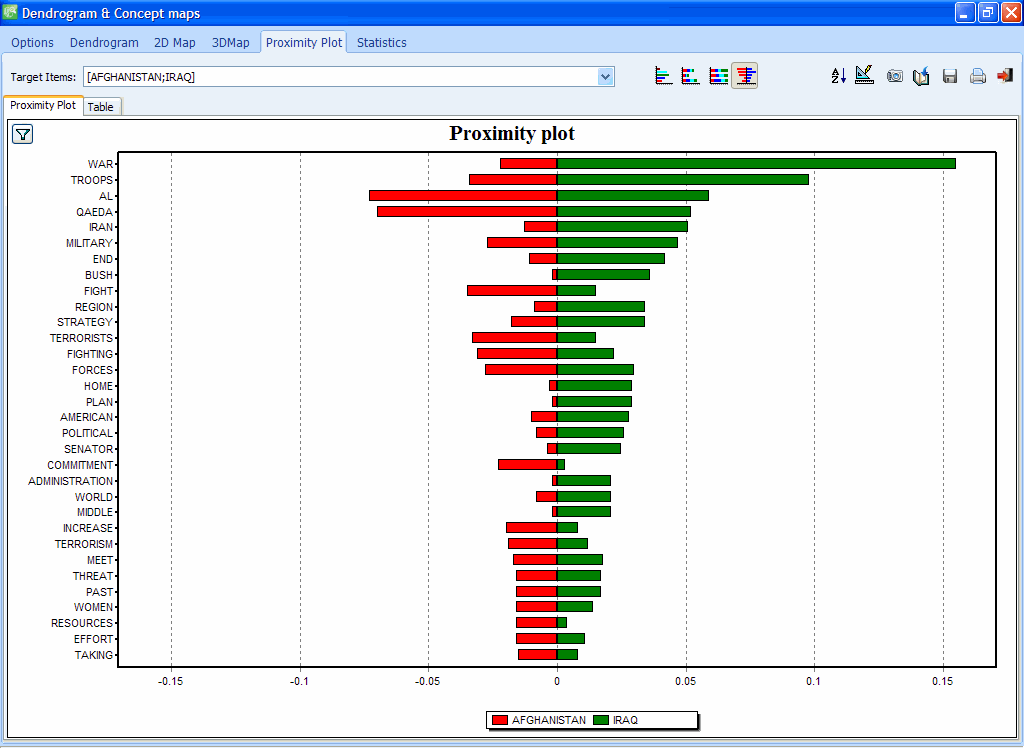
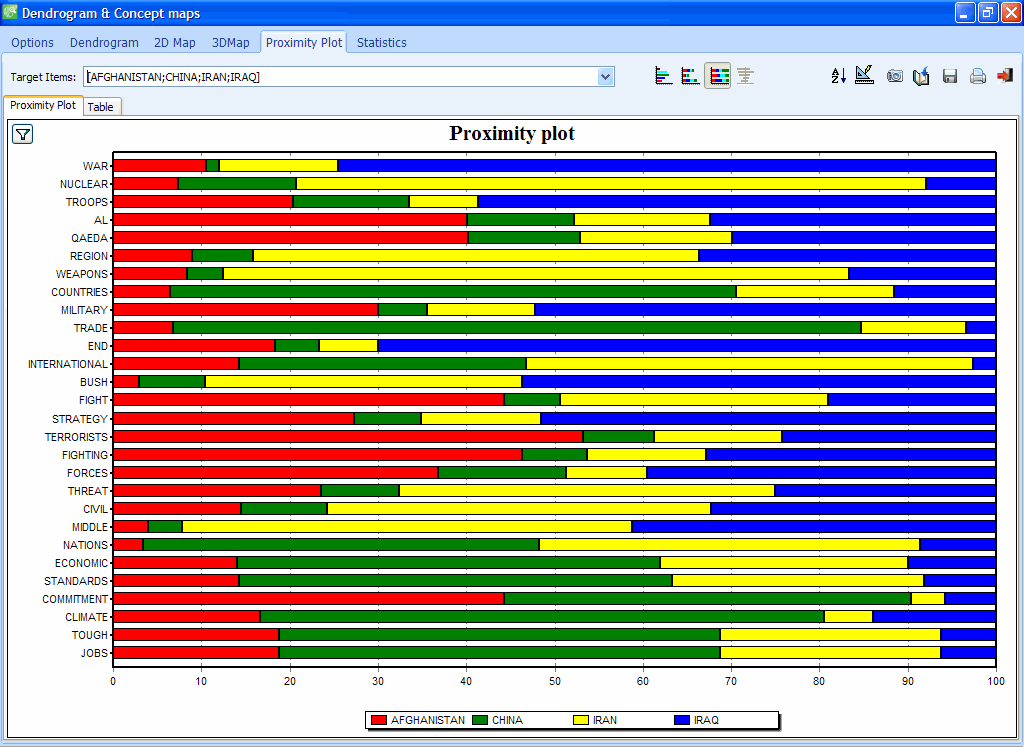
8. REDESIGNED PROXIMITY PLOT
The proximity plot feature now produces high-definition graphics and can now be used to display the proximity from more than one code using dual and stacked bar charts.
