Is Sentiment Analysis in Qualitative Data Analysis Software Accurate? May 21, 2024 - Blogs on Text Analytics
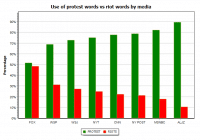
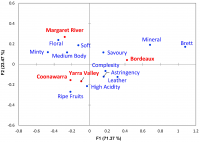
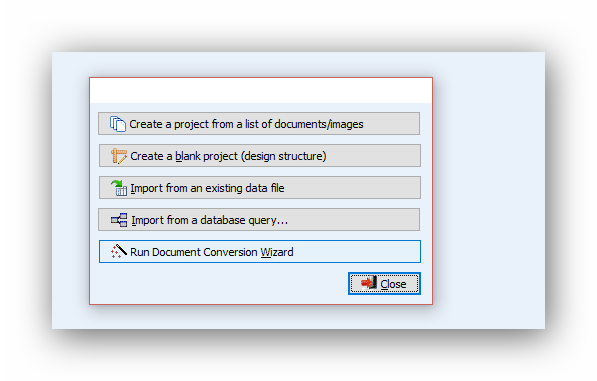
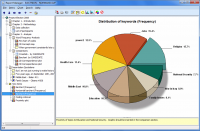
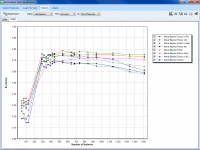
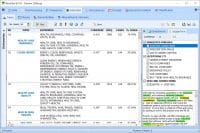
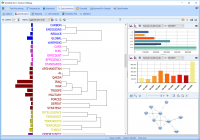
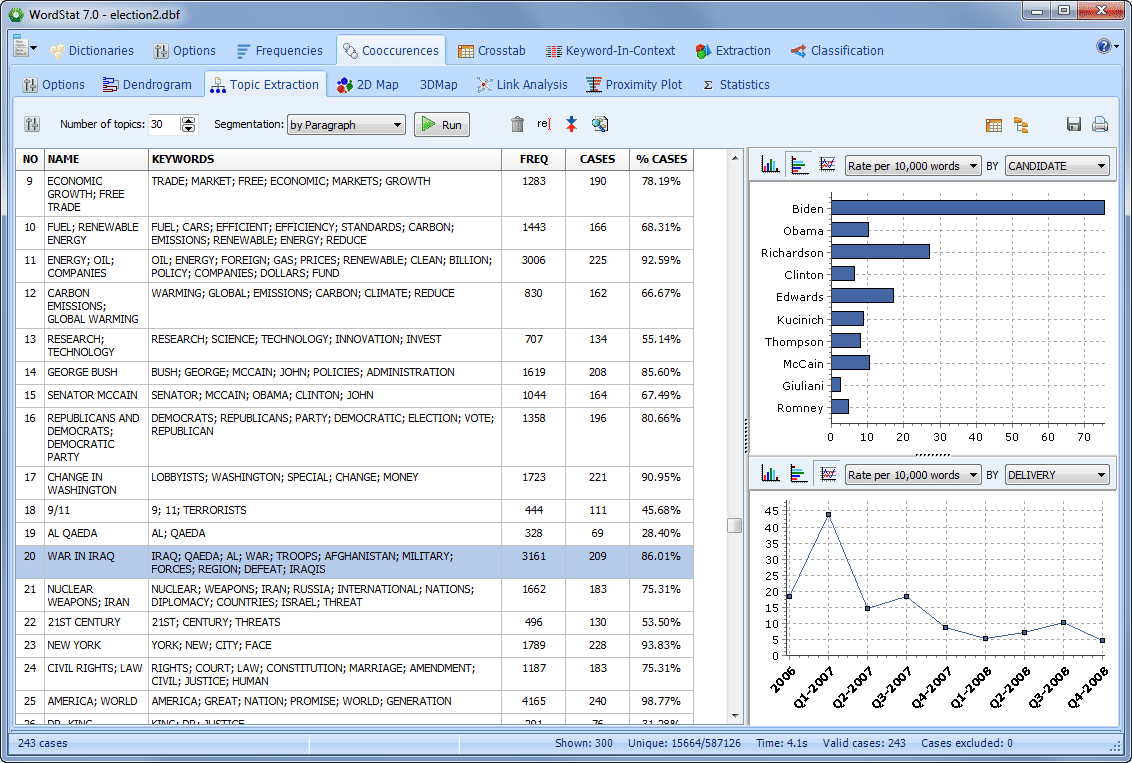
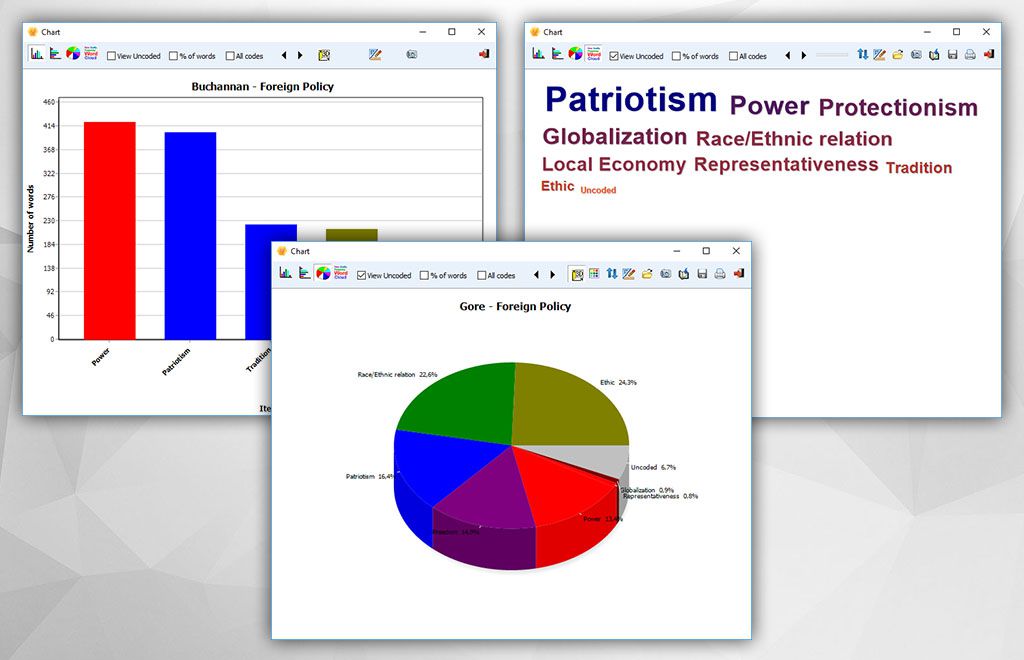
We saw in our previous blog that QDA Miner and WordStat were much more scalable and quicker than other CAQDAS desktop tools. These tools nevertheless offers text analysis techniques designed to handle large datasets, such an automatic sentiment analysis and automatic theme extraction. This second blog aims to assess the quality of sentiment analysis engines […]