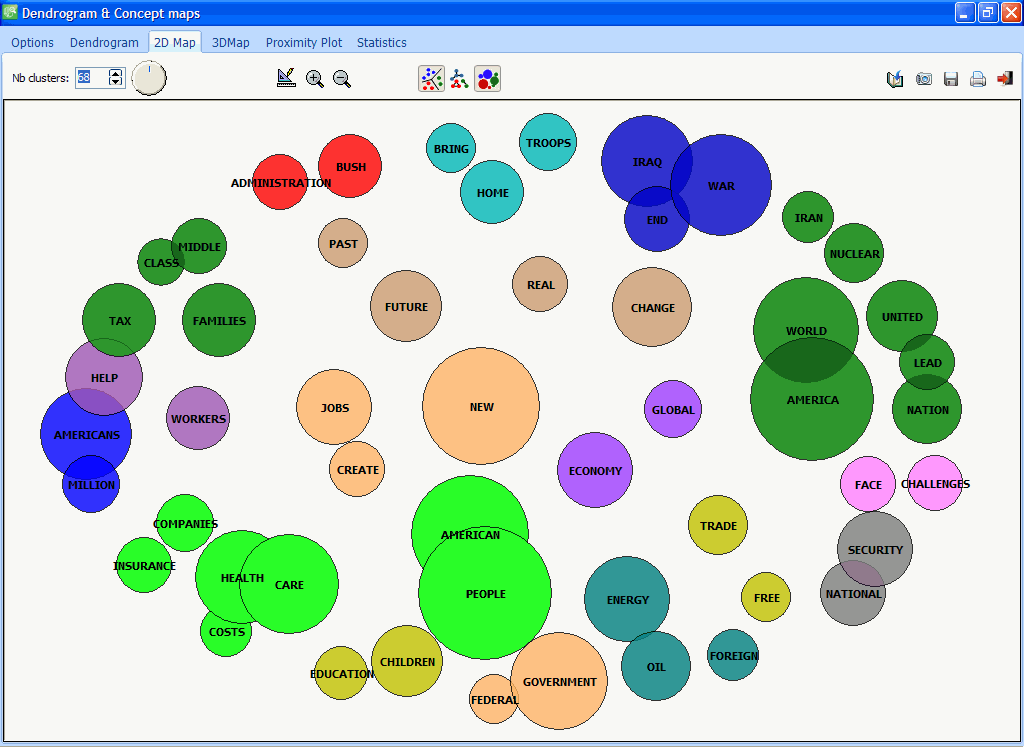
9. IMPROVED MULTIDIMENSIONAL SCALING PLOTS
One can now display the code frequency in MDS 2D and 3D plots using bubble plots.
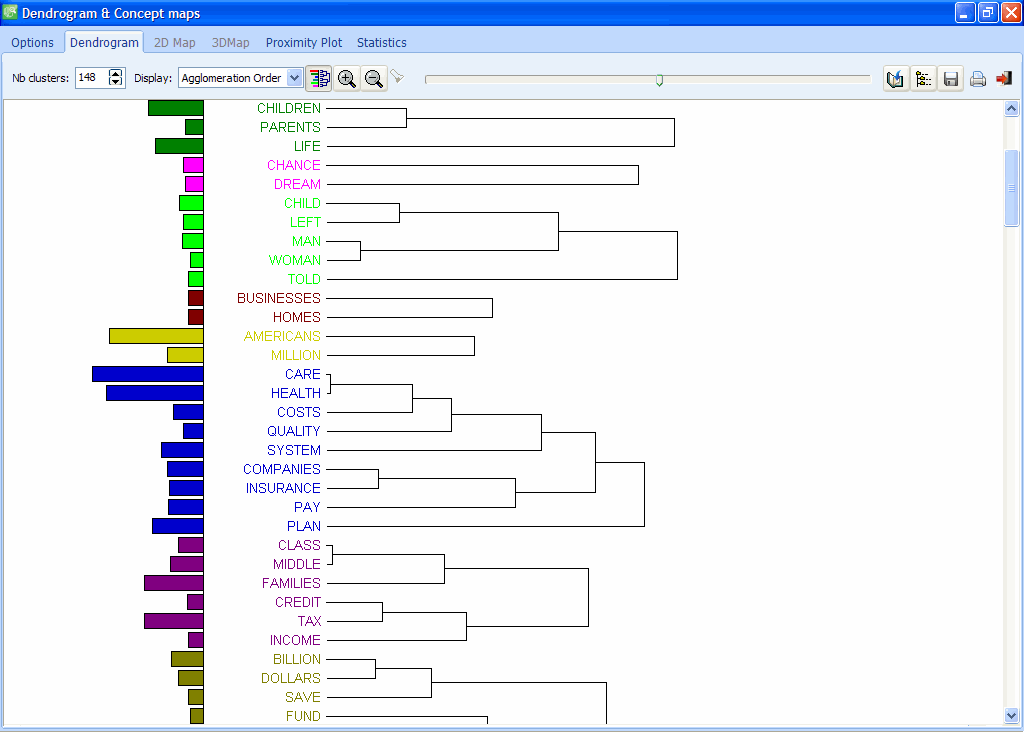
10. IMPROVED DENDROGRAMS
One can now display the coding frequencies along with dendrograms using a bar chart.
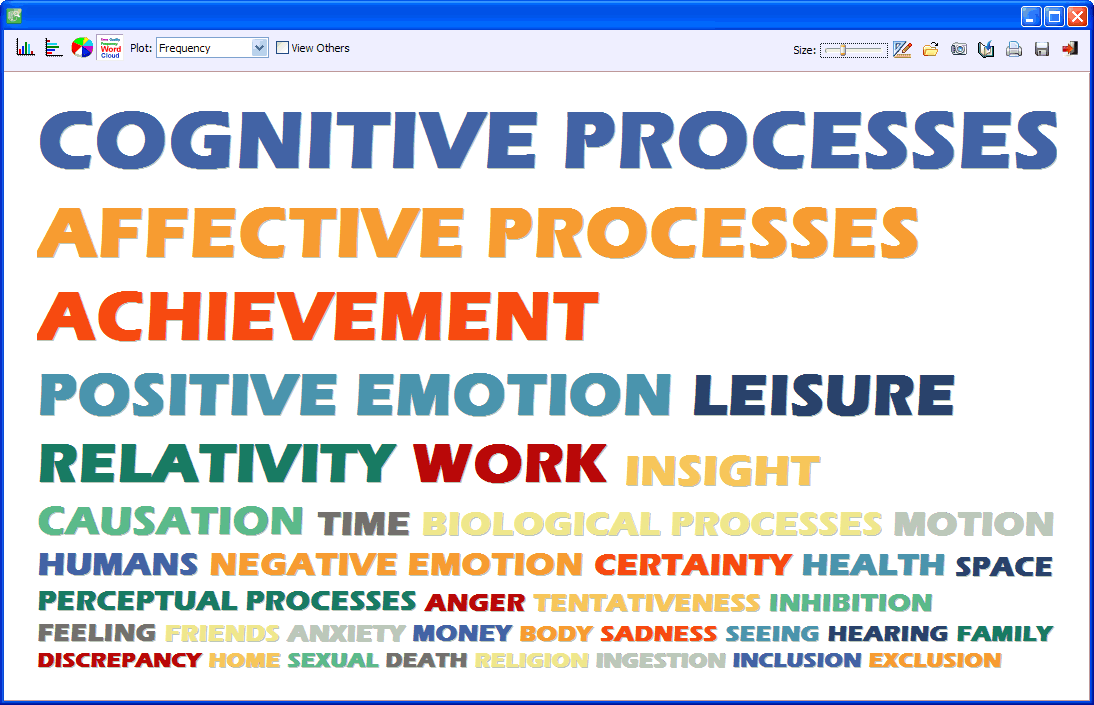
11. TAG CLOUDS
The CODING FREQUENCY command can now be used to create tag clouds.
12. IMPROVED IMPORTATION OF PDF FILES
A new PDF importation engine now allows one to keep the format of your original PDF, including tables and images (optional). It removes hyphens and line breaks to restore the original document structure (sentences and paragraphs) even for multi-column documents.
13. SPREADSHEET EDITOR
A new spreadsheet editor allows fast editing of numerical, categorical, logical and date variables in a spreadsheet editor. Clipboard operations are supported for fast assignments of values to numerous cases.
14. AUTOMATIC TRANSFORMATION OF DATE VARIABLES
When a date variable is selected in the Crosstab page, a dialog box appears, allowing one to group all dates by decades, years, months, quarters, weeks, or days of the week.
15. QUERY- BY-EXAMPLE FROM ANOTHER PROJECT
The query-by-example feature can now use as starting examples (and non-examples) text segments that have been coded in another project, allowing one to use a fully coded project as a “learning set.”
16. NEW ALGORITHM FOR FASTER CORRESPONDENCE ANALYSIS
We implemented a much faster correspondence analysis algorithm. See timing results below.
|
DIMENSION
|
COMPUTING TIME
QDA Miner 4.0 |
|
|
283 rows x 10 columns
|
1.28 seconds
|
0.00 seconds
|
|
854 rows x 10 columns
|
34.1 seconds
|
0.03 seconds
|
|
1377 rows x 10 columns
|
2 minutes,28 seconds
|
0.05 seconds
|
|
2027 rows x 10 columns
|
20 minutes, 2 seconds
|
0.06 seconds
|
|
3089 rows x 10 columns
|
1 hour, 34 minutes, 8 seconds
|
0.11 seconds
|
17. IMPROVED INTERACTIVITY IN 2D CORRESPONDENCE ANALYSIS
It is now possible in the 2D correspondence analysis to right-click an item and either remove it or produce a coding retrieval of the selected item.
18. TIMED BACKUP
A new project option allows one to configure QDA Miner to automatically prompt the user to back up a project at a specific time interval and to specify a default backup location.
19. VIDEO RECORDING OF GRAPHIC ROTATIONS
Now, 3D rotations of graphics may be recorded and saved in an AVI movie format.
20. ABILITY TO SELECT CODES BASED ON FREQUENCY OR CODE OCCURRENCE
A new option available in several coding analysis dialog boxes allows one to select codes based on their frequency or case occurrence.
21. CUSTOMIZABLE COMMENTS
Up to six types of comments may now be created. One may differentiate comment types by various colors and customizable labels. The List Comment feature also allows one to filter the list of comments to show a specific type of comment.
22. CUSTOMIZABLE TEXT REPORT
The text report for coded segments can now be customized, allowing the user to choose which information this report will include.
23. IMPORTATION OF RIS DATA FILES
QDA Miner can now import reference Information System (RIS) data files created by citation programs such as EndNote, Reference Manager, ProCite and Zotero, as well as many digital libraries like IEEE Xplore, ScienceDirect and SpringerLink. A dialog box allows one to select which fields to import. Such a feature will be useful for literature reviews or for the empirical study of scientific domains.
24. BATCH SEARCHING AND REPLACEMENT OF MISSPELLED WORDS
Spelling mistakes are very common in text data obtained from social media, web surveys or customer feedback systems. Even if QDA Miner has several spelling-resistant search features, spelling mistakes may still reduce the ability to accurately retrieve and code relevant documents. A new FIND UNKNOWN WORDS command allows one to search through all documents in a project for unknown words and replace them in batch mode. QDA Miner will even remember replacements you did in other projects and offer you the possibility to reapply those replacements.
25. ENHANCED SECTION RETRIEVAL
The section-retrieval tool now allows one to define multiple criteria for the end delimiter. This allows the autocoding of focus-group transcripts, group-interview data or structured data when some fields may be missing. For example, if you want to code a group interview with three participants (for example, JL, PM and GR) and an interviewer (Q), you could specify a search that will retrieve everything starting after Q= (used as a prefix for the interviewer question) up to either JL=, PM= or GR=.
26. PASTING OF IMAGES
One may now use the clipboard to paste a graphic or a photo into an image variable.
27. NEW VARIABLE TYPE TRANSFORMATIONS
One may now transform a document variable into a short-string variable, or may extract from string variables dates in various formats and store them in a new date variable